基于人脸卡口数据的行人共现关系图谱构建①
2022-06-29屈诗琪刘宇宁范冰冰
屈诗琪, 刘宇宁, 范冰冰
(华南师范大学 计算机学院, 广州 510631)
1 引言
随着人脸识别技术的不断突破和完善, 可以提取到人脸在不同光影、姿态、表情和成像条件下的鲁棒的特征, 进而通过人的脸部特征信息进行身份识别, 因此大范围地部署人脸卡口是现在安防领域的重要发展目标. 人脸卡口即智能人脸抓拍摄像机, 主要部署在非机动车道, 比如一些重要的道路的人行道或者一些场所的出入口上, 只关注行人信息, 可以有效地采集经过的行人人脸图片, 形成人脸图像库. 由此, 当锁定某个案件嫌疑人时, 可以实现人脸检索功能, 得出嫌疑人被拍到的图片、地点和时间信息, 大致可以还原该人的行动轨迹; 还可以实现实时人脸比对功能, 当人脸被抓拍到时, 实时比对布控库中的人脸, 抓捕在逃人员等.
但在侦察团伙犯罪案件时, 对人脸卡口数据已经不满足只能实现人脸检索、人脸比对和人脸验证等功能. 如何从这样一个海量的未知人员人脸图像库获得更深层的信息, 比如除了获取嫌疑人的个人信息之外,还想知道与嫌疑人有密切来往关系的人有哪些, 即构建嫌疑人社交网络, 这将会是公共安全领域关注的热点问题. 人的社交一般分为虚拟和现实, 虚拟比如手机通话、微信等的社交软件, 这一类数据可以通过网络监管获取. 但现实的社交是比较难获取的, 现有的方法主要还是靠人工操作, 通过调取海量的监控视频进行反复查看才能建立行人之间的关系, 效率低下. 利用人脸卡口数据, 自动构建行人共现关系图谱, 能够给解决这一类问题提供思路和线索.
随着多媒体技术的快速发展, 图像、视频等多媒体数据的大量涌现, 基于图像和视频信息的社交关系理解研究也在进一步发展. Wu 等人[1]通过人们的相册集发现人们现实的社交关系, 其中根据个体在同一张照片的次数和距离来判定关系的紧密程度建立无向加权图, 再使用一种图聚类算法, 来检测社交集群; 周丽丽[2]将影视视频关键帧作为事务, 使用FP-Growth 对其进行频繁项集挖掘来判定两个人物之间有无关系,当共同出现次数超过阈值则存在关系, 以此构建人物关系网络; 周檬[3]利用DBSCAN 进行人脸聚类, 再通过统计监控视频关键帧中行人与行人间的共现关系、人与摄像头的出现关系构建视频图谱.
在大多社交关系的研究中, 缺乏人物节点(关系图上的顶点)识别的具体论述, 使用的聚类算法没有经过比较并对其进行有效性验证. 人脸卡口的人脸类别数量相对于相册集或者影视剧中的实验数据集更为复杂多样, 作为关系网络构建的基础, 准确地进行人物节点识别才能构建可用的行人共现关系图谱; 在目前研究人物之间的社交关系中, 其中关系存在判定, 即有无关系, 主要是基于共现的方法, 关系程度则取决于共现频度. 对此, 本文基于行人节点识别和共现关系抽取两个方面完成行人共现关系图谱的构建流程: 首先提出基于Chinese Whispers 的行人节点识别的算法, 在此基础上使用Faiss 加速邻接边的构建, 提高行人节点识别效率, 并与其他算法做比较验证了其优越性. 其次, 在共现频次的基础上增加其置信度来挖掘行人的关系, 最后以图形界面的形式展示图谱.
2 相关知识
2.1 人脸聚类评价方法
使用有标签的人脸数据集并根据两种聚类评价指标对聚类结果进行评价: 1)采用scikit-learn 库中的聚类效果评价指标: 同质性(homogeneity): 每个集群只包含单个类的成员; 完整性(completeness): 同类的所有成员都分配在同一集群中; 同质性和完整性的加权平均F-measure. 以人脸聚类为例, 同质性即同一个类中是否都是同一个人的照片, 完整性即是否将一个人的所有照片都聚集在一个类中. 2)采用文献[4]中的成对准确率P_pairwise, 成对召回率R_pairwise指标. 如式(1)、式(2)所示:
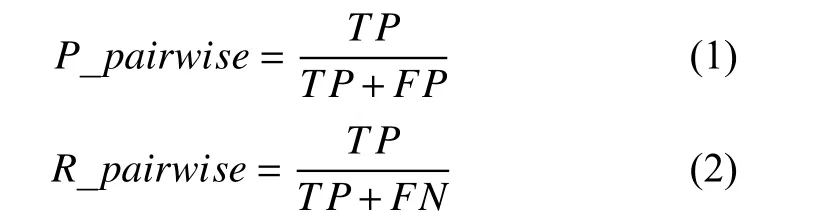
其中,TP表示同一个人的人脸被正确地聚在同一类中的对数;FP表示不是同一个人的人脸被错误地聚在同一个类中的对数;TN表示不是同一个人的人被正确地聚到不同的类中;FN表示同一个人的人脸被错误地聚到不同的类中. 其中, 成对F均值度量F_pairwise:
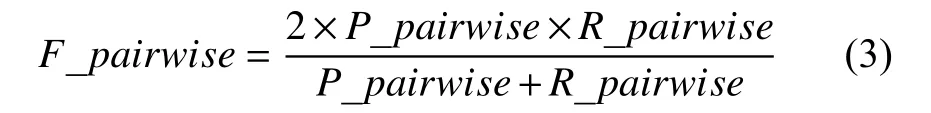
2.2 DBSCAN
DBSCAN (density-based spatial clustering of applications with noise)是一种很典型的密度聚类算法,这类密度聚类算法一般假定类别可以通过样本分布的紧密程度决定. 算法通过参数(Eps,MinPts)用来描述样本分布紧密程度, 其中,Eps描述任意样本的邻域距离阈值(距离度量一般使用欧式距离、曼哈顿距离等),MinPts描述了任意样本的Eps邻域中样本个数的阈值. (Eps,MinPts)参数是影响聚类效果的两个很重要的参数,Eps过小会导致原本是一个类簇却被分割成多个小的类簇,Eps过大会导致不是一个类簇的多个距离相近的簇聚成一个大簇.MinPts越大, 形成类簇的条件就越苛刻, 那么样本集的噪声点就越多, 当MinPts=1 时,样本集中就没有噪声点, 所有的样本都能在类簇中.
2.3 Approximate Rank Order
Approximate Rank Order[4]聚类是根据Rank Order[5]聚类改进的. 与绝对距离(比如欧氏距离)不同, Rank Order 聚类发现了来自同一个人的两个脸往往有许多共享的邻居, 但是来自不同人的两个脸的邻居通常差别很大这一特点, 提出一个新的人脸相似度量方法Rank Order 距离, 它通过比较两个样本之间的邻域结构得到样本之间的相似度. 后来, 为了使其能应用在大规模人脸数据中, 提高聚类效率, Approximate Rank Order 算法重新定义距离的度量方式, 不需要计算每个人脸的所有最近邻而是k个最近邻, 从而得出人脸之间的非对称秩序距离之后, 就可以逐步地将低于距离阈值threshold 的人脸合并为一个类簇.k和threshold是该算法的两个需要指定的参数.k是选取每个人脸最近邻的数量, 而且Approximate Rank Order 使用FLANN库的随机k-d tree 算法求出每个人脸图片的k个最近邻图片排序, 聚类的效率显著地提高.
3 行人共现关系图谱构建
人脸卡口主要采集经过的行人的人脸图像、被抓拍到的时间戳以及卡口自身的编号, 其中卡口的编号就代表行人被抓拍时的位置信息. 基于人脸卡口的行人共现关系图谱构建的整体流程如图1 所示, 其中最主要的两个步骤: 一是基于聚类的行人节点识别, 由于人脸卡口中出现的人是未知的, 没有模板人脸库让其去一一对应来标明行人的身份, 所以使用基于聚类的方法标注人脸卡口中的人脸图像, 从而得到图谱中的行人节点; 二是行人共现关系抽取, 通过人脸卡口数据的特性, 定义共现关系的有无和共现关系的强度来共同抽取行人间的共现关系, 从而得到图谱中节点之间的边.
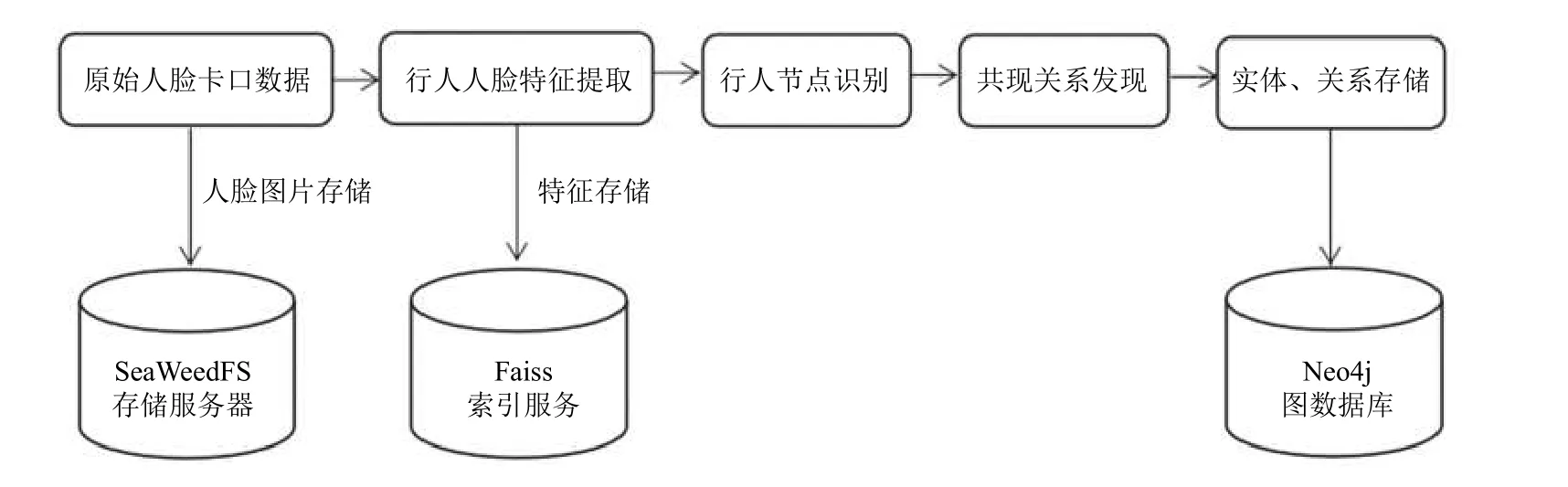
图1 行人共现关系图谱构建流程
3.1 基于聚类的行人节点识别
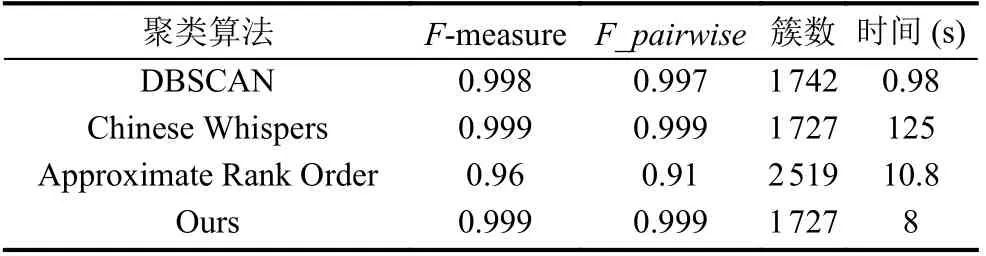
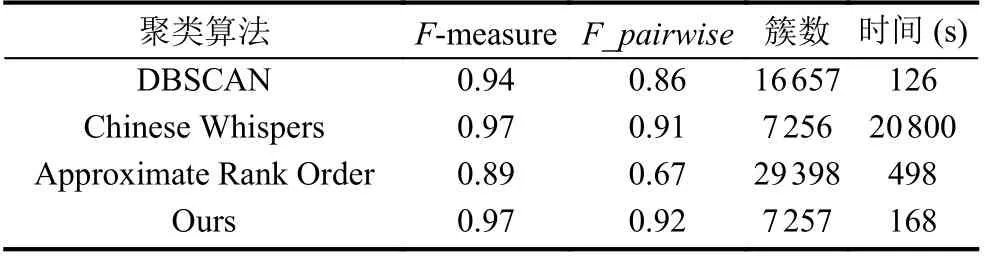
基于聚类的行人节点识别, 也可称作人脸聚类, 旨在把相似的人脸图像归为一类, 即把属于同一个人的人脸打上同一个标签[6], 如图2 所示. 人脸聚类效果的好坏主要取决人脸特征的提取(人脸的向量表示)和聚类算法的选择[7], 人脸特征的提取要保证具有高精度的可分性, 这里使用目前效果较好的CNN+ArcFace Loss方法提取人脸特征向量. 适用于人脸聚类的聚类算法是不需要预先设定类别的数量的, 如传统的K-means就不行, 因为我们对人脸卡口数据集是没有预先的认识, 其具体包含多少个类别是未知的. 文献[3]使用CNN+ArcFace Loss 方法提取人脸特征, 直接使用DBSCAN作为人脸聚类算法, 标识监控视频中出现的行人; 文献[8]使用FaceNet 提取人脸特征, 在LFW 数据集上验证了DBSCAN 相较于其他聚类方法(如谱聚类和Rank Order); 文献[9]使用附加间隔Softmax 提取人脸特征,分别在LFW 和LFW+模糊视频上实验结果都证明Approximate Rank Order 比DBSCAN 更加适合处理较大规模的复杂人脸数据; 文献[10]使用Chinese Whispers对人脸聚类获取同一个人的人脸图像, 结合人脸质量评估算法从而达到在一段视频中人脸图像去重的目的.可见, 适用于人脸聚类的聚类算法是需要根据人脸特征提取算法和人脸数据择优选择的, 常用来做人脸聚类的算法主要是DBSCAN, Approximate Rank Order和Chinese Whispers.
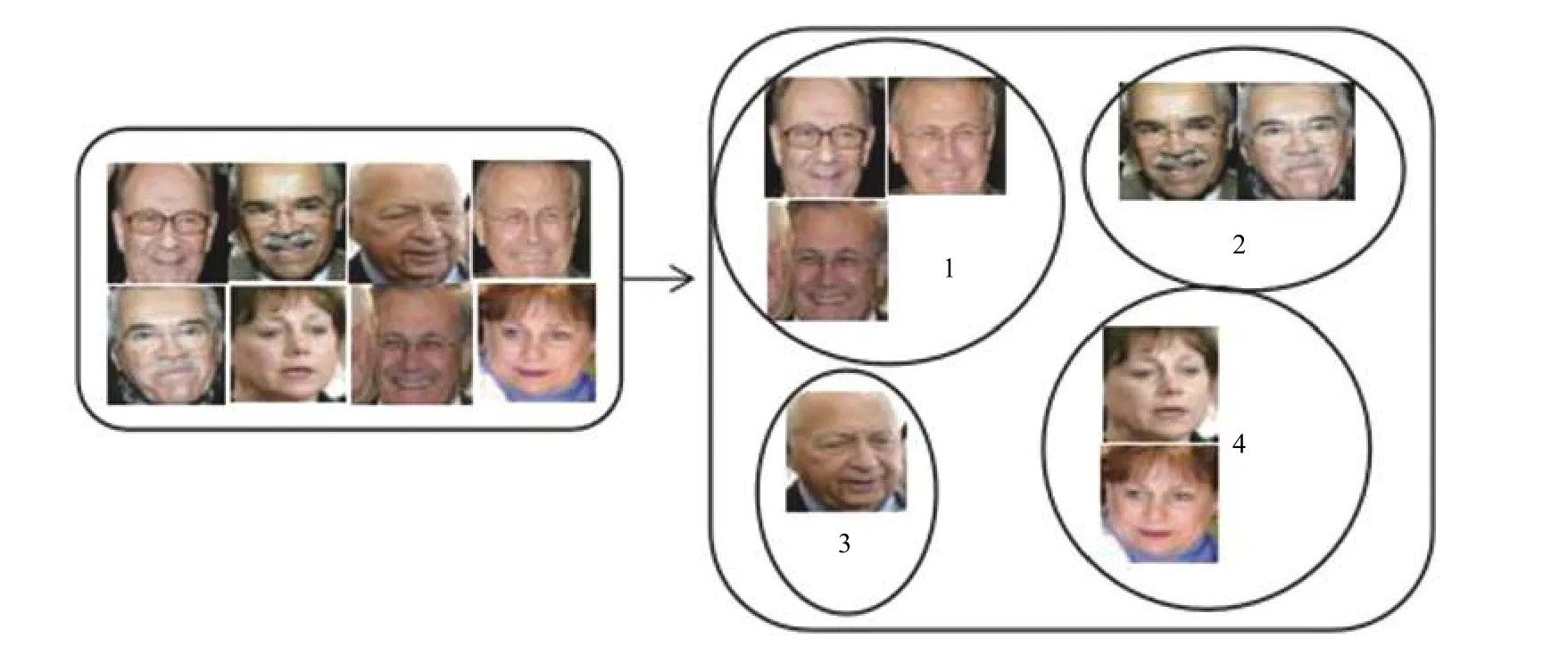
图2 行人节点识别
3.1.1 Chinese Whispers 算法
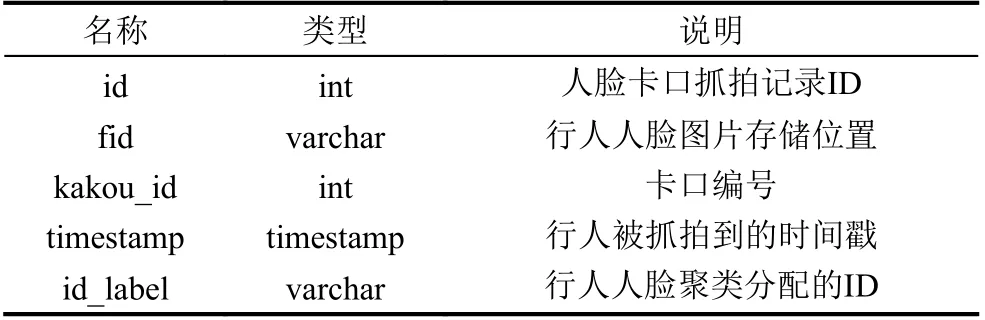
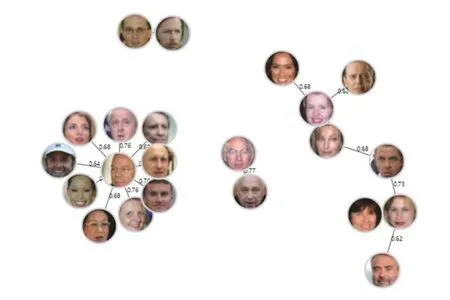
Chinese Whispers[11]最早是被用在自然语言处理如文本聚类中, 后来也广泛应用于人脸聚类, 它不需要预先设定类别数量, 是一种可以自动查找类别个数的高效图形聚类算法. 该算法分为两个步骤: 第一步是构建无向加权图G=(V,E). 把数据集中的每一个样本当作图上的一个点v_i∈V, 并且初始化每一个节点的类别属性为当前节点顺序编号. 接着就是构造无向图的边, 当节点v_i和v_j(其中v_i 该算法需要事先定义两个超参数threshold 和iterations. threshold 是节点之间的相似度阈值, 只有大于这个阈值, 节点与节点之间才有边, 消息才得以互相传递. 形式上, 该算法并不会收敛, 所以要指定iterations迭代次数, 但是对于加权图, 只需要几次迭代就能达到稳定状态. 它的不足之处在于因为其随机性(对小图来说从哪个节点开始迭代很重要), 所以对于处理小图具有不确定性, 但是在大图中这种不确定性将会消失, 适合处理稍大数据的聚类. 3.1.2 改进的基于Chinese Whispers 的行人节点识别 虽然原始的Chinese Whispers 算法是适合处理稍大数据的聚类, 但是由于人脸特征向量512 维是高维向量, 算法需要计算不同节点之间的相似度, 其时间复杂度为O(n2), 当处理大规模人脸聚类时, 会导致算法的第一步骤即图的初始化缓慢. 文献[7]使用增量聚类的思想提出基于Chinese Whispers 的人脸动态聚类, 其时间效率虽然稍有提高, 但是准确率都稍有下降, 并且对于类别数较多的数据集, 时间提升效果不明显. 本文使用Faiss (Facebook AI similarity search)[12,13]加速图中节点的边的构建, 把判断两节点是否相似问题, 转化为对节点的限定半径邻居查询问题, 提高聚类速度.Faiss 为稠密向量提供高效相似度搜索, 是目前最为成熟的近似邻搜索库. Faiss 提供了许多不同应用场景下的索引供选择, 由于Chinese Whispers 算法需要计算每个样本节点之间的相似度, 即余弦相似度, 提取的人脸特征是经过L2 范数归一化的, 人脸特征余弦相似度的值等同于人脸特征内积的值, 所以选择Faiss 中的IndexFlatIP 为人脸特征构建索引. 其中详细的行人节点识别步骤如算法1 所示. 算法1. 改进的基于Chinese Whispers 的行人节点识别算法输入: 行人人脸图像数据集D, 相似度阈值t, 迭代次数iterations输出: 行人身份标签列表labels 1) 使用CNN+ArcFace Loss 提取数据集D 中所有人脸图像的人脸特征, 保存到feats;2) 根据feats 构建Faiss 中的IndexFlatIP 特征索引;3) 使用特征索引, 一次性查询所有人脸特征feats 的限定半径t 邻域的最近邻居, 保存到res;4) 构造节点列表nodes, 初始化每个节点的label 为0 到len(feats)–1;5) 根据res 构造边列表edges, 其中边的权重为两个节点的余弦相似度;6) 根据nodes 和edges 完成对无向图G 的初始化;7) n=0;8) while n 3.1.3 实验 (1) 实验环境与数据集: 实验在CentOS 7 系统,CPU 为Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20 GHz,内存为128 GB 的服务器上进行. 使用LFW[14]和CASIAWebFace[15]数据集的部分数据. 其中LFW 数据据分布很不均匀, 大多数人只有1 张图像, 所以只选取LFW 中有2 张及以上的数据集. CASIA-WebFace 的图片比较多,由于实验室设备的限制, 只选取了一部分数据集, 如表1. 表1 实验数据集 (2)人脸特征提取: 使用RetinaFace[16]人脸检测算法对两个数据集进行数据清洗, 删除无法检测到人脸的图片. 接着使用RetinaFace 进行人脸检测, 由于有些图片中可能不止一人出现, 对这些图片仅选择中心坐标的人脸作为目标对应其标签. 为了更好地提取人脸特征, 对RetinaFace 人脸检测算法得到的人脸5 个关键点进行仿射变换摆正人脸位置, 再使用CNN+ArcFace Loss方法[17]提取512 维人脸特征. (3)实验结果与分析: 在人脸聚类中, 我们往往会更加在意聚类评价指标中的同质性和准确性, 因为如果某一个人脸的聚簇中出现大量别人的人脸, 人脸聚类结果的应用就会失去它的意义, 所以本文实验结果中的F-measure 和F_pairwise都是在同质性和准确率大的情况下取它们的最大值. 如表2 所示, 在LFW 数据集的表现上, 4 个算法聚类效果差距不大, 但是Chinese Whisper 的得分最高,并且簇数是最接近真值的, 且经过改进的Chinese Whispers 与原始Chinese Whispers 算法的结果是一样的, 时间效率却提高了不少. 表2 在LFW 子集(真实簇数=1680)上的实验结果对比 但是在CASIA-WebFace 数据集的表现上差距就显现出来了, CASIA-WebFace 数据集中的图片相较于LFW 数据集, 同一个人的照片时间跨度更大、造型差异大、模糊度高等, 人脸聚类的难度比LFW 数据集大很多. 如表3 所示, Chinese Whispers 算法的表现最好,两个平均度量指标得分最高, 且聚类簇数最接近真实簇数, 说明其人脸聚类的鲁棒性, 更适应稍复杂的人脸数据, 而且经过改进后的Chinese Whispers 使得其可以应用在大规模的数据集上. 继续对我们的方法的实验结果进行详细分析, 7257 个聚簇中有5015 个孤立点, 这5012 个孤立节点是在图上没有邻接边的点, 即跟样本集中的所有样本的相似度都小于相似度阈值. 这些孤立节点大多是数据集采集时的错误标记或是遮挡、模糊等原因无法正确人脸识别. 去掉孤立节点之后, 完整性和成对召回率提高,F-measure 得分0.98,F_pairwise得分0.96. 所以, 将其应用在人脸卡口数据上的聚类效果应该会更好. 表3 在CAISA-WebFace 子集(真实簇数=1727)上的实验结果对比 行人共现关系抽取算法基于前面已有的基于Chinese Whispers 的行人节点识别方法, 对每张脸进行聚类, 将属于同一人的人脸分配同样的编号, 即id_label,作为不同行人的身份辨识. 当行人节点识别完成后, 本文涉及到的数据存储字段如表4 所示. id 表示抓拍到的人脸编号, id_label 是聚类之后的编号, 相同身份的行人的id_label 与id 是一对多的关系. 人脸图片使用SeaweedFS[18]存储, 使用fid 存储图片链接, 极大地减少了存储空间, 且直接通过http 协议访问该链接, 能够提高图片的访问速度. 表4 存储字段描述 在文献计量研究领域中, 共同出现的特征项之间存在着某种关联, 关联程度可以使用共现频次来评估.所以, 在图像或视频的社交关系挖掘中, 也是在共现的基础上发现社交关系的, 大都是统计图像或视频关键帧中的共现次数. 人脸卡口数据与图像和视频数据不同, 共现不是体现在一同出现在一个画面中, 而是体现在一定时间间隔内被同一个人脸摄像机抓拍到. 当基于人脸卡口的行人共现关系网络G=(V,E), 关系如公式(4)所示: 其中,support(i,j)是行人i,j共同出现的次数,sup_min是设置的共现关系的最低阈值,Eij=1 表示行人i,j之间有边连接, 即认为i,j之间有关系. 反之, 则认为i,j之间无边连接, 即i,j之间无关系. 一般情况下, 我们把只共现一次视为偶然情况, 所以sup_min要大于或等于2. 行人对之间的关联程度除了用共现频次来表示以外, 本文引入Apriori 关联规则算法中置信度概念[19]来计算共现关系的置信度, 如式(5)所示: 其中,confidence(i⇒j)得到的是i出现, 则j也一同出现的概率, 反映了在i方面, 认为j的重要程度. 我们还可以得到其平均置信度, 如式(6)所示: 其中,confidence(j⇒i)是式(5) 中i,j互换位置的结果. 使用置信度来体现行人对之间的关联紧密程度更具有说服力, 比如当行人a, b 分别被拍到了2 次, 且他们也正好共现了2 次, 那么他们共现的置信度就是1;而行人c, d 分别被拍到了10 次和15 次, 共现了3 次,那么他们共现的置信度是0.25. 如果仅根据共现频次,c 和d 之间的关联程度要大于a 和b, 但是从现实角度,我们会认为a 和b 的关联程度要大于c 和d. 所以, 人脸卡口中行人对满足最小支持度和最小置信度的共现关系, 被认为是强关联关系, 其中共现关系抽取的详细步骤如算法2 所示. 算法2. 行人共现关系抽取算法输入: 人脸卡口数据集D, 卡口列表L, 时间间隔t, 最小支持度sup_min, 最小置信度conf_min输出: 共现关系结果集合R 1)扫描人脸卡口数据集, 统计每一个ID 出现的总次数, 保存到字典id_to_counts;2) for L_i in L:3) S 为在L_i 被抓拍的人脸集4) 对S 中出现的人脸按照时间戳从小到大排序5) for Sk in S[0:]:6) Sj in [k+1:]:7) if (T_Sj – T_Sk > t): break;8) //在时间间隔内9) if (IDk > IDj): 交换IDk 和IDj 10) R[(IDk, IDj)] +=1//记录一次共现11) 把R 中记录的共现次数小于sup_min 的行人对过滤掉;12) for R_i in R: 13) 根据id_to_count 分别计算R_i 中行人对的置信度conf1, conf2;14) if (avg(conf1, conf2) 选择Neo4j 作为图谱的图数据库存储, Neo4j 能够高效地存储节点、关系和属性, 同时, Neo4j 支持Cypher查询语言, 关系查询灵活高效, 支持增删改查功能. 基于人脸卡口数据的行人共现关系图谱的实体和关系存储的属性如表5 所示. 表5 Neo4j 存储描述 表5 中, 行人节点的id_label 作为唯一性约束,img_url 是该ID 行人人脸图像, paths 是一个列表, 存储了该行人的(kakou_id, timestamp), 即行动轨迹. 关系属性中的conf 是共现置信度, times 是共现频数. 根据公开的人脸数据集LFW 和CASIA-WebFace随机+人为制造了人脸卡口数据集作为样例, 构建行人共现图谱. 最后, 采用Web 页面作为前端展示页面, 使用D3.js 作为前端展示框架, 借助D3.js 的力学导向图,将数据以网络的形式展现. 如图3 所示, 展示了数据集中部分数据, 生动地反映行人之间的共现关系, 其中节点之间边的长度取决于共现关系的置信度的大小, 置信度越高, 节点相距就越近, 更能显示紧密的关系. 图3 基于人脸卡口数据的行人共现关系图谱展示界面 本文针对侦察团伙犯罪案件时人脸卡口数据应用的局限性以及对人的现实社交关系难以辨认的问题,实现了一种基于人脸卡口数据的行人共现关系图谱的构建流程. 该流程首先使用Faiss 加速Chinese Whispers算法中初始图的邻接边的构建, 使其能够完成大规模人脸聚类的任务, 得到人脸卡口数据这一未知人员库中行人的潜在身份id, 然后再根据人脸卡口记录挖掘行人的共现关系, 通过共现频次和置信度来体现关系强度, 最后使用前端框架展示图谱交互式界面.

3.2 行人共现关系抽取
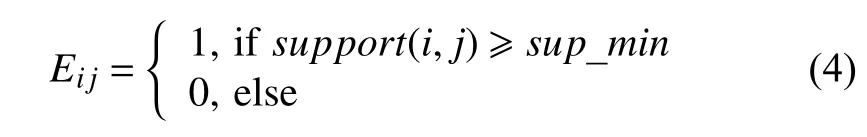
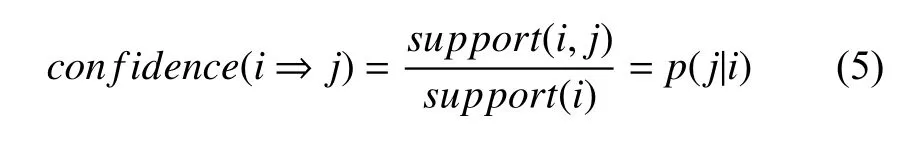
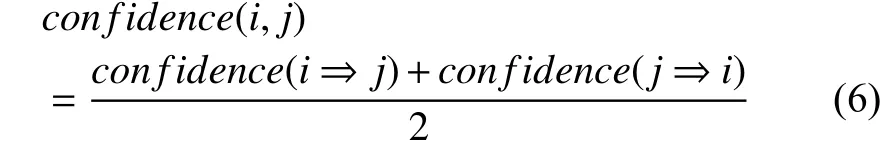


3.3 实体、关系存储
4 图谱可视化
5 结论
