面向电力规章制度的命名实体识别①
2022-06-29何晓勇金兆轩金志刚
陈 鹏, 蔡 冰, 何晓勇, 金兆轩, 金志刚, 侯 瑞
1(国网宁夏电力有限公司, 银川 750001)
2(天津大学 电气自动化与信息工程学院, 天津 300072)
3(华北电力大学 苏州研究院, 苏州 215123)
4(华北电力大学 经济与管理学院, 北京 102206)
随着智能电网的不断革新, 信息技术与电力系统逐渐融合, 电力企业在数字化转型的方向上有了极大的进展, 在这一过程中产生了大量的行业相关数据, 也可以称为是数字资产, 数字资产是企业或机构在生产、运营、管理过程中累积的对企业或机构具有利用价值的数字化信息和内容, 通过对数字资产的组织加工, 可以优化企业内容管理架构, 促进企业运营模式改革, 从而提高企业收益. 简单地将海量的数字资产存储在各种存储介质中并且不采取任何管理措施, 企业的数字资产无法体现其自身的任何价值, 为了发挥企业数字资产的最大价值, 数字资产管理应运而生. 数字资产管理是对数字资产的创建、采集、组织、存储、利用和清除过程加以研究并提出的相应方法的统称.
将电力行业数据进行有效的组织管理可成为电力企业实现数字资产商品化[1]的指导方法, 采用合适高效的分类管理方式不仅进一步加快电力企业数字化转型步伐, 也可以推动电力企业发掘新的利润增长点.
1 相关工作
知识图谱是谷歌公司于2012 年首次提出的概念.知识图谱的本质是一个与传统数据库不同的大型语义知识库, 知识库中主要涉及到的内容为数据中的实体与关系, 一个构建好的知识图谱可以用来辅助进行问答, 数据分析和决策等应用[2]. 知识图谱的构建包含知识抽取, 知识融合等内容, 其中知识抽取是构建知识图谱的核心环节. 将知识图谱的构建方法应用到电力企业所产生的庞大数据, 可促进对数据的高效分类并且促进实现数字资产商品化, 提升数字资产的价值.
命名实体识别[3]是构建知识图谱最重要的也是最为根基的一环, 该任务旨在从文本中抽取待分类的命名实体并标注其类型, 通用的命名实体任务一般包括人名、地名、和机构名等. 实现特定领域的命名实体识别需要将领域内特定类别的实体识别出来, 该任务最早使用人工编写规则的方式进行识别, 例如通过制定有限的规则和模式, 从文本中自动匹配这些规则或模式的字符串, 并标记为各类命名实体, 不过随着数据集的越来越复杂, 用人工制定的有限规则识别日益增长的命名实体是非常困难的. 因此基于统计机器学习的方法获得了越来越广泛的关注, 使用统计机器学习的方法大致可分为以下几个步骤: 选择适合文本序列的模型, 使用合适的文本特征来增强模型的特征捕获能力. 并且将命名实体任务转化成为序列标注任务, 也即对序列中的每个字符都有多种标签类别的可能与之对应, 模型所要做的就是为每个字符分配可能性最大的分类标签, 从而使实体被标注为正确实体类型标签,完成命名实体任务.
近年来, 随着基于神经网络模型的深度学习方法成为了机器学习中十分热门的方向, 其中利用语言模型等任务所得到的预训练高维词向量来作为词语的表示方法更是加强了神经网络模型的表示能力, 这样的表示不仅缓解了独热向量的数据稀疏问题, 还使得稠密的向量具有一定的语义表示能力. 从Word2Vec 开始, 寻找一个有效的词向量表示成为了自然语言处理重要的研究方向, 文献[4]使用BERT 模型在大规模语料中进行自监督的预训练, 得到每个字关于上下文的表示, 并且通过多层堆叠的Transformer 模型, 可以使得文本的向量表示具有动态的, 上下文相关的特点, 这样的特点可以缓解过去静态的词向量无法解决词语歧义的问题.
郭军成等人[5]利用BERT 嵌入Bi-LSTM 实现了对简历数据的命名实体识别, 吴超等人[6]利用了Transformer 混合GRU 在电力调度领域进行了命名实体识别, 谢腾等人[7]将BERT 嵌入到Bi-LSTM-CRF中, 在MASR 通用数据集中获得了显著的效果, 赵丹丹等人[8]利用了多头注意力机制和字词融合实现人民日报中的通用领域命名实体识别. 与此同时, 近年来由于Transformer[9]使用自注意力机制在预训练任务上和机器翻译任务上表现十分出色, 如何将Transformer 较好的适配到其他任务也成为了一个热点的研究方向,韩玉民等人[10]利用Transformer 实现材料领域的英文命名实体识别, 何孝霆等人[11]利用Transformer 来捕捉文本的特征从而判断文本的真实立场.
本文提出了一种融合字符和二元词组特征, 通过BERT 预训练模型得到上下文语义特征, 然后嵌入改良位置编码表示的Transformer 模型的命名实体识别方法, 较好地实现了电力领域命名实体识别任务.
2 嵌入BERT 的Transformer NER 架构
2.1 CB-BRTC 模型
本文提出的模型CB-BRTC 如图1 所示, 可分为4 部分, 第1 部分为特征表示, 本文提出了一种基于字符级别的混合二元词组作为特征的输入. 第2 部分为BERT 模型, 通过使用中文的BERT 模型可以得到上下文语义的表达, 将字符混合二元词组的特征通过BERT 模型得到具有上下文语义表示的词嵌入向量.第3 部分为改进Transformer 模型的编码层, 使用多头自注意力机制自动捕捉文本在不同语义空间的表达,使用相对位置编码融入词向量中. 第4 部分为解码层,通过使用条件随机场解码序列的输入, 从而得到最终的标签序列.
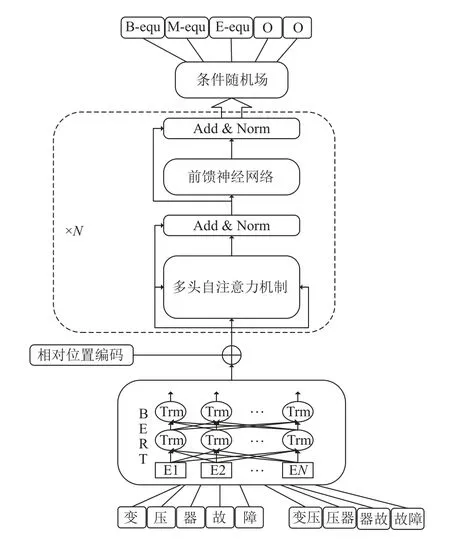
图1 CB-BRTC 模型结构
算法的流程为:首先通过对收集来的电力政策数据进行预处理, 得到字符序列和字符的二元词序列, 然后将字符序列和二元词组序列通过使用BERT 的词表映射, 使文本通过BERT 计算每个字符的上下文语义表示的词向量, 随后使用相对位置编码, 融合词向量表示,通过使用Transformer 的多头自注意力机制捕捉序列在不同语义空间的表达, 再经过前馈神经网络进行融合, 最终得到关于命名实体识别任务的编码表示. 最后将该编码表示通过条件随机场解码得到符合序列标签转移规则的标签表达, 同时为了高效解码, 使用维比特算法得到分数最高的路径从而选择合适的标签序列.
本文使用的结构与前人主要的区别在于本文选择了对中文命名实体识别效果具有高效并且容易得到的字符融合二元词组特征, 利用BERT 得到符合上下文语义的动态词向量使得句子的表达含义相较Word2Vec的静态词向量更加准确. 并且使用改进Transformer 位置编码的编码结构, 通过使用相对位置编码来使得模型更易捕捉文本的前后关系.
2.2 BERT-WWM 模型
BERT 模型是一种基于自监督训练任务的预训练语言模型, 具有三大特点, 即使用海量的数据, 巨大的模型, 和使用强大的算力得到. BERT 本身采用多种Transformer 堆叠而成, 使用了包括掩码语言模型和下一个句子预测的两个预训练任务.
BERT 使用词向量, 块向量和位置向量之和来表示输入. 通过使用掩码语言模型和下一个句子预测预训练任务来完成自监督训练. 掩码语言模型任务中,BERT 使用了15%的掩码比例, 将输入序列的15%的子词进行遮盖, 在这15%的遮盖子词中, 有80%的概率使用“[MASK]”标签来替换, 有10%的概率使用词表中的随机词来替换, 有10%的概率保持不变. 下一句预测是指利用文本中天然的句子顺序, 通过控制正负样本的比例在1:1, 即使正确句子顺序和错误句子顺序的比例为1:1, BERT 需要判断后一个句子是否是前一个句子的下一个句子, 从而学习到两段输入文本之间的关联.
BERT-WWM[12]是在BERT 的基础上使用进阶的预训练任务, 进一步提升预训练任务的难度, 从而使预训练模型具有更加有效的语义表达信息. BERT-WWM使用的预训练任务是整词掩码的任务, 通过使用哈工大开发的LTP 工具完成对语料的分词, 在进行整词掩码时, 将整个词语进行遮盖, 从而使得模型学习难度加大, 获得更好的语义表达形式.
2.3 编码结构
Transformer 是一种特殊的利用全连接的多头自注意力机制模型, 完整的Transformer 是由编码结构和解码结构[9]组成的, Transformer 的编码结构通过使用多头自注意力机制捕捉命名实体识别任务的文本在多个语义空间的表达和不同语义空间中文本序列中不同字符之间的关系. 本文使用的Transformer 结构引入相对位置信息, 其编码单元的结构如图2 所示.
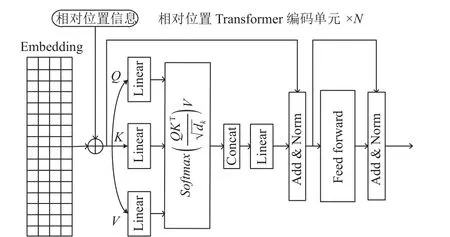
图2 相对位置Transformer 结构
在Transformer 结构中使用的多头注意力机制如式(1)所示:

其中,Q,K,V在原始Transformer 结构中是由式(3)中的向量表示得到,H为输入的序列矩阵,WQ,WK,WV是可训练的参数, 通过多头自注意机制可以反映出来每个字符和其他字符的关系, 使用Transformer 可以有效缓解卷积神经网络的专注于局部性的特点和循环神经网络梯度消失所导致无法实际捕捉长距离依赖关系的问题, 拥有比卷积神经网络和循环神经网络更好的特征捕捉能力.
Transformer 编码单元利用残差网络和层正则化来缓解深度神经网络中经常会遇到的退化问题, 具体的实现如式(4)所示:
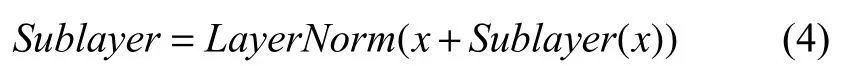
其中,x为通过复杂网络结构前的输出, 在Transformer中指多头自注意力映射前的输出或者通过前馈神经网络之前的输出,Sublayer(x)表示通过复杂结构之后的输出, 在Transformer 中指多头自注意力映射拼接降维后的输出或者通过前馈神经网络的输出.
在每个多头注意力和残差连接后都会接一个位置全连接前馈神经网络, 表达式如式(5)所示:
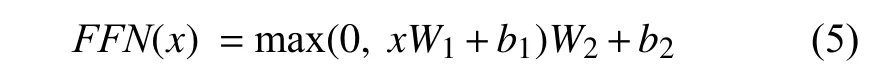
其中,W1和W2为可学习的变换矩阵,b1和b2为可学习的偏置, 由于采用自注意机制来捕捉文本序列之间的关系, 其本身并没有可以感知位置的结构, 所以在Transformer 的输入部分引入位置编码, 位置编码可以使用可训练的矩阵表达, 也可以通过事先设置好格式得到.文献[9]采用了绝对位置编码, 如式(5)和式(6).
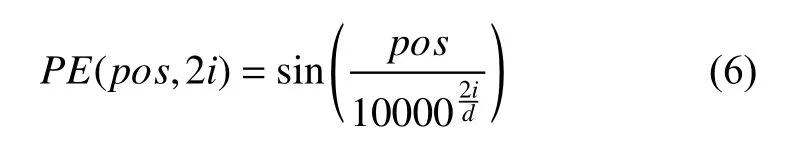
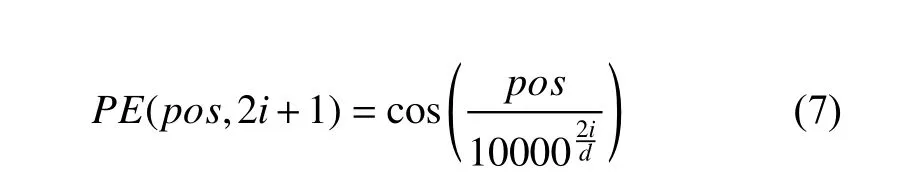
其中,pos是位置,i是位置编码的第i维度,d是输入的维度, 原始的Transformer 采用三角函数来将绝对位置进行编码. 但是有研究[13]证明, 使用绝对位置编码会使得Transformer 的位置感知能力丧失对方向的判断, 相对位置的编码结构可以使得模型对位置的感知更加敏感, 因此本文采用相对位置编码从而使得Transformer模型更适合命名实体识别这一任务. 不仅如此, 原版的Transformer 模型存在一定的冗余参数, 因此本文将原版公式中涉及到两个可学习的参数的相乘结果用一个可学习参数替换, 使用相对位置编码和消除冗余参数后的多头自注意力机制计算公式如下所示:
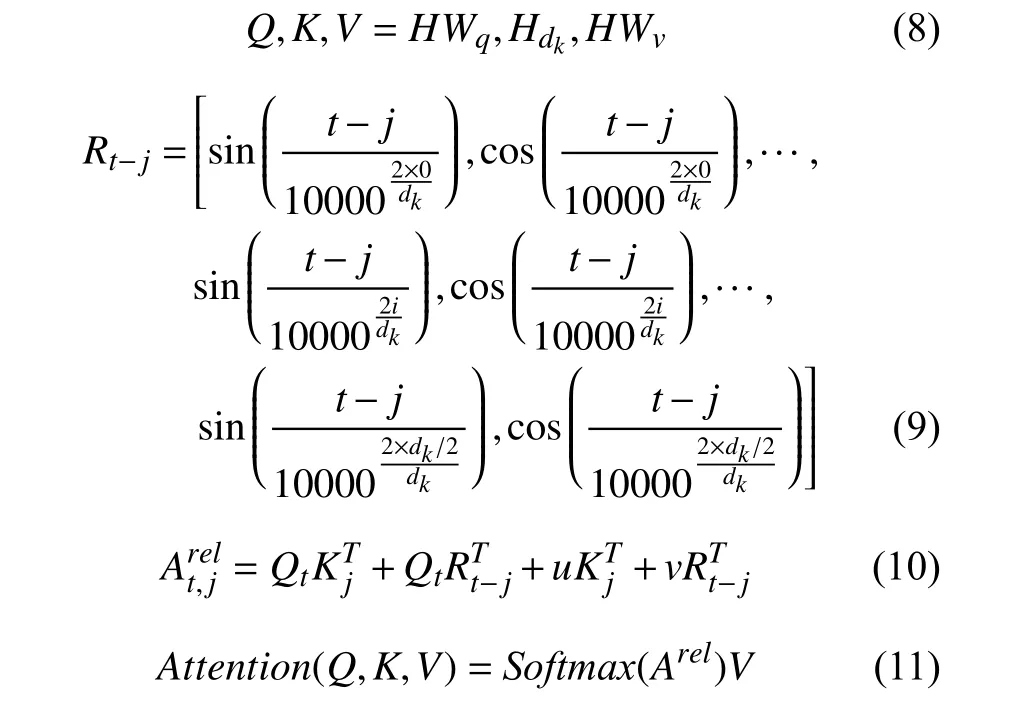
其中,t是目标字符的位置,j是文本中计算自注意力时每个字符的位置,Qt和Kj是t位置的问向量和j位置的键向量,Wq和Wv是可学习的矩阵,Hdk是由H以dk为单位划分的每一个部分, 每一个部分使用一个自注意力的头来捕捉特征,u和v都是可学习的向量,Rt−j是相对位置编码的向量, 由正弦和余弦函数间隔填充, 从而可以捕捉前后字符出现的关系.
2.4 解码结构
为了充分利用不同标签之间的依赖关系, 本文采用条件随机场模型来捕捉序列标签之间的转移概率和发射概率, 从而得到更加符合标签顺序的标签序列, 一个序列的标签y=l1,l2,···,lτ出现的概率由式(12)所示:
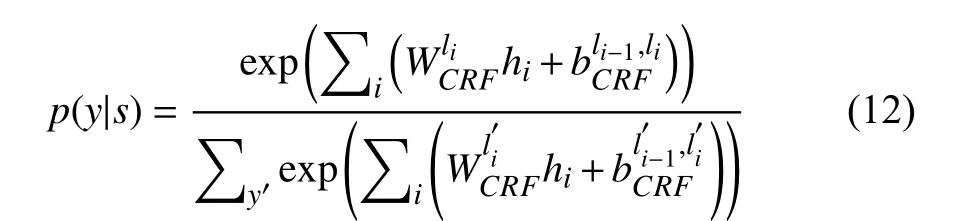

3 实验
3.1 实验环境和数据介绍
实验计算机的系统配置和主要程序版本如下:Linux 操作系统, Python 3.7, PyTorch 1.2, 16 GB 内存.
本文使用电力行业规章制度的标注文本实验, 对规章制度中的非结构化数据利用专家标注的方法构建标注数据, 并将数据分为训练集, 开发集和测试集, 数据集中的实体类型分为“机构单位”“电力设施”“政策原则”这3 种实体类型. 采用“BMEO”的实体标注方式, 例如“机构单位”的实体用“B-AFF”“M-AFF”“E-AFF”来表示“机构单位”实体的开头中间和结尾. “O”代表该字符不属于3 类实体的任一类. 数据集的规模如表1 所示.

表1 电力政策实体标注数据集
3.2 命名实体识别效果对比
本文实验采用的评价指标为边界判断的准确率(P)、召回率(R)和F1 值来表示模型对实体所在位置的定位, 用类型准确率(type acc)表示对实体判断的准确率. 公式的参数定义如下:TP为模型识别正确的边界数量,FP为模型识别出错误的边界的数量,FN为该字符是相关实体的边界但模型没识别出实体边界的数量.计算公式如下.
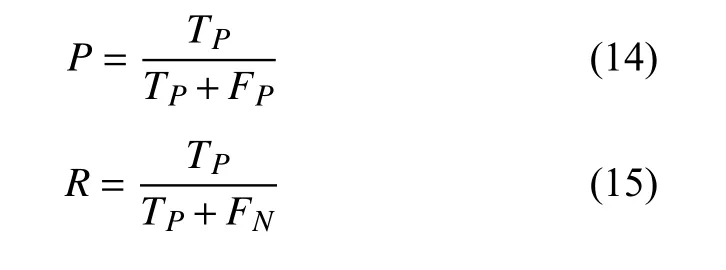

为了证明本文提出的模型的有效性, 本文使用了多种模型的对比实验来说明本文提出方法的有效性,实验中, 我们分别对比了卷积神经网络中的膨胀卷积方法[14], 循环神经网络中的长短期记忆网络和双向长短期记忆网络[15], 原始Transformer 模型与本文提出的CB-BRTC 模型. 对比试验的结果如表2 所示.
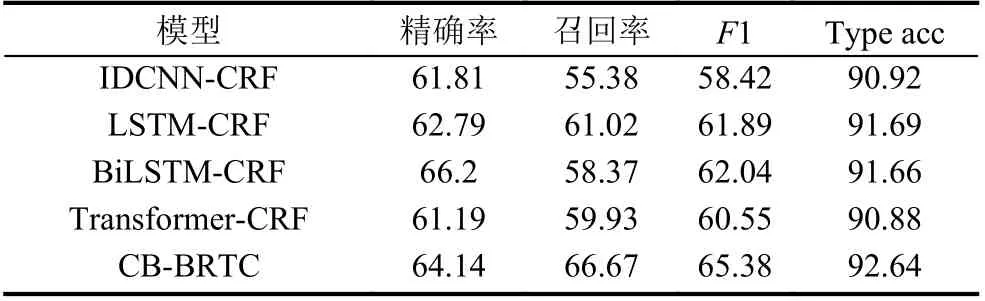
表2 对比实验结果 (%)
从表2 中可以看出, 本文提出的模型算法流程充分利用了输入的特征, 并具有高效的特征提取能力, 长短期记忆网络在一定程度上优于卷积神经网络, 因为其具有捕捉序列的长程依赖的能力, 原版的Transformer模型难以直接捕捉到序列的先后关系, 从而效果并不如长短期记忆网络. 通过引入相对位置编码, 本文提出的基于字符特征和二元词组特征的模型, 利用BERT构建符合上下语义的词嵌入表示, 并使用相对位置编码的Transformer 模型得到序列中有方向感知的文本序列编码, 最后通过条件随机场解码, 取得了优于其他模型的效果, 在同样使用一层网络结构来对电力政策文本进行命名实体识别任务时, 本文提出的模型取得了最优的效果, 拥有比IDCNN 方法高出6.96%的F1值, 比长短期记忆网络方法高出3.49%的F1 值, 比原型Transformer 高4.83%的F1 值.
本文利用字符和二元词组特征来作为神经网络的输入, 由于中文缺少像英文文本中的空格边界, 所以中文命名实体识别多采用字符特征来作为模型的输入,而由于中文的语言习惯, 多为两字成词, 所以二元词组是实体中较为重要的特征, 本文融入这两种特征作为输入, 对命名实体识别的效果是有帮助的. 将字符特征和二元词组特征融合后通过BERT 预训练神经网络,可以将预训练神经网络中通过自监督训练得到的符合语义表示的字向量和词向量的高效表示迁移到本任务所使用的字符上. 利用增加了相对位置编码的Transformer神经网络捕捉针对命名实体识别在不同语义空间的特征表达, 拥有比绝对位置编码的Transformer 更好的方向感知. 最后使用机器学习中经典的条件随机场算法来捕捉标签的发射概率和转移概率, 从而减少差错, 得到更加合理的标签序列表达.
3.3 BERT 使用探究
目前现存的BERT 使用方法有两种, 一是使用BERT当作特征, 固定参数, 不参与训练, 只训练Transformer和条件随机场的参数, 另一种是在BERT 上做精调, 将BERT 的参数也做训练. 本节主要探究了这两种不同方式之间的差异. 效果之间的不同如表3 所示.

表3 是否精调BERT 模型结果 (%)
在利用Transformer 网络进行BERT 的精调探究,实验结果表示精调的结果要比不精调效果更好, 精调是为了在通用语义表示的基础上, 根据命名实体任务的特性进行领域适配, 使BERT 模型与命名实体识别更加适配, 得到更加高效的电力行业规章制度文本表达, 这样的文本表达对识别命名实体有着更好的表达,本文在探究BERT 的使用方法中, 我们使用了更加细致的实验用来增强模型对电力命名实体识别的效果,采用冻结和解冻的策略来反映BERT 预训练模型对命名实体识别的促进作用, 冻结是指在训练的过程中,BERT 模型的参数不参与梯度下降算法进行迭代更新,解冻之后, 随着模型一起更新, 结果如表4 所示.
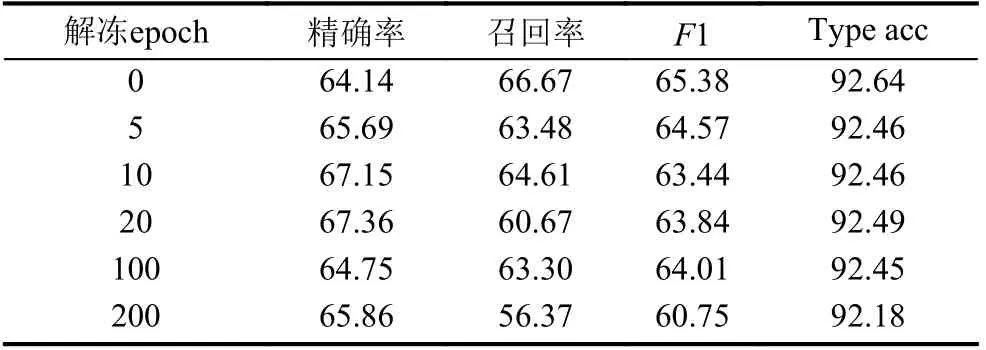
表4 冻结解冻BERT 参数 (%)
实验结果表明使用BERT 作为词嵌入层, 在一开始就解冻的策略是该模型进行命名实体识别任务最有效的策略. 经过使用不同超参数调试, 我们设置具有BERT 学习参数为相对位置编码的Transformer 学习率的0.04 倍, 用来避免精调BERT 所导致预训练模型的灾难性遗忘的现象[16].
在利用BERT 进行模型的实验分析中, 本文对于电力行业规章制度的标注文本中的实体进行识别, 并探究了不同类型实体识别的效果, 分别采用精确率, 召回率和F1 值3 种评价指标. 精调的实验结果如表5 所示.
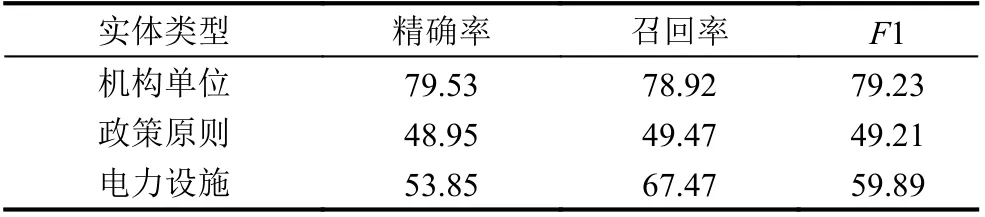
表5 不同实体类别识别结果 (%)
实验结果表明模型对于机构单位的实体识别效果最好,F1 值为79.23%, 机构单位的识别效果最好的原因可能是由于电力内部企业数量固定, 且政策中反复提及的电网机构单位模型更容易判断. 政策原则的识别效果最差,F1 值为49.21%, 导致政策原则识别效果差的原因可能是因为实体类型过长, 并且政策原则种类繁多, 模型不能在有限的数据中得到很好的训练.
3.4 消融实验
为了探究本文所提出的方法中每个部分对电力政策文本进行命名实体识别的作用, 本节对CB-BRTC 模型进行了消融实验, 分别通过去除二元词组特征, 去除BERT 词嵌入层和去除Transformer 中的相对位置编码信息的实验来探究每个模块对模型的作用, 实验结果如表6 所示.
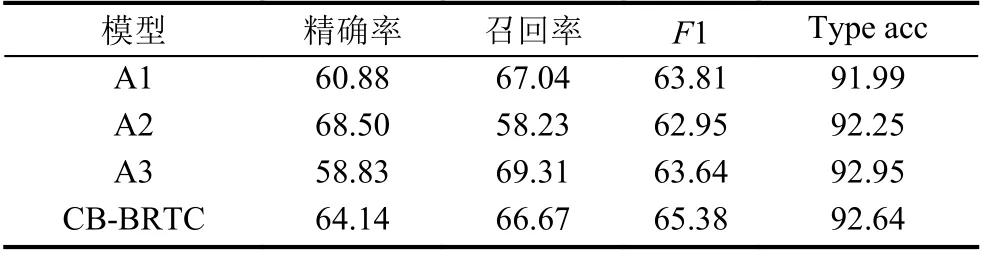
表6 消融实验结果 (%)
表6 中, A1 表示整个模型去除BERT 后使用Word2-Vec 在中文语料上的预训练词向量输入相对位置编码的Transformer, 然后将编码结构的输出再通过条件随机场, A2 表示整个模型去除二元词组特征后通过BERT来构建词嵌入, 然后利用相对位置编码的Transformer对序列进行编码, 最后将编码的结果通过条件随机场,A3 表示模型去除Transformer 中的相对位置编码, 替换为绝对位置编码, 通过使用BERT 构建序列的词嵌入, 通过绝对位置编码的Transformer 后将输出送入条件随机场. 表6 的结果表明, 去除二元词组特征后的模型对电力政策文本的命名实体识别效果最差,F1 值为62.95%, 并且当去除本文所提出模型中的任何一部分都会对模型的效果造成损伤. 这一实验结果说明本文使用字符混合二元词组作为特征, 将BERT作为词嵌入层, 利用相对位置编码的Transformer 结构, 使用条件随机场作为解码输出, 对电力行业文本的命名实体识别效果有显著的效果.
4 结论与展望
本文提出了一种新颖的神经网络模型CB-BRTC模型来对电网企业的规章制度等文件进行信息提取,识别出非结构化文本中的命名实体. 模型使用字符级别的向量和二元词组特征作为输入, 使用改进Transformer的结构作为编码器结构, 引入相对位置编码使得Transformer 具有方向感知的功能, 最后使用条件随机场捕捉标签之间的转移概率和发射概率, 使得序列标注更合理. 本文提出的方法在电力行业规章制度上均比传统神经网络方法取得了更好的实体识别效果. 本文的方法可以促进将电力行业数据进行有效的组织管理, 通过进一步的结构化构建电力行业知识图谱, 不仅进一步加快电力企业数字化转型步伐, 也可以推动电力企业发掘新的利润增长点. 不过对于行业内的命名实体效果仍难以达到通用领域非常高的识别率, 找到更有效率的神经网络模型来促进行业数字资产管理,这也是我们下一步工作的方向.
