结合可信度的km-means 算法①
2022-06-29熊君竹何振峰
熊君竹, 何振峰
(福州大学 计算机与大数据学院, 福州 350108)
聚类是一种无监督学习方法, 它基于给定的相似性评价措施将数据集划分成若干簇, 使得在同一个簇中的对象彼此具有高相似性, 处于不同簇中的对象具有低相似性[1]. 聚类被广泛应用在许多领域, 如机器学习、模式识别等[2]. 对于传统的聚类算法, 属性值的缺失导致部分实例之间的距离无法有效的度量, 所以不能直接应用到不完整的数据集上. 因此, 在不完整数据集上的聚类研究是非常有意义的.
目前针对不完整数据的处理, 主要采用以下方法:(1) 在聚类之前直接删除包含缺失值的实例, 尽管它很简单, 但是当缺失比例较小时, 删除是非常有效的方法[3].(2) 对缺失的数据集进行填充, 通过填充的方式获取完整的数据集, 然后使用传统聚类算法进行聚类分析, 算法的性能往往受限于预估填充值的准确性[4]. (3) 在聚类过程中采用非填充的方式, 在聚类之前没有对缺失部分进行填充处理, 而是在不完整状态下减少缺失值对聚类过程的影响. 如利用数据包含的背景知识, 通过在实例之间添加少量“软约束”[5]引导包含缺失值的实例进行簇的划分, 减少数据填充过程中不可靠的填充值对聚类的影响.
针对不同的问题, 研究人员提出了多种结合不完整数据的聚类算法. 文献[6]提出一种删除策略, 当数据集缺失比例较小时, 一般小于10%, 直接将包含缺失值的实例删除, 数据缺失比例较小时, 对于最终的聚类分析结果不会产生较大的影响. 文献[7] 提出K-Pod 算法, 采用迭代填充的方式处理不完整数据, 填充的过程中使用期望最大化算法(expectation maximization)预估缺失属性值, 每一次迭代过程中使用K-means 对填充后的实例进行标记, 直到算法收敛, 但是迭代过程中重复使用K-means 方法进行更新, 消耗了大量时间. 文献[5]提出SLIM 算法, 在聚类过程中添加基于距离的成对约束, 引导包含缺失值的实例进行簇的划分. 文献[8]提出km-means 算法, 该算法将缺失值的处理结合到聚类过程中, 通过调整局部距离计算方式, 减少实例中缺失值对目标函数的影响.
km-means 是对K-means 的扩展, 仍然受到K-means算法固有缺陷的限制[9]. 该算法采用K-means++[10]的初始化方式获取k个聚类中心, 使得中心之间距离尽可能的大. 由于缺失值的存在, 导致聚类中心的可靠性存在较大的不确定性. 主要表现在两方面: 直接不确定性和间接不确定性. 初始化过程中选择的聚类中心, 在标记阶段引导簇的划分起到十分关键的作用, 所以增大初始化阶段选取聚类中心的可靠性研究具有重要意义.
可信度来源于He 在EKM 算法[11]中, 描述成对约束在簇划分过程中的满足度, 即某个簇中, 实例的划分结果满足成对约束的个数占成对约束总个数的比例.EKM 算法中认为满足度高, 则该簇可信度高; 满足度低, 则该簇的可信度低. 因此, 受He 工作的启发, 为了描述不完整数据集中实例之间距离的可信度, 结合实例的完整性, 本文将实例中属性值的完整性称为实例可信度, 实例中缺失值的比例越小, 则计算出的局部距离可信度的越高; 反之, 实例中缺失值比例越高, 则计算出的局部距离可信度的越低.
为了解决km-means 初始化阶段选取聚类中心的可靠性问题, 本文在初始化过程中引入可信度, 通过可信度调整距离的计算, 减小选取聚类中心的直接不确定性, 增大初始化完成后选取聚类中心的可靠性, 使得聚类中心能够更好地引导标记阶段的簇划分. 本文第1 节介绍不完整数据的缺失机制和符号定义, 第2 节介绍km-means 算法, 第3 节介绍改进的km-means 算法,第4 节先对初始化阶段选取聚类中心的可靠性问题进行实验与分析说明, 然后对改进后的km-means 进行实验并分析结果, 第5 节对所做的工作进行总结.
1 不完整数据集
1.1 不完整数据的缺失机制
不完整数据的缺失机制[12]有3 种不同的类型. 完全随机缺失, 是指缺失部分独立于本身, 与数据集的其他属性无关; 随机缺失, 是指缺失部分独立于本身, 与数据集中其他属性有关; 非随机不可忽略缺失, 是指缺失部分与本身有关, 与数据集中的其他属性也有关. 完全随机缺失和随机缺失被称作可忽略缺失, 目前处理不完整数据集主要针对可忽略缺失.
1.2 符号定义
现有文献中有许多关于缺失度(missing rate)[12,13]的定义. 本文采用属性值缺失度和实例缺失度, 从不同维度描述缺失程度. 属性值缺失度衡量数据集中缺失的属性值比例, 实例缺失度衡量含有缺失属性值的实例比例.
设数据集D={X1,X2,···,Xn}∈Rn×p,n是数据集D的规模,p是属性个数.Xi的部分属性值可能会出现缺失, 用?表示缺失值. 假设Y={Y1,Y2,···,Yn}是一个p维的缺省信息矩阵,Yi的第j个属性Yij=I(Xijis recorded),Xij是Xi的第j个属性,I(·)是一个指示函数, 当自变量为真时为1, 否则为0.

定义2. 实例缺失度(instance missing rate,IMR).设D中含有缺失属性值的实例个数为ni, 则数据集D的实例缺失度为IMR=ni/n.
在不完整数据集中, 属性值缺失度和实例缺失度描述数据集的整体缺失程度.
2 km-means 算法简介
km-means 算法又被称为结合不完整数据集处理的K-means 类型算法, 在Hartigan 等人[14]提出的K-means算法框架基础上改进, 使其能够高效的结合缺失值的处理. 该算法的主要思想是: 通过修正实例与聚类中心之间的相似性度量方式, 将缺失值的处理结合到算法中, 减少实例中的缺失值对目标函数的影响, 使得算法准确度有不错的提升.
给定数据集D={X1,X2,···,Xn}∈Rn×p. 假设K是已知的, 算法的目标寻找划分集C={C1,C2,···,CK}和聚类中心µ={µ1,µ2, ···,µK}, 优化目标是使得每个实例到它所在聚类中心的距离总和最小, 优化目标函数如式(1):
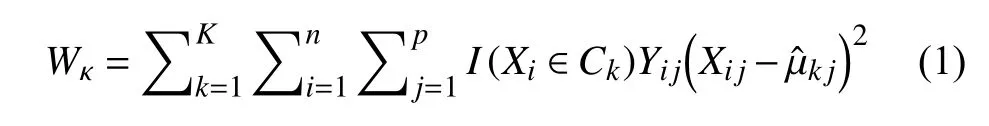
对于每一个划分集合C, 聚类中心的更新如式(2):


算法1. km-means 算法输入: 数据集D, 聚类数K C={C1,C2,···,CK}µ={µ1,µ2,···,µK}输出: 聚类簇的划分, 聚类中心1)采用算法2 初始化得到K 个簇中心, {ˆµ(0)k ;k=1,2,···,K}1 ,ξ(0)2 ,···,ξ(0)n }2)采用式(6)初始化每一个实例的所属簇, ξ(0)={ξ(0)3)初始化活动集和迭代次数L≠∅L={1,2,···,K}t=0 4) while do Xi∈D 5) for each Xik=ξ(t)Δ−k,i 6) 获取距离 最近的簇, 采用式(4)计算 . // t 表示迭代i次数7) if k∈L l=argminb≠kΔ+b,i 8) 计算9) else l=argminb∈LΔ+b,i 10) 计算Δ+l,i<Δ−k,i 11) if 12) 将 从 移入 , 更新XiCkClξ(t+1)i=l kˆµ(t+1)lk lL 13) 采用式(2)更新聚类中心和, 并将和放入 中ˆµ(t+1)14) else XiCkξ(t+1)i=ξ(t)i 15) 仍属于 , 设置16) end for L 17) 从 中移除本轮迭代过程中没有更新的簇索引, 更新迭代次数t=t+1 18) end while

算法2. KMIWMD 算法输入: 数据集D, 聚类数量K输出: K 个聚类中心1) 随机选取作为第1 个聚类中心|µ|<Kµ←ˆµ1 =Xi 2) while do // |·|表示集合的个数proi=d2i/∑ny=1 d2y,i∈{1,2,···,n}3) 计算概率4) 通过概率选取第k 个(k=2, 3, …, K)聚类中心µ←µ∪ˆµk proiˆµk 5) 6) end while

在KMIWMD 算法初始化完成后, 选取的聚类中心存在不可靠性, 这种不可靠性具体表现在两方面:(1) 直接不确定性, 被选为簇中心的实例存在缺失值时,它所处的空间位置并不确定, 在缺省值被填充为某些值时, 它不适合作为簇中心. (2) 间接不确定性, 在度量实例之间的距离时, 由于缺失值的存在, 可能出现原本距离较近的实例, 得出的距离较大, 导致相距较远的实例不会被选作下一个聚类中心, 如图1 所示. 我们将其他包含缺失值的实例, 导致聚类中心的不确定性称作间接不确定性. 上述两种不确定性会导致聚类中心在标记阶段对簇的划分产生错误的引导, 容易陷入局部最优解.
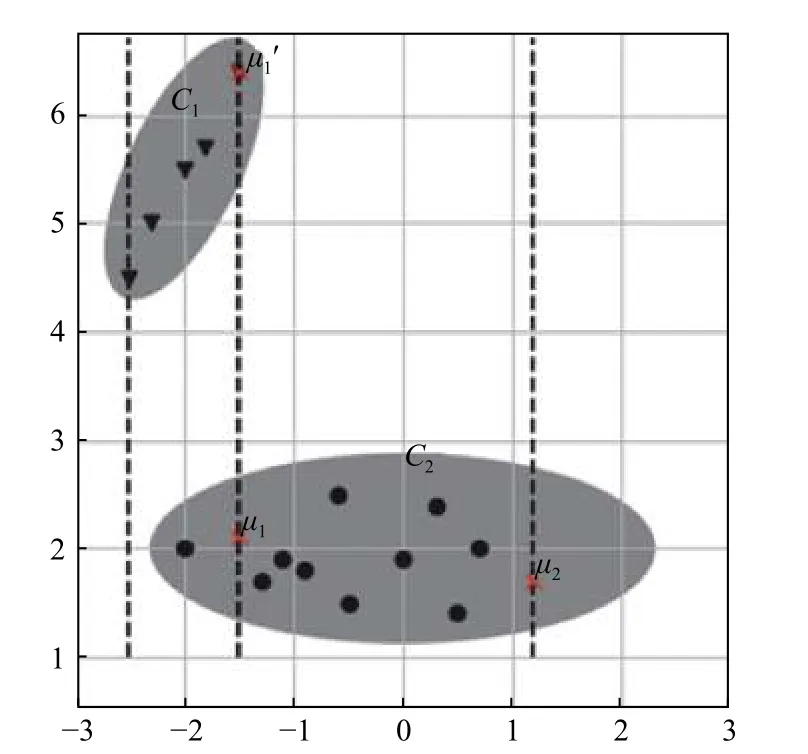
图1 不可靠的聚类中心影响示意图
如图1 所示, 存在两个大小不同的簇C1和C2, 假设使用KMIWMD 初始化选择的第一个聚类中心 µ1. 当µ1=(−1.5,?)存在缺失值时, 由于缺失值的存在, 导致原本二维平面上的点与点之间的距离变成了点与直线之间的距离, 即其他实例到 µ1的距离变成了到直线x=–1.5 的距离. 此时 µ2与直线x=–1.5 距离最远, 由算法2 中的步骤(3) 计算得, 概率pro2最大, 所以选择µ2为下一个聚类中心. 由图1 可知此时选择的两个聚类中心均在簇C2中, 这会导致在接下来的实例标记过程中, 初始中心无法有效的引导簇的划分. 当µ1=(−1.5,2.1)不存在缺失值时, 距离 µ1最远的实例为 µ1′,通过计算可知pro1′最大, µ1′作为下一个聚类中心. 因为 µ1′和 µ1分布在不同的簇中, 所以和 µ2相比 µ1′是一个更好的聚类中心. 上述过程中, 我们将 µ1是否包含缺失值称作直接不确定性; 将 µ1存在缺失值时, 导致选取下一个聚类中心的发生变化称作间接不确定性. 针对上述存在的问题, 我们将在第3 节讨论解决方案.
3 结合可信度的km-means 聚类算法
针对km-means 算法初始化(KMIWMD 算法)过程中, 选取聚类中心的不可靠性问题, 受He 等人的工作启发[11,15], 本文在式(7)的计算过程中引入可信度, 如定义3 和定义4, 通过可信度优化不完整数据集的初始化过程, 减少初始化完成后, 多个聚类中心位于同一个簇中, 使得聚类中心能够更好地引导簇的划分. 结合式(7)和可信度, 推出新的结合缺失值处理的初始化方式,式(8)为结合实例可信度的距离计算, 当实例Xi中存在缺失值, 即ICi<1, 在计算实例与聚类中心之间的距离时, 实例可信度通过减少该实例被选做下一个聚类中心的概率proi, 尽量保证选取较完整的实例作为下一个聚类中心, 从而增大选取聚类中心可靠性. 式(9)为结合公共属性可信度的距离计算, 式(9)与公共属性可信度的结合方式和式(8)类似.

在不完整数据集中, 实例可信度描述单个实例的缺失程度, 实例可信度越小, 表示该实例包含缺失属性值越多, 实例越不可信. 公共属性可信度描述任意两个实例之间, 同一个属性均未缺失的属性值比例, 公共属性可信度越小, 表示两个实例之间公共缺失的属性值越多, 实例越不可信.
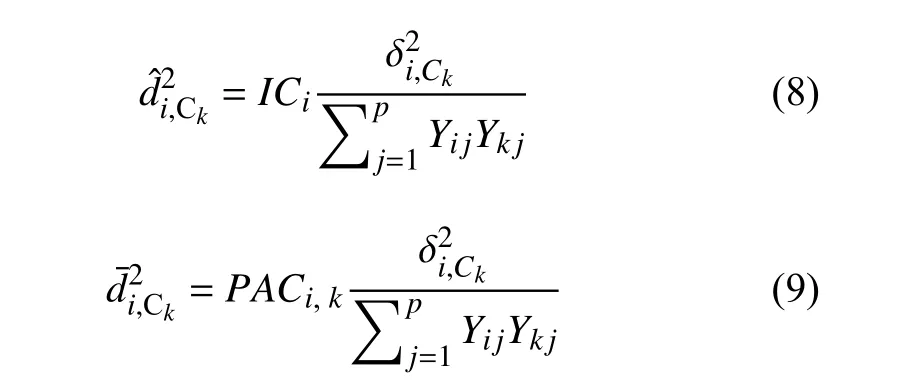
式(8) 中的ICi表示Xi的实例可信度, 式(9) 中的PACi,k表示Xi与Ck的公共属性可信度. 结合上文对算法2 的分析与改进, 本文提出优化后的KMIWMD 算法, 即结合可信度的不完整数据集聚类中心初始化算法, 记作KMIWMD++, 具体的流程如算法3 所示.

算法3. KMIWMD++算法输入: 数据集D, 聚类数K, 可信度阈值输出: K 个聚类中心θ′1) 采用定义3 计算各个实例µ←ˆµ1 =XiICi>θ′2) 随机选取作为第一个聚类中心, 其中, IC={IC1,IC2,···,ICn}3) while do // ||表示集合的个数d2i=minl=1,2,···,k−1 ˆd2i,Cl 4) 使用式(8)计算|µ|<K/∑ny=1 d2y,i∈{1,2,···,n}5) 计算概率proiˆµk proi=d2i 6) 通过概率选取第k 个(k=2, 3, …, K)聚类中心µ←µ∪ˆµk 7) 8) end while
步骤(4)中我们可以使用式(8)或式(9)结合不同的可信度, 调整初始化过程中的距离计算. KMIWND++算法确定下一个聚类中心的时, 在局部距离计算的过程中引入可信度(实例可信度或公共属性可信度), 步骤(2)中通过实例可信度选择包含较完整信息的实例作为第一个聚类中心, 减小簇中心包含缺失值对第k(k=2, 3, …,K)个中心选取的影响. 步骤(4)、步骤(5)通过实例可信度(或者公共属性可信度)调整距离计算, 减少包含缺失值的实例被选作下一个中心的概率,尽可能地减少直接不确定性对中心选取的影响, 使得初始化完成后多个中心分布在不同的簇中. 最后, 本文将使用算法3 初始化的算法1 称作KMMC (km-means with credibility), 接下来在第4 节通过实验分析对比km-means 和KMMC 在结合不完整数据集的处理效果.
4 实验与分析
如表1 所示, 实验阶段使用7 个UCI 数据集和3 个UCR 数据集. Seeds, Ceramic, Wine, Wdbc, CCBR,Iris 和Column 来自于UCI 数据集. Plane, CBF 和Trace来自于UCR 数据集. Wdbc 表示的是Breast Cancer Wisconsin (Diagnostic)数据集, CCBR 表示Cervical Cancer Behavior Risk 数据集, Ceramic 表示Chemical Composition of Ceramic Samples 数据集, Column 表示的是Vertebral Column 数据集. 每组数据都采用了ZScore 标准化.
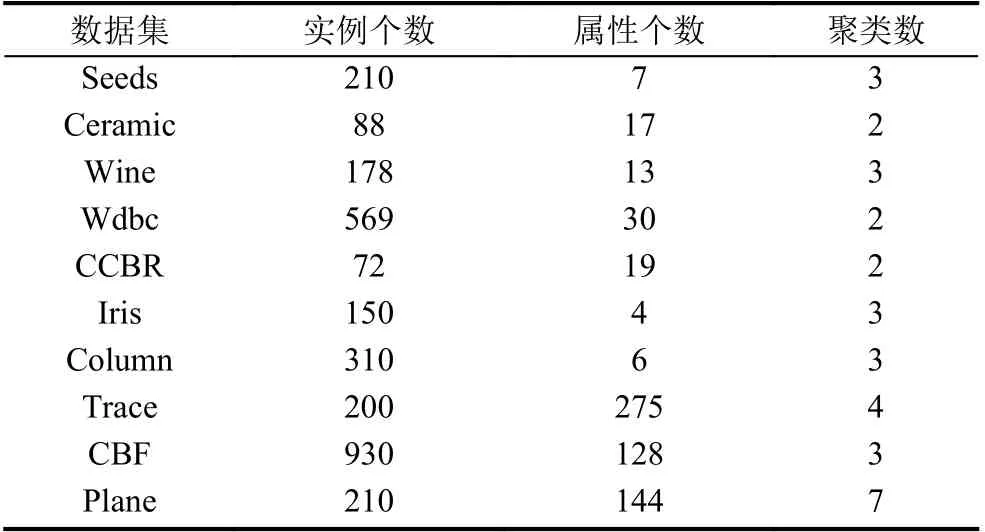
表1 数据集信息
本文对实验需要的缺失数据集进行如下处理, 构建随机缺失机制下的不完整数据集. 在完整数据集基础上, 分别构建不同实例缺失度(IMR)的不完整数据集, 构建过程中分别取IMR为0、10%和20%. 首先通过随机数发生器在n个实例中随机选取miss=IMR×n个实例作为缺失部分, 然后通过随机数发生器依次在miss个实例中随机选取m个属性, 将该属性对应的值设置为空值, 每个实例的随机种子为该实例在数据集中的序号, 最后将miss个包含缺失值的部分和n–miss个完整部分组合成实验所需的不完整数据集. 公共属性可信度存在为0 的情况, 如X1=(?,?,6),X2=(1,5,?),此时PAC1,2=0, 为了避免这种情况, 构建过程中保证每个实例中属性值缺失的个数m
第一组实验, 如表2 和表3 所示, 通过实验分析KMIWMD (算法2)和KMIWMD++ (算法3)初始化完成后聚类中心包含缺失值的情况和初始完成后聚类中心出现在同一个簇中的情况, 其中算法2 为km-means算法中的初始化聚类中心部分.
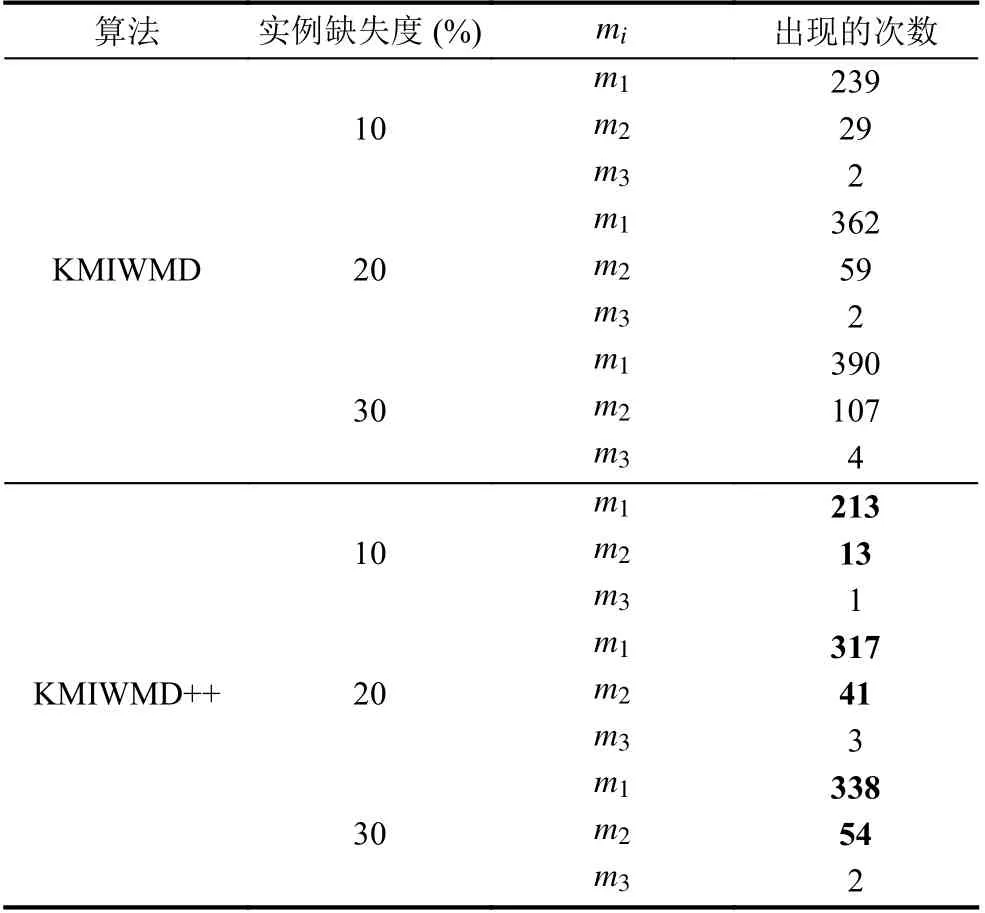
表2 算法2 与算法3 初始化完成后聚类中心包含缺失值的情况
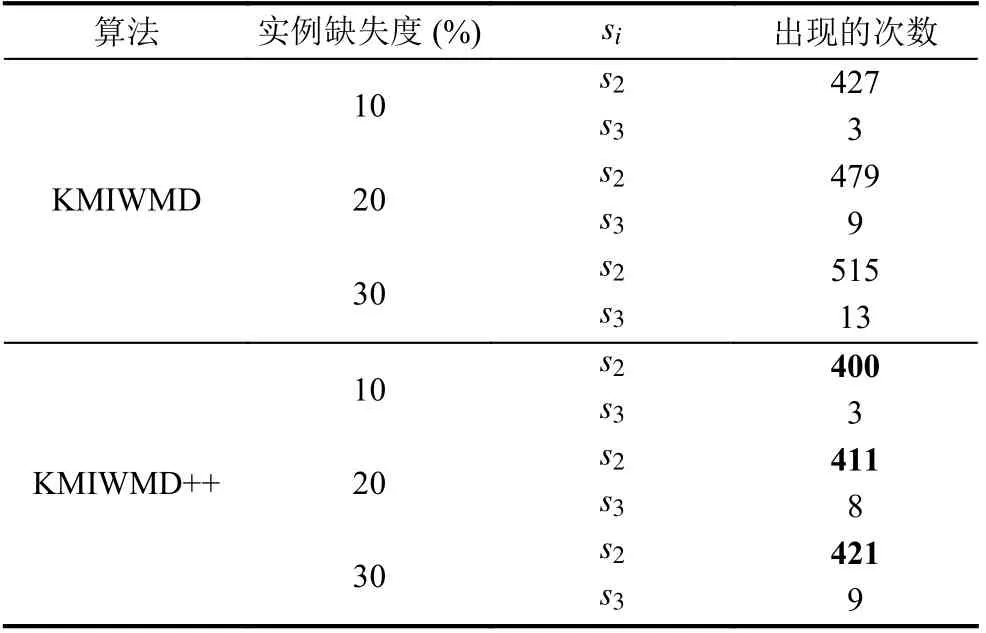
表3 算法2 与算法3 初始化聚类中心完成后聚类中心在同一个簇中的情况
第2 组实验, 如表4 所示, 通过实验对比km-means算法结合不同的聚类中心初始化算法(算法2 和算法3)对聚类准确度的影响.
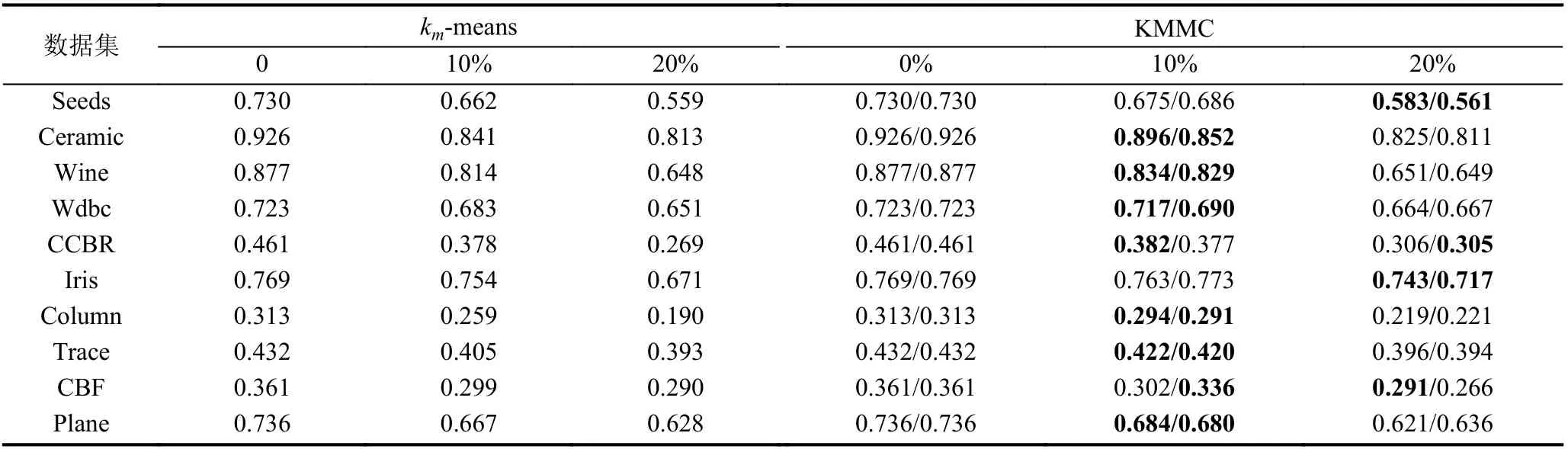
表4 KMMC 和km-means 算法ARI 系数对比
表2 和表3 分别表示对Iris 数据集, 采用KMIWMD和KMIWMD++算法进行1 000 次实验, 初始化完成后选取的聚类中心包含缺失值的次数和聚类中心在同一个簇中的次数(表2 和表3 中的数据统计在同一组实验中完成). 表2 中的mi(i=1,2,···,k)表示选择k个聚类中心包含缺失值的次数, 如m1=239表示1 000 次实验中, 选取的k聚类中心里有1 个聚类中心包含缺失值出现239 次, 表3 中si(i=2,3,···,k)表示选择的k个聚类中心在同一个簇中的次数, 如s3=8表示1 000 次试验中, 选取的k聚类中心有3 个聚类中心在同一个簇中出现了8 次.

表4 是KMMC 与km-means 对比实验结果, KMMC算法中每一行两个值分别表示采用实例可信度和公共属性可信度优化的实验结果. 从实验数据分析可知, 当数据集不存在缺失值时, 通过定义3 和定义4 可知, 实例可信度ICi≡1,∀i∈(1,n), 公共属性可信度PACi,k≡1,∀i,k∈(1,n),i≠k, 文中引入的可信度对于KMMC 算法与km-means 算法初始化聚类中心不存在影响, 所以表4中KMMC 算法与km-means 算法在完整数据集的情况下ARI 值均相等. 在相同的缺失机制和实例缺失度的情况下, KMMC 的ARI 值普遍要比km-means 的值要高, 说明了减少初始化中心的直接不确定性, 即减少包含缺失属性值的实例作为初始样本中心, 可以提高结合缺失值处理的聚类算法性能. 但是在高维数据集(CBF), 传统的距离度量方式难以准确找出实例之间的差异性, 导致聚类效果不佳; 同样, 在Trace 数据集上,当实例缺失度为20%时, 优化初始中对聚类结果几乎没有提升. 在高维数据集中随着实例缺失度增大, 通过优化初始化聚类中心, 无法有效的改善聚类准确度.
5 总结与展望
针对不完整数据集初始化聚类中心问题, 提出了结合可信度的不完整数据集聚类算法KMMC, 将实例可信度和公共属性可信度运用到聚类中心初始化过程中, 减少实例中属性值的缺失对实例之间距离度量的影响, 增大初始化阶段选取聚类中心的可靠性. 通过可信度调整距离计算, 有效减少了簇划分过程中, 不可靠的聚类中心对实例标记阶段产生的错误引导. 最后, 通过UCI 和UCR 数据集对比KMMC 与km-means 算法的聚类准确度, 实验结果表明, 改进初始化聚类中心的KMMC 算法的准确度优于km-means 算法, 验证了KMMC 算法的有效性. 未来工作将致力于如何在不完整数据集上引入成对约束, 引导聚类过程中的簇划分,减少不完整数据对实例标记阶段的影响.
