基于关键词生成的网格事件相似度并行计算①
2022-06-29陈健鹏佘祥荣秦加奇
陈 钢, 陈健鹏, 佘祥荣, 秦加奇, 陈 剑
(长三角信息智能创新研究院, 芜湖 241060)
社会治理网格化将城市按照一定标准划分成一系列网格单元, 网格化系统所沉淀的海量事件数据能够全面、及时地反映城市问题. 在城市应急管理中, 基于历史网格事件库的案例推理[1]对于科学救援、精准决策具有重要意义. 事件检索是案例推理的关键步骤, 通过在网格事件库中检索出与目标事件相似的历史事件(集), 进而辅助目标事件的处置决策. 网格事件库中的数据量越庞大, 经验积累越充分, 对决策支持的力度也越大. 从相似的事件处置中得到经验性的知识, 必须在合理时间内在网格事件库中找到相似事件[2]. 因此, 高性能网格事件相似度计算决定了案例推理的效用. 近年来, 图形处理单元(graphics processing unit, GPU)在硬件架构上取得了长足的进步. 片上运算单元密集、存储带宽高效等特点使得GPU 非常适用于数据相关性较低的大规模并行计算. 事件相似度计算对大量事件数据进行相同处理, 其中蕴含丰富的数据并行性, 适合在GPU 上加速执行[3].
事件关键词提取大多数通过TF-IDF 提取候选关键词, 利用Word2Vec 计算词向量, 并采用特征工程对候选关键词进行特征提取, 再经由支持向量机、决策树等算法将关键词提取转换为二分类问题[4]. 这种方法需要做大量的特征工程, 特征的选取和分析方式复杂,还可能会造成前端特征与后端任务的脱节. 此外, 词向量加机器学习的方法仅能够基于给定的事件文本提取关键词, 无法挖掘网格事件中蕴含的重要特征. 指针生成网络(pointer-generator network, PGN)结合了传统Seq2Seq 模型和指针网络的优势, 在生成新词的同时也具备了从原文复制单词的能力, 允许模型从源文本中复制词用作生成词来解决词表无法覆盖(out of vocabulary,OOV)的问题, 并引入了覆盖机制以改善生成新词时的重复问题, 提高模型的表达能力[5]. 为了在海量网格事件库中快速、准确地检索事件, 本文提出一种基于关键词生成的网格事件相似度并行计算方法, 具体创新点如下:
(1) 引入记忆网络(memory network)对基于LSTM网络的PGN 进行改进, 用以增强其记忆能力;
(2) 针对GPU 体系结构特点, 对LSTM 网络的计算过程进行优化;
(3) 提出基于历史相似事件的先验知识来计算事件相似度阈值的方法;
(4) 通过实验证明本文网格事件相似度技术方法的有效性.
1 相关研究
文献[6]设计了一种基于网格事件大数据汇总共享、通过数据梳理及案例推理技术实现科学决策的方法, 并基于这一方法设计了网格化管理辅助决策支持系统. 文献[7]通过文本分词、特征词提取、基于情景相似度的突发事件情报感知方法, 结合当前事件演化态势和以往的经验性知识实现对突发事件的识别和预判. 文献[8]在传统词嵌入模型中增加了Ngram 和汉字语义信息并与知网融合, 在此基础上将WNCH 方法应用到文本属性相似度的计算. 文献[9]通过扩展Needleman-Wunsch 算法的得分函数以结合时间、空间信息, 通过粒度调控实现了从不同的粒度来计算时空事件序列的相似度. 文献[10]对突发事件进行情景要素分解, 引入支持向量机和相似度算法, 基于粒度原理构建了一种融合情景的动态响应模型. 文献[11]提出一种融合句法特征和句法相似度的网络舆情突发事件识别方法. 文献[12]提出了食品安全事件的多层多级语义结构排序策略算法, 计算食品安全数据与语义结构模板的相似度, 确定其综合得分, 选择适当的阈值确定食品安全事件精度.
尽管上述方法能够较好地完成案例检索, 但案例检索的事件相似度计算方面存在局限性, 大多数研究基于案例的数值属性、模糊属性、符号属性进行事件之间的相似度计算, 忽略了事件的文本属性, 如事件原因、事件摘要等, 这些属性对于案例检索都是不可或缺的[13]. PGN 主要解决传统Seq2Seq 模型中输出严重依赖输入的问题, 突破了模型输出端对词汇表长度的限制, 在摘要生成任务中具有良好的表现. 文献[14]针对生成式文本摘要应用场景, 提出了以Transformer 为基础的摘要模型, 并在Transformer 模型中加入了指针生成网络和覆盖损失进行优化. 文献[15]针对代码注释自动生成引入指针生成网络模块, 在解码的每一步实现生成词和复制词两种模式的自动切换, 以此解决无法生成OOV 词的问题.
2 网格事件相似度计算
网格事件可以分为城市管理、环境保护、物业管理、平安建设、应急突发事件等类型, 包括基本属性(事件标题、等级、类别, 发生地点、发送时间等信息)和情景属性(事件原因、对象、发生环境、应对任务等信息). 在计算事件相似度之前, 需要生成事件关键词以确定该事件的基本属性和情景属性.
2.1 关键词生成
长短期记忆网络(long short-term memory, LSTM)是在循环神经网络(recurrent neural network, RNN)基础上改进而来的一种神经网络模型, 可以解决长期依赖问题. LSTM 神经网络使用输入门、忘记门和输出门3 种门结构以保持和更新细胞中信息的增减. 然而,单向LSTM 只能处理一个方向上的信息, 无法处理另外一个方向上的信息, 双向LSTM (bidirectional LSTM,BiLSMT)通过双向语义编码结构获取上下文信息, 能够更好地对网格事件信息进行提取[16], 而注意力机制(attention)可以更深层次地挖掘网格事件不同类型的关键词. 本文提出的基于PGN 的网格事件关键词生成模型如图1 所示.
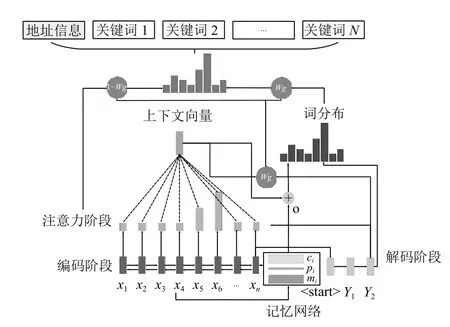
图1 基于指针生成网络的关键词生成
2.1.1 编码器
在网格事件特征提取中, 当前时间步长的隐藏状态与前一时刻和下一时刻相关联. BiLSTM 使用两个不同方向的LSTM 分别从网格事件文本的前端和后端进行遍历, 利用两个并行通道, 既能获得正向的累积依赖信息, 又能获得反向的未来的累积依赖信息, 提取的特征信息更加丰富. 因此, 编码器部分采用BiLSTM 网络, 如图2 所示.
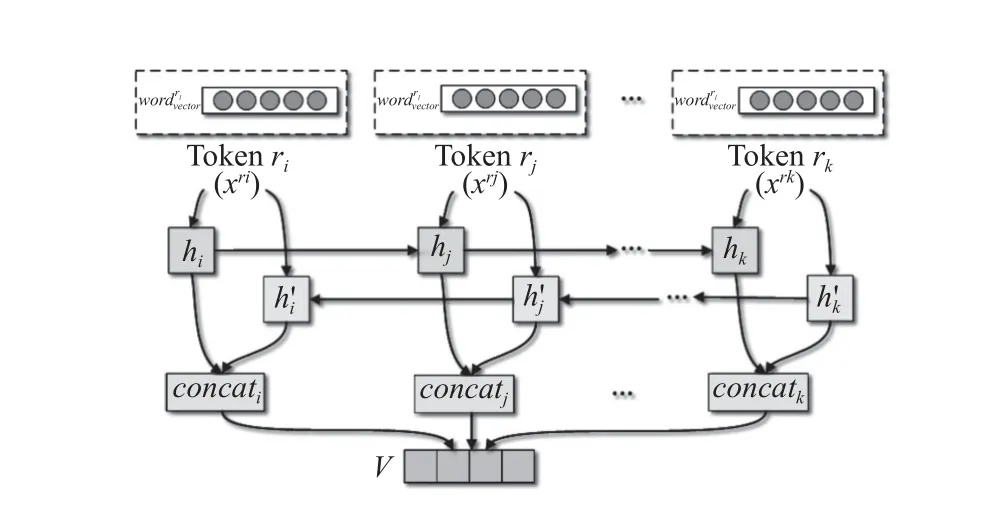
图2 BiLSTM 结构
对于网格事件候选词序列X={x1,x2,···,xn} (n为输入序列的长度), 按照顺序先输入到Embedding 层,将候选词映射到高维向量上, 然后再将处理好的序列输入到编码器中, 得到每个序列的隐藏状态集合E={e1,e2,···,en}. 对第i个隐藏状态ei来说, 由于采用的是Bi-LSTM 网络, 算法会从前往后和从后往前两个方向计算, 得到的隐藏状态ei会充分关联上下文信息.BiLSTM 计算过程如式(1)到式(6)所示. 首先, 遗忘门根据上一个记忆单元的输出ht–1和输入数据xt产生一个0–1 之间的数值ft来决定上一个长期状态Ct–1中信息丢失多少.ht–1和xt通过输入门确定更新信息得到it, 同时通过一个tanh 层得到新的候选记忆单元信息C't. 通过遗忘门和输入门的操作, 将上一个长期状态Ct–1更新为Ct. 最后, 由输出门得到判断条件, 然后通过一个tanh 层得到一个(–1, 1)之间的值ot, 该值与判断条件相乘来决定输出当前记忆单元的哪些状态特征.
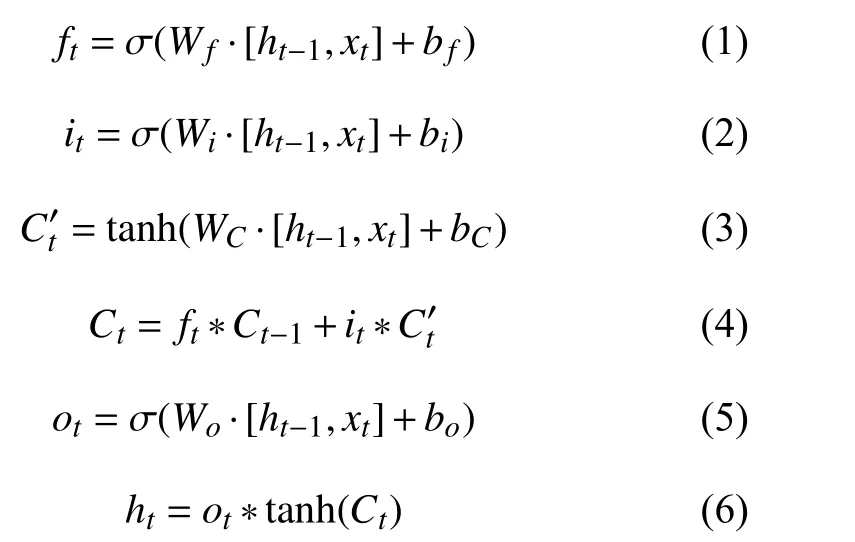
2.1.2 解码器

其中,ct是先前时间步的注意力权重叠加后得到的覆盖向量. 对上下文向量ut进行Softmax激活函数操作后, 得到的结果视为在输入序列元素上的概率分布, 其中vT、W1、W2、Wc和b是模型学习参数.
PGN 使用LSTM 作为编码器和解码器, 但LSTM的隐藏状态记忆存储能力有限, 无法存储太多的信息,且容易丢失一部分语义信息. 为此, 本文通过引入记忆网络存储序列信息对其进行改进以增强其记忆能力.在图1 中,mi是根据单词的词向量和位置形成的句子向量, 其公式为:
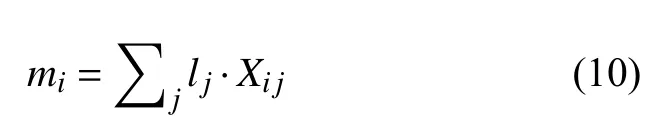
其中,Xij是句子中每个单词的词向量矩阵,l记录每个单词的位置信息,l计算公式为:
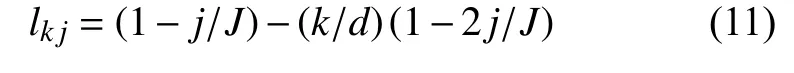
其中,J是句子长度,d是编码维度, 经过Softmax之后形成一个权重向量P:
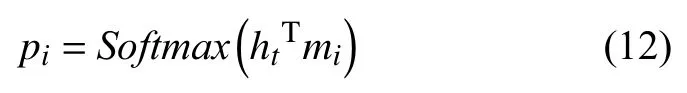
文本向量ci由权重向量P和mi构成:

记忆网络的最终输出计算公式为:

权重wg的计算方式为:

2.1.3 模型训练
在PGN 中t时刻模型损失值可通过对目标输出单词yt和覆盖向量计算覆盖损失求得:

根据输出端的概率分布, 得到输入序列概率最高的L个候选词作为网格事件的关键词.
2.2 相似度计算
计算网格事件相似度需要从结构相似度(属性相似程度)和情景相似度(关键词相似程度)两方面来综合衡量.
2.2.1 结构相似度
结构相似度比较两个网格事件具有的共同属性,共同属性越多, 事件相似程度也越高.
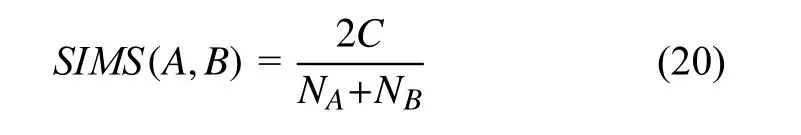
其中,A为新发送事件,B为网格事件数据库中历史事件,C为两个事件的共同属性数,NA和NB分别为事件A和事件B的属性数.
2.2.2 情景相似度

2.2.3 总体相似度
两个网格事件的总体相似度由结构相似度和情景相似度构成:
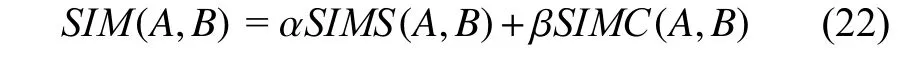
其中,α为结构相似度的权重,β为情景相似度的权重,且α+β=1. 根据网格事件数据库中历史事件相似度情况, 利用Viterbi 算法求解出α为0.19、β为0.81. 可见, 情景相似度总体上决定了事件相似度.
2.3 GPU 并行计算
在基于PGN 生成事件关键词时, LSTM 网络涉及大量的矩阵和向量运算. 此外, 计算网格事件库中两两事件的相似性的计算复杂度非常高, 尤其是存在情景相似度的计算时. 因此, 本文利用GPU 对这两个过程进行加速.
2.3.1 LSTM 网络加速
由于矩阵乘操作占了LSTM 网络计算过程的95%时间, 可以从权重矩阵列内(输入向量按列与权重矩阵相乘)、列间并行(每个输入值与权重矩阵内的每一列元素进行乘法计算)以及权重矩阵之间并行(每个输入值与门单元权重矩阵进行向量矩阵乘法运算)对LSTM 网络进行加速计算. 由于LSTM 网络不同层间具有强依赖关系, 需要先完成底层计算, 才能对上层计算. 因此层与层之间无法并行处理, 只能在层内并行计算. 此外, 不同时间步之间也具有强依赖关系, 所以只能在每个时间步内的每层做并行计算, 图3 展示了LSTM 网络的可并行性.
图3 LSTM 网络可并行性
在LSTM 网络中, 存在3 种不同形式的矩阵乘运算: 矩阵向量乘(MMV)、向量矩阵乘(VMM)和向量外积(VEP). MMV 出现在前向计算中, VMM 和VEP 出现在反向计算中. GPU 核心(kernel)程序启动会导致开销, LSTM 网络每个单元有3 个门, 每个门具有两个不同的权值矩阵, 若不加以合并, 完成一次前向和一次后向计算分别需要启动12 次kernel, 导致开销较大. 权值矩阵过小无法充分利用GPU 并行计算优势,为此本文实施了两个层次的权值合并.
(1) 列向合并
列向合并针对同一层相同门的不同权值进行合并,因此输入数据根据扩充顺序同步进行合并. 以输入门为例, 输入门接收的输入包括从当前时间步的输入xt与上一个时间步的输出ht–1, 其对应的权值分别为Wt和Wt–1, 合并后的权值Wcom=[Wt,Wt–1], 在行数不变的基础上对列做了加和. 对于输入合并, 合并后的输入Icom=[xt,ht–1], 对应列也做了加和:
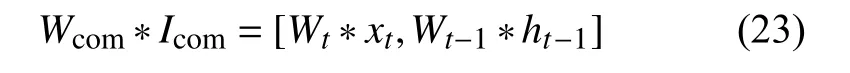
相同门的前向计算和后向计算过程是相互对应的,因此前向和后向的计算公式完全一样. 值得注意的是,后向过程原本对x和h分别进行更新, 现在对合并后的向量进行更新.
(2) 行向合并
在对行向不同门的权值进行合并的过程中, 输入数据不需要进行变换. 将f、i、o三个门合并后得到新权值矩阵Wjoin, 其行数变为原来的3 倍, 列数不变. 行向合并计算过程如下:

值得注意的是, 由于后向计算过程中不同门的激活函数不同, 导致各个门的梯度计算不完全一致, 因此,需要分别计算各个门的梯度系数.
通过对权值进行列向和行向合并, LSTM 网络进行一次前向计算仅需要启动2 次kernel, 进行一次后向计算仅需要启动3 次kernel. 同时, 每次参与计算的矩阵元素增加, 进而达到有效利用GPU 并行计算能力的目的. 为充分利用GPU 并行计算能力, 可以在程序中显式使用向量数据类型. 相对标量数据类型, 向量数据类型可由2–4 个32 位的标量数据类型组合而成, 其大小由向量数据类型的后缀数字指示. 例如, 例如,float4 向量数据类型由4 个float 数据类型构成, 分别用x、y、z和w进行引用. 使用float4 向量数据类型,可以在一次存储访问请求中取入4 个float 类型的标量数据. 与标量数据类型相比, 使用向量数据类型后的存储访问次数有所减少, 较大限度地利用了存储带宽,如图4 所示.
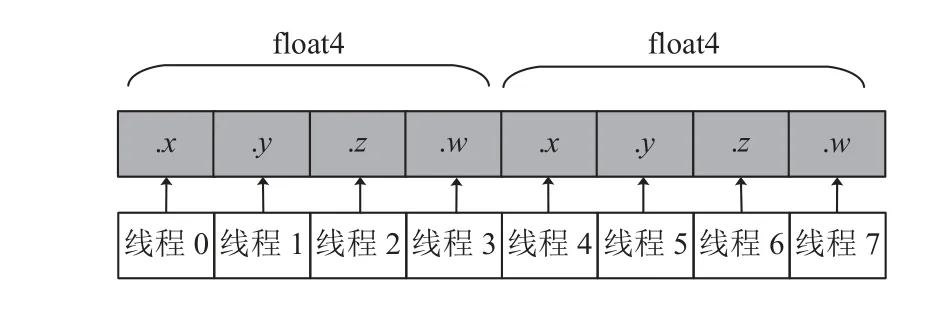
图4 float4 向量数据类型
2.3.2 相似度计算加速
在事件结构相似度和情景相似度计算中, 由于不存在数据依赖关系, 因此可以安排每个GPU 线程负责目标事件与网格事件库中的一个历史事件进行相似度计算. 为计算情景相似度, 本文实现了基于GPU 的Word-Similarity 计算过程[18]. 在WordSimilarity 并行化过程中, 关系义原描述中存在大量的分支结构, 在GPU 上并行化会严重影响执行性能. 为此, 对于一些以线程作为控制变量的条件分支, 在控制变量取值有限的情况下, 本文通过引入数组实现分支路径的间接索引, 如代码1 和代码2 所示. 引入的数组可以通过线程的进行访问, 该数组返回的值即是相应的分支路径. 也就是说, 每个线程根据其访问数组来决定其所要执行的分支路径, 这种间接索引的方式能够完全消除条件分支.

代码1. 分支重构前代码if(tid.x==0)if(tid.y==0) statements with func(m,a,b);else statements with func(m,a);else if(tid.x==1)if(tid.y==0) statements with func(m,a,b);else statements with func(m,a,b);else if(tid.x==2)if(tid.y==0) statements with func(m,a,b);else statements with func(m,a,b);else if(tid.x==2)if(tid.y==0) statements with func(m,a,b);else statements with func(m,a,b);代码2. 分支重构后代码index=m+2*tid.x;array[2][4] = {(1,2,2,1),(2,1,1,2)};a[array[tid.y][tid.x]]=func(b[index],a[tid.y]);
3 实验分析
为验证本文提出的网格事件相似度并行计算的性能, 选取安徽省芜湖市2016 年1 月1 日–2020 年12 月31 日期间40000 条社会化网格治理系统中的事件来构建数据集. 数据集中包含了事件属性、事件文本、事件情景描述、经过人工标注的相似事件等信息. 通过对40000 条事件文本进行统计分析, 长度均值为632个字, 且95%的事件情景描述的文本长度在142 个字以内. 本文选取了其中30000 条事件作为训练集, 5000条事件作为验证集, 5000 条事件作为测试集. 实验硬件环境为: 内存DDR4 64 GB, 2.4 GHz Intel(R) Xeon(R)Silver 4210R CPU, NVIDIA GeForce RTX 3090 GPU;软件环境为Ubuntu 18.04, CUDA Toolkit 10.2.
3.1 事件相似度性能对比
本文采用精确率(Precision)、召回率(Recall)和F1 值作为事件相似度计算性能的评价指标. 本文对40000 个网格事件采用第2.2.2 节所述阈值计算方法,得出事件相似度阈值为0.91. 为了验证基于关键词生成的事件相似度性能, 通过实验与使用TF-IDF、textRank 和LDA (latent Dirichlet allocation)对网格事件文本进行关键词提取并计算相似度的机器学习方法进行了对比, 对比结果如表1 所示.
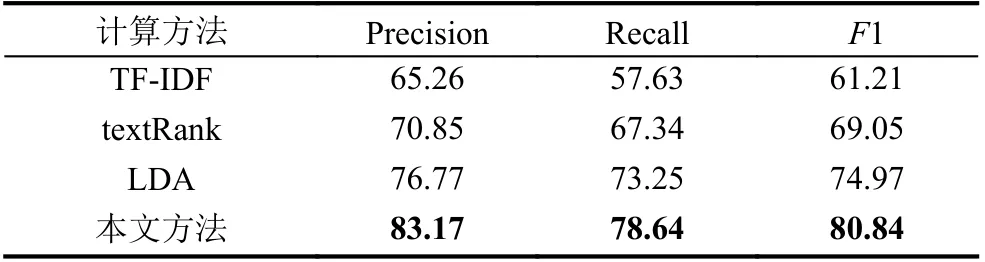
表1 基线模型对比实验结果 (%)
通过对比可以发现, 本文基于深度学习的方法在性能上优于TF-IDF 等基于机器学习的方法, 原因在于机器学习模型方法仅简单的对文本中的词向量进行加权平均, 没有使用文本更深层次的语义信息, 而深度学习方法可以获取更深层次的语义信息. 此外, 使用attention 机制的PGN 关键词生成模型更加关注那些对判断事件相似度因素贡献较大的文本特征. 通过消融实验将记忆网络从PGN 中消除, 精确率指标为82.61%. 可见, 记忆网络在精确率指标上能够提升0.7%的性能.
3.2 并行计算加速比分析
在GPU 并行加速过程中, 实验采用每个线程块包含512 个线程的设置. 从表2 中看出, 当待比对的事件规模过小时(5000 件), GPU 的计算速度反倒比CPU慢, 一方面是因为GPU 计算资源不能被充分利用, 另外一方面原因是CPU 和GPU 之间的数据传输开销及kernel 启动开销抵消了GPU 加速的性能增益. 当事件规模增加到10000 件时, GPU 并行加速的优势开始体现. 当事件规模增加到40000 件时, 此时能够取得4.04 倍的加速比. 从表2 也可以看出, 随着事件规模的不断增大, 数据传输开销占比呈递减趋势. 可以预期的是, 随着事件规模的不断增加, 能够取得越来越高的加速比.
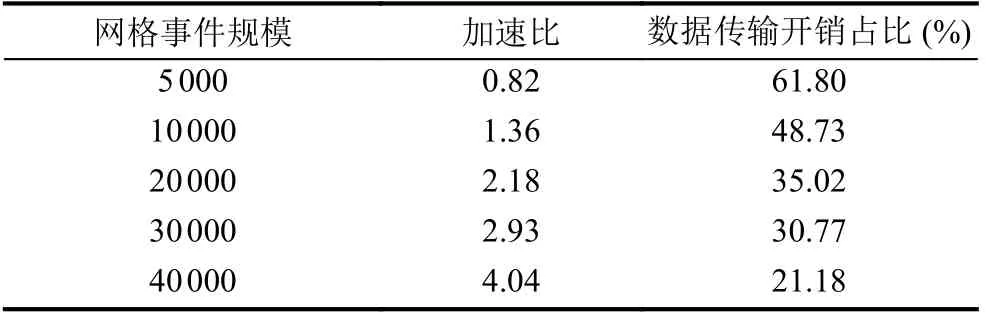
表2 并行计算加速比
3.3 与QRNN 和SRU 网络的性能对比
准递归神经网络(QRNN)是一种交替卷积层的神经序列建模方法, 其网络结构由类似于CNN 中的卷积层和池化层两类子部分组成[19]. QRNN 卷积层与CNN卷积层类似用于提取输入特征, 池化层可用于减少特征数目, 但不同的是QRNN 采用了fo-Pool (在动态平均池化的基础上增加了输出门)结构进行池化. 简单循环单元(SRU)是一种轻循环单元[20], 其具体结构分为两个部分: 轻循环部分和高速网络(highway network)部分. 轻循环部分处理输入向量并计算包含序列信息的状态序列, 高速网络部分促进基于梯度的深度网络训练. 为验证LSTM 网络应用在基于PGN 的事件关键词生成的优越性, 本文采用QRNN 网络和SRU 网络对40000 个网格事件与LSTM 网络进行了性能对比, 对比结果如表3 所示.

表3 LSTM、SRU 和QRNN 性能对比
从表3 可以看出: (1) QRNN 网络计算性能总体低于SRU 网络; (2) 2 层SRU 网络在计算速度上比2 层LSTM 网络要快, 但2 层SRU 网络在相似度计算精度上相对较弱; (3) 8 层SRU 网络能达到和2 层LSTM 网络相近的相似度计算精度, 但8 层SRU 网络计算速度稍慢于2 层LSTM 网络. 可见, 虽然SRU 网络在LSTM网络的计算方式上进行了优化, 但在本文任务上SRU网络的适应性弱于LSTM 网络.
4 结论与展望
通为了满足大规模网格事件环境下实时计算事件相似度的需要, 本文提出了一种基于关键词生成的网格事件相似度并行计算方法. 该方法通过指针生成网络生成网格事件关键词, 基于关键词结构相似度和情境相似度计算事件相似度, 利用GPU 对事件关键词生成过程中的LSTM 网络和相似度计算过程进行加速.实验结果表明: 相比TF-IDF、textRank 和LDA 方法,本文方法在相似度计算性能上更好, 采用GPU 进行并行计算最高获得了4.04 倍的加速比. 本文下一步工作是在网格事件相似度的基础上结合案例推理技术实现社会突发事件的辅助决策.
