基于改进CSRNet的人群计数算法*
2022-06-28郭濠奇
郭濠奇, 杨 杰, 康 庄
(江西理工大学 电气工程与自动化学院,江西 赣州 341000)
0 引 言
现代交通发展日新月异,城市化进程不断加快,城市间的人口流动不断增加,演唱会、学术大会等大型活动也越来越多,在这种人群密集的环境中,为保证人民群众的生命安全,对这些场所进行人群计数是十分必要的。针对人群计数,国内外学者进行了大量的研究,计数方法主要分为三种,分别为基于目标检测的方法、基于回归的方法、基于密度图的方法。基于密度图的计数方法是目前主流的计数方法[1~4]。郭俊等人[5]提出了一种基于机器视觉跟踪的计数算法。Zhang Y Y等人[6]提出了基于多列卷积神经网络的人群计数算法。Li Y H等人[7]提出了基于膨胀卷积神经网络的CSRNet算法。孟月波等人[8]提出了一种编码—解码结构的多尺度卷积神经网络。
针对现今计数算法存在的训练时间长、收敛慢的问题,本文提出了一种基于改进CSRNet的人群计数算法。对CSRNet[9]的网络结构进行改进,使用普通卷积网络替换膨胀卷积网络,同时增加密集连接结构,改进后的网络分别在ShanghaiTech数据集[6]和UCF_CC_50数据集[10]上进行实验验证。
1 基于改进CSRNet的计数算法
1.1 真实密度图的生成
基于密度图的人群计数算法,在网络训练时,输入为样本图片和对应的真实密度图。因此,在进行训练前,需要根据样本图片的标签生成样本图片的真实密度图。生成真实密度图时,读取样本图片标签中的人头位置信息,将该位置标记为1,没有人头标注的位置则为0,生成和图像尺寸相同的矩阵,将该矩阵与高斯核函数进行卷积操作,即可得到用于训练的连续的真实密度图。设图像对应标签中的一个人头标注点为xi,用δ方程表示为δ(x-xi),则拥有N个人头标注点的图片可用方程(1)表示
(1)
将H(x)与高斯核函数Gσ(x)进行卷积得到连续的密度方程,用方程(2)表示
F(x)=H(x)*Gσ(x)
(2)

(3)
1.2 针对膨胀卷积结构的探讨
CSRNet算法采用单列卷积网络,分为前端网络和后端网络两部分。前端网络采用VGG16的前10个卷积层,后端网络采用6层膨胀卷积[7]。在深度学习中,随着网络的加深,在不改变卷积核大小的情况下,一般采用减小图片尺寸来扩大卷积核的感受野。但图片尺寸减小的同时,图片的空间特征信息也将有损失。CSRNet算法通过在后端网络采用膨胀卷积,在不改变图像尺寸的情况下,扩大卷积核的感受野。针对后端网络,CSRNet给出了4种不同膨胀率的结构设置,但在验证膨胀卷积效果时,仅在ShanghaiTech的A数据集上对4种结构进行了对比,得出后端卷积网络膨胀率为2时效果最好。本文针对CSRNet选出的膨胀率为2的网络结构,将膨胀率改为1(膨胀率为1的卷积即普通卷积),在ShanghaiTech A,B数据集上分别进行实验,从平均绝对误差(MAE)、均方误差(MSE)和样本的平均训练时间(time per sample,TPS)三个指标进行对比,对比结果见表1,其中,drate代表膨胀率。

表1 膨胀卷积结构与普通卷积结构实验对比
由表1可知,空洞卷积结构的使用仅使ShanghaiTech A数据集的MAE略有提升,但样本的平均训练时间相比采用普通卷积结构的网络却提高了7倍多。因此,本文在网络设计中摒弃了CSRNet后端网络的空洞卷积,采用普通单列卷积结构进行网络的设计。
1.3 网络改进
本文提出的基于改进CSRNet的人群计数算法属于端到端的计数算法,网络结构采用单列卷积网络。为增强网络的特征提取能力,前端网络采用VGG19的前12层卷积网络,后端网络中,将膨胀卷积网络替换为普通卷积网络,并增加密集连接结构,对卷积层的输出特征进行重利用,增加网络的收敛速度,改进的网络结构如图1所示,卷积层命名方式为Conv-k-in_channel-out_channel,k表示卷积核的大小,in_channel表示输入的通道数,out_channel表示输出的通道数。
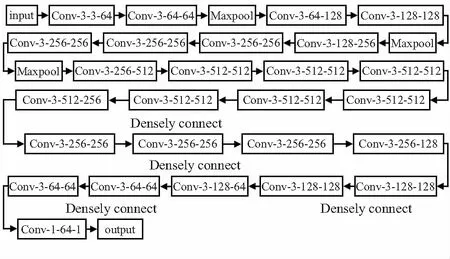
图1 本文网络结构
在后端网络中增加的密集连接属于跳连结构,结构中每个卷积层与之后的卷积层都有连接,如图2所示。假设有s层卷积,那么结构中的连接总数为[s(s+1)]/2,第i层卷积的输出特征图用fi表示,f0表示输入,经过密集连接之后,第s层卷积会接收到前面(s-1)层的特征图和输入特征图,则第s层的输入可用Hs([f0,f1,f2,…,fs-1])表示,其中,[f0,f1,f2,…,fs-1]表示输入特征图和前(s-1)层的输出特征图在通道维度上叠加的结果,Hs包括卷积层和激活函数层,作用是对特征图进行降维,减小模型计算量。加入了密集连接的神经网络,增加了卷积层之间信息和梯度的传递,减轻了神经网路容易出现的梯度消失问题。

图2 密集连接结构
2 实验结果
本文的实验平台配置:电脑配置为i5—6500 CPU,8GB RAM,64位Windows7操作系统,服务器配置为Tesla-P100,本文算法采用的深度学习框架是Pytorch框架。
2.1 训练设置
在训练过程中,每次训练抽取的样本数为1,采用RMSProp优化器进行网络权重的训练,其中,优化器的权重衰减设置为5×10-4,动量(momentum)设置为0.95,学习率的设置如图3所示。

图3 学习率设置
选择欧氏距离作为网络训练的损失函数,用来衡量算法生成的密度图与真实密度图之间的差异,公式如下
(4)

2.2 评价指标
选取MAE和MSE作为模型的评价指标,其中,MAE为真实人数和模型计数结果的平均绝对误差,MSE为真实人数和模型计数结果的均方误差,公式如下
(5)
(6)

2.3 实验结果
1)ShanghaiTech数据集
ShanghaiTech数据集[6]包含A和B两个数据集,一共1 198张图片样本,330 165个人头标记。A数据集为密集人群数据集,包含482张图片样本,其中300张用于训练,182张用于测试。B数据集为稀疏人群数据集,共包含716张图片样本,其中400张用于训练,316张用于测试。在ShanghaiTech数据集上的实验结果如表2所示,图4是ShanghaiTech A数据集上的样本图片、对应的真实密度图和本文算法生成的密度图,图5是ShanghaiTech B数据集上的样本图片、对应的真实密度图和本文算法生成的密度图。

表2 ShanghaiTech数据集上的结果对比

图4 ShanghaiTech A数据集上的实验结果

图5 ShanghaiTech B数据集上的实验结果
2)UCF_CC_50数据集
UCF_CC_50数据集由Idress H等人[10]提出,包含50张来自互联网的图片样本,是一个非常具有挑战性的数据集。UCF_CC_50数据集不仅图片样本数量十分有限,而且图片中人数最少的为94,最多的为4 543,人数波动十分剧烈。其中,50张图片的平均人头标点数量约为1 280个,人头标点总数为63 974个。在训练UCF_CC_50数据集时,采用Idress H使用的五折交叉验证法进行模型的训练和验证。在UCF_CC_50数据集上的实验结果如表3所示,图6为UCF_CC_50数据集的样本图片、对应的真实密度图和本文算法生成的密度图。

表3 UCF_CC_50数据集上的结果对比

图6 UCF_CC_50数据集上的实验结果
经实验验证,本文提出的基于改进CSRNet的人群计数算法在两个公共数据集上均表现良好,实现了精度上的提升。同时,由于未采用膨胀卷积,相比CSRNet算法,本文的算法在样本的平均训练时间上也有下降。
3 结 论
针对CSRNet后端网络,本文进行了膨胀卷积结构与普通卷积结构的对比实验,发现膨胀卷积相比普通卷积虽然特征提取能力稍强,但训练更耗时。在本文算法中,采用普通卷积网络结构缩短训练模型所需的时间;采用更深的网络增强网络的特征提取能力;在网络中增加密集连接结构,加强网络中特征和梯度信息的传递。实验验证,本文的算法具有较高的精度和较快的训练速度,在安全预警、区域人群计数等方面具有广阔的应用前景。
