基于多尺度注意力残差网络的图像超分辨率重建①
2022-06-27李俊珠陈清俊
李俊珠, 郑 华,2,3,4, 雷 帅, 陈清俊, 潘 浩
1(福建师范大学 光电与信息工程学院, 福州 350007)
2(福建师范大学 医学光电科学与技术教育部重点实验室, 福州 350007)
3(福建师范大学 福建省光子技术重点实验室, 福州 350007)
4(福建师范大学 福建省光电传感应用工程技术研究中心, 福州 350007)
1 引言
图像作为一种重要的信息传递方式, 图像的恢复和复原一直是人们关注的重点领域. 图像超分辨重建技术在移动数据的传输、卫星遥感成像、小目标检测以及视频监控等领域都有着广泛的应用和重要的研究意义. 在现实生活中, 由于硬件设备条件的原因会导致拍摄出许多低像素的图像. 例如移动数据传输的过程中, 由于设备本身成像的限制以及传输速度的要求, 低分辨率图像的传输可以节约网络移动通信的带宽, 再由用户自己决定是否进行图像超分辨的重建, 如此既满足了用户的需求又加快了图像的传输速率.
随着现代技术的发展, 越来越多的人参与图像超分辨率的研究. 在图像的超分辨重建算法受到广泛地关注之后, 陆续有研究人员提出了基于插值的超分辨率重建方法, 基于重建的超分辨率重建方法, 基于深度学习的超分辨率重建方法. 其中基于插值的方法虽然重建速度快且算法比较简单, 但是容易丢失高频信息,适合小倍数图像的重建; 基于重建的方法相对前者要好, 但是从常规来说, 加深网络的深度的确能够提高重建精度, 但是随着卷积神经网络深度的增加, 也面临着计算复杂度加深和内存消耗的问题. 单图像超分辨率重建的目的就是把分辨率低的图像通过一些技术方法恢复出与之相对应的高分辨率图像, 这是个没有唯一解的问题. 如何在不增加网络参数量的同时还能提高重建图像的精度, 这是很多研究者都在思索的问题[1-5].
本文所提出的图像超分辨率算法, 使用多尺度残差模块充分利用低分辨率图像本身的特征, 再分别用两个、3 个3×3 的卷积替代5×5、7×7 的卷积来减小参数量. 在模块中也引入了通道注意力机制, 它可以自适应地学习特征权重, 赋予高频信息更大的权重, 使网络更注重传递有效的特征信息, 增强网络的学习能力.通过实验证明, 本文结合不同大小的卷积核以及注意力残差机制构建的单图像超分辨率重建网络, 在精度上和视觉效果上都取得了一定的提升.
2 基于深度学习的图像超分辨率技术
2.1 深度学习在图像超分辨率的应用
目前, 深度学习的快速发展使得图像超分辨率领域得到了重大的突破. SRCNN[1]运用卷积神经网络来学习低分辨率到高分辨率图像之间的映射关系, 而FSRCNN[2]在网络重建部分加入反卷积层的方式来替代Bicubic 插值下采样, 有效的提升了网络的训练速度. 但由于FSRCNN 算法卷积层数较少, 且相邻的卷积之间缺乏相关性, 重建效果不是很理想. VDSR[3]通过对网络层数的加深, 增大了网络层的感受野, 还利用残差学习的方式加速网络收敛的速度. SRDenseNet[4]的稠密块结构将每一层的特征都传递给后面的每一层,特征的重复利用能够减轻梯度消失且加强了特征的传播. RCAN[5]网络将通道注意力机制(channel attention,CA)[6]引入, 让网络自适应地学习特征信息的权重, 赋予高频有效信息更大的权重, 提升了神经网络的表达能力. MemNet[7]利用递归单元的内存块建立长期记忆,以及使用门控单元控制不同的网络模块在输出的权重,自适应地形成长期持续的记忆. IDN[8]提出的信息蒸馏块包含了增强单元和压缩单元, 对低分辨率图像的轮廓增强输入并将特征像素映射压缩. MSRN[9]使用3 种不同大小的卷积核, 对初始输入的低分辨率图像进行反复的特征信息提取, 提高网络重建的性能和加快网络收敛的速度. MWRN[10]使用多窗口残差网络改变了卷积核大小, 使得网络性能和参数量也有了一定的提升. TTSR[11]鼓励低分辨率图像和参考图像进行联合学习, 通过CA 机制调整通道的特征来传递图像的纹理特征.
2.2 通道注意力机制
由于卷积神经网络有着十分强大的非线性表达能力, 它在图像超分辨率领域近10 年来得到广泛的应用.为了使得网络给予高频有效信息更多关注, 忽略与网络数据中无关的信息, 注意力机制重新被应用在计算机视觉领域. 自2018 年Hu 等人在SENet[6]中提出CA机制之后, 就被广泛应用于深度学习的网络中, 虽然增加了一些参数量, 但是性能却有了比较大的提升.
图1 左侧是由C个通道, 大小均为H×W的特征图组成, 假设特征图组X=[X1,X2,···,Xi,···,XC]. 在压缩(squeeze)操作中, 对每一通道输入首先进行全局平均池化(global average pooling, GAP), 每一个通道得到一个特征标量, 那么C个通道进行操作之后就得到C个特征标量, 如式(1)所示[6].

图1 通道注意力机制示意图

经过GAP 操作之后引入门结构机制, 使用两个全连接层为每个通道形成相应的权重系数, 先将C个通道压缩成C/r个通道, 再恢复成C个通道, 两个全连接层中的瓶颈结构可以降低模型的复杂度, 如式(2)[6]:

3 基于多尺度注意力残差网络的图像超分辨率算法
由于网络深度和层数增加可以提升图像重建的效果, 但是网络深度的增加会使得网络难以训练且很难收敛. 针对特征复用不足且参数量过大的问题, 本文提出基于多尺度注意力残差的图像超分辨率重建算法.
3.1 网络框架
如图2 所示, 多尺度注意力残差网络的单图像超分辨率主要包括浅层特征提取、深层特征提取、特征融合、特征重建4 个方面. 首先经过Bicubic 插值得到低分辨率图像(LR), 在我们对ILR进行浅层的特征提取时, 要先经过一个3×3 的卷积层提取浅层的图像特征,再使用激活函数ReLU 增强网络的非线性表达. 浅层

图2 MCRN 模型网络框架
3.2 多尺度注意力残差模块
本文提出了多尺度注意力残差模块(multi-scale attention residual block, MCRB), 每个模块在残差块的基础上使用3 个通道自适应检测尺度不同的特征图像,再对3 层卷积层提取的特征进行特征融合, 尽可能的提取初始的特征图像, 加强了特征复用. 模块的卷积后面加入了激活函数ReLU, 以增强每个模块的非线性表达能力. 通道注意力机制的引入使得网络对高频有效信息赋予更大的权重, 对低频无效的信息进行忽略.
在不降低模型性能的前提下, 用两个3×3 的卷积核代替一个5×5 的卷积核, 3 个3×3 的卷积核代替一个7×7 的卷积. 如图3 所示, 一个像素经过两个3×3 的卷积核之后会产生5×5 个与之相关联的像素点. 用小尺寸卷积核堆叠的卷积层来替代大卷积核的卷积层,不仅能够维持感受野大小不变, 且每个卷积层中含有的激活函数也能增强网络的非线性表达能力.
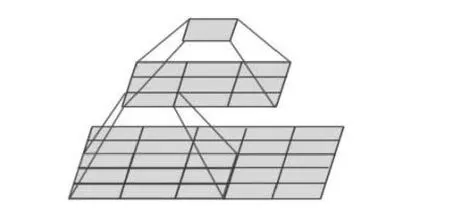
图3 两个 3×3 代替 5×5 示意图
如图4 所示, 在MCRB 模块中, 让输入特征通过3 层有差别大小的卷积层来进行特征提取, 之后再把3 层特征融合, 并通过一个1×1 的卷积核和通道注意力机制分别进行特征过滤和不同权重的赋予, 最后在该过程中加入跳跃连接. 它的具体表示方法如式(7):

图4 MCRB 模块工作原理


在网络中, 如果只是一味的加深网络的深度和宽度, 会使得网络重建的性能有一定的提升, 但同时也增加了大量的参数量, 使得训练时间大幅增加, 模型难以收敛. 本文提出的MCRB 模块, 使用3 级卷积层对特征图进行特征提取, 充分复用原始特征和加强网络的非线性表达能力. 再对每一层卷积提取的信息进行特征融合, 引入注意力机制对网络的特征权重进行赋值,增强高频有效信息的传播, 过滤掉低频无效的信息.
4 实验
4.1 实验环境和数据集
本文的训练集是采用图像超分辨率算法常用高质量的图像数据集DIV2K, 它包含1 000 张高质量图像数据集中的前800 张作为我们实验的训练集, 另外200 张分别作为验证集和测试集. 实验测试集还包括Set5[12]、Set14[13]、B100[14]、Urban100[15]、Manga109[16].
实验环境基于Ubuntu 16.04 系统, Python 3.8 深度学习开源框架PyTorch 1.8.1、NIVIDIA 1080Ti、CUDA Version 10.1 上完成. 在训练的每个批次中, 随机地选择16 个LR 色块, 它的输入图像剪裁块的大小为48×48, 采用损失函数、ADAM 优化器[17]进行优化.我们将学习率的初始值设置为Lr=1E-4, 每200 个epoch 就减半, 模型训练完成1 000 个epoch 大概需要36 h.
4.2 评价指标
对于重建的效果数值上, 本文主要采用峰值信噪比(PSNR)和结构相似度(SSIM)[18]来作为评估网络重建的性能.
(1)PSNR
PSNR主要是通过误差敏感对图像进行评估, 若一个HR 图像的大小为m×n, 重建得到的图像为S, 则PSNR的定义如式(8):


4.3 实验结果分析
在本文实验中, 我们与目前一些主流的、效果较好的网络模型进行对比, 包括 SRCNN、LapSRN[19]、DRRN[20]、MSRN. 分别在数据集Set5、Set14、B100、Urban100、Manga109 上进行测试. 在测试数据时, 我们将原始的RGB 通道的图像转换到YCrCb通道的色彩空间上, 对Y 通道进行PSNR和SSIM的数值计算.
表1 是实验测试的结果, 从表中可以看出在放大倍数为4 的时候测试集Manga109PSNR的值为30.98 dB, 相比MSRN 增加0.41 dB. 从客观的评价指标上可以看出, 本文提出的方法优于目前一些较好的网络. 本文在MSRN 的基础上增加了一条Bicubic 插值上采样的路径, 用小卷积核3×3 代替较大的5×5 和7×7 卷积核, 并引入了注意力机制, 在控制网络参数量的同时获取更多的特征, 从而使得SR 性能提升.

表1 不同方法的PSNR 和SSIM 的对比
图5、图6 展示了数据集Set5、Set14 在×4 放大倍数下的视觉重建效果图, 左侧部分是原始的高清图像, 右侧是SR 重建图像针对左侧局部区域放大的对比展示图. 通过放大细节图, 我们可以看出, 仅通过Bicubic 插值法对图像进行×4 倍采样的图像十分模糊,睫毛细节和书本的纹路也难以观察到. 在图5 中睫毛的高频信息更丰富. 对于图6 的重建, 我们放大了书架上横放的书本, 其他一些经典算法的SR 重建使得书本纹路紊乱, 而本文算法重建细节效果比较好, 图像更光滑和清晰.

图5 数据集Set5 中图像“baby”重建对比图

图6 数据集Set14 中图像“barbara”重建对比图
4.4 不同数量残差块分析
本文展示的MCRN 网络模型使用了多尺度注意力残差模块来对图像进行重建. 通过实验表明, 评价指标PSNR和SSIM都有所提升, 图像视觉的细节重建效果较好. 随着多尺度注意力残差模块数量的增加, 评价指标PSNR也会增加, 当残差块为24 的时候,PSNR达到32.50 dB 且参数量也只有5.8 M. 由图7 可见, 在12-24 个残差块的这个区间, 性能增加的最多. 所以本文选择了24 个残差块对图像进行重建, 它平均重建一张图片需要0.25 s.

图7 Set5 在×4 倍不同MCRB 数量性能对比
5 结语
本文提出多尺度注意力残差网络主要用3 个不同大小的卷积层进行特征提取再进行融合, 以多个小卷积核替代大卷积核并引入注意力机制. 在控制参数量的同时取得不错的重建效果, 不仅有效地缓解了梯度消失和梯度爆炸的问题, 网络模块的非线性表达能力也得到了增强. 注意力机制的引入, 使得通道赋予不同的权重, 有利于高频有效信息的传播和过滤掉网络中冗余的部分. 此外本文用Bicubic 插值直接给重建图像提供低频信息, 此操作对网络前期训练优化迭代的稳定有益. 我们通过实验可以看出网络整体性能的提升,也验证了网络的有效性.
