基于GAN 和U-Net 的低光照图像增强算法①
2022-06-27李晨曦
李晨曦, 李 健
1(中国科学院 计算机网络信息中心, 北京 100190)
2(中国科学院大学, 北京 100049)
目前, 基于深度学习的计算机视觉算法通过强大的图像特征学习能力, 在图像识别、目标检测等领域取得巨大成功. 深度卷积神经网络能够很好的提取图像中的关键信息, 理解图像语义, 但这依靠于高质量的图像数据. 光线不足的环境下产生的图像数据, 往往存在亮度和对比度低、细节丢失、噪声多等现象[1], 这类低光照图像不但影响人类的主观感受, 而且对上游的视觉算法任务造成阻碍. 所以, 不依赖于昂贵的图像采集设备的图像增强算法[2]具有非常重要的研究意义和应用价值. 本文着手于提高低光照图像的亮度、对比度, 改善图像感知质量, 展开相关算法研究, 共分为6 个章节: 第1 节对相关工作展开调研和分析. 第2 节介绍生成对抗网络算法基本原理. 第3 节提出了一种基于生成对抗网络的增强算法, 设计了带有混合注意力模块的U-Net 作为生成器, 基于PatchGAN 的全卷积网络作为判别器. 第4 节通过大量实验来证明所提出模型的有效性. 第5 节通过消融实验证明本文所提出的模型组件和加权融合损失函数对提高图像质量有积极的影响. 第6 节总结本文的工作, 展望未来的工作方向.
1 相关工作
低光照图像增强方法分为传统图像处理方法和基于深度学习的图像增强方法. 传统方法中直方图均衡化[3]方法通过均匀拉伸灰度直方图, 扩展图像灰度级的动态范围, 来增加对比度. 限制对比度自适应直方图均衡化[4]算法把图像划分为多个不重叠区域, 并对区域内灰度直方图最大值进行限定, 超出最大值的像素均匀分配到其余灰度级, 之后再进行直方图均衡化,能够有效抑制区域内噪声放大和局部区域过度增强,但仍不能有效处理噪声, 恢复图像细节. Retinex 理论[5]模拟人类视网膜成像原理, 将图像分解为入射分量和反射分量, 入射分量决定了像素的动态范围, 反射分量则反映了图像中物体的本质内容. 通过估计两种分量, 去除入射分量, 只保留图像中物体的反射属性, 得到不受光照影响的图像内容, 从而实现图像增强. 根据这一理论出现了单尺度Retinex (SSR)[5], 多尺度Retinex(MSR)[6]等方法. SSR 用高斯函数与图像进行卷积, 近似估计入射分量, 从而求得反射分量. MSR 使用不同尺度的高斯核函数, 可以看作多个不同尺度的单尺度Retinex 线性加权求和. 带彩色恢复的多尺度Retinex算法(MSRCR)[6]引入颜色恢复因子, 弥补图像局部区域对比度增强而导致的图像颜色失真的缺陷. 此外,NPE[7]利用亮度滤波分解图像将反射分量限制在[0, 1],并结合log 双边转换平衡光照分量对细节和自然度的增强, 避免过度增强. LIME[8]首先估计亮度图, 再根据Retinex 公式反推出反射分量, 同时使用BM3D 算法进行去噪. BIMEF[9]引入相机响应模型加强图像曝光度, 并通过光照估计加权融合得到增强图像.
近年来, 深度学习凭借强大的图像理解能力在一些低级的图像视觉任务, 如超分辨率, 去噪去雾等中获得成功, LLNet[10]将深度学习引入低光照图像增强任务, 构建了堆叠稀疏去噪自编码器, 并人工合成低光照数据, 模拟低光照环境, 对低光照有噪声图像进行增强和去噪. 相比传统算法增强图像质量明显提升, 但模型结构简单, 没有完全利用深度学习的优势, 仍有巨大的进步空间. MBLLEN[11]提出多分支网络, 分别对应图像增强中亮度增强、对比度增强、去噪去伪影等多种功能需求, 并对不同层次的特征进行融合, 达到多方面提高图像质量的效果. ALIE[12]提出了一种注意力机制引导的增强方法和多分支网络结合的体系结构, 通过生成注意力图和噪声图来引导区域自适应性的弱光增强和去噪. Wang 等[13]将Retinex 理论和神经网络相结合, 通过卷积神经网络估计光照分量, 调整曝光程度,得到期望的正常曝光图像, 并加入平滑损失提高对比度、三通道颜色损失提高鲜艳程度. EnlightenGAN[14]首创地在低光领域使用GAN 技术, 即使不成对的数据也能进行训练学习, 并利用局部和全局判别器处理局部和全局的光照条件. 基于深度学习的方法通过改变网络结构、学习不同类型特征以及优化损失函数等多元化的手段可以显著提高增强效果, 但对于图像质量和细节的恢复还有很大提升空间.
2 生成对抗网络原理
本文针对传统增强方法的不足和现有基于深度学习算法的特点, 提出使用生成对抗网络作为模型框架进行低光照图像增强的方法. 本节介绍生成对抗网络的基本原理, 及目前主流的PatchGAN 思想.
2.1 生成器和判别器
生成对抗网络由生成器G和判别器D[2]组成, 生成器学习真实数据的潜在分布, 产生生成数据. 判别器本质是一个二分类器, 判断输入数据是生成数据还是真实数据. 两个模型训练过程中相互博弈, 使得生成器的生成数据不断接近真实数据, 判别器无法判断其真假, 最终达到生成器和判别器的动态平衡. GAN 的优化属于极大极小博弈问题[2], 其目标函数公式如下.


算法1. GAN 算法的训练流程for number of training epochs do for k steps do抽样m 个来自噪声分布的样本 ;{x1,x2,···,xm}{z1,z2,···,zm}抽样m 个来自真实分布的样本 ;D(G(zi))噪声样本经过生成器和判别器得到输出 ;D(yi)真实样本经过判别器得到输出 ;Ld计算判别器损失函数 :Ld= 1 m∑m i=1[-logD(yi)-log(1-D(G(zi)))]通过Adam 梯度下降算法优化判别器的参数:θd=Adam(∇θd(Ld),θd)计算生成器损失函数 :Lg= 1 Lg m∑m i=1[log(1-D(G(zi)))]通过Adam 梯度下降算法优化判别器的参数:θg=Adam(∇θg(Lg),θg)end for end for
2.2 PatchGAN 方法
普通二分类判别器采用基于CNN 的分类模型, 将输入数据映射为二维向量, 表示该数据为真实数据和生成数据的概率, 研究表明该方法在低光照图像增强领域并不适用, 因为图像增强不仅是一个整体的二分类问题, 而且还需要对图像中不同区域进行调整. Patch-GAN 是一种关注局部图像特征的判别器框架[15], 思想是使用全卷积网络提取高级图像特征, 输出为一个N×N的矩阵, 其中每一个元素表示一个感受野, 能够表示出原图像中对应区域的图像特征.
3 主要方法
本文提出的模型基于GAN 架构, 生成器采用带有混合注意力机制的U-Net, 输入为低光照图像, 输出为同尺寸的增强图像. 判别器借鉴PatchGAN 的思想, 采用全卷积网络, 输出为矩阵张量. 具体结构如图1 所示.

图1 GAN 框架模型图
3.1 生成器网络结构
生成器是GAN 的核心, 主要作用是进行图像增强、去噪和细节恢复. U-Net[16]在图像分割领域应用广泛, 是由编码器、解码器和跳跃连接[17]组成的卷积神经网络. 编码器使用3 次最大池化层缩小特征图尺寸,获得感受野更大的特征图. 解码器使用3 次反卷积从高级语义特征恢复到高分辨率图像, 跳跃连接将编码器和解码器对应层次的特征图进行叠加, 避免了网络深度加深造成的浅层特征丢失, 同时聚合多层特征合成高质量图像. 本文提出的生成器网络在U-Net 的基础上进行改进, 在网络头部提取注意力图, 在编码器部分加入混合注意力模块MixAttBlock, 在解码器部分加入注意力卷积模块ConvAttBlock, 提高网络的特征表示能力, 有助于恢复图像细节. 生成器网络具体结构如图2所示.

图2 生成器网络结构图
注意力卷积模块: SENet[18]提出的通道注意力机制, 通过全局平均池化获得每个通道的代表值, 再使用全连接层及激活函数学习通道间的关系, 获得通道的权值. 注意力机制能够引导网络关注更重要的特征, UNet 的解码器阶段特征图通道数逐层减少, 直至恢复至三通道, 我们在此引入通道注意力, 形成注意力卷积模块(ConvAttBlock), 在通道恢复时有助于保留重要特征, 其网络结构如图3 所示.

图3 ConvAttBlock 结构图
非对称的non-local 模块: 卷积层只在局部像素范围进行卷积运算, 因此需要堆叠大量卷积层才能获得较大感受野, 同时也增加了网络参数和网络优化难度.Non-local[19]旨在通过计算特征图任意像素位置之间的远程依赖的方式代替堆叠大量卷积层, 来提高感受野.
其通用公式为式(2), 其中,xi表 示特征图上任意位置,f是相似度函数,g是映射函数, 将点映射成向量, 即求任意位置的特征表示,C(x)表示归一化. Non-local的具体网络结构如图4(a)所示, 其中, θ 和 φ 两个卷积用于压缩通道数, 矩阵乘法用于计算相似度, Softmax 进行归一化, γ卷积即为映射函数.

图4 Non-local 和ANN 模块结构图

Non-local 引导网络利用更大范围的信息这一特性, 使得低光照图像增强时能够保留更丰富的信息. 同时, 该模块计算过程中会产生的大型的矩阵张量, 导致内存占用量和计算量激增. 为进一步优化网络性能, 我们采用了非对称的non-local 模块(asymmetric nonlocal, ANN)[20], 在 φ 和 γ卷积后面引入金字塔池化层, 结构如图4(c)所示. 多尺度的池化可以在减小特征图尺寸的同时, 不会丢失过多的特征信息. ANN 的具体结构如图4(b)所示, 其中,N=H×W, 且S≪N.
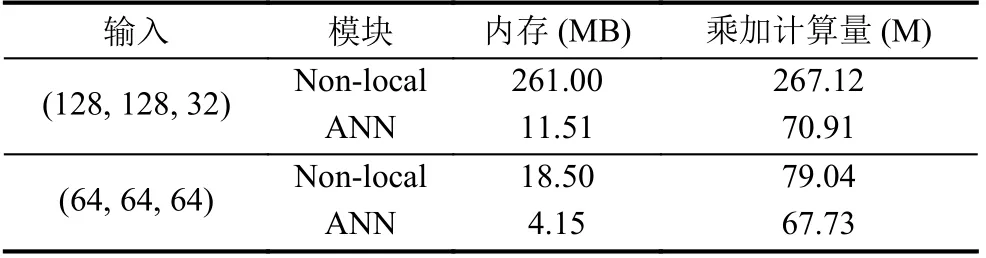
表1 Non-local 与ANN 内存和乘加计算量对比

图5 MixAttBlock 结构图
3.2 判别器网络结构
本文的判别器采用13 层全卷积网络, 均使用3×3 的卷积核, 除最后的卷积层外, 其余卷积层后均使用LeakReLU 激活函数. 全卷积网络提取高层图像特征, 并输出一个1×4×4 的矩阵张量, 充分考虑图像不同区域的影响, 注重图像全局质量和局部细节的提升. 网络结构如图6 所示.

图6 判别器网络结构图
3.3 损失函数
3.3.1 生成器损失函数

这类损失只能使生成图像与对应的标签图像像素值绝对误差减小, 没有考虑图像的内容相关性. 为了能够更好的恢复图像细节, 我们采用了多损失加权融合的方法, 加入对抗损失、结构损失和感知损失, 构造新的生成器损失函数, 公式如下:

对抗损失: 该损失基于生成器和判别器的对抗机制[17], 引导生成器网络学习正常光照图像的亮度、对比度、纹理等特征. 对抗损失定义为生成图像输入判别器得到结果矩阵, 与相同尺寸的全1 矩阵张量的均方误差值(mean square error,MSE). 当结果矩阵每个元素都接近1, 则判别器不能判断其是否为生成图像, 从而达到生成器和判别器的动态平衡. 计算公式如式(7),其中,G表示生成器网络输出,D表示判别器网络输出,Ione表示全1 矩阵张量.

结构损失[22]: 该损失旨在通过衡量生成图像和标签图像的结构差异性, 提高生成图像的整体视觉质量.该损失根据常用的图像质量评估指标结构相似性(structural similarity, SSIM)[23]和多尺度结构相似性(multi-scale structural similarity, MS-SSIM)[24]构成.SSIM 从亮度、对比度、结构3 方面度量图像相似性,计算公式如式(8)所示. 亮度、对比度、结构度量函数表达式分别为式(9)、式(10)、式(11). 其中, μx和 μy分别表示图像x和y的均值, σx和 σy分别表示图像x和y的方差, σxy表 示图像x和y的协方差,C1、C2和C3是常数. 实际计算时, 使用高斯加权滑动窗口将图像划分为多个局部区域, 整张图像的SSIM取所有区域的均值.

感知损失:Lpix、Lstr等指标只关注了图像中的底层信息, 而没有考虑高层特征信息. 我们认为越相似的图像, 通过通用特征提取器获得的特征图也越相似, 而高层特征图也是提高图像视觉质量的重要标准, 这在SRGAN[25]中定义为感知损失. 由于VGG19 网络在图像特征提取上有着良好的表现, 我们采用ImageNet 上预训练的VGG19 模型作为特征提取器[1], 提取其第2 和第5 个池化层的输出构成特征图, 计算特征图的均方误差作为感知损失, 通用公式如下,

3.3.2 判别器损失函数
生成图像和正常光照图像输入判别器时, 生成图像应该判别为假, 而正常光照图像应该判别为真, 又由于判别器的输出为1×4×4 的矩阵张量, 则使用全0 和全1 矩阵张量分别与生成图像和正常光照图像的输出矩阵计算MSE, 损失函数定义为:

4 实验分析
4.1 实验环境
本文实验环境为Ubuntu 18.04, Intel Xeon E5-2630@ 2.20 GHz, 32 GB RAM, TITAN RTX 24 GB, PyTorch深度学习框架.
4.2 数据集
真实环境下很难捕捉到成对的低光照和正常光照图像, 根据之前的研究, 本文采用MBLLEN 提供的基于PASCAL VOC 图像数据集的合成数据集[11], 该数据集通过对每个通道随机伽马非线性调整产生低光照图像, 公式表达为:

4.3 实验指标
图像增强通常采用峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性 (SSIM)作为定量指标[26].PSNR通过评估生成增强图像与正常光照图像间像素差异来衡量整体增强效果, 单位是分贝(dB), 公式如下:


4.4 参数细节
本文采用 Adam 优化器, 初始学习率为 1E-3, 并使用学习率衰减, 每个epoch 衰减1%. 网络训练的epoch设置为100, batch-size 设置为16. 采用随机裁剪、旋转和翻转扩充数据, 并指定输入尺寸为256×256. 金字塔池化层输出尺寸设置为[2, 6, 8], 损失函数权值(λ1,λ2,λ3,λ4)设置为(0.006, 0.85, 0.14, 0.004).
4.5 实验评估
实验网络模型训练损失随迭代的收敛曲线如图7所示, 其中, 图7(a)是生成器训练损失曲线, 图7(b)是判别器训练损失曲线. 可以看出, 模型在100 epoch 后接近收敛.

图7 训练损失曲线
本文提出的模型与一些经典算法在VocDark 测试集上的对比结果如表2 所示. 其中, 加粗字体表示最高值, 下划线表示次高值. 实验通过客观指标对比证明本文算法要优于其他算法, 说明基于U-Net 的生成对抗网络在低光照图像增强任务中具有比较明显的优势.

表2 与经典算法的对比结果
测试集的直观增强效果如图8 所示, MSRCR 算法的结果存在颜色失真, 曝光过度的问题. NPE 算法一定程度上缓解了颜色失真的问题, 但亮度提升不足, 且局部区域模糊. LIME 算法的结果色彩不自然, 亮度、对比度过高, 如Image 1 中沙发偏蓝, Image 2 中狗的毛色过亮. BIMEF 算法结果偏暗, 如Image 4 和Image 5 整体亮度增强效果不明显. MBLLEN 算法的效果较好,但局部区域较暗, 且与自然光照图像存在偏差, 如Image4中羊腿下的区域和Image 5 中车底的区域较暗. 本文算法的结果与自然光照图像非常接近, 并且本文算法在增强整体的亮度、对比度的同时, 细节恢复上也更加出色, 如Image 1 中地面光线轮廓更真实, Image 2 中地面、Image 4 中羊嘴和Image 5 中车牌的细节更加明显. 从人眼视觉感知效果上可以看出, 本文算法的增强图像质量高于其他算法.

图8 测试集效果对比
5 消融实验
本文通过消融实验验证提出的网络模型中每个组件的有效性. 实验通过逐步添加各类组件来比较指标的变化. 在这些实验中, 均保持训练过程中的超参数设置不变, 将所有网络训练100 epoch 达到收敛状态, 选择PSNR、SSIM作为衡量不同模块对网络性能影响的指标.
首先选择U-Net 作为骨干网络, 分别加入ConvAtt-Block、MixAttBlock 以及其组合, 结果如表3 所示, 说明本文所提模块组合后能够取得最佳效果.

表3 不同模块组合结果对比
图9 展示了添加不同模块的效果, 通过视觉对比可以发现, U-Net 作为骨干网络在低光照图像增强中能取得较好的效果, 但仍存在亮度、对比度提升不足, 边缘细节模糊的问题. 加入ConvAttBlock 后增强效果不明显, 加入MixAttBlock 后局部区域提升明显, 如Image 1中羊毛颜色和细节得到恢复, Image 5 中人脸细节更加明显. 本文所提方法产生的增强图像视觉效果最好, 说明这些模块有助于恢复低光图像各方面属性, 使其成为清晰真实的自然光照图像.

图9 模块消融实验效果对比
其次, 本文对多种损失的组合进行对比, 测试集结果如表4 所示, 其中, *号表示选中该损失参与加权融合, 组成新的生成器损失函数. 可以看出同时使用Lpix和Lstr能够显著增强图像的PSNR, 说明该损失能够正确引导网络学习低光照图像到自然光照图像的映射关系. 并且Lp的加入有助于提高增强图像质量.

表4 不同损失组合结果对比
6 总结
本文针对低光照图像增强的问题, 提出了一种基于U-Net 生成对抗网络的低光照图像增强算法. 生成器采用带有混合注意力的U-Net 网络, 该方法利用非对称的non-local 模块减少网络复杂度的同时提高感受野, 与通道注意力结合, 获得更丰富的特征表示. 判别器借鉴PatchGAN 的思想, 从普通的二分类网络改为输出为矩阵的全卷积网络, 以考虑图像局部区域差异,提高生成器的增强效果. 实验证明本文的方法能够获得高对比度、高亮度、噪声和颜色失真较小、细节更显著的增强图像. 并且, 通过在公开数据集上对PSNR、SSIM等评价指标的客观比较, 证明本文所提方法具有更好的效果. 最后, 通过消融实验证明本文提出的算法及参数配置能够取得最佳的效果. 在今后的工作中, 我们将从两个方向继续探索和应用低光照图像增强技术:一是结合图像分类、目标检测等上游任务, 提高其在低光照领域的可行性和准确性; 二是进一步优化网络结构和训练方法, 解决GAN 难训练, 容易出现梯度消失和梯度爆炸的问题.
