基于优化K-means聚类算法的用户画像
2022-06-26王晨光
王晨光
(中国石化油品销售事业部,北京 100728)
用户画像是一种典型的大数据工具,其最早的英文单词“User Persona”由Alan Copper提出,他认为用户画像是真实用户的虚拟代表,根据用户行为、动机等将用户分为不同的类型,从中抽取每类用户的共同特征,并根据名字、照片、场景等要素对同类用户进行描述[1]。近年来,用户画像在电子商务、社交网络、图书馆、医疗和金融等领域得到了广泛的应用[2],包括精准营销、个性化推荐、定向广告投放等。
在传统行业,企业经营大数据的维度往往较少,同时通常分散在若干建设于不同时期的信息系统,难以得到较为完整的用户信息。这种情况下,生成的用户画像与真实情况很可能存在偏差,其参考意义也将大大降低。同时,传统企业的数据信息密度较低,对算法的运行速度要求也更高。
因此,本文希望提出一种方法,利用有限维度、高分散度的企业经营数据,充分挖掘出其中的隐藏信息,提高生成用户画像的精度和速度。
用户画像的核心步骤是数据挖掘,即利用各种机器学习算法分析大数据内部规律,挖掘其中的潜在价值。按照数据是否有标签,可分为无监督学习、半监督学习和有监督学习[3]。聚类是一种典型的无监督学习算法,在用户画像生成领域应用较为广泛,其根据数据的相似性将数据集聚合成不同的类/簇,使得同簇中的元素尽可能相似,不同簇的元素差别尽可能大。
目前,K-means算法是在工业界和学术界中最有影响力的聚类算法之一,由MACQUEEN于1967年首次提出[4]。其目标是对于给定的数据集Sn和聚类簇数k(k≤n),将Sn按数据的聚集程度划分为k个簇,使同簇样本的相似度较高、簇间样本的相似度较低。经典K-means算法流程如图1所示。
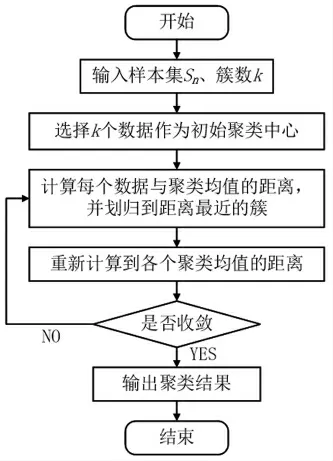
图1 经典K-means算法示意图
1 系统设计与实现
本文提出的用户画像系统整体架构分为三层,即数据采集层、数据分析层和数据应用层。其中,采集层采集所需数据并存入数据库,分析层利用聚类算法挖掘数据中的规律和价值,应用层面向具体业务场景,生成相应的用户画像并用于辅助经营决策。
2 算法架构
2.1 数据采集层
数据采集的方式主要是系统数据接口,必要时可以通过网络爬虫,来源包括各类涉及用户数据的业务系统,可根据业务需求和基础设施能力自动化采集,并存储于Hadoop等大数据平台[5-6]。
2.2 数据分析层
数据分析的第一步是对数据进行预处理,以解决源数据质量参差不齐的问题。用户相关数据较为分散,各个系统的技术架构、数据字段也有所区别,因此,预处理是非常关键的一步。包括数据清洗、数据集成数据规约和数据变换等。
挖掘分析阶段,针对数据维度有限的问题,本文采用“机器学习自动分类+人工提取分类特征”相结合的方法,充分挖掘出数据中隐藏的有效信息。
经典K-means算法中,每轮迭代都需要计算所有样本点与聚类中心之间的距离,对于传统企业的大数据应用场景来说,效率较低、耗时较长。同时,该算法对聚类簇数k、初始聚类中心、离群点和噪声点较为敏感,也不支持凹数据集。为了克服上述不足,人们提出了多种优化算法,其优缺点的对比见表1。

表1 不同K-means优化算法的优缺点对比
传统企业在大数据分析实践中,普遍面临数据维度少、分散度高的情况,易出现噪点。针对此情况,可以利用Mini Batch K-means算法进行处理[7]。同时,考虑到该算法精度不足的劣势,以及噪点容忍度高的优势,可同时结合K-means++算法,以弥补该算法带来的精度损失。其中,Mini Batch K-means算法从原始样本中随机选择少部分做经典K-means以加速收敛,避免样本太多导致的计算难题[7]。为弥补精度损失,一般重复采样并分别执行,利用得到的若干样本集进行聚类,并选择其中的最优结果,如下所示。算法1 Mini Batch K-means小批量优化算法输入:采样数m,迭代次数t,原始样本集X={x1,x2,……,xn}输出:聚类结果C={c1,c2,……,ck},其中且

K-means++算法的原理是对K-means的初始聚类中心的随机选择过程进行改进,以减少偶然性、提高算法精度,其伪代码如下所示。
算法2 K-means++初始聚类中心优化算法
输入:聚类簇数k,迭代次数t,原始样本集X={x1,x2,……,xn}
输出:聚类结果C={c1,c2,……,ck},其中且

聚类簇数k是K-means算法中的一个关键参数,通常利用Within-cluster SSE和手肘法确定[8],k一般设为4~7。随着k的增大,SSE值逐渐减小;当k小于实际簇数时,SSE值会迅速下降;当k继续增大时,SSE的下降趋势将放缓。本文实验如图2所示,故本文将k设为5。
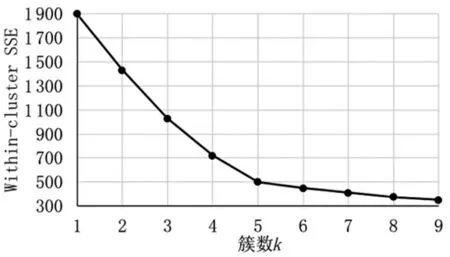
图2 SSE随簇数k的变化趋势
2.3 数据应用层
用户画像的生成需要结合具体的业务场景。本文利用RFM[9]模型制定用户画像生成标准。RFM是应用最广泛的一种指标模型,通过用户最近一次消费的日期R、消费频率F以及消费金额M三项指标评估客户的价值状况,用于监测消费行为异动、防范用户流失。根据RFM模型,本文构建了一个用户画像生成标准,其示例见表2。

表2 用户画像的生成标准示例
以流失客户为例,基于数据分析得到的“平均消费周期(T)”特征,在每一类中进行分析。一般地,注册日期距今已超过1个月、且最后一次消费距今已超三倍周期的用户,可认为已流失。制定了用户画像的生成标准之后,我们就可以自动地对全部用户进行打标签,若干标签即构成了用户画像。
3 实验结果
3.1 基于企业数据的实验
基于某企业实际经营管理数据,进行了Ⅰ、Ⅱ、Ⅲ、Ⅳ四组实验,即分别基于K-means、K-means++、Mini Batch K-means以及Mini Batch K-means&Kmeans++等四种聚类算法,生成用户画像。对用户数据进行分析后,取多次结果的平均值,见表3。

表3 基于企业数据的测试结果
可以看出,相比经典K-means聚类方法,本文提出的Mini Batch K-means&K-means++方法的查准率、查全率、F1值分别提高了22.1%、20.6%、21.3%,对比实验Ⅱ和实验Ⅲ,也取得了更好的结果。
3.2 基于公开数据的实验
基于UCI公开机器学习测试集的Online Retail II数据进行了实验。该数据来自一家英国电商平台,共1 067 371条交易流水信息。以商品编码、商品名和总价为标准,将消费行为较相似的用户进行聚类划分,结果如图3所示。可以看出,实验Ⅳ较实验Ⅰ和Ⅱ提高了约150倍。基于聚类算法通用的内部指标[5]进行量化评估,见表4,其中,SC和CHI越大越好,DBI越小越好。可以看到,实验Ⅳ的整体结果明显好于实验Ⅰ和Ⅲ,与实验Ⅱ差别不大。

图3 不同实验的耗时对比
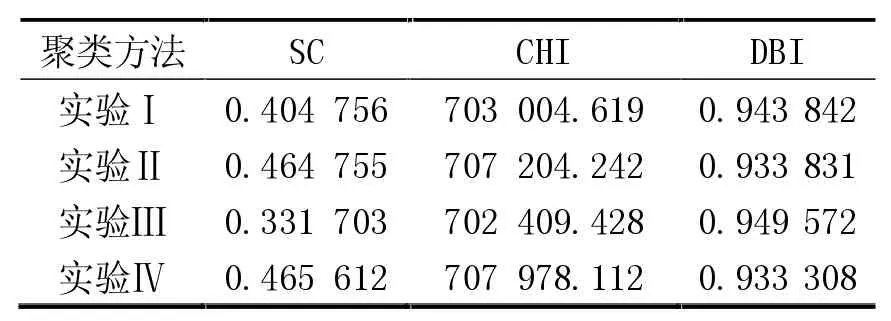
表4 基于公开数据的测试结果
4 结论
针对传统企业的数据应用现状,本文提出了基于优化K-means算法的用户画像方法。在经典K-means算法基础上,分别利用K-means++初始聚类中心优化算法体高精度、Mini BatchK-means小批量优化算法提高速度,以增强针对用户画像的分析能力。结果显示,针对有限维度、高分散度的情况,该方法的速度和精度比经典方法分别提高了约150倍和20%。
