广东省气象业务网文件管理子系统设计与实现
2022-06-24黄伟阮惠华李泽杰黄宇宸陈逸智
黄伟,阮惠华,李泽杰,黄宇宸,陈逸智
(广东省气象探测数据中心,广东广州 510640)
随着气象现代化要求日益增高[1],广东省气象局于2019年开始建设新业务网,针对原业务网的文件处理功能不集中,文件管理与业务网页面显示耦合度太高的问题[2],新业务网建设采用开发文件管理子系统的思路。当前,文件类气象资料的处理多为功能单一的软件系统,例如对气象数据的全链路监控[3]、针对CTS文件传输的可视化监控[4]、对观测类数据的调度传输[5]、气象资料检索[6]、气象资料备份[7-8]等等,这些功能单一的系统,无法满足新业务网的需求,且各个系统之间信息无法共享。综合式的文件管理方案,有利于业务网功能扩展以及降低系统耦合度。新一期的业务网建设对数据安全提出了更高的要求[9],独立的文件管理系统更有利于安全功能的扩展。
广东省气象业务网文件管理子系统(以下简称系统),要求在可能出现的单点故障和维护状态下,保证业务能够不间断运行及保证数据的一致性和完整性[10]。同时系统设计采用微服务架构[11-12],实现动态可扩展性。
1 系统设计与实现
1.1 系统模块设计
系统的基础功能可分为3个大模块:文件调度模块、文件搜索模块和文件监控模块。其中,3个模块通过日志相互关联。
1)文件调度模块。该模块实现了文件的迁移、清理、转换、改名、备份等功能。支持不同协议、不同节律、不同字符集的传输;系统实现了多种文件读取的过滤、文件写入的后处理、对Office文档的转换功能。具体功能详见表1。

表1 调度模块功能说明
2)文件搜索模块。该模块是基于Solr的搜索引擎实现。Solr是基于Lucene的全文搜索服务器,支持中文分词算法。匹配度根据文件名命中数、文件内容命中数、文件时间不同权重计算匹配度,最后根据匹配相关的排序显示。显示词条包含文件的文件名、文件实体地址、源地址、目标地址等信息。
3)文件监控模块。该模块实现了对数据流程的监控管理,应用数据血缘关系形成数据链路图来描述数据流程,通过配置每个节点的监控,实现整个数据流程的监控,每个监控节点定义了不同告警级别、不同类型(文件、连接、服务)、不同节律的监控,并通过数据接口发送到值班辅助平台。
另外,系统接口服务模块支持http的get与post两种方式请求,为了保证系统数据访问安全,访问系统接口通常需要3个步骤:访问认证接口;根据时间戳、系统编码、密码等信息生成认证;获取认证信息后,则数据访问接口附带认证信息,获取接口数据。对于以往开放式的数据服务,数据安全性有较大提升。
其他功能包含公共信息的管理,如连接协议管理、系统监控管理、日志的维护模块、消息提醒模块、资料类型相关子系统的关联配置等。系统功能划分见图1。
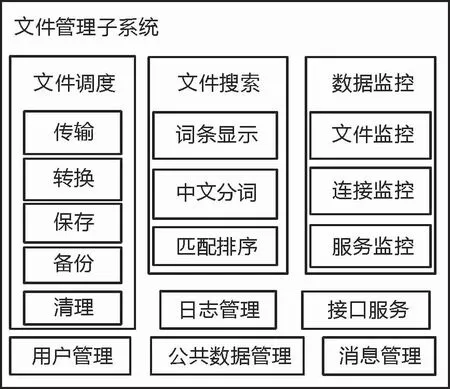
图1 功能模块示意图
1.2 系统逻辑架构设计
为了充分满足系统在高可用、易扩展等方面的要求,采用Spring Cloud微服务架构。根据不同的方法划分成相应的微服务,各服务之间彼此独立,也可以根据业务需求进行服务调用。逻辑层级上系统分为3层结构:交互层、服务层、数据层。
系统以Tomcat为web服务器,Tomcat响应用户请求,访问微服务集群;而传输产生的日志、搜索的索引等其他相关的日志,通过Solr日志索引库存储。Oracle则提供了基本元数据的持久化存储,例如配置信息等等。通过Redis作为数据缓存,减少了数据查询的压力。系统逻辑架构如图2所示。
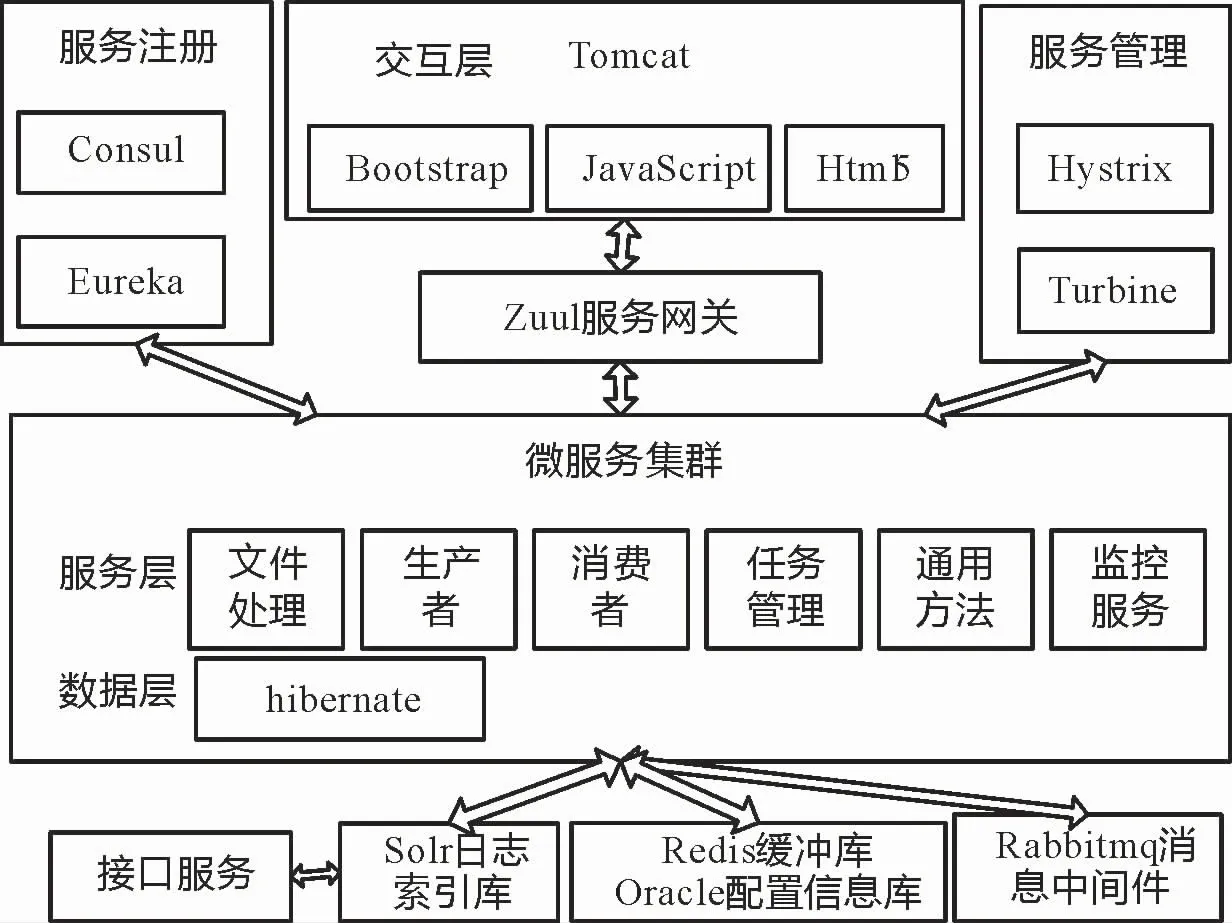
图2 系统逻辑架构示意图
1.3 系统部署实现
通过测试发现,系统运行压力主要存在于文件处理服务的IO压力以及线程数量的不足,所以部署多台文件处理服务器和一台接口服务器。因系统用户数有限,Oracle、Redis服务压力小,部署同一服务器。Solr提供日志服务与搜索服务,单独部署一台服务器。消息中间件与其他系统共用现有消息中间件服务器(图3)。
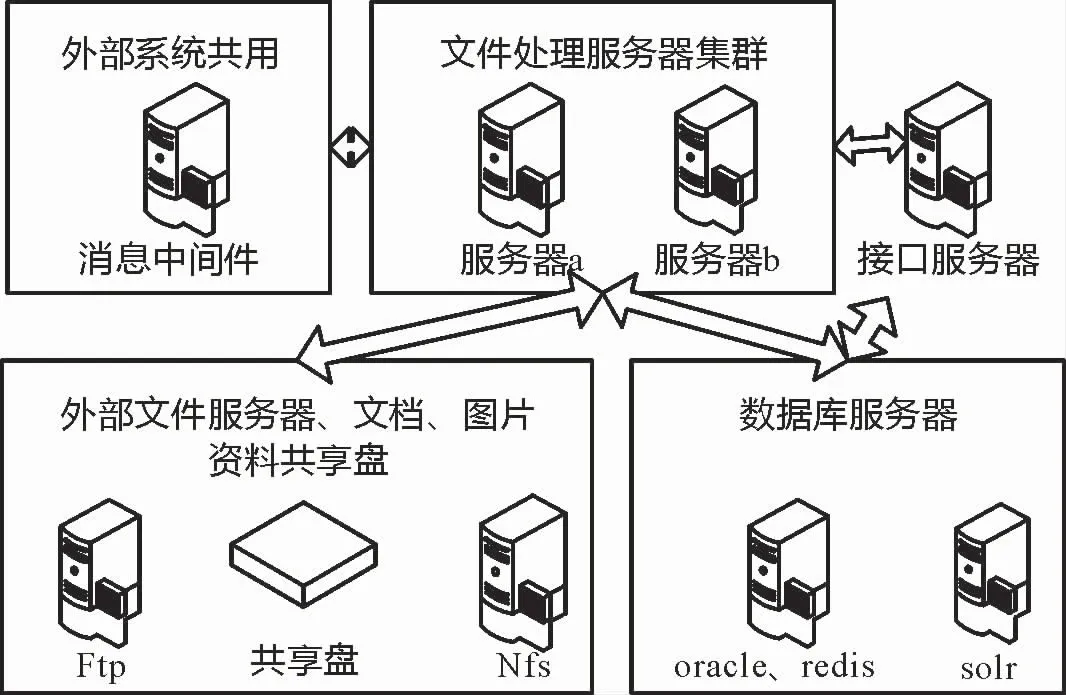
图3 系统物理部署示意图
2 关键技术
2.1 基于Quartz的任务调度算法
系统的调度任务分配是基于Quartz框架完成,核心元素是调度器scheduler,并由触发器trigger和任务job两个元素构成。trigger是用于定义调度时间的元素,例如定时执行、按日历执行、单次执行等;job用于表示被调度的具体作业内容。概括性的描述,通过轮询scheduler列表,完成了任务的调度,具体如图4所示。
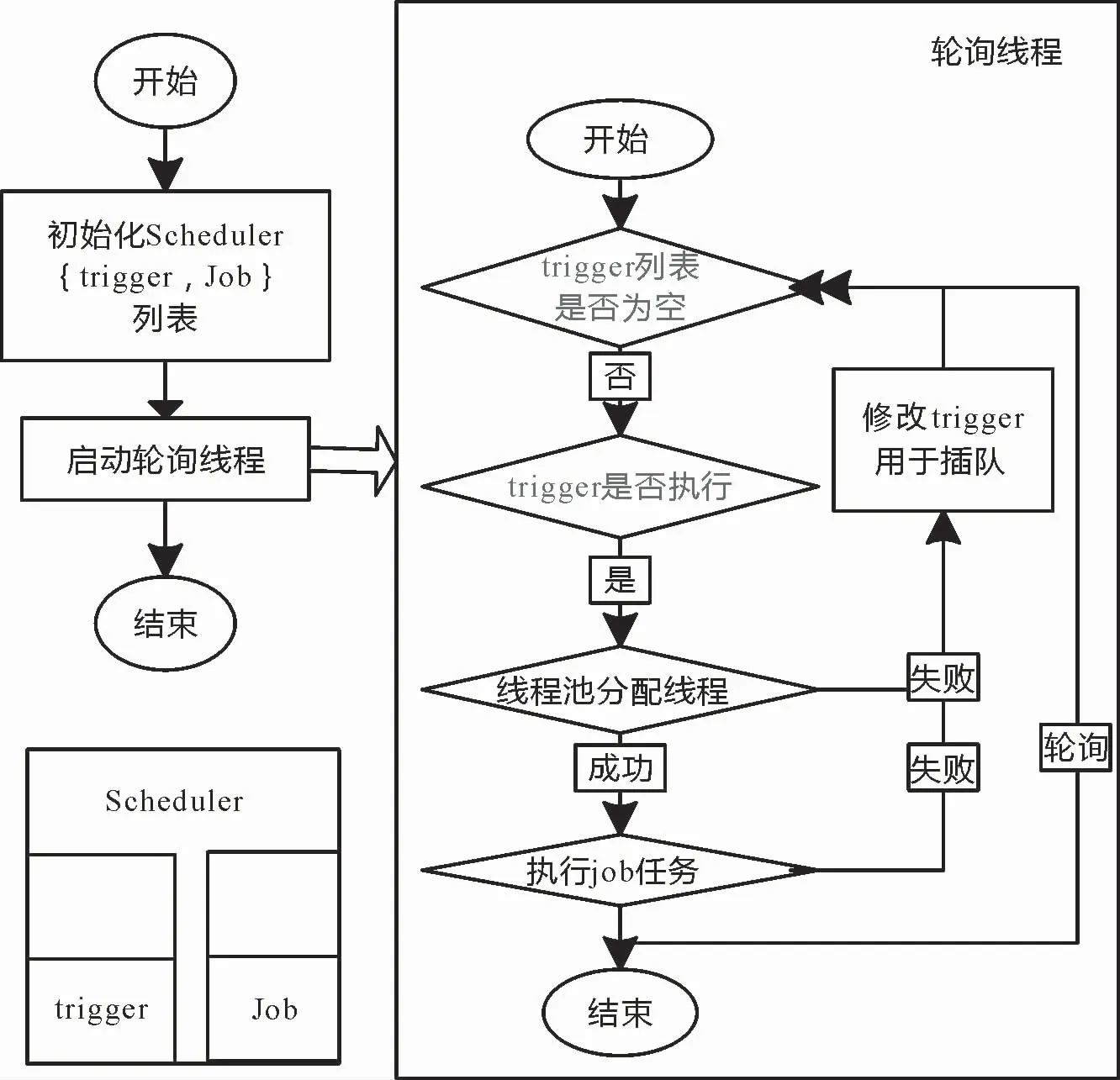
图4 任务调度算法
2.2 文件同步清单生成算法
文件同步是一项耗费IO资源的功能,为防止频繁的扫描和重复同步,对哪些文件同步的判断十分关键。该系统采用的是日志比对的方式,对源目录扫描文件集A和已同步文件集合B进行比对,判断出是否需要同步,其具体方法是:A和B交集代表已经传输的日志,避免再次传输;A补集代表新增的文件,新增的文件清单,发送到消息队列处理;B的补集代表已过期的日志,为了减少日志查询压力避免日志累积,可以删除过期日志,具体同步清单生成如图5所示。
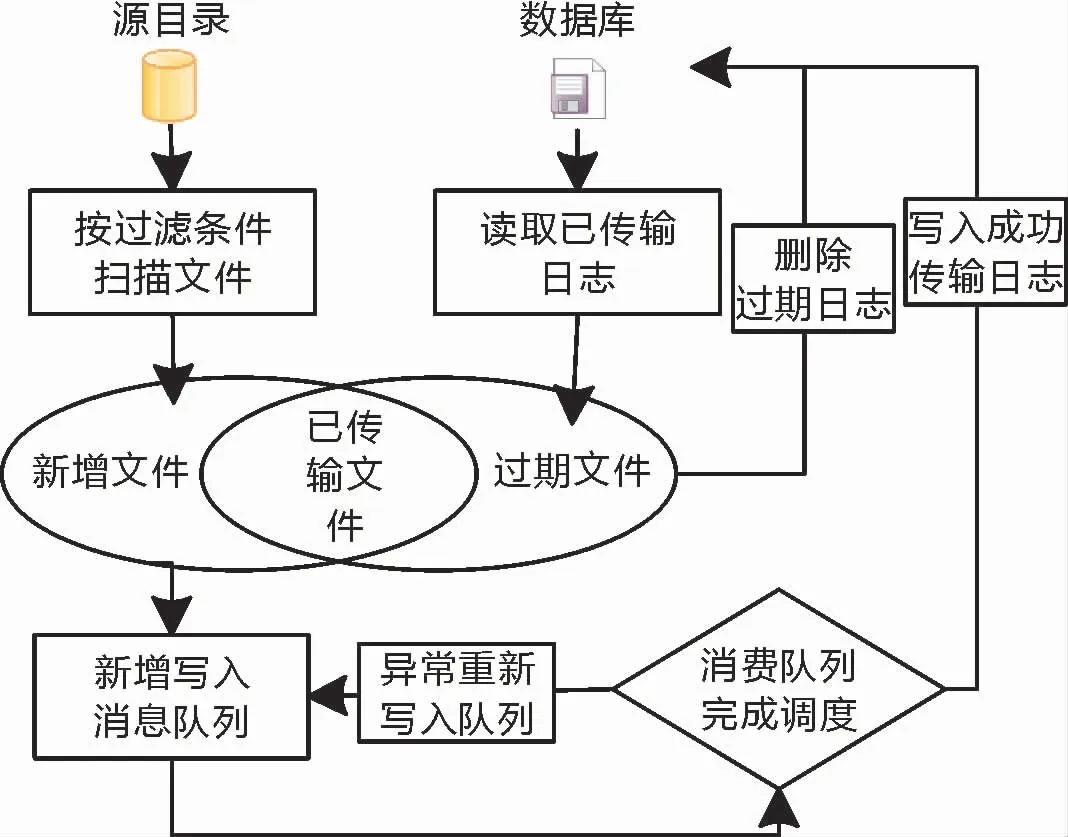
图5 同步清单生成数据流程图
2.3 任务异步执行管理
为了避免多个任务线程对资源的抢占,本系统由RabbitMQ消息中间件实现任务的异步执行,对应每个任务,QuartZ生成任务调度器,执行调度清单生成算法,生成的调度清单打包成JSON消息集发送到RabbitMQ。当队列监听线程发现有消息时,通过消费者获取消息,解析JSON信息,获取完整的任务信息,完成任务的执行(图6)。
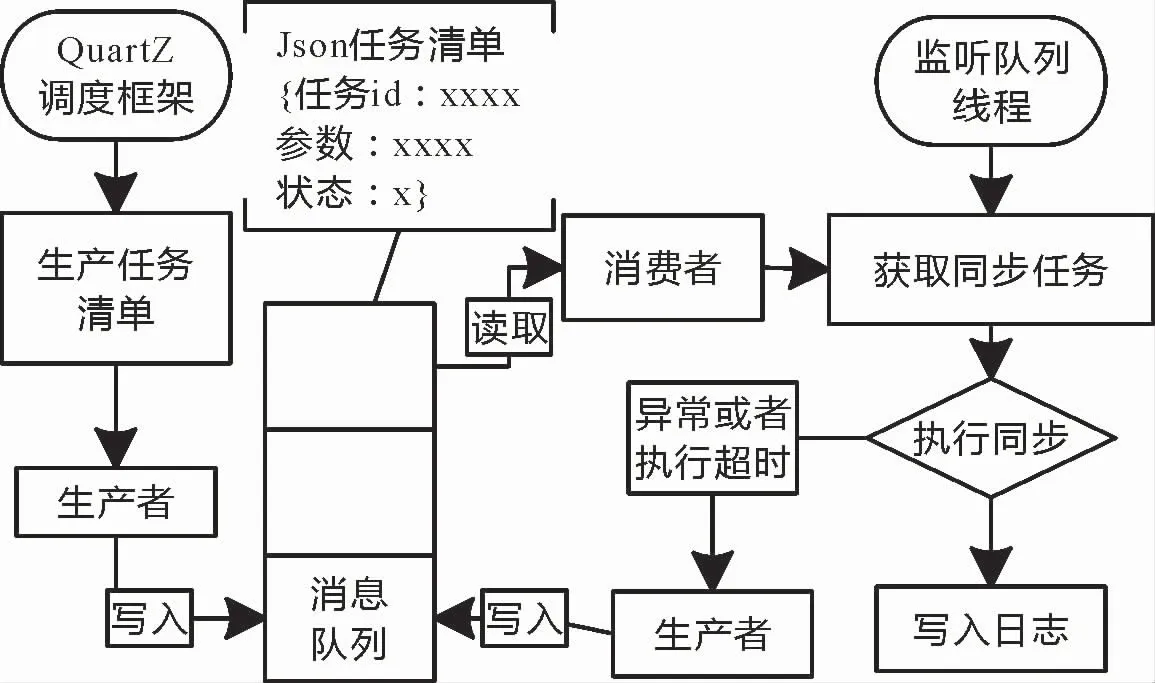
图6 线程异步流程图
该机制有以下几个优点。
(1)调度线程不会受到任务实际执行情况影响,当完成消息写入时,调度器的线程就结束。
(2)如果执行异常,将异常消息写入日志,任务json重新写入队列,并附加已传输的次数,实现文件有限次数的重传。
(3)执行线程设置了超时中断,当任务阻塞时,线程超时,中断线程回收资源,任务json重新写入队列。
(4)消息中间件作为任务执行的缓存器,只有一个监听线程,配置有限个消费者,避免了大量任务同时执行造成的IO压力。
2.4 字符集转换算法
由于文件管理的数据源于不同用户的文件上传,系统无法控制用户上传的中文文件名字符集,如果不对中文文件名有效的处理,则会出现文件名乱码的情况,严重的将会影响到文件的读取,字符转换算法的核心是:
(1)正确匹配源文件的字符集读取文件,此处可以根据用户设定的字符集或者用JCharDet算法识别,JCharDet是基于统计概率的识别方法,通过计算字符集转换后字符出现的概率,判断是否乱码、识别出字符集。
(2)负责转换的服务器操作系统字符集为最为完备的字符集,编码范围至少包含了源与目标目录的字符集,该系统设定为utf-8,以免在字符集转换的过程中发生了信息丢失。
(3)将正确读取的文本以目标目录字符集写入到目标目录。
3 试运行
系统为业务网提供了完备的文件处理服务。随着新业务网建设周期,不断的优化建设系统。通过统计2021年8月到10月的运行,日均同步文件数量144 264个,总计大小23 GB、搜索接口访问231次。在千兆网络带宽、64核CPU、64 g内存、ssd存储的配置条件下,对系统的最大负载做了测试,分析了系统的文件处理、接口服务的最大负载能力,系统运行在最大负载的情况下,仍能够稳定运行。通过与原业务网分散的文件处理功能对比,系统最大负载能力如表2所示。

表2 最大负载性能对比
在管理效率上,通过系统的监控模块实现自我监控,监控消息通过服务接口对接值班辅助理平台,纳入了值班监控;与原系统相比,通过分析值班员人工记录的日志。对文件故障的发现时间减少了约33%;系统的文件接口,增加了信息认证,文件的同步,不依赖第三方软件,有效的提升了安全性;集约的文件处理功能,实现了原业务网3个系统功能,减少了运维的工作量,优化了业务管理。系统还弥补了原业务网系统中中文字符集转换、全文搜索等缺失的功能,解决了业务上的需求。
