基于SSD的轻量级车辆检测网络改进
2022-06-23杨德刚蒋倩倩何林晋
徐 浩,杨德刚,蒋倩倩,何林晋
重庆师范大学 计算机与信息科学学院,重庆 401331
车辆检测是近年来目标检测领域中一个热门的研究方向,其广泛应用于智能交通、车流统计、拥堵监控系统之中。传统方式的目标检测算法一般采用梯度直方图(histogram of oriented gradient,HOG)[1]或尺度不变特征(scale-invariant feature transform,SIFT)[2]等作为特征提取方法,再使用支持向量机(support vector machine,SVM)[3]或Gadient Boosting[4]和Adaboost[5]等自适应分类器对特征进行分类,整个检测流程较为复杂且基于人工设计的特征提取方法难以提取出鲁棒性强的特征。近年来,随着深度学习算法的不断发展[6-7],检测的精确率不断提升,并逐渐取代了传统的目标检测方式,但在面对实际应用时,基于深度卷积神经网络的检测模型还存在着占用硬件内存空间、计算耗时、检测效率不高等方面的问题。终端摄像设备由于成本低廉,便于部署,维护简单等特性被广泛安装于各个城市的交通干道之上,随着万物互联时代的到来,各种终端设备不断接入互联网,将检测任务从云端卸载到边缘端有利于缓解网络传输压力、降低数据传输风险、保护数据隐私安全,输入设备采集到的数据直接在本地进行处理,能够避免网络波动带来的延时,使任务响应更加迅速,但目前大部分嵌入式设备上的算力很难支撑深度卷积神经网络模型的实时运行,并且由于车辆具有快速移动的特性导致算力紧张的嵌入式的设备并不能准确、及时地捕捉移动中的车辆并返回检测结果。
针对这一问题,本文结合残差网络(residual networkv2)[8]以及通道注意力网络(squeeze-and-excitation networks,SENet)[9]提出一种改进的轻量级特征提取网络,并根据输入图像大小及特征图感受野简化特征融合层数量,针对实际应用中特定角度下的车辆检测任务重新设计默认框(default boxes)生成比例,在降低计算量的同时提升模型检测效率,使得算力较低、存储空间有限的嵌入式摄像设备也能部署基于深度学习的目标检测模型进行车辆检测任务并及时返回检测结果,为以后的移动和嵌入式的智能监控设备提供一套轻量级的类实时车辆检测参考系统。
1 传统的SSD检测模型
SSD(single shot multibox detector)目标检测模型[10]是一种单阶段(one-stage)目标检测方法,该模型由两部分构成,前半部分由深度卷积神经网络来提取图像特征得到多个不同尺度的特征图(feature map),后半部分采用类似于特征金字塔网络(feature pyramid networks,FPN)[11]结合多个不同尺度的卷积层输出进行特征融合,对大小不同的目标进行定位和分类。SSD论文中使用VGG-16[12]作为特征提取网络并将后两层全连接层替换为卷积层(如图1中的Conv6和Conv7),之后分别在38×38、19×19、10×10、5×5、3×3和1×1的卷积层上做特征提取得到不同尺度特征图,如图1所示。最后将6层不同尺度的特征图依次送入分类网络和回归网络中对不同大小目标的位置和类别进行回归预测。
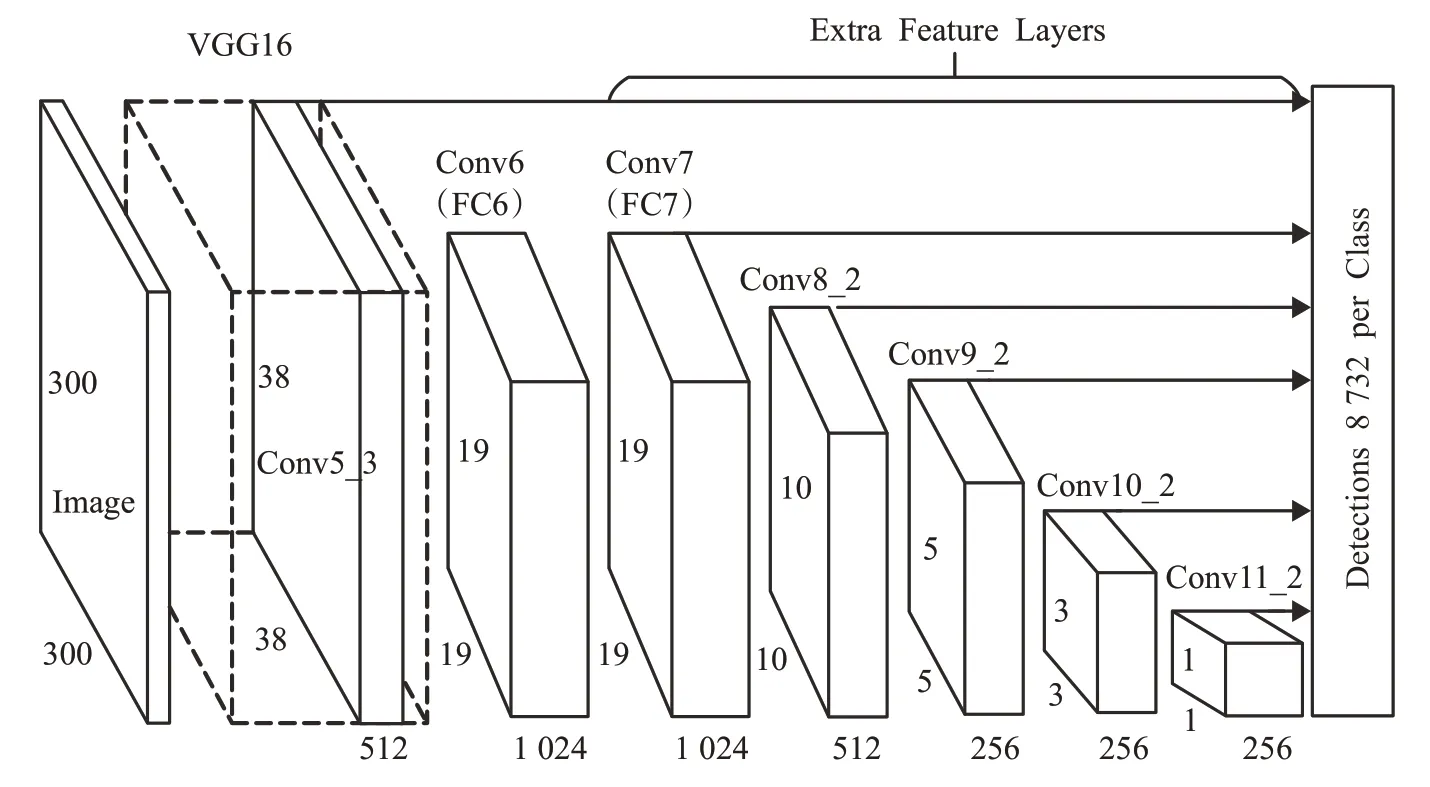
图1 SSD检测模型Fig.1 SSD object detection model
SSD检测算法的损失函数由位置损失Lloc和置信度损失Lconf两部分加权求和取得,计算公式如式(1):
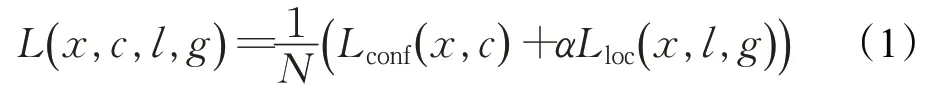
其中,x为默认框与真实框的匹配结果,c为每个类别置信度,l为检测网络预测框,g为真实目标标注框,N为匹配正样本总数,α为位置损失的权重,该损失函数的详细定义可参考文献[10]。
2 改进的SSD目标检测模型
经典的SSD检测模型采用VGG-16网络导致网络参数量庞大、运行时占用内存多等问题,为了在有限的计算资源平台上实现目标检测任务并做出及时的检测结果反馈,需对原始SSD检测模型的特征提取网络及多尺度特征层进行精简优化。本文使用改进后的通道注意力模块(squeeze-and-excitation block,SE block)结合改进后的残差连接块(residual blockv2)作为SSD检测模型的前端特征提取网络,以及根据实际应用中在特定拍摄角度下车辆外形的长宽比特征重新设计SSD检测模型的默认框生成比例并结合特征图感受野范围简化特征图融合层,降低算法运算复杂度,适应未来嵌入式摄像设备实时检测移动车辆的应用需求。
2.1 通道注意力模块
SE block主要根据每个通道对于目标的重要程度进行学习,强化对当前检测任务有正向作用的通道特征并抑制对当前检测任务作用较小的通道特征,在不影响现有网络模型的基础上通过压缩(squeeze)和激励(excitation)操作来重新标定之前的卷积结果U,得到新的卷积结果X͂,SEblock工作原理如图2所示。
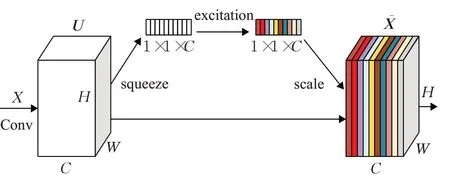
图2 注意力模块Fig.2 SEblock
图2中U∈RH×W×C,X͂∈RH×W×C。首先在原始卷积结果U上执行Squeeze操作,使用全局平均池化(global average pooling)[13]对每一个通道上的所有特征点计算一个平均值,使得每一个通道都压缩为一个具有全局感受野实数,其计算公式如式(2):
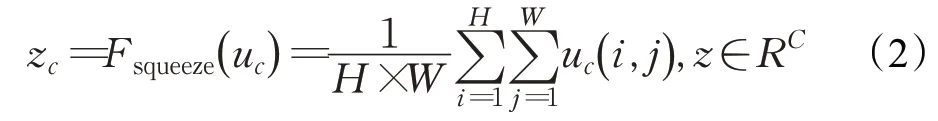
接着进行Excitation操作,对每个通道的重要性进行预测,其中第一个全联接层(fully connected layers,FC)层先对数据进行降维,并使用ReLU激活函数对输出结果进行非线性变换增强数据的表达能力,第二个FC层用来还原数据初始的维度,其计算公式如式(3):
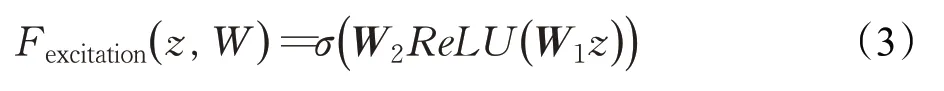
对于原始的SE block模块,本文将Excitation操作最后一层的sigmoid激活函数如式(4),替换为用ReLU[14]函数表示的分段线性函数h-sigmoid如式(5):
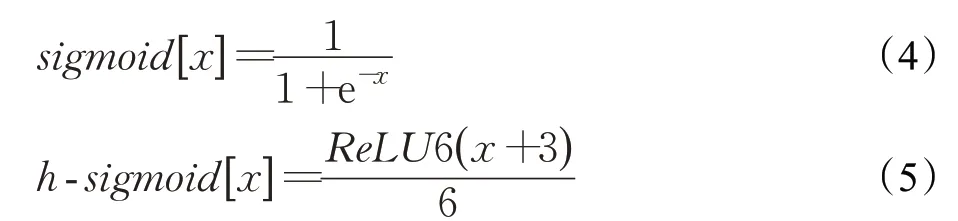
以降低部分计算成本,其函数图像对比如图3所示。由于ReLU函数计算简单并且在量化模式下可以消除由于编程实现方式不同带来的数值精度损失[15],而sigmoid激活函数中的指数运算在反向传播更新梯度时求导存在除法运算较为消耗计算资源,为了缩短模型训练时间以及在算力有限的嵌入式设备中加速推理速度,使用h-sigmoid激活函数将更符合车辆检测任务中快速检测的需求,改进后的注意力模块如图4所示。
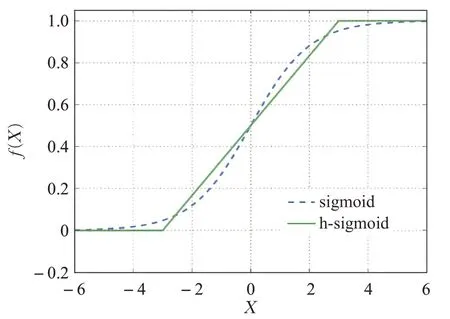
图3 sigmoid对比h-sigmoid激活函数Fig.3 sigmoid vs h-sigmoid
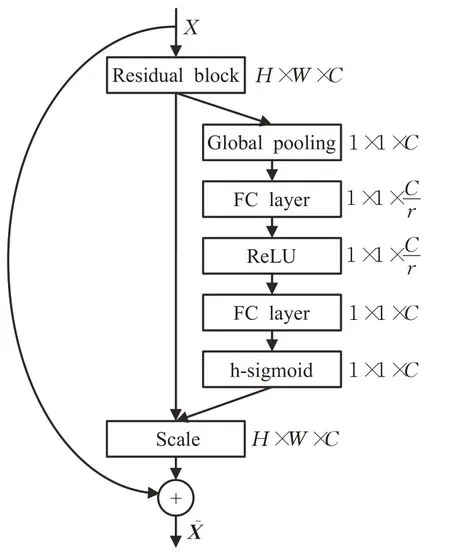
图4 改进后的注意力模块Fig.4 Improved SE block
2.2 残差连接块
理论上神经网络层数越深,拟合复杂数据模型的能力就越强,但实际在训练深层卷积神经网络时存在着梯度消失或梯度爆炸的问题,导致深层的卷积神经网络难以训练,针对这一情况He等人[7]提出的残差神经网络,在卷积块之间加入恒等映射(identity mapping)的方式使浅层信息可以传达到深层网络,反向传播更新权重时深层网络的梯度信息也可以通过捷径连接(shortcut connections)传回浅层网络从而训练出更加鲁棒的网络权重,在残差块中的激活函数是深度学习的核心单元也是深度卷积神经网络成功的原因之一,更为有效的激活函数虽然在每层中只有少量的拟合能力提升,但会因为在整个模型中的大量使用而获得更强的数据拟合能力,本文将SSD检测模型的特征提取网络从VGG-16替换为了结合注意力机制的残差网络,并将残差块中的ReLU激活函数替换为h-swish激活函数,h-swish是Howard等人[15]提出用于逼近swish的硬性分段函数,计算公式如式(6),swish激活函数是Google Brain团队在2017年提出的一种新的激活函数,计算公式如式(7),swish与h-swish函数图像对比如图5所示。
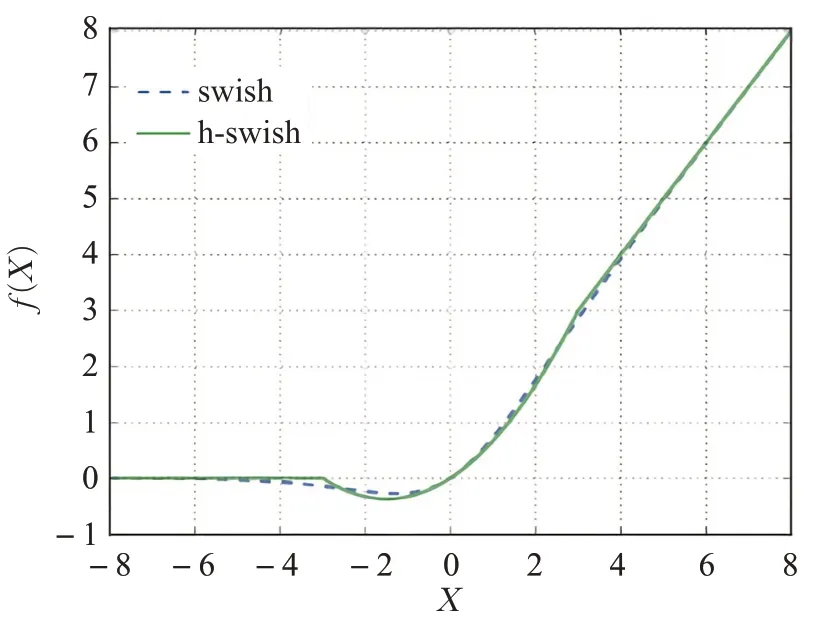
图5 swish与h-swish激活函数Fig.5 swish vs h-swish
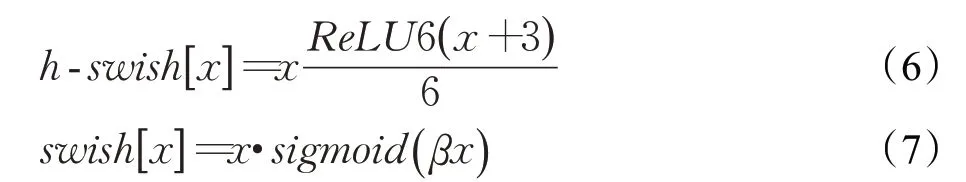
swish激活函数相较于ReLU激活函数能够有效提高网络模型检测的精度[16],但swish激活函数中存在着指数运算计算成本较高,在算力较低的设备上计算耗时较长,在实际车辆检测任务的应用场景中需要及时返回结果,本文使用计算更为简单的h-swish激活函数替换残差块中的ReLU激活函数,用来模拟swish激活函数所达到的非线性激活效果,并在改进的残差块中加入注意力模块得到改进后的注意力残差模块(SE-residual block)如图6(b)所示,与传统的Residual block对比如图6所示。

图6 残差块对比Fig.6 Residual block comparison
相较于传统的Residual block,Residual blockv2中把批标准化(batch normalization,BN)[17]层和激活函数层提到卷积层之前,在执行卷积操作之前先把数据进行规范化以提升训练效率,传统的Residual block中在addition操作之后使用了ReLU函数进行非线性激活,由于ReLU激活函数非负的特性,导致数据在残差块间前向传播时只能单调递增,限制了特征的表达能力,Residual blockv2中把addition操作后的ReLU激活函数移动到addition操作前,文献[8]表明卷积前激活(pre-activation)能够达到更好的训练效果。
2.3 默认框选择
SSD检测模型中采用了类似Faster-RCNN[18]中的锚框(anchor boxes)机制,对于同一特征层上的默认框使用不同的宽高比,设默认框的宽高比为ar,默认框的宽为,默认框高为,且当ar=1边长为min-size时添加一个边长缩放为的默认框,如图7所示。
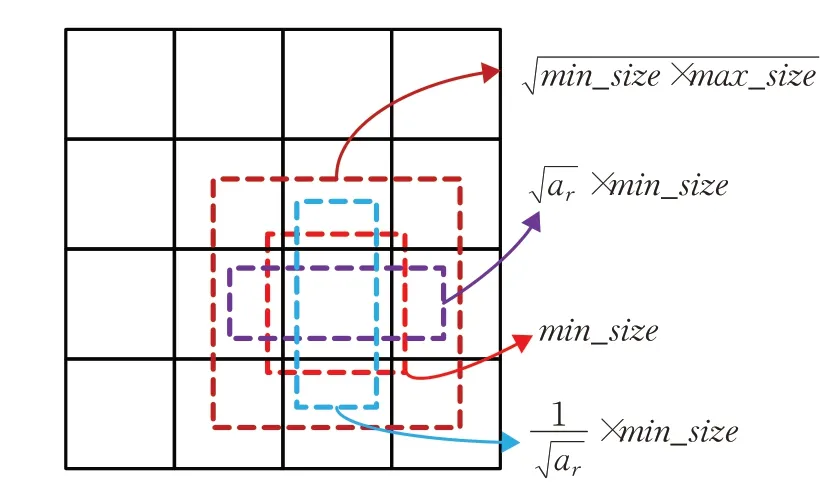
图7 默认框生成原理图Fig.7 Generate default box
默认框尺寸计算公式如式(8):
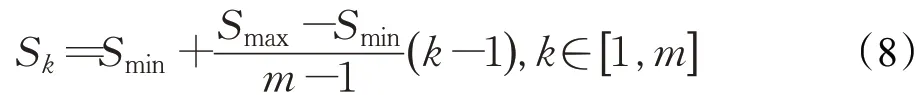
其中,m为模型检测中采用的特征图层数,Smin为设计好的最小归一化尺寸,取值为0.2,Smax为设计好的最大归一化尺寸,取值为0.9,Sk为第k个特征图的min-size为参数,Sk+1为第k层的max-size参数,Feature map上每个点生成默认框的中心为,其中|fk|为第k个正方形特征图大小i,j∈[0,|fk|)。
在模型训练阶段,多数情况下正样本数量占比相对较少,存在着正负样本不均衡的问题,而传统的SSD算法中只对负样本数量进行了筛选,为了保证训练效果更加高效,采用Focal Loss[19]替换分类网络中的Softmax损失函数,以减小易分样本损失对总损失的影响。在模型部署阶段,由于嵌入式摄像设备一般安装于车辆行驶路面的正上方,检测车辆时为正面俯视角度,根据摄像头实际应用中安放位置和训练所用数据集得到的固定拍摄角度的车辆特性对默认框比例进行重新设计,利用先验知识判定特定在正面俯视角度下的完整车辆宽高比参数ar≤1,但由于捕获延迟和拍摄时刻不同的问题,存在部分车辆的顶部或底部未包括在图像中或只包含车辆的顶部或底部,区域候选框宽高比ar取值设定为{1,2,1/2,2/3,2/5}。
2.4 改进后的SSD网络结构
改进后的SSD特征提取网络主要在ResNet18残差网络结构的基础上结合和通道注意力模块将Residual block替换为改进后的SE-Residual block,并在全局平均池化之前新增加了一个注意力残差块用于增强模型的数据表达能力及提升特征图的感受野,最终得到SE-ResNet20特征提取网络,其主要由9个SE-Residual block组成,每个块中包含了两组完整的卷积模块,在卷积模块中首先进行批标准化处理(batchnorm)规范化数据,然后采用h-swish激活函数进行非线性变换,最后使用3×3的卷积核对特征图进行卷积操作,在输入图像大小为512×512时每层卷积具体参数如表1所示。
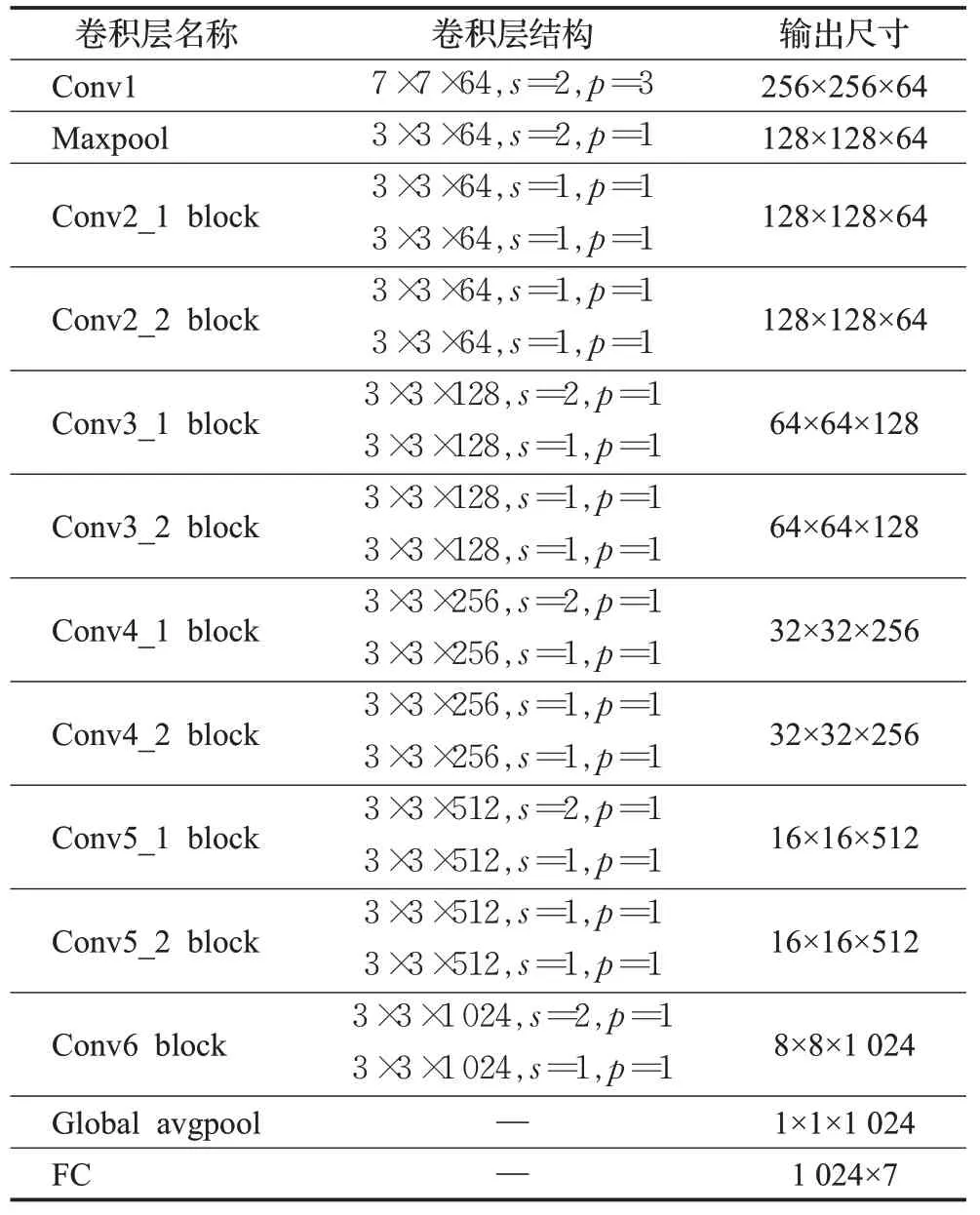
表1 SE-ResNet20网络结构Table 1 SE-ResNet20 network structure
改进后的SE-ResNet20由19个卷积层加上1个全连接层组成,在残差块中,当输入和输出维度相同时则直接将输入通过跳跃连接加到输出中,当输入输出维度不同时则通过步长进行下采样,在Conv3_1、Conv4_1、Conv5_1、Conv6的第一层卷积中使用stride=2进行下采样并进行通道升维使通道数量翻倍,接着使用全局平均池化得到一个1×1大小的具有全局感受野的特征向量,最后根据数据集中车辆的类别加上背景类共分为7类,得到1 024×7的特征输出,改进后的SSD检测模型如图8所示。
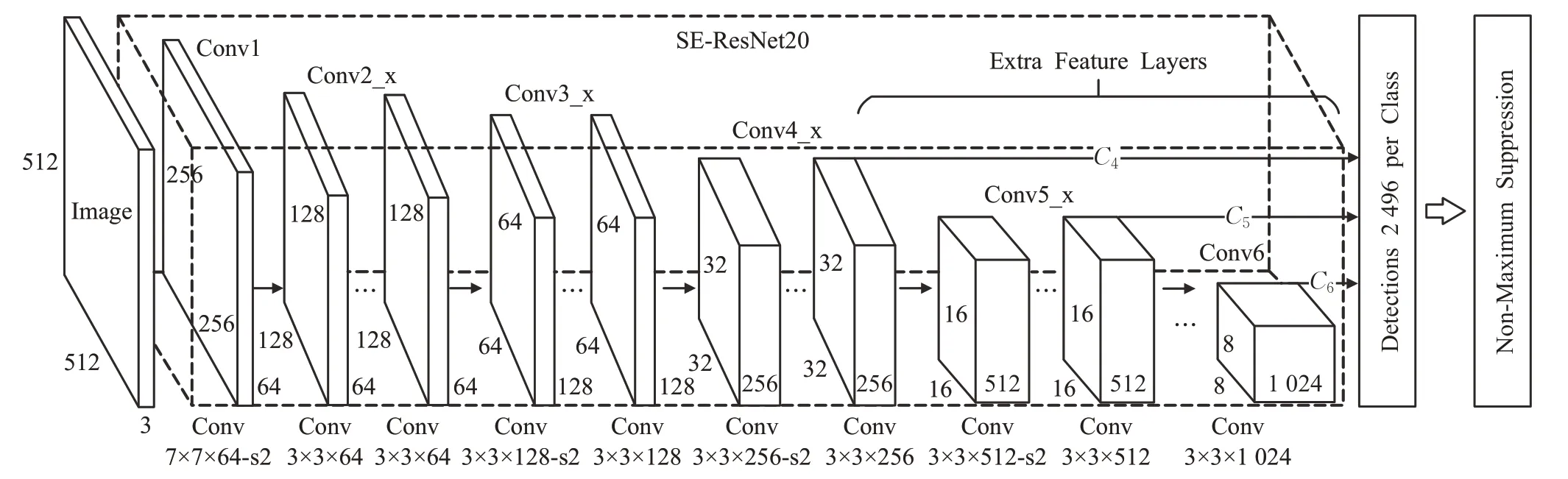
图8 改进后的SSD目标检测模型Fig.8 Improved SSD object detection model
设特征图大小为n×n,第n次下采样后的特征图为Cn,在特征图的每个点上都设置k个不同比例的默认框,则单层特征图生成默认框的数量为n×n×k。传统的SSD目标检测模型选取6个特征图的k值分别为4、6、6、6、4、4,在使用512×512大小的输入图像下计算得到24 528个默认框。本文在训练数据集中采用Kmeans聚类算法并设置K=7,通过标注的位置信息得到7类不同的先验框,其相对百分比范围为0.118 4~0.514 2,若采用512×512的大小输入图像,其真实框大小为60.6~263.2。通过感受野(effective receptive field)计算公式(9):
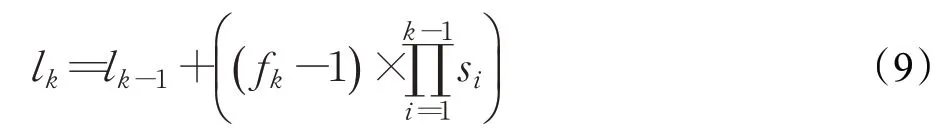
C4的感受野为64,C5的感受野为128,C6的感受野为256,结合感受野范围大小改进后的模型在C4层使用ar为{2}的默认框,在C5层使用ar为{1,2,1/2,2/3,2/5}的默认框,在C6层使用ar为{1,1/2,2/3}的默认框,在采用同为512×512大小的输入图像中,改进后的SSD目标检测模型默认框为2 496个,相较于传统的SSD目标检测模型默认框总数仅为其1/10,具体计算量如表2所示,更少的默认框匹配量可能导致在目标位置回归精度上存在部分损失,但能够减少大量计算提升检测速度。
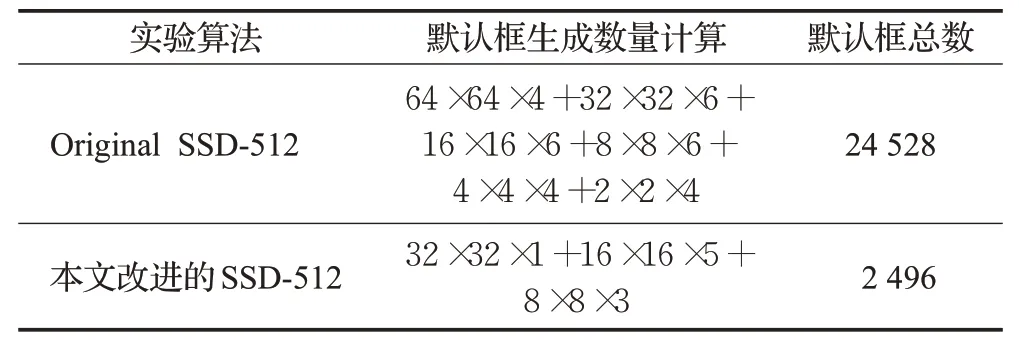
表2 默认框生成数Table 2 Default box number
3 实验对比及分析
实验所采用的软件环境为Ubuntu18.04操作系统,Python版本为3.7.4,深度学习开发框架MXNet1.6.0版本,深度学习加速库为NVIDIACUDA10.0和cuDNN7.6.5版本,优化工具套件OpenVINO为2021.1版本;训练及测试硬件平台为Intel Corei9-9900K处理器,NVIDIAGeforce 1080Ti11G显卡,32 GB运行内存的主机;部署硬件平台为Raspberry PI 3B+,Intel神经计算棒(NCS2)。
其中树莓派Raspberry PI 3B+是Raspberry PI基金会开发的一款基于ARM处理器架构的卡片式低功耗电脑主板,搭载博通BCM2837B0处理器,1GB LPDDR2 SDRAM板载内存以及USB、RJ45、HDMI、CSI、音频等丰富的外置扩展接口,通过Micro-SD卡槽可扩展存储空间容量。IntelNCS2是Intel公司推出的低功耗AI协处理器设备,是一款基于USB模式的深度学习推理工具,被广泛应用于边缘计算场景中提供专用的深度神经网络处理性能,通过USB接口可以连接在Raspberry PI 3B+上提供神经网络推理加速功能,实验设备如图9所示。

图9 实验部署设备Fig.9 Experimental deployment equipment
实验设置每批次(batch size)训练样本图片为32张,优化器使用SGD(stochastic gradient descent)[1]算法,动量(momentum)设置为0.9,权重衰减系数(weight decay)设置为0.000 1,学习率(learning rate)初始值设置为0.001,迭代到100个Epochs之后每50个Epochs学习率减少为之前的0.2倍,迭代300个Epoch后结束训练得到权重文件。改进后的SSD检测模型与传统SSD检测模型的损失函数下降如图10所示。
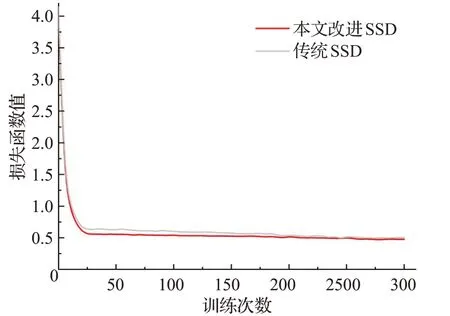
图10 损失函数下降图Fig.10 Loss function
模型训练完成后将在主机上训练好的MXNet模型文件.params和.json文件通过OpenVION工具套件对其进行优化,得到Intel NCS2能够识别并加速的IR文件并进一步将IR文件的数据类型从Float32量化到INT8数据类型,由于模型训练时正反向传播中每次梯度更新的数值比较小,因此需要较高的数据存储精度来表示,在模型训练完成后的推理阶段中权重数值精度对整个推理结果影响较小,不会对整个检测模型的结果精度造成较大损失,通过模型量化可以减少推理阶段的计算量以提升推理速度。最后将量化后的模型文件及权重部署到通过USB接口连接NCS2的树莓派3B+上,部署实验参考文献[20]作出部分调整,实验流程如图11所示。
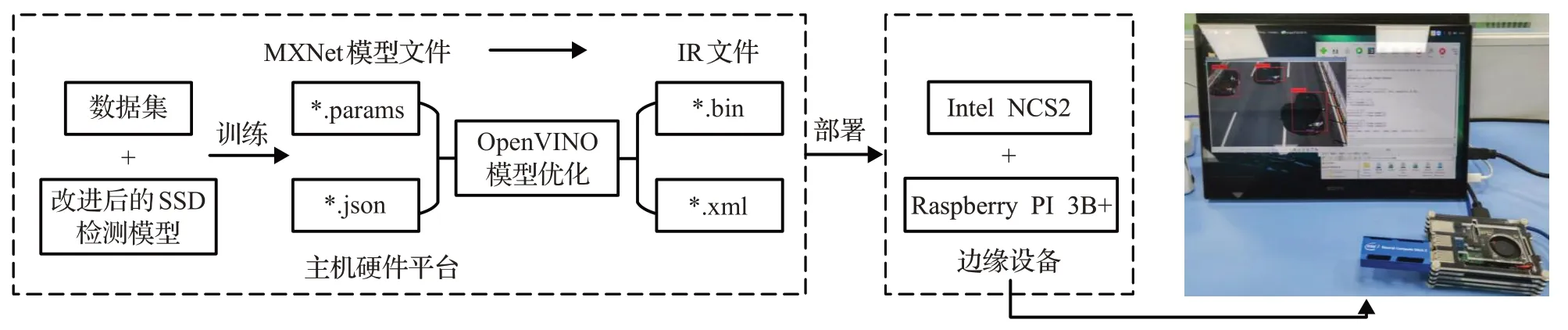
图11 实验流程图Fig.11 Experimental procedure
3.1 实验评价指标
BIT-Vehicle Dataset[21]是北京理工大学制作提供的车辆检测公开数据集,采集的图像均为路面车辆正面俯视图,车辆类型总共包含六类车辆共9 850张,分别为公交车(bus)、小型客车(microbus)、小型货车(minivan)、轿车(sedan)、运动型多用途汽车(SUV)和卡车(truck),每类对应数量分别为558、883、476、5 922、1 392和822。实验按照8∶2的比例把数据集分为训练数据集和测试数据集,并且为了增强训练所得到模型的鲁棒性,在训练集中采用了水平翻转、随机扩展、剪裁等数据增强策略共得到15 760张带有标签的训练数据集,部分训练数据集图片如图12所示。

图12 数据增强后的部分训练集图片Fig.12 Enhance dataset
实验使用平均精度均值(mean average precision,mAP)、平均检测速度、模型参数量大小、运行时占用内存大小作为模型的评价标准。
其中mAP计算公式如式(10):

其中,Q为类别总数,AveP(q)为第q类物体的平均精度(AP)。AP由准确率(precision,P)与召回率(recall,R)计算得到,其计算公式如式(11)、(12):

其中,TP表示被正确识别为正样本的数量,FP代表被错误识别为正样本的数量,FN表示被错误识别为负样本的数量。
模型检测速度:采用在测试数据集中检测每张图片平均耗费的时间,单位为毫秒(ms)。
模型参数量大小:训练完成后的整个网络模型及网络模型参数的大小,单位为兆字节(MB)。
运行时占用内存:检测模型运行过程中所占用运行内存(RAM)的空间总大小,单位为兆字节(MB)。
在要求及时反馈检测结果的目标检测任务中,模型检测速度直接影响检测结果是否能稳定可靠,在算力及存储空间有限的终端设备上检测模型参数量大小和运行时占用内存大小则直接影响终端硬件成本。
3.2 实验结果对比
实验统一采用缩放至512×512大小的图像作为车辆检测模型的输入尺寸进行实验,改进后的SSD目标检测模型在数据集BIT-Vehicle上的mAP可以达到94.87%,实验数据如表3所示。在保持其余外部条件不变的情况下,实验对比了改进后的SE-ResNet20网络与SSD原论文中采用的VGG-16网络以及ResNet18 v2网络和Howard等人于2019年提出的轻量级网络MobileNetv3作为特征提取网络时SSD目标检测算法性能对比,实验数据如表4所示。

表3 BIT-Vehicle Dataset检测精度Table 3 BIT-Vehicle Dataset detection precision %
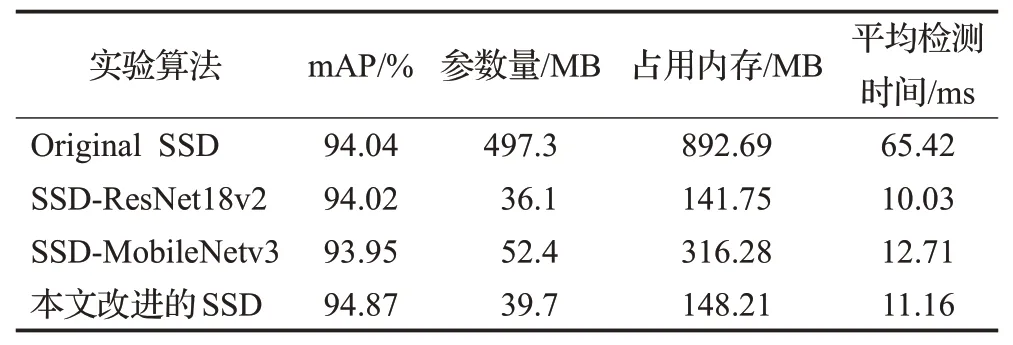
表4 不同网络模型性能对比Table 4 Performance comparison of different detection models
由于在数据维度不一致时MobileNet和ResNet采用的两种不同的策略,MoibleNet中使用增加1×1的卷积核用来达到数据的升维和降维,更多的卷积核会导致模型参数量及内存占用量较大,而在ResNet中则是采用步长进行下采样,不会增加额外的参数。参数量越多代表着访问内存的时间及次数也将更多,对于每一层卷积,设备都需要从内存中读取特征值,进行卷积运算时也需要从内存中读取每层的权重,在计算完成之后还需将新的特征值写回内存,由于计算机内存读写存在耗时,内存中数据读写量越大所消耗时间就越多,通常情况下模型的权重文件越小,模型在实际运行时的检测速度就越快。相较于ResNet18v2网络,加入通道注意力模块和替换激活函数后的SE-ResNet20增加了约10%的参数量以及约1 ms的推理时间,但在mAP上提升了0.85个百分点。
模型训练完得到固定的权重之后,实验将同一张图片分别输入传统SSD采用的VGG-16网络与改进后的SE-ResNet20网络进行特征可视化,特征可视化结果如图13、14所示,VGG-16网络中采用第2、4、7、10、13层卷积层的结果,SE-ResNet20网络采用C2、C3、C4、C5、C6的卷积层结果,从特征可视化结果可以较为直观地看出,改进后的SE-ResNet20网络相较于VGG-16网络有更好的特征提取能力。

图13 VGG-16特征可视化Fig.13 VGG-16 feature visualization
SSD目标检测模型改进前后检测效果如图15所示,图15(a)为经典的SSD检测模型识别效果,图15(b)为改进后的SSD检测模型识别效果。

图15 检测效果对比Fig.15 Comparison of detection effect

图14 SE-ResNet20特征可视化Fig.14 SE-ResNet20 feature visualization
从检测效果来看,改进后的SSD检测模型对位于图像中心部分的完整车辆信息有更好的检测效果,但对位于图像边缘的残缺车辆信息检测准确率及位置回归精度较低,画面边缘小目标检测效果不佳的原因可能在于C4特征图的有效感受野仅为64,且为了提升检测效率在C4特征图上的默认框宽高比只使用了ar=2的比例,在图像边缘的小物体检测上原SSD检测算法融合了感受野更小的特征图以及更多默认框比例,可以得到更精确的位置信息,由于在车辆快速行驶过程中摄像头捕捉到的车辆图像只有短暂时间位于画面边缘部分,对整体的车辆检测任务影响较小。
从实验得到的检测结果数据可以发现,经过本文改进的SSD目标检测模型较传统的SSD目标检测模型在检测速度和检测平均精度均值上均有所改进,改进后检测模型的平均检测时间下降了54.26 ms,模型参数文件减少了457.6 MB。在检测模型实验部署阶段通过OpenVINO工具套件把32 bit的浮点型权重值量化为8 bit的整数型权重,进一步减少检测模型的权重文件所占用的存储空间,完成量化后的模型权重文件大小从39.7 MB压缩到了11.6 MB。
4 结束语
针对目前的嵌入式摄像设备难以运行基于深度学习的目标检测任务的问题,提出了基于残差连接和通道注意力机制的轻量级SSD车辆检测模型,改进后的SSD检测模型参数量仅为传统SSD检测模型的1/12。实验在BIT-Vehicle Dataset上对道路车辆检测mAP达到94.87%,与原SSD模型mAP相比提升了0.83个百分点,平均检测时间下降了54.26 ms,最终在实验选定的边缘设备上可以达到平均16 frame/s的检测速度,对于嵌入式设备识别快速移动车辆效率不高的问题得到改进,为以后的智能交通场景中实时的车辆跟踪、车流统计、拥堵检测等应用提供了参考。
