基于ALBERT-AFSFN的中文短文本情感分析
2022-06-23叶星鑫罗梦诗
叶星鑫,徐 杨,2,罗梦诗
1.贵州大学 大数据与信息工程学院,贵阳 550025
2.贵阳铝镁设计研究院有限公司,贵阳 550009
情感分析任务属于自然语言处理领域中重要的文本分类任务[1-3]。情感分析任务在不同的领域中扮演着不同的角色,也发挥着不同的作用。对于电商商家而言,可以给他们提高自身竞争力提供合理建议;对于消费者而言,可以给他们选择物美价廉且适合自己商品提供重要参考;对于政府而言,通过对公众舆论进行情感分析是他们把握舆论动态、调整政策的重要依据。目前无论是在电商领域,还是在政府平台情感分析都有着实际且广泛应用,但是受到语言多样性、随机性,以及不断出现的新鲜词汇等因素的影响,中文短文本情感分析任务仍然具有挑战性且具有极大的研究价值。
情感分析任务包含两个重要的步骤[4],分别是文本特征提取与表示和文本特征分析与分类。针对文本特征的提取与表示,许多研究者花费了大量的时间和工作进行研究。Mikolov等[5-6]在2013年提出了Word2Vec模型对文本特征进行表示,Pennington等[7]在2014年提出了Glove(global vectors)模型对文本特征进行表示,以上两种方法虽然解决了维度灾难问题,但是它们均采用静态方式对文本特征进行表示,并未考虑文本的位置信息,也不能解决一词多义问题。随着预训练语言模型在自然语言处理领域的发展,Peters等[8]提出了ELMO(embeddings from language models)、Radford等[9]提出了GPT(generative pre-training)、Devlin等[10]提出了基于Transformers的双向编码器表示预训练模型BERT(bidirectional encoder representations from transformers)、Lan等[11]在2019年提出了轻量化的BERT模型ALBERT(a lite BERT),该模型在BERT的基础上,采用双向Transformer作为特征提取器获得文本的特征表示,有效利用了文本的语义信息和位置信息,并且将NSP任务升级为SOP任务,在提升各个任务的准确的同时也通过因式分解与参数共享两个技术减少了模型的参数量,缩短了训练时间。
情感分析的文本特征分析方式一般包含三种,分别是基于情感词典和规则[12-13]的方法、基于传统机器学习[14-15]的方法和基于深度学习的方法。前两种方法实现简单,容易理解但是泛化能力和迁移能力差,准确度不高,因此基于深度学习的情感分析方法越来越受关注。Mikolov[16]、Kim[17]、Zhou[18]等先后提出了循环神经网络(Recurrent Neural Network)、文本卷积神经网络TextCNN(text convolutional neural network)、基于注意力的双向长短期记忆网络Att-BiLSTM(attention-based long short-term memory networks),提高了文本分类的准确率,但是它们迁移能力弱,针对不同的应用领域需要重新训练和学习,这将会花费大量的人力、物力和财力,因此也限制了文本情感分析的进一步发展。
综上所述,为了更好地应用文本的语义信息、位置信息以及通道间的关联信息,提升模型对文本的情感分析能力,本文提出了结合ALBERT和注意力特征分割融合网络(ALBERT-attention feature split fusion network,ALBERT-AFSFN),在文献[19]的分割注意力网络(split attention network)中嵌入文献[20]的注意力特征融合(attention feature fusion,AFF)策略,从而提升其在不同通道间的特征提取和融合的能力。本文的主要贡献如下:
(1)对分割注意力模块进行改进,在分割注意力模块中嵌入有效的注意力特征融合模块,解决不同尺度特征的融合问题,并使其更适合用于捕获文本中不同通道间的情感信息。
(2)把改进的模块结合到ALBERT网络结构中,使其有效利用文本的语义信息和位置信息,提高文本的分类准确率。
(3)模型在三个数据集Chnsenticorp、waimai-10k和weibo-100k上实现了具有竞争力的性能。
1 ALBERT预训练语言模型概述
ALBERT本质上是一个轻量化的BERT模型。如图1所示,其主要由输入层、词嵌入层、特征编码层和输出层组成。词嵌入层主要将输入的向量化文本的内容信息、位置信息和句子信息进行融合;特征提取层主要采用了双向的Transformer编码器对语料库进行特征提取表示,该编码器的核心是多头注意力机制。
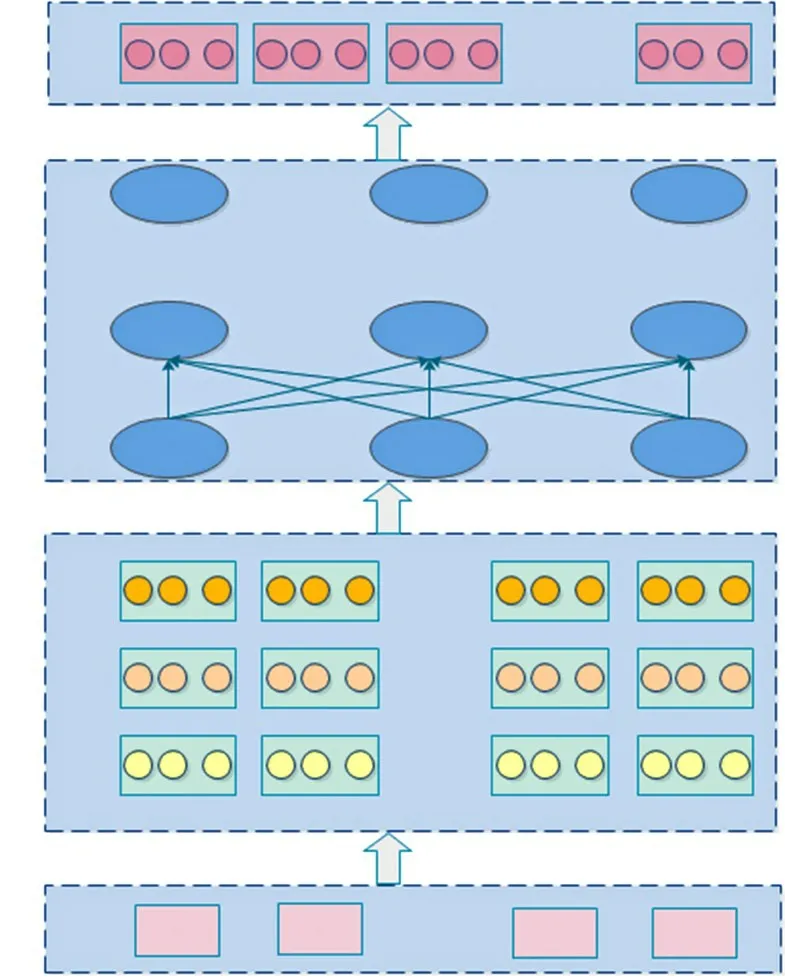
图1 ALBERT预训练语言模型结构Fig.1 Structure of ALBERT
ALBERT除了保留BERT模型结构的优点外,还在此基础上做了两点改进:(1)通过使用嵌入层因式分解(embedding factorized embedding parameterization)和跨层参数共享(cross-layer parameter sharing)两个技术减少了BERT模型的参数量,缩短了训练时间。(2)将任务NSP(next sentence prediction)换成更出色的SOP(sentence-order prediction)任务,在避免了话题预测的同时迫使模型学习更细粒度的语篇层次连贯性差异,提升了模型的效果。
综上所述,ALBERT相对于BERT而言,其参数更少,对语义特征提取能力更强,更加适合于本文的短文本情感分析任务。
2 本文模型
2.1 模型概述和工作流程
本文提出了结合ALBERT和注意力特征分割融合网络模型。如图2所示,其主要由输入层、ALBERT层、注意力特征分割融合网络层、全连接层和Softmax层组成,该模型的主要工作流程如下:
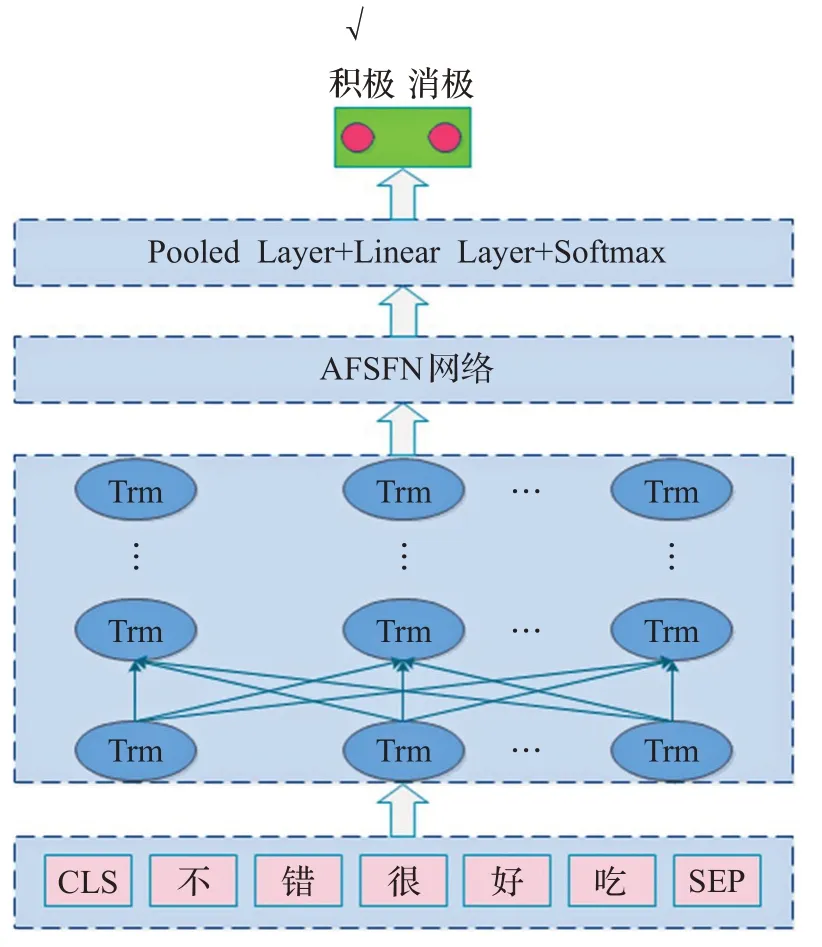
图2 ALBERT-AFSFN模型结构示意图Fig.2 Structure of ALBERT-AFSFN module
(1)对输入的数据进行预处理,并在输入文本的开头和结尾分别加上特殊字符[CLS]和[SEP],通过输入层将输入文本内容表示成序列化的情感文本信息,最后将其输入到ALBERT网络中。
(2)ALBERT网络层通过双向的Transformer对输入序列的内容特征和位置特征进行提取,最终得到文本的特征表示。
(3)对ALBERT层输出的文本特征进行训练,首先将文本特征分为两组,再将这两组特征输入到注意力特征融合(AFF)层得到融合的特征表示,之后再将其继续通过全局池化层,全连接层得到特征矩阵,这个特征矩阵再拆分为两部分分别通过softmax层得到权重矩阵,最后再将权重矩阵与两组输入分别相乘后通过AFF层进行融合,得到最终的输出。
(4)将特征融合分割注意力网络层提取的特征通过两次全连接层,第一次全连接层输出的维度与ALBERT隐藏层维度大小相同,第二次全连接层输出的维度是情感文本的类别数,最后对输出结果进行Softmax归一化,得到情感文本的每一类的概率分布矩阵,按最大值进行索引,得到最终的文本情感分类标签。
2.2 改进的AFSFN网络
基本的分割注意力网络(split-attention networks,SAN)是一个计算单元,它由特征图组(feature-map group)和分割注意操作(split attention operations)组成,其首先将输入分割为几个特征组,之后再根据其简单的相加融合策略将分割后的几个特征组进行相加融合,之后在经过池化、全连接、激活函数激活等一系列操作后得到两个权重矩阵,最后将这两个权重矩阵与切割后的输入特征进行简单相加融合得到最终的输出。本文对分割注意力网络的特征融合策略进行了改进,即将其融合方式从简单的相加连接改为AFF方式连接,最大程度保留了不同通道之间的语义关联信息,加强了其特征提取和融合能力。从而得到了改进后的网络结构AFSFN,其结构如图3所示。
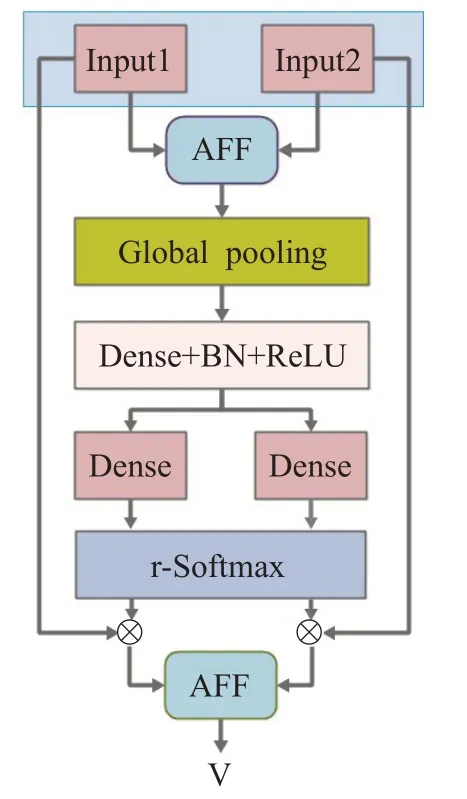
图3 改进的AFSFN模型结构图Fig.3 Imporved Structure of AFSFN
本文首先将输入特征分为两个组R(i∈1,2),用Ui(i∈1,2)表示,每组特征的通道数是c=C/2,之后再将两个组的特征进行注意特征融合,即将分割后的两个特征Ui(i∈1,2)输入到注意力特征融合网络AFF中进行融合并得到融合后的输出,输出的结果用F表示,计算公式如式(1)所示。通过分割注意力网络的最终输出Vc如式(2)所示。其中ai(c)是指在通道上通过r-Softmax的计算得出的权重系数,其由式(3)计算得出。
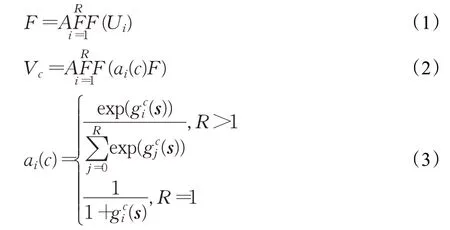
ai(c)中gc i是指通过两个全连接层和ReLU激活函数将s∈Rc参数化的注意力权重函数,s表示输入该网络的向量特征表示,其在c通道上的计算如式(4)所示:
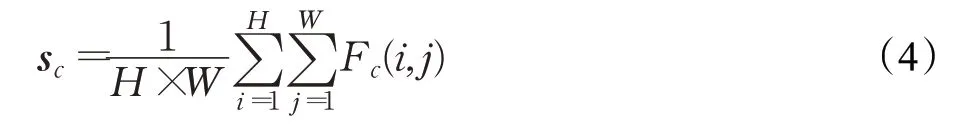
在改进的AFSFN模型中,最主要的模块是注意力特征融合模块,其结构如图4所示。AFF的核心结构是多尺度通道注意模块(multi-scale channel attention module,MS-CAM),核心思想是通过改变空间池的大小,在多个尺度上实现通道注意融合。其计算公式如式(5)所示:
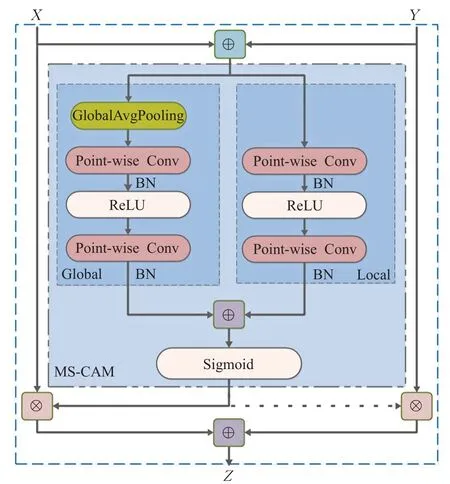
图4 注意力特征融合模块结构图Fig.4 Structure of attention feature fusion
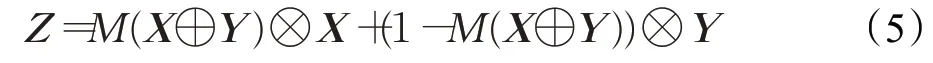
其 中X∈RC×H×W与Y∈RC×H×W表 示 输 入 特 征,Z∈RC×H×W表示通道注意力权重矩阵,M(⋅)表示MSCAM模块的运算和操作,C是特征的通道数,H×W是特征的尺寸大小,⊕是指将向量扩展成相同的维度后再进行加法运算,⊗是指将对应向量进行乘法运算。
为了使网络尽可能轻量化,MS-CAM模块仅仅聚合了局部上下文(local context)网络和全局上下文(global context)网络。其中局部上下文聚合层的计算如式(6)所示:
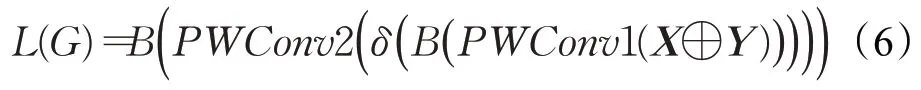
其主要采用了逐点卷积(PWConv)作为聚合器,利用了输入特征的每个空间位置的点式通道交互作用。全局上下文聚合层的计算方法与局部上下文聚合层类似,不同之处在于其一开始对输入进行了全局平均池化。
3 实验结果和分析
本文使用的框架是PyTorch1.6.0,操作系统是Ubuntu18.04,操作系统的显卡是NVDIA GeForce GTX 1080Ti,显存有11 GB。
3.1 数据集介绍
为了验证本文模型的优越性,本文选取了三个公共的数据集ChnSentiCorp、waimai-10k和weibo-100k进行验证。其中ChnSentiCorp语料库涉及酒店、笔记本与书籍三个领域的评论;waimai-10k语料库是取自百度外卖平台的评论,总共包含11 992条评论,其中正向评论3 900条,负向评论8 092条;weibo-100k是新浪微博上采集的大规模情感分析数据集,包含119 988条评论,正负向各59 994条。这些数据集正负情感倾向分布极为不均,因此本文使用下采样对文本进行了均衡处理,同时数据中存在大量的无关内容,如用户名、转发标记和URL等,本文使用正则表达式对数据进行过滤处理,得到的处理前及处理后的数据如表1所示。

表1 数据预处理展示Table 1 Display of preprocessing data
3.2 参数设置
本文模型主要参数包括两个部分,一部分是基础模型ALBERT的参数,本文采用谷歌发布的ALBERTBASE模型及其参数设置,另一部分是AFSFN部分的参数,本文将其卷积核大小设置为3×Embedding size,通道数设置为64。本文所有参数设置如表2所示。

表2 总体参数设置Tabel 2 Settings of total paraments
3.3 模型对比实验
为了对比模型的效果,评估模型的竞争性和优越性,本文采用以下三个模型与本文模型进行对比,各个模型的详情如下:
(1)TextCnn模型:采用文献[16]的TextCnn模型,本文使用了三个尺度不同的卷积核,其大小分别是3、4、5,通数都设置为64。
(2)Att-BiLSTM模型:采用文献[18]的Attention+BiLSTM模型,该模型是由注意力机制和双向长短期记忆网络组成。本文将隐藏层节点设置为768。
(3)ALBERT模型:采用文献[15]的ALBERT-BASE模型,该模型的参数设置与本文模型的参数设置相同。
(4)ALBERT-SAN:采用文献[15]与文献[19]的网络相结合,即将ALBERT与未改进的分割注意力网络SAN相结合。ALBERT模型的参数设置与本文其他模型相同,分割注意力网络SAN的特征图组(feature-map group)参数设置为1,基本组(cardinal group)参数设置为2。
(5)ALBERT-AFSFN模型:本文提出的结合ALBERT和改进的分割注意力网络的中文短文本情感分析模型。
同时本文选取了准确率(accuracy,A)、召回率(recall,R)和F1值作为验证指标。实验结果如表3所示。
通过表3的对比实验可以看出,结合ALBERT与原始分割注意力网络(ALBERT-SAN)的模型在三个数据集上的准确率、召回率和F1值均都有所提升,且在ChnSentiCorp数据集上得到了最好的准确率,在waimai-10k数据集上得到了最好的召回率,表明ALBERT-SAN网络是有优势的。为了进一步提升模型的表现力,本文对原始的分割注意力网络进行了改进,得到模型ALBERT-AFSFN。通过表3的实验结果可以看出该模型与传统的Att-BiLSTM、TextCnn网络相比有了大幅度提升,尤其是在小样本数据集ChnSentiCorp和waimai-10k上提升幅度较大,准确率的提升能达到3%左右,在大样本数据集weibo-100k上也能提升1%左右;相比于基本的ALBERT,本文提出的网络ALBERT-AFSFN无论是在准确率上,召回率上还是F1值上均提升1%左右,表明本文模型的优秀能力;相比于ALBERT-SAN网络,本文网络ALBERT-AFSFN在数据集ChnSentiCorp上的召回率和F1值是有优势的;在数据集waimai-10k上的准确率和F1值是有进步的;在数据集weibo-100k上的准确率、召回率和F1值均是有提升的,这些结果也进一步证明了通过AFF改进分割注意力网络,并让其与ALBERT相连接是有效果的,也是非常有必要的。
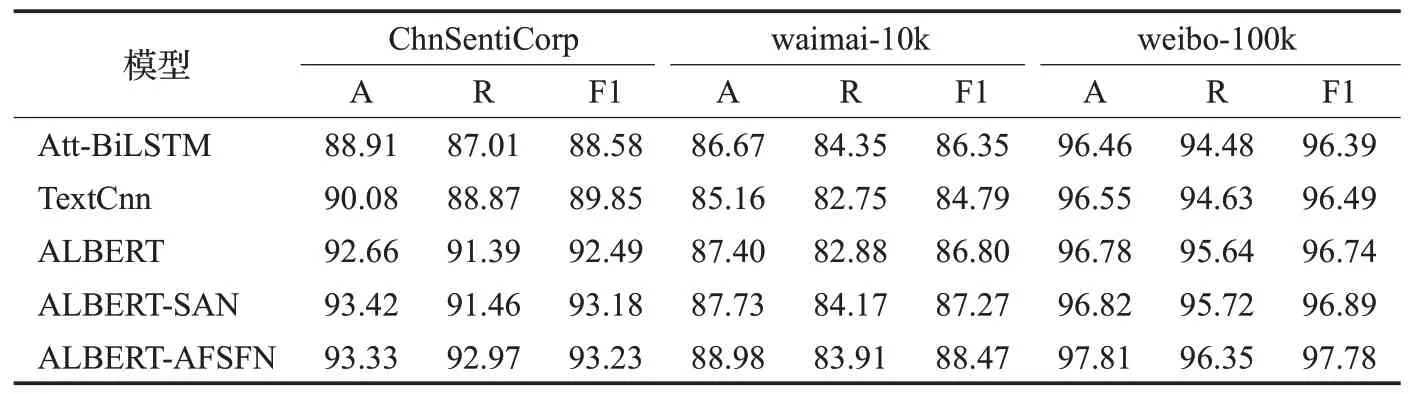
表3 模型对比实验结果Table 3 Experimental results of compared modules %
为了更加直观地观察本文提出的模型与传统网络模型的准确率和F1值的变化趋势以及模型的收敛情况,现将各个模型在ChnSentiCorp数据集上的准确率、F1值和Loss在训练中的变换情况绘制成如图5~7所示的折线图。
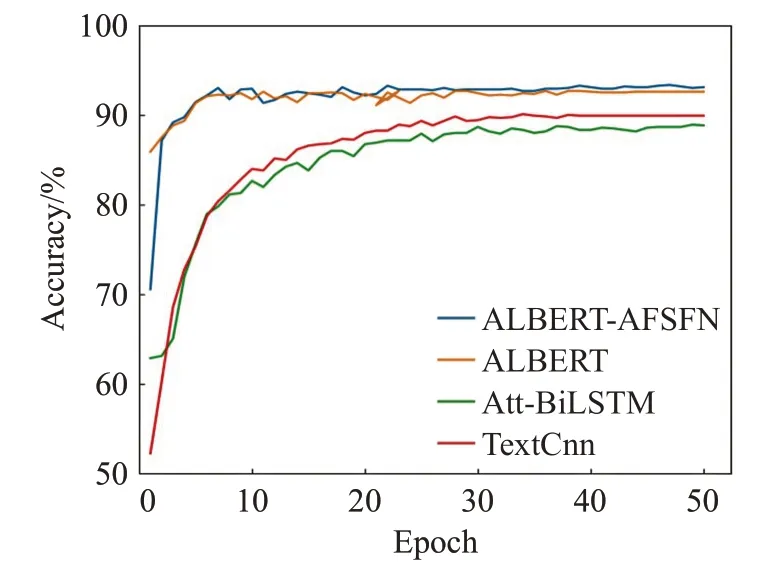
图5 各模型的准确率变化趋势折线图Fig.5 Accuracy line chart of each model
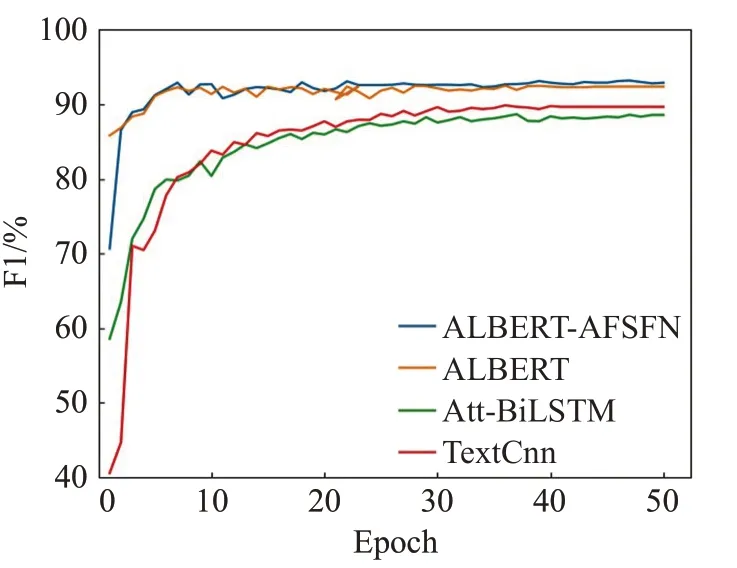
图6 各模型的F1值变化趋势折线图Fig.6 F1 line chart of each model
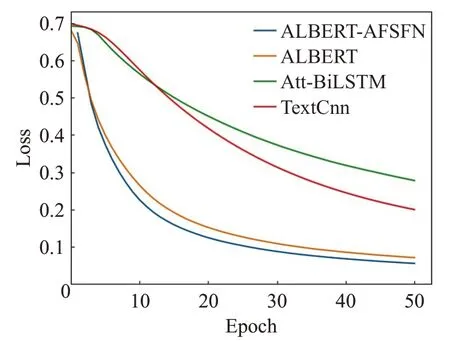
图7 各模型的Loss变化情况折线图Fig.7 Loss line chart of each model
由图5~7所示的准确率、F1值以及Loss变化情况可以看出,Accuracy和F1值在训练步数10步左右时,均有所波动,20步左右时开始趋于平缓,且本文模型的结果都明显优于其他模型,表明本文模型能够取得更优秀的成绩。同时训练步数在10步左右时Loss下降速度开始减慢,20步左右时,Loss开始趋于平缓,但是本文提出的模型的Loss一直是最小的,表明了其收敛性更好,收敛速度更快。也证明其在中文短文本情感分析中的有效性和优越性。
同时为了直观观察和对比通过AFF改进后的分割注意力网络和基本的分割注意力网络在中文短文本情感分析中的效果,现将其在训练中的准确率、召回率和F1值变化趋势绘制成如图8~10所示的曲线图。
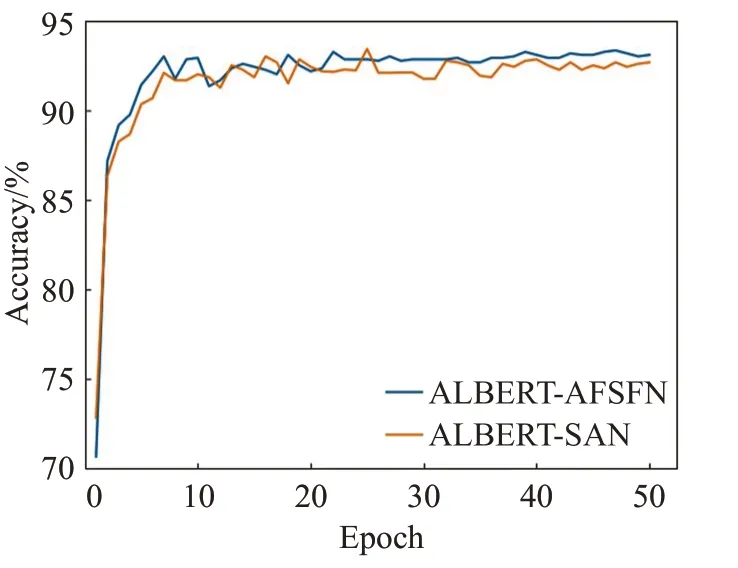
图8 改进前后的AFSFN模型准确率变化趋势折线图Fig.8 AFSFN model accuracy change trend line chart before and after improvement
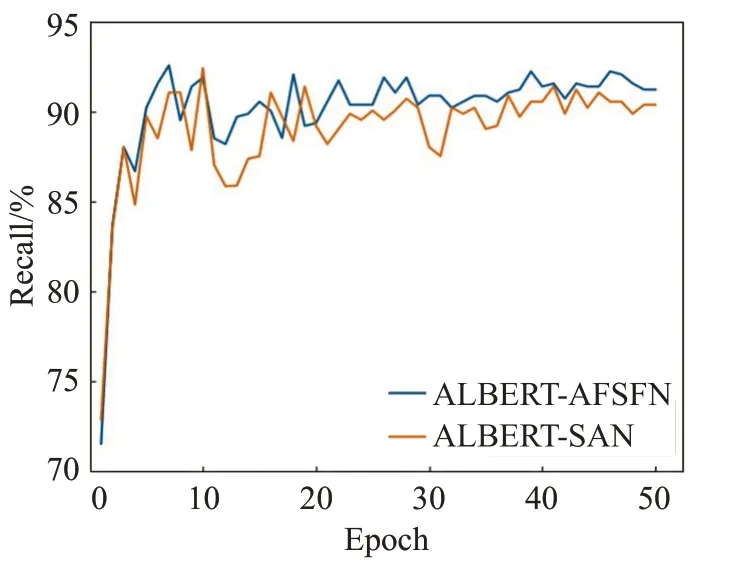
图9 改进前后的AFSFN模型召回率变化趋势折线图Fig.9 AFSFN model recall rate change trend line chart before and after improvement
由图8~10所示的准确率、召回率和F1值变化情况可以直观看出通过AFF改进后的分割注意力网络得到的结果明显优于基本的分割注意力网络,并且其训练稳定程度也优于基本的分割注意力网络,说明了通过AFF融合策略改进后的分割注意力网络具有优秀效果和表现力。
3.4 训练方法对比实验
训练方法一般也会影响结果的准确性,本文运用了两种训练方法对模型进行验证。一种是冻结预训练语言模型的参数,仅对下层模型的参数进行训练更新;一种是无论是预训练语言模型还是下层模型都对其参数进行更新。
本文在三个数据集上都进行了不同训练方法训练的实验,且冻结参数训练方法和不冻结参数训练方法的学习率、训练步数以及优化器等参数设置均相同,其结果如表4所示,从表中可看出将全部参数进行训练会得到更高的准确率、召回率和F1值,并且在情感分类任务中该种方法的分类效果也更好,可靠性也更高。
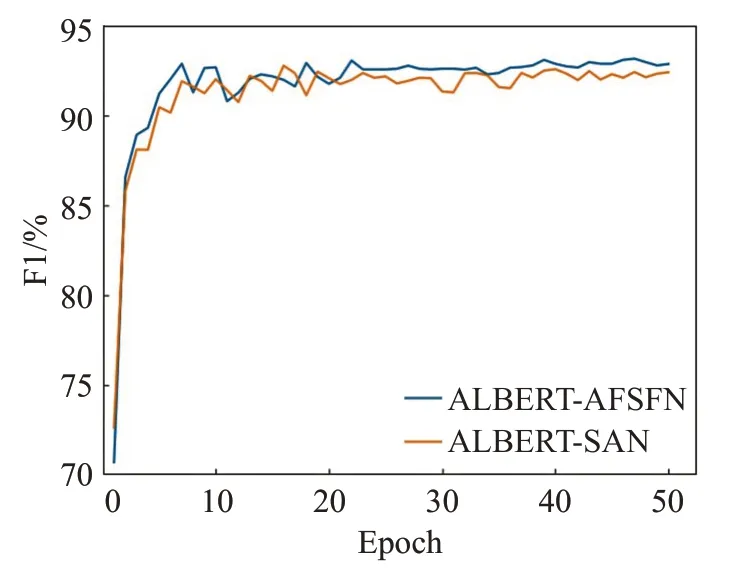
图10 改进前后的AFSFN模型F1值变化趋势折线图Fig.10 Straight line graph of F1 value change trend of AFSFN model before and after improvement
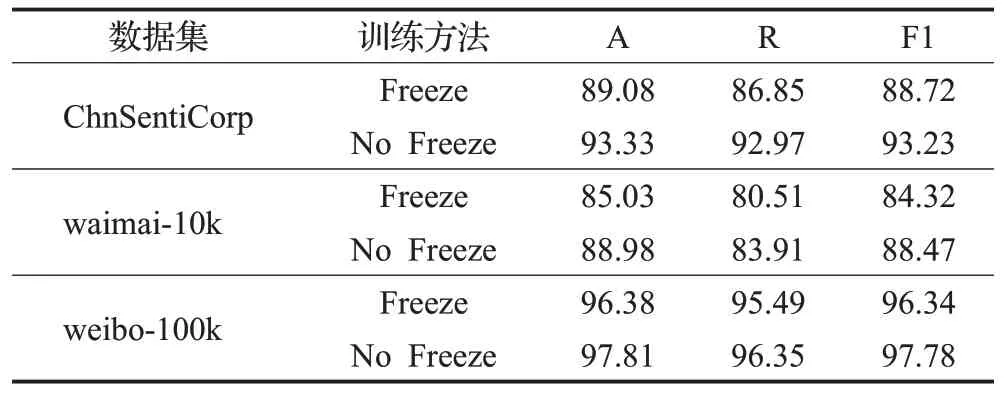
表4 训练方法对比实验结果Table 4 Experiments results of compared trainning-way %
4 结束语
本文提出了一种ALBERT-AFSFN模型,用于中文短文本情感分析。模型首先对网络Split-Attention Network的特征融合策略进行了改进,将其从简单的相加连接改为AFF连接,加强了该网络通道间的联系,最大程度保留了通道间的语义信息及其关联信息。除此之外模型还采用ALBERT预训练语言模型训练得出动态词向量的特征表示,在保证提取到语料库内容信息的同时,也保证提取到了语料库的位置信息。实验结果表明,该模型在不同实验数据上相较于传统的Att-BiLSTM网络和TextCNN神经网络,都具有较高准确度和F1值,且其收敛性也更好,表明其能够适应不同领域的中文文本数据,证明了本模型的优越性和竞争力。
在未来的工作中,将进一步考虑如何有效地融合更多通道的信息,提升模型特征提取和融合的能力,从而将本文所提出的模型应用到更广泛的领域中,甚至将其应用到自然语言处理的其他任务中,例如方面级情感分类任务、观点提取任务和命名体识别任务等。
