融合空间位置注意力机制的英语题注生成模型
2022-06-23颜靖柯钟美玲
王 琴,王 鑫,颜靖柯,钟美玲,曾 静
1.桂林电子科技大学 基础教学部,广西 北海 536000
2.桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004
3.桂林电子科技大学 海洋工程学院,广西 北海 536000
4.桂林电子科技大学 计算机工程学院,广西 北海 536000
5.电子科技大学 信息与软件工程学院,成都 610000
数据可视化将高维复杂的数据以条形图、折线图等直观形式呈现,但据有关研究表明:实践过程中对图表的解析和利用存在一定的困难且利用不充分。
Carberry等[1]在图表语料库上的研究表明,通过传统视觉方式观察图表,35%的描述不能表达出文本传达的关键信息,26%的描述只能表达小部分图表预期信息。但采用题注的形式分析描述图表内容,可以降低图表解析难度,使图表内容更加直观易懂。
近年来,许多研究者针对数据到题注的生成任务开展了大量的研究,该任务已逐渐成为自然语言的多项任务中一项非常重要natural language generation(NLG)子任务。NLG任务主要分为传统文本题注方法和基于时间序列的题注生成方法。传统题注生成方法(Duboue等[2]、Sent等[3])利用语料库关注数据表“说了什么”和“用什么方式说的”,它们采用统计学习的方法,搜索描述数据表的题注,一旦数据表的风格发生变化,该类方法将导致其描述失真,表明该类方法缺乏通用性。基于时间序列题注生成方法(Wiseman等[4]、Li等[5])通过数据表中的时间和数据间因果关系分析数据表所表达的关键信息。尽管该方法也可以生成数据的描述题注,但是存在以下问题:
(1)该方法和其他NLG任务不同,如机器翻译(Guo等[6]、AI等[7])的句子和词语是成对出现的,更容易产生训练的数据。然而数据可视化任务需要结构化的数据,在获取数据的过程中存在着一定的困难。
(2)该方法将题注中的实例数据(名称、数值等)进行了等价标记,这可能会导致模型预测不准确的题注。
(3)该方法生成数据描述题注过程中每组源语句和目标语句之间彼此等价,并没有考虑每组语句之间可能存在的空间位置嵌入关系。例如“China's economy、U.S.economy”,存在“China's economic growth is faster than the U.S.'s economic growth”。生成过程中没有采用词向量搜索算法,可能会生成不合逻辑的题注。例如“China in Pork is growing.”。为解决上述三个问题,本文从数据层面和模型层面提出了解决方案。
(1)针对该任务数据缺失的问题,本文设计了一个包含大量图表和相应英语题注的数据集,该数据集利用爬虫技术抓取了多个网站上的8 300张图表作为语料库。
(2)本文提出了一种TransChartText网络模型。该模型利用变量替换图表数据的标记,提高了位置关系的覆盖程度,使生成的英语题注更符合事实;引入空间位置注意力机制对空间位置嵌入编码,解决图表题注中词语与词语或句子与句子的空间位置关系的问题,赋予图表数据之间有序关系;引入基于Diverse Beam search[8]的集束搜索算法获得较优的英语题注选择结果。
(3)本文对TransChartText模型进行了一系列评估,结果表明在多个数据集上TransChartText模型的BLEU、CS、CO、ROUGE指标上优于当前大多数模型。
1 相关工作
1.1 基于图表的题注生成模型
大量研究逐渐倾向于从海量数据中自动提取对该数据集的描述。Cui等[9]、Wang等[10]、Srinivasan等[11]先利用统计分析推断数据潜在的重要理论依据,再利用图表或者自然语言的方式将它们模板化呈现出来。虽然上述工作也能生成数据描述,但是他们使用预先定义模板的方法生成题注,导致这些方法缺乏通用性,在语法风格和词汇方面有较少的选择。Wiseman等[4]和Chen等[12]使用编码器-解码器的架构,生成数据描述。该方法中编码器作用是识别输入的表数据,解码器的作用是利用长短期记忆网络创建基于表数据描述,然而该方法在内容选择方面表现不佳,并且缺乏句子间的连贯性。NCP2019[13]在编码和解码结构中加入了注意力机制,相比于只基于编码和解码器的架构提升了模型对题注内容的选择和排序。AOKI等[14]提出了HDTag模型,不仅在编码器和解码器中加入了注意力机制,而且将图表的主题标签序列数据输入进题注生成器,控制题注的生成。HDTag和NCP2019模型虽然加入注意力机制有助于提升模型对内容选择,但是模型通过卷积计算特征远程依赖性,需要经过长的路径计算信号特征,导致模型难以学到特征的远程依赖性。Li等[5]提出DataTrans2019,该模型利用Transformer计算两个位置之间的长距离的依赖关系。该关系不需要长路径学习,就能使解码器能够更好地专注于的句子规划,数据到题注生成的过程也更具有解释性。但是,该方法不仅没有编码词与词之间潜在的空间位置关系,不能覆盖多种语句之间的位置关系,而且不能对不同类型的数据进行分类标记,导致生成的题注不合逻辑。
1.2 Tansformer模型
传统的自然语言算法RNN[15]、LSTM[16]只能从左到右或从右到左依次提取特征,但可能导致两个问题:(1)t时刻计算的特征依赖前面t-1时刻特征的值,极大地限制了模型的并行能力;(2)长期特征值之间较远距离的依赖过程,可能存在特征信息丢失的情况。Transformer[17]利用自注意力机制和前馈神经网络对特征进行“自我学习”和“自我调整”,不仅表现出了强大的并行能力,而且一定程度上缓解了特征信息丢失的问题。Transformer的计算原理是计算输入的每对词向量之间关联情况,并利用相互之间的关联关系分配每个词向量权重,从而体现出不同词向量之间的重要程度。Transformer不仅考虑了自身词向量的特征,而且还将该词向量与其他样本词向量的关系融入到权重内,获得词向量的特征表达。本文的工作受Transformer模型启发,通过改进编码器和解码器提高生成图表题注描述的准确率。
2 基于TransChartText题注生成模型
本章首先阐述了题注生成模型的数据,然后详细介绍基准模型,并且介绍了模型的扩展,对模型进行了调整。
2.1 基于图表的题注描述数据集
虽然,最近NLG任务(Chen等[18]、Parikh等[19])的数据集可以使用到题注生成任务,但是,上述数据集主要用于特定领域数据描述(如NBA比赛的胜负描述),并且它们并没有提供带图的多种行业类别下表题注。因此需要特定的数据集来研究所提出的问题。
基于上述问题,本文分析了各种科研论文和新闻文章网站,选择多个网站的数据作为模型训练的数据来源,创建了基于图表的题注描述数据集。该数据集由条形图和折线图组成,利用爬虫框架抓取了8 300条数据,该数据分别包括广告业、农业、工业、建造业等22个行业的数据统计表格、表格标题和对图表描述的题注,22个行业的数据分布如图1所示。
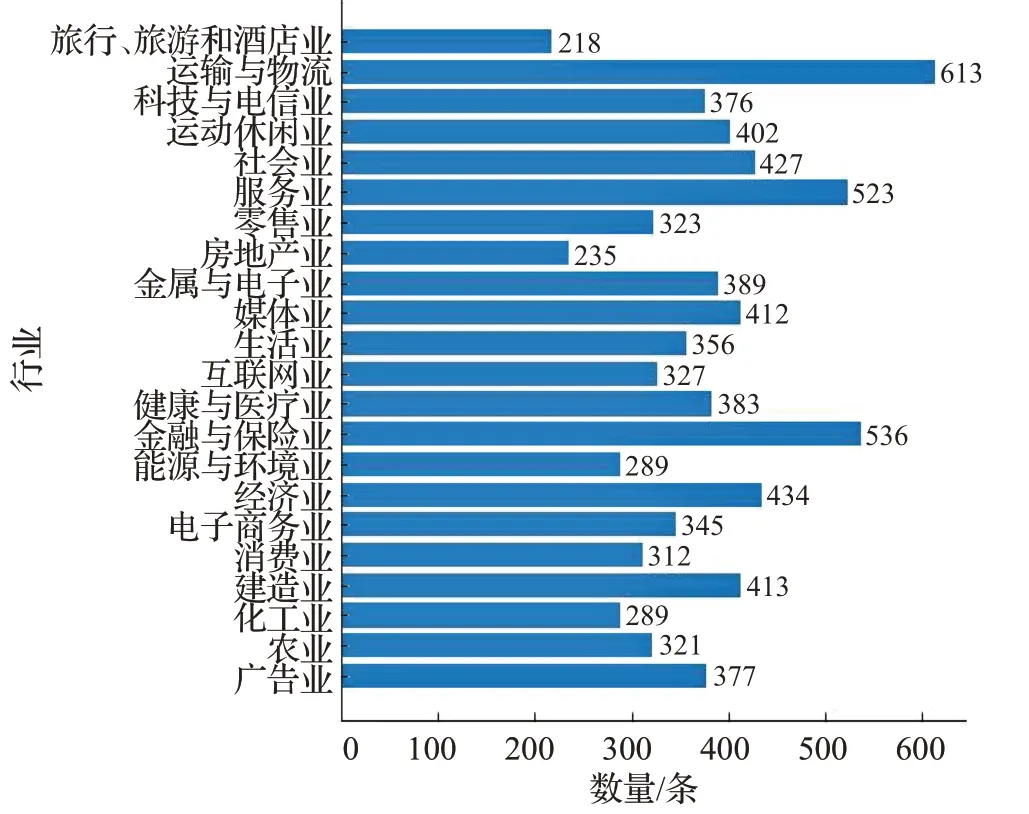
图1 基于图表的题注描述数据集图表分布Fig.1 Chart-based captions describe for chart distribution of data set
(1)该数据集与传统数据集相比,具有丰富的逻辑推理,每条题注描述涉及多个行业方向的推理。该数据集描述的图表的题注内容包括了图表中的要点,如极值(最高点或者最低点)、趋势(上升或者下降)、简单的值索引(第一个值或者最后一个值)。该数据集的描述模拟了真实环境下人工进行的图表评论。
(2)该数据集汇聚了22个行业的数据,包含了不同的句子条数、平均词个数,表格单元格数。22个行业具体的数据分布情况,如表1所示。另外,该数据集由丰富的语法和连贯性组成,与其他数据集相比它更专注逻辑推理。
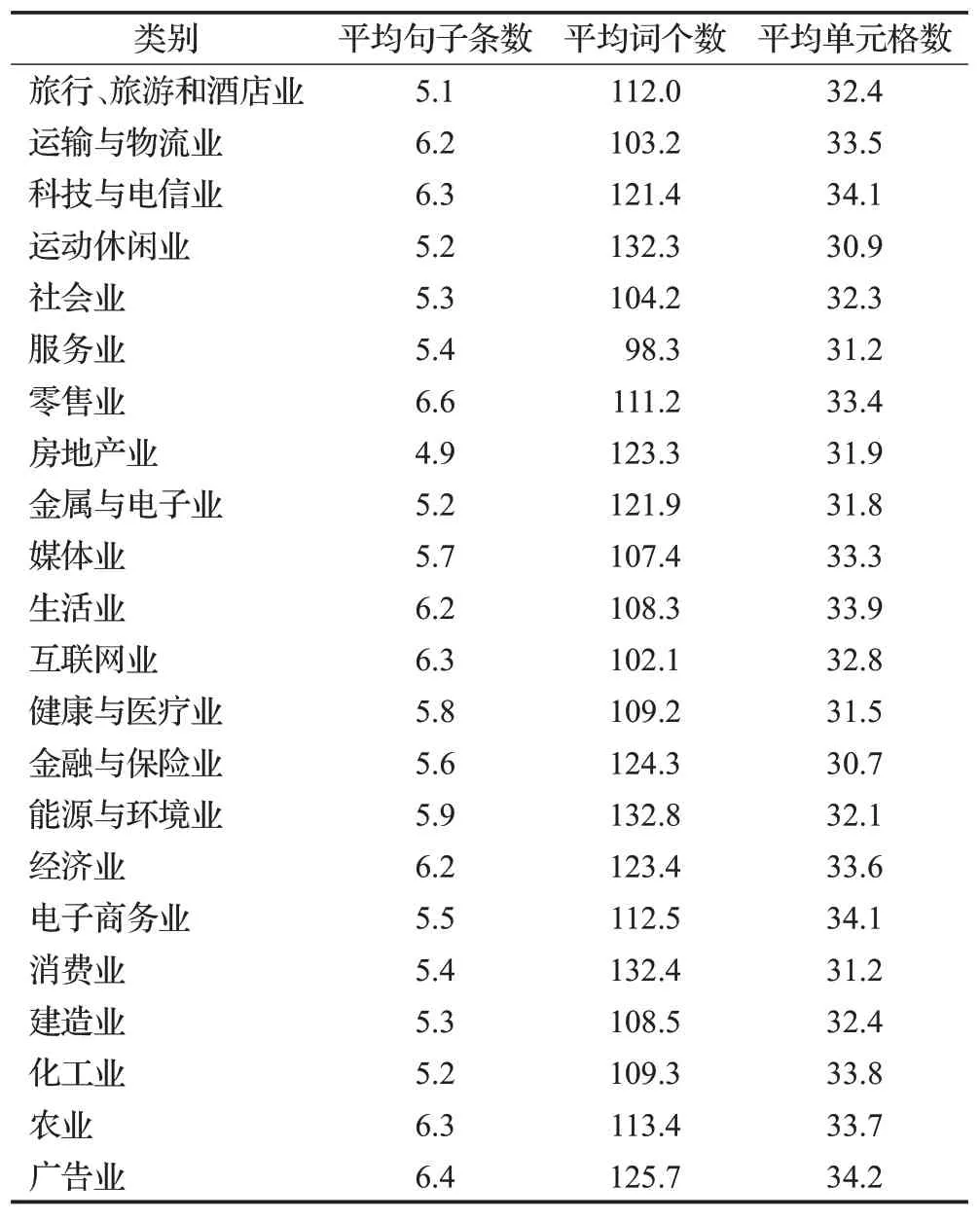
表1 不同行业的数据统计Table 1 Statistics of different industries
2.2 数据描述
基于TransChartText的题注生成任务是通过给定结构化的数据生成描述性的题注。模型输入的结构化数据由一个记录表组成,其中,每条记录表包括标题ri(0)、表格单元格的值ri(1)、列索引值ri(2)、图表的类型ri(3)。输出的w=w1+w2+…+wi是一条基于图表的描述性题注向量,i表示文本的长度。数据到题注的生成概率权重由下列公式表示:
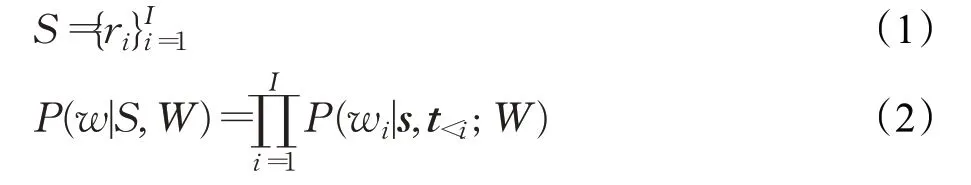
其中,w=w1+w2+…+wi表示生成的题注向量,W表示模型参数。
2.3 数据变量替换
本文的图表数据集并不只关注某个特定的领域,如果将题注中所提到的数据进行常规标记,可能会预测出与图表无关的数据。针对上述问题,本文采用了数据变量替换的方法,在数据进入编码器的时候,首先修改题注,用预选设置的变量模板来替换题注中的数值,将数值映射到某类别变量;然后用模型对修改后的题注进行训练和预测,使模型不会直接预测数据表或标题中相关的实际值,降低了模型拟合难度;最后将生成的索引和预定义的数据变量进行匹配,生成题注。在数据变量中定义了七类数据变量,它们分别是标题实体变量、日期、x轴标签(年,月)、y轴标签(数值)、表格单元格的数据、条形图和折线图趋势、占比。对于所定义的七个变量,采用了命名识别LearningToAdapt[20]根据NER的频率来构建变量模板数据库。图2展示了题注重要关键词被数据变量的标记值替换,用加粗显示出来替换的词语。其中,templateYLabel表示当前数据表中纵轴标签的值,templateXValue表示当前数据表中横轴标签的值,templateXLabel表示当前数据表中横轴标签值的属性,templateXValue[min]表示当前数据表横轴标签的最小值,templateXValue[max]表示当前数据表横轴标签的最大值,templateTitleSubject表示当前标题标签的值。

图2 数据变量替换Fig.2 Data variable substitution
2.4 模型框架
本文围绕图表的题注生成问题,提出了基于Trans-ChartText的题注生成模型,图3是该模型的概述,数据表和一些作为模型输入的图表元数据(图3(a)),并利用TransChartText模型(图3(b))生成题注。该模型首先对图表题注数据进行了分词操作,并对输入的n个单词采用了变量替换的方法,使模型更好地拟合数据并减少模型过度推理题注的情况;然后,在TransChartText编码器,对n个单词给出对应位置的描述,增强编码器的位置关系学习能力,同时利用多头注意力机制对词向量特征进行编码;最后,在TransChartText解码器中设置多头注意力机制对编码器输出的词向量特征进行解码,并使用Softmax和集束搜索算法计算出词序列。
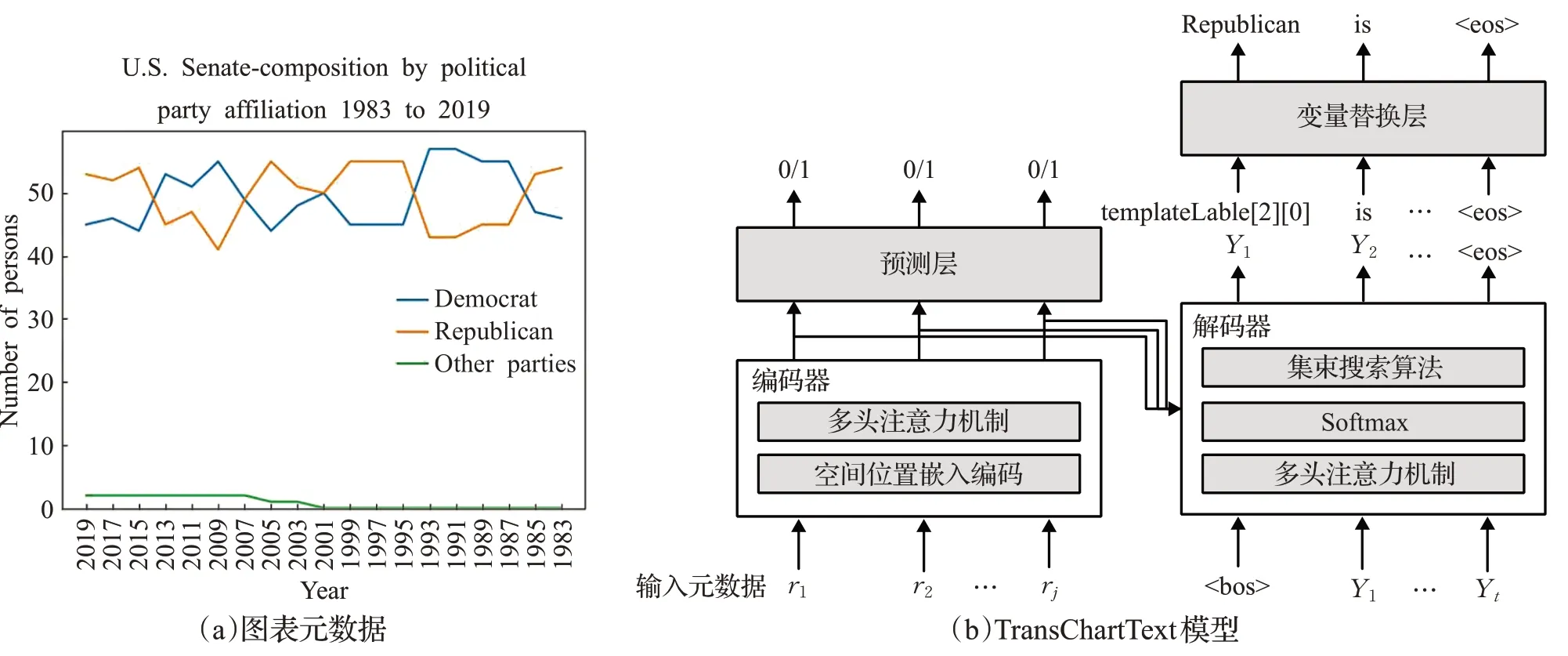
图3 基于TransChartText题注生成模型Fig.3 Generate model based on English summary in TransChartText
在TransChartText模型编码器输出的顶部添加一个单独的预测层,它从输入的词向量中选择重要的词向量(如实体名称、图表上升或下降的最大值(最小值)等),这些重要的词向量可能在图表生成的题注中被提出,单独的预测层可以使模型更好地预测重要的数值。预测层将输入的记录序列以及标签序列通过交叉熵损失函数优化编码器。另外,在题注生成模型中,编码器和解码器同时训练更新权重。
在TransChartText模型的解码器输出顶部,通过添加变量替换层对输出的词序列中的变量模板进行替换,得到预测题注中的真实数值。
2.5 融合数据空间位置关系的TransChartText编码器
一段描述性的语句中词向量与词向量之间存在一定的空间位置关系,比如“Pork price,Dog meat price”之间的关系为“The price of pork is higher than that of dog meat”。基于上述原因,在TransChartText编码器中需要将词向量的空间位置特征通过编码器编码进词向量特征。受Tan等[21]启发,本文提出将TransChartText编码器分为1个位置编码层和6个多头注意力机制组成。TransChartText的编码模块如图4所示。
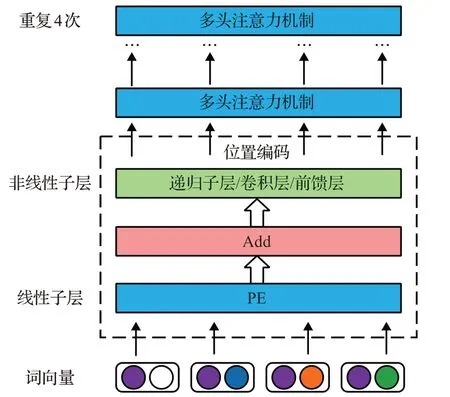
图4 融合数据空间关系的TransChartText编码器Fig.4 TransChartText encoder integrating data spatial relations
在TransChartText的位置编码层,为增加网络空间位置特征非线性和线性表示能力,使用非线性子层和线性层对词向量特征进行变换。
在非线性子层中,研究了递归子层、卷积层和前馈层。首先,使用双向LSTM构建递归子层,处理词向量ri;使用双向LSTM学习长期依赖上下文的词向量位置特征信息。为在输入和输出之间保证相同维度,将输出结果相加。递归子层的计算方式如式(3)所示:

在卷积层中,本文使用门控单元(GLU),给定滤波器W∈ℝk×d×d和V∈ℝk×d×d对词向量位置特征信息进行变换,实现基于时序的对位置局部特征信息输出的控制。卷积层的计算方式如式(4)所示:
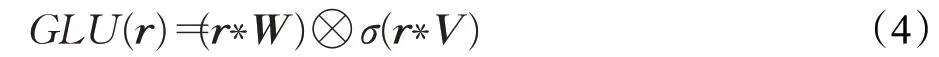
其中,d表示词向量的维度,滤波的宽度k设置为3,σ表示激活函数,*表示卷积操作,⊗表示矩阵之间元素的乘积。为了加强模型对位置特征转换和特征信息重组,本文设置前馈层,前馈层是由两个线性层组成,在第一个线性层中设置Relu激活函数增加前馈层的非线性。计算公式如式(5)所示:

TransChartText编码模块不仅记录了对应词向量与其他向量之间的位置关系,而且还通过多头注意力机制更新语义信息表示。
在多头注意力机制中,首先将位置编码的词向量Y∈ℝi×d通过在8个头中进行不同的线性投影映射为查询矩阵Q,键矩阵K和值矩阵V。然后将8个头在不同的通道聚合不同的值矩阵,并用点积计算查询矩阵和键矩阵的相关性,计算方式,如公式(10)所示:
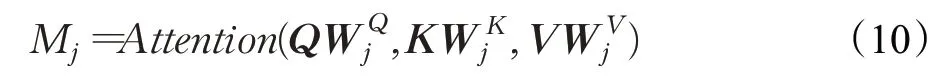
其中,第j个头可以用WQ j∈ℝn×d/h,WK j∈ℝn×d/h,WV j∈ℝn×d/h分别表示学习到的查询、值和键映射。最后,多头注意力机制将头产生的向量M聚合在一起形成新的词向量,其计算方式如公式(11)所示:
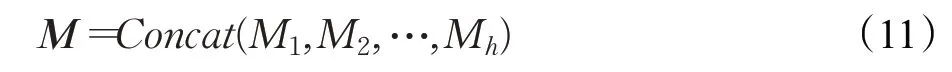
2.6 基于Diverse Beam Search的集束搜索算法的TransChartText解码器
Transformer解码器是根据编码器的输出词向量和上一个单词的词向量预测下一个单词。在解码器中,编码器的输出向量M和上一个单词的词向量会传入多头注意力机制进行解码并通过Softmax层产生条件概率,选择当前时间序列局部最优的候选值加入单词序列y。解码器计算方式如下:
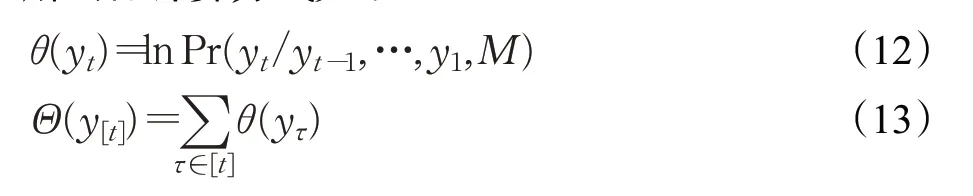
其中,yt表示在t时刻基于上一个单词预测的词向量,θ(yt)表示当前词向量的条件概率,它的值取决于前t-1输出的词向量y[t-1],Θ(y[t])表示t个词向量的条件概率。
Transformer的解码器只采用条件概率搜索词序列,该方式本质上没有从整体最优考虑候选值搜索,得到的结果存在词序列排序错误。而集束搜索算法[22]可以将每个时间序列节点存储概率值最高的前B个候选词向量作为下一步搜索的候选词向量路径,极大程度上确保了全局最优解,其中B称为集束搜索算法的宽度。集束搜索算法选择在t时刻的B个候选词向量的解集可以表示为:

在时间序列,集束搜索算法选择t时刻的Yt=Y[t-1]×V概率值,计算最高的B个候选词向量。每一时间序列,集束搜索算法都会更新词向量,其计算方式如下:
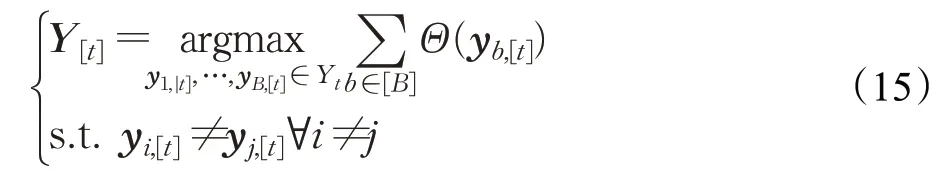
虽然集束搜索算法能够根据条件概率Yt,对B个候选词向量进行排序,选择可能的词序列,但是它大多数选择都是基于当前时间序列中单个条件概率最大的词向量,如果单个词向量出现微小的扰动,也可能产生错误的词序列。
为解决上述问题,本文采用了基于Diver Beam Search[8]的集束搜索算法,它将Y[t]分成G组Yg[t](g∈[G])行词序列的搜索,并产生多个词序列进行选择。该方式解决了词向量出现微小扰动和产生错误词序的问题。Diver Beam Search算法中每一组有B/G个候选词向量,为保证组与组之间的差异,引入Δ(Y[t])惩罚因子用来保证组与组之间的差异,Diver Beam Search算法计算方式如下:
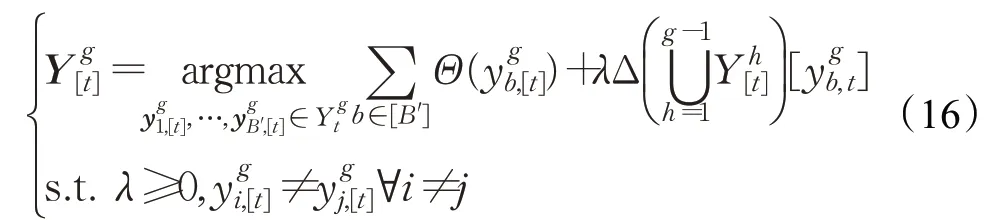
其中,λ是控制分组项的强度。Diver Beam Search通过时间t从左到右依次生成题注词向量的概率,并通过分成G组从上到下操作生成词序列概率,每组之间词向量的概率和条件概率结合计算词序列概率,直到找到正确的概率组合。如图5所示,在本次实验中设置B为6,并将B分成3组用不同的颜色表示,每组包含了B'=2个集束搜索。为减少每个时间步数中的搜索空间,优先计算前G-1组的题注词向量概率,并按照时间序列依次继续计算第G组的条件概率。例如,图5中第3组t=4时,前2组已经完成了词向量可能序列概率的计算,利用前2组的概率值计算第3组的词向量序列概率。在该示例中,设置λ=-1,当惩罚因子为0时,词向量序列完成搜索。

图5 基于Diver Beam Search的集束搜索算法Fig.5 Beam Search algorithm based on Diver Beam Search
3 实验设计与结果分析
首先介绍了模型的实验参数和评测指标;然后利用WIKIBIO(Lebret等[23])、ROTOWIRE(Wiseman等[4])、MLB(Puduppully等[24])制作的基于图表的题注描述数据集对文本模型进行评测,用代表性模型进行对比实验,并通过消融实验验证本文模型效果;最后进行数据可视化证明本模型的优势。
3.1 实验参数
模型的训练需要两种类型的标签数据。第一类标签是图表标签,如果题注s包含记录表ri,标记为1,否则标记0。第二类标签是图表的题注,如果ti(ti∈s)包含记录表ri,标记为1,否则标记为0。本文将数据分为训练集、验证集、测试集,其比例分别为80%、5%、15%。
本次实验是在GTX 2070 8 GB下的Python3.6,PyTorch1.6进行实验,迭代次数为2 000代,Transformer包含的词嵌入大小为512,8个head,dropout设置为0.1,DiverseBeam的B大小为6,G设置为3组,采用GELU激活函数。
本文对比评测了基于编码解码框架的5种图表题注生成模型,描述如下:(1)WS2017模型[4]使用了基于编码器和解码器的方法生成题注。(2)Chen2019模型[12]使用了基于卷积和LSTM的编码器和解码器的方法生成题注。(3)NCP2019模型[13]除了使用编码器和解码器,还引入了注意力机制进行内容选择模型。(4)HDTag模型[14]不仅在编码器和解码器中使用了注意力机制,而且使用了带主题的标签作为额外的输入。(5)DataTrans2019模型[5]虽然使用了Transformer进行编码和解码,但是没有引入注意力机制对位置嵌入进行编码和变量替换。
最后,为证明TransChartText模型中引入空间位置嵌入编码、数据变量、集束搜索算法对模型的提升效果,构建了4种模型。它们分别为:第一种模型(TransChartText-v1)是基于Transformer的模型,该模型没有加入数据变量替换、空间位置嵌入编码、集束搜索算法;第二种模型(TransChartText-v2)在v1模型上加入数据变量替换;第三种模型(TransChartText-v3)在v1模型上加入空间位置嵌入编码;第四种模型(TransChartText-v4)在v1模型上加入集束搜索算法。
3.2 评价指标
使用的题注评测指标包括BLEU、内容选择(CS)[4]、内容排序(CO)、ROUGE、模型的参数量、每条图表数据的检测速度。BLEU表示评价模型生成的句子与实际句子的差异指标,它是计算预测句子和真实句子的N-grams概率模型,如果两个句子完全匹配,BLEU是1.0,反之,如果两个句子不匹配,BLEU为0。CS表示输入数据的内容出现在生成题注数据的准确率。CO表示将输入数据和生成题注进行归一化,并计算Damerau-Levenshtein距离。ROUGE通过将自动生成的题注和原始题注进行比较,统计二者之间重叠的基本单元(语法、词序列和词对)的数目,用以评价摘要质量并得出相应的分值。
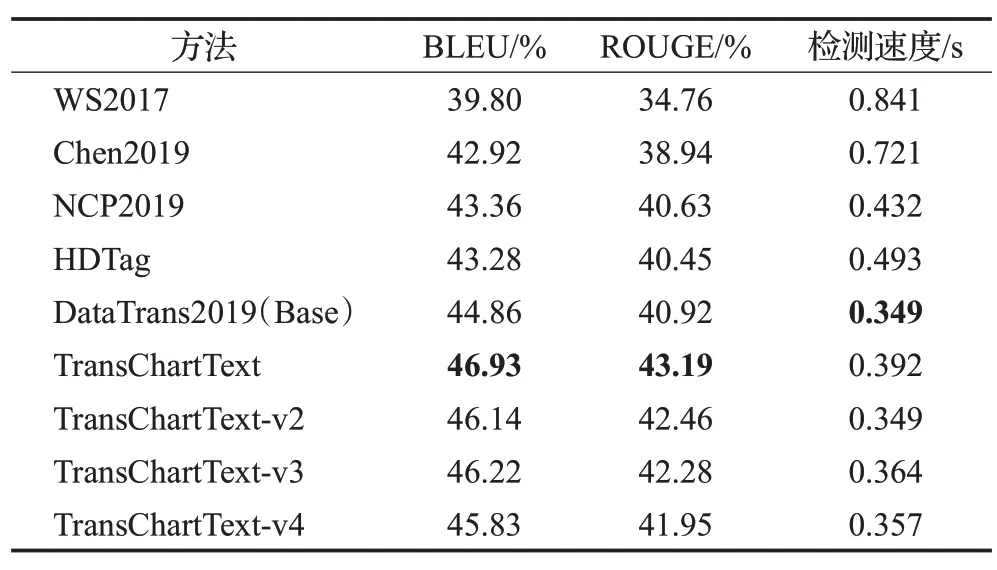
表2 不同模型在WIKIBIO数据集的实验结果Table 2 Experimental results with model in WIKIBIO dataset
3.3 WIKIBIO数据集评测结果
本节中,首先模型在WIKIBIO数据集上进行了实验。WIKIBIO数据集中包含728 321篇来自维基百科的英语图表文章题注。表3显示了模型的实验结果,从表3可以得出TransChartText与模型DataTrans2019的BLEU和ROUGE存在显著的差异,TransChartText在增加少量的计算开销的情况下,TransChartText的BLEU和ROUGE相比于DataTrans2019提高了2.07%和2.27%。另外,本文进一步比较TransChartText和WS2017、NCP2019、Chen2019、HDTag模型的BLEU、ROUGE、检测速度,TransChartText的BLEU、ROUGE、检测速度达到了46.93%、43.19%、0.392 s,表明TransChartText能高效地推理出图表的英语题注。DataTrans2019与WS2017、NCP2019、Chen2019、HDTag模型相比BLUE和ROUGE达到了44.86%和40.92%,说明在充足的数据前提下,Transformer可以显著提高生成题注的质量。HDTag使用了带主题的标签作为额外的输入提高模型的生成效果。TransChartText-v2与HDTag相比,TransChartText-v2加入数据变量替换,BLEU和ROUGE更高,说明Trans-ChartText加入数据变量替换,可以使生成的目标题注与真实题注更贴近。在TransChartText-v3中使用了注意力机制对空间位置嵌入编码,虽然增加了少量的计算开销,但是BLEU和ROUGE达到了46.22%和42.28%,说明增加空间位置学习可以减少模提取的位置特征丢失。TransChartText-v4加入集束搜索算法相比于Data-Trans2019的BLEU、ROUGE、检测速度,虽然检测速度增加了0.008 s,但是BLEU、ROUGE提高了0.97个百分点和1.03个百分点,说明加入了集束搜索算法可以使模型计算更好地词序列概率组合。
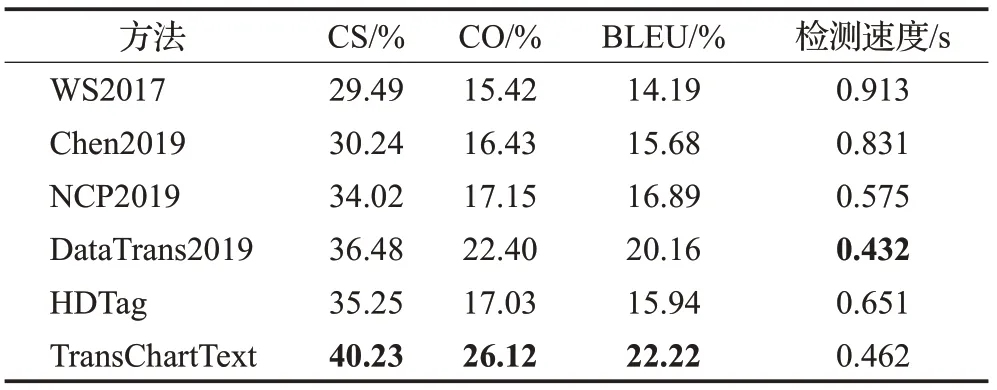
表3 不同模型在ROTOWIRE数据集的实验结果Table 3 Experimental results with model in ROTOWIRE dataset
3.4 ROTOWIRE数据集评测结果
为进一步证明本文提出模型的合理性和有效性,讨论在ROTOWIRE数据集进行模型验证。该数据集是由NBA篮球比赛的图表题注组成的数据集,该数据集总共包含了4 853条数据。与WIKIBIO数据集相比,因ROTOWIRE数据集基本上是数字格式,模型需要理解数值数据之间的关系。在ROTOWIRE数据集上,Trans-ChartText与其他模型相比它的CS、CO、BLEU值更高。例如,TransChartText与DataTrans2019模型相比,虽然TransChartText的检测速度比DataTrans2019上升了0.03 s,但是CS提高了3.75个百分点,CO提高了3.72个百分点,BLEU提高了2.06个百分点。这表明由本文模型生成的题注更接近真实题注,且可以生成更流畅的目标题注文本。
3.5 MLB数据集评测结果
讨论在MLB数据集上进行的实验。MLB数据集包含24 304条棒球统计图表数据和相应题注。MLB数据集相比于ROTOWIRE有更丰富的词汇和更长的题注。从表4可以看出,TransCharText相比于其他模型的CS、CO和BLEU指标获得更高的值。但是与ROTOWIRE相比,虽然TransCharText在CS和CO指标上效果更好,但BLEU指标表现不佳。实验结果表明,创建基于MLB的题注任务效果不够理想。
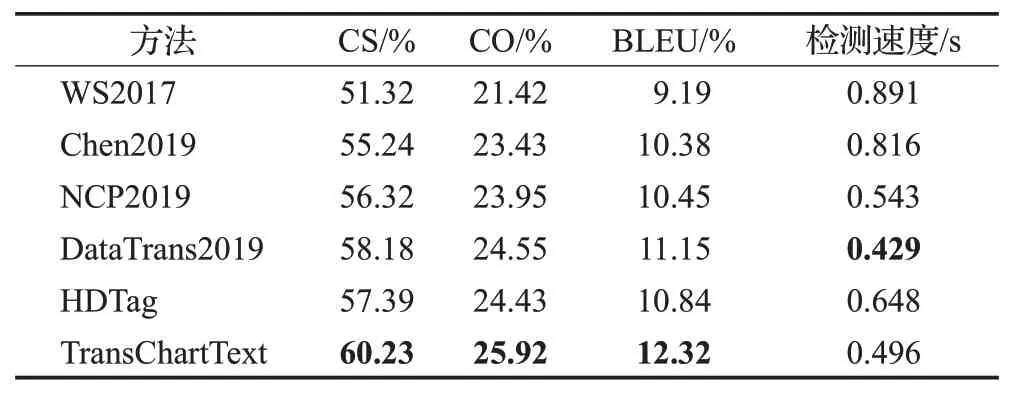
表4 不同模型在MLB数据集的实验结果Table 4 Experimental results with model in MLB dataset
3.6 基于图表的题注描述数据集评测结果
虽然已在ROTOWIRE和WIKIBIO数据集上进行了实验,但由于该数据集只有NBA篮球一种类别,模型在单一类别的数据集的实验结果不能证明其通用性。基于上述原因,本文在采集的基于图表的题注描述数据集据进行了对比实验。从表5的统计结果可以看出,本文模型与其他五个模型相比,其五个指标值均有显著提升,相比于其他有效性指标,CS指标获得了比较高的准确率。
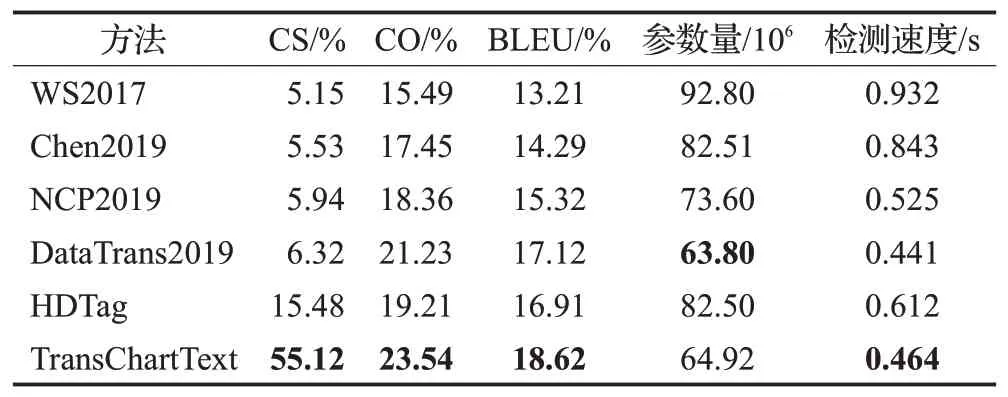
表5 基于图表的题注描述数据集的实验结果Table 5 Chart-based captions describe experimental results of data set
NCP2019和HDTag模型相比于WS2017模型和Chen2019模型评价指标都有提升,说明采用了注意力机制能够加强模型对内容特征的选择,提升了模型生成英语题注的准确率。HDTag相比于DataTrans2019在基于图表的题注描述数据集上CS有较大提升,说明HDTag中加入带主题的标签作为模型的额外输入可以提升模型生成多种类别题注的准确率。另外,本文模型TransChartText与HDTag相比,CS、CO和BLEU分别上升了39.64、4.33、1.71个百分点,说明采用了Transformer中的多头注意力机制加强了词向量特征之间的远程依赖关系提取。虽然DataTrans2019也同样使用了Transformer编码解码,与其相比,本文模型在CS、CO、BLEU上依然分别上升了48.8、2.31、1.5个百分点,说明本文在Transformer中引入空间位置注意力机制位置嵌入编码、数据变量、集束搜索算法,可以增强词向量的位置信息表示能力和内容表示能力,使模型能够准确生成关于图表的题注描述。另外,本节对比了TransChartText和其他模型的参数量和时间,结果显示虽然TransChartText相比于DataTrans2019模型的参数量增加1.12×106,检测速度增加0.023 s,但是相对于WS2017、Chen2019、NCP2019、HDTag的参数量和检测速度依然具备明显优势。
在图表题注描述数据集中具有22个行业类别,每一类别与DataTrans2019的CS对比结果如表6所示。从表6可以看出,本文模型的CS平均精度都有一定的提高,而且本文模型对每个行业的图表描述CS的平均准确率都几乎在同一基准线上,表明该算法对各行业图表描述的适用性。
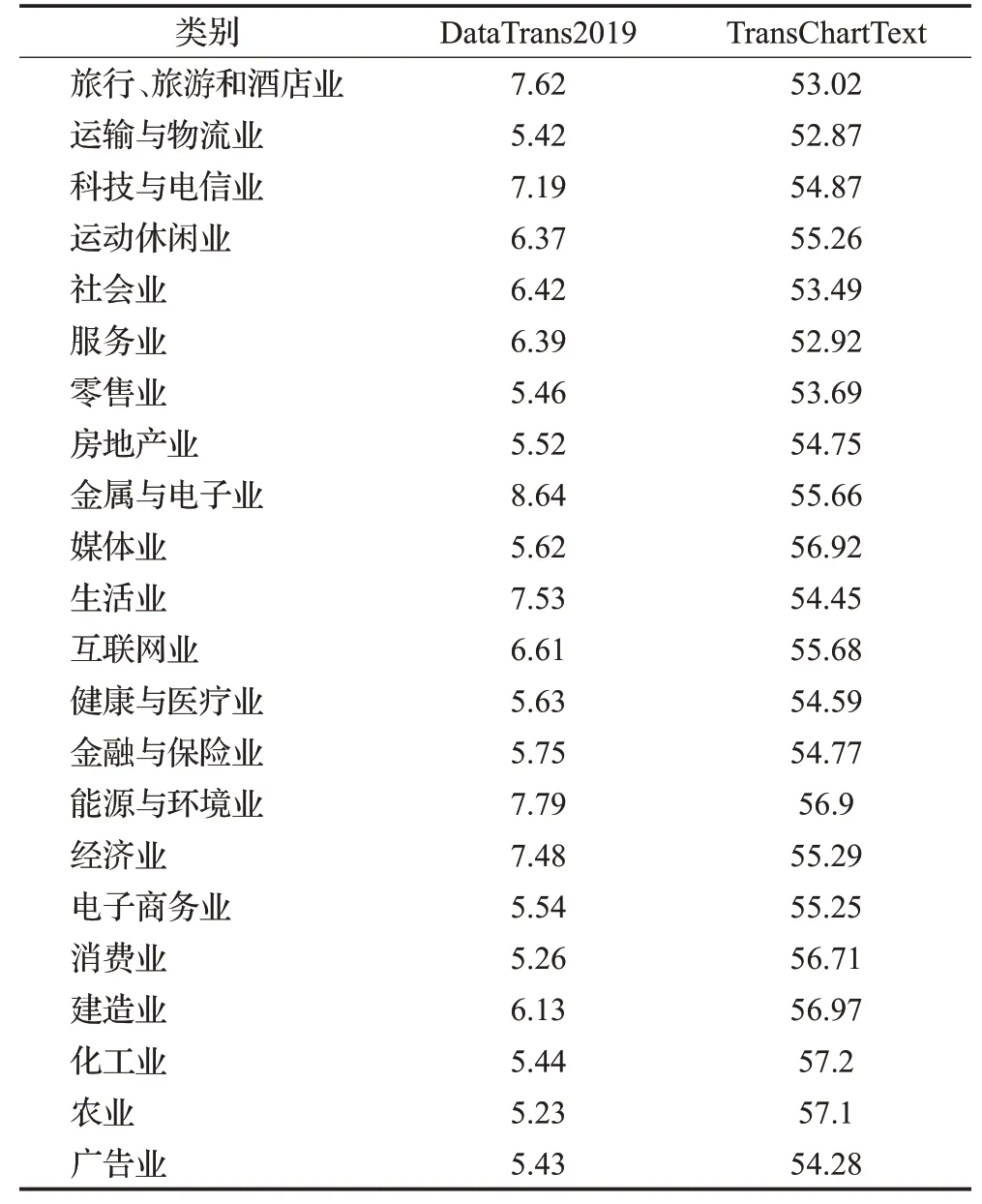
表6 每个类别的CS指标对比Table 6 Comparison of CS indicators for each category
本文模型与上述其他模型相比,在Transformer中引入位置嵌入编码、数据变量、集束搜索算法,它们对模型性能提升的具体贡献需要以下实验予以证明。
3.7 消融实验
本节讨论通过消融实验验证模型中引入空间位置嵌入编码、数据变量、集束搜索算法对模型性能的具体影响。从表7的TransChartText-v1结果可以看出,本文模型在移除空间位置嵌入编码、数据变量、集束搜索算法会导致模型性能下降。TransChartText-v2利用变量来替换题注中的数值使CS的准确率提高到54.32%,说明本文提出的变量替换方法对内容准确率提高十分显著。TransChartText-v3和TransChartText-v4相对于v1的CS的准确率分别提升了1.53、1.11个百分点,说明空间位置嵌入编码和集束搜索算法也能提升内容选择的准确率。消融实验结果显示,TransChartText-v3的CO和BLEU相对于TransChartText-v1增加了1.01%和1.12%,说明位置嵌入编码,有助于加强模型学习词向量之间的空间位置关系。TransChartText-v4相对于TransChartText-v1的CO和BLUE增加了1.16%和1.2%,说明本文加入了集束搜索算法可以更好地生成描述图表的英语题注。
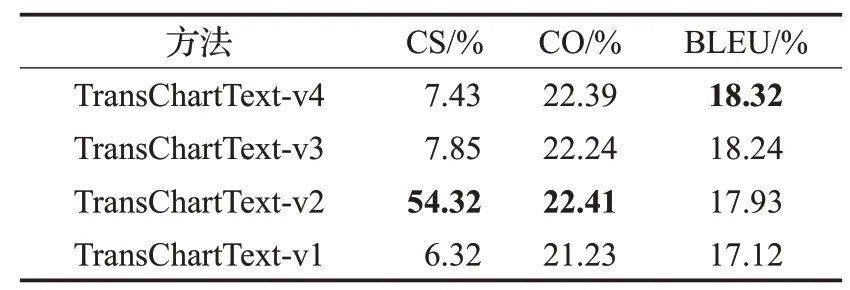
表7 消融实验结果Table 7 Ablation test results
3.8 定性分析
本节对本文模型的主要方法进行了定性分析。本文将TransChartText-v1和TransChartText-v3进行了可视化分析,具体如下:图6给出的是(a)TransChartText-v1和(b)TransChartText-v3的题注模态内的注意力可视化,其中从(a)和(b)中对角线部分可以看出,(a)中对角线部分获得的注意力权重得分低,(b)中对角线部分获得的注意力权重得分高,说明在TransCharText加入了空间位置嵌入编码使模型学习到了题注模态内部的位置关系。
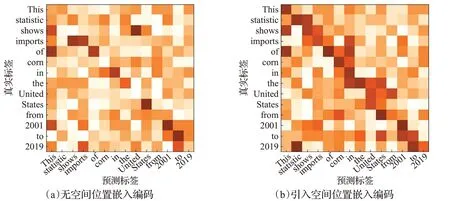
图6 题注模态内的注意力可视化Fig.6 Attention visualization in annotation modes
3.9 实例分析
为进一步分析模型性能,在基于图表的题注描述数据集中随机选择了实例题注进行可视化显示,并与DataTrans2019生成的结果进行对比,对比结果如图7所示。Gold表示真实题注,Our Model表示本文提出的模型生成题注。图7可以看出本文的模型不但能够推理出逻辑能力强的英语文本题注(下划线),而且能够推理出具有空间位置关系的语句(斜体),但Data-Trans2019模型只使用Transformer推理图表的题注描述,题注中存在推理出浅层语义的文本题注和错误的文本题注。
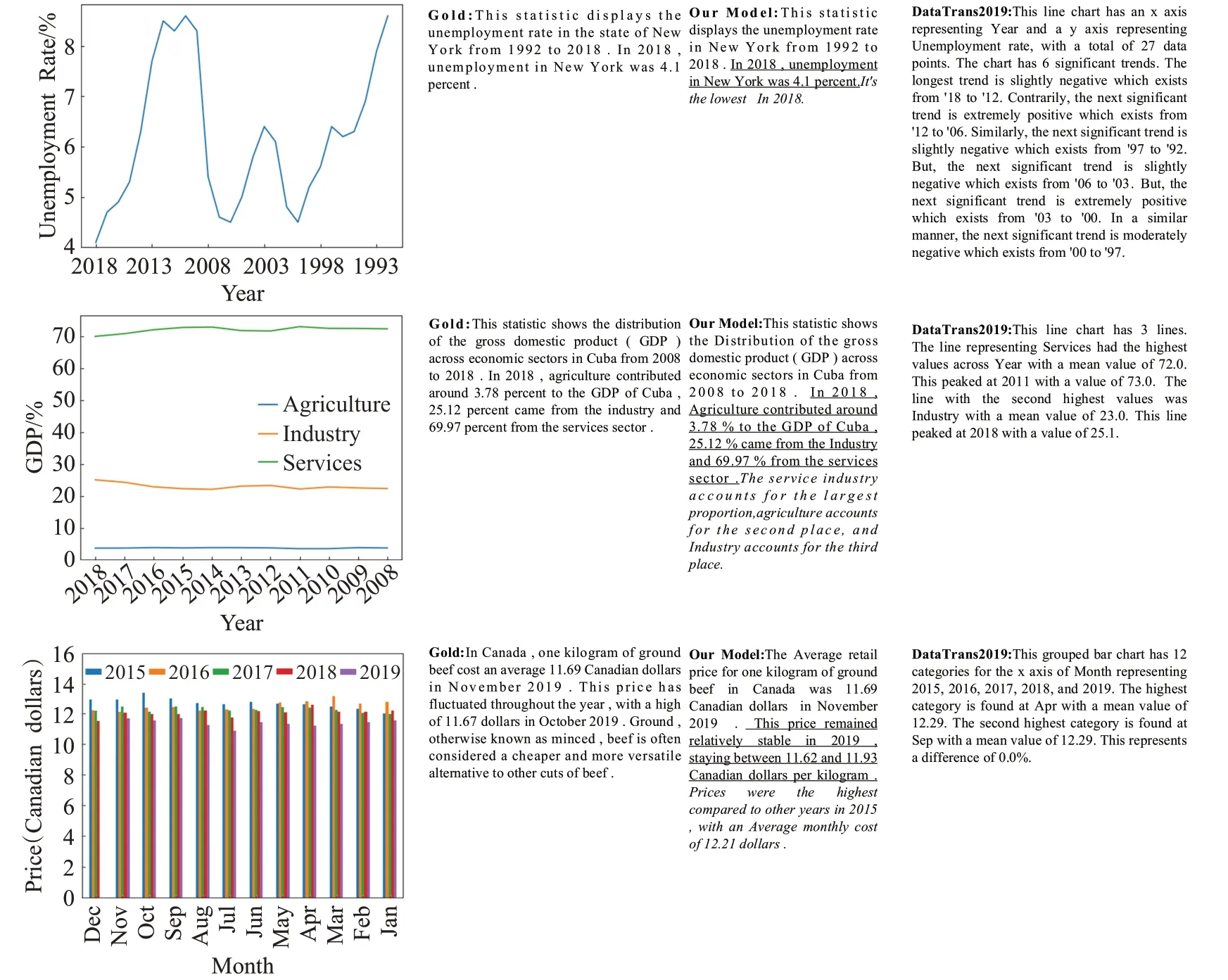
图7 本文模型与DataTrans2019模型的生成题注实例对比Fig.7 Generate annotations example comparison between DataTrans2019 model and proposed model
4 结束语
围绕如何基于图表生成题注这一问题,本文制作了基于图表的题注描述数据集并提出了TransChartText题注生成模型,增强了模型学习符合事实、陈述正确、具有逻辑的题注能力。首先,利用数据变量替换图表数据值,使模型能更容易总结图表内容信息;然后,利用空间位置嵌入编码,使模型能更加容易学习词之间的关系,增强了词之间的空间位置关系和正确的词位置排序;最后,利用集束搜索算法能搜索更好的词向量结果,提高了生成图表题注的质量。通过大量实验结果证明了本文提出的TransChartText模型能够有效地生成准确度高、逻辑性强的题注,但是目前所提出方法,还没有应用识别饼状图、散点图、热力图等。未来,在NLG领域,将探索如何把MLP和迁移学习融入到TransChartText模型之中,使其适用于不同学科领域图表类型(如饼状图、散点图、热力图等),能快速准确地生成相应的英语题注。
