利用Bagging算法和GRU模型预测股票价格指数
2022-06-23牛红丽赵亚枝
牛红丽,赵亚枝
北京科技大学 经济管理学院,北京 100083
股票市场是金融市场的重要组成部分,能够在一定程度上反映国家的经济发展状况。提前预判股票市场的走势,有助于国家监管部门了解经济的运行情况,出台相关政策对市场进行调整,维护经济稳定健康发展。同时,股票市场也是投资市场最重要的组成部分,与其他行业相比,股票市场是高投资回报率与高风险并存的,有效的股票价格预测可以帮助投资者规避投资时的高风险。因此预测股票价格对政策制定者和投资者有着十分重要的意义。
由于影响股票价格的因素众多,使得股票价格时间序列具有非线性、非平稳性和高噪声的特点,导致对其价格的准确预测非常困难。国内外学者在股票价格研究方法上做了许多的研究。早期,计量经济学方法被学者们用于股票价格预测,学者们利用统计学理论对股票价格的波动和趋势进行预测研究,指导投资者的投资活动。学者们常用的计量经济学模型包括自回归滑动平均模型(ARMA)、差分整合移动平均自回归模型(ARIMA)、广义自回归条件异方差模型(GARCH)。例如,吴玉霞等[1]使用ARIMA模型预测创业板股票价格的走势和变化趋势,投资者和企业在决策时可参考其预测结果。李木易等[2]对股票波动率特征进行分析并提出了新的动态混合HGARCH模型对股票日内波动率进行分析预测,提出模型能够更好地刻画波动率特征。金瑶和蔡之华[3]将AR模型和Kalman滤波结合起来预测股票价格,新的方法克服了单一模型的缺点,取得了更好的预测结果。上述研究虽然取得了一定的成果,然而,计量经济学模型有很严格的假设条件,其在处理线性数据占有优势,而股票价格时间序列数据具有非线性、非平稳和高噪声的特征,使得运用传统计量经济学方法难以取得令人满意的效果。
相对于计量经济学方法,机器学习方法无需设置任何假设条件能直接挖掘输入数据之间的非线性关系,它的网络学习模式使得它具有学习精度高和泛化能力强的优点,非常适合于处理非线性、非平稳的数据集。因此,近年来机器学习方法逐渐取代了计量经济学方法,被广泛应用于股票价格预测领域。常用的机器学习方法包括支持向量机(SVM)、人工神经网络(ANN)等。SVM方法的预测精度难以令人满意,因为其在对输入数据集进行特征选择时,无法筛选出最合适的特征数量[4]。而人工神经网络的网络学习模式使其拥有更强大的学习能力,在处理非线性、非平稳和高频高噪声的数据集时更有优势,因而,在股票价格预测领域的应用更有应用前景。近年来,学者们利用神经网络在股票价格预测领域做了大量的研究。例如,于卓熙等学者[5]首先采用主成分分析方法对输入变量进行降维后,然后通过广义回归神经网络对股票价格进行预测,将其预测结果与ARIMA模型的预测结果对比,目标模型具有更好的预测性能。由于BP神经网络模型在参数寻优过程中容易陷入局部最优解,綦方中等[6]针对这个问题,利用改进的果蝇算法寻找BP神经网络参数最优解,使其获得了更好的预测效果。肖菁和潘中亮[7]利用LM算法改进了三层BP神经网络,并用遗传算法来寻找参数的最优解,来解决传统神经网络容易陷入局部最优解的问题,实验结果也表明,该种方式提高了预测精度。对于高维的输入变量,邓烜堃等[8]使用基于受限布尔兹曼机的深度自编码器方法对输入数据集进行降维,降维后的数据使用BP神经网络进行预测,所提出的降维方法减少了运算开销同时提高了BP的预测精度。利用技术方法改进神经网络的结构在一定程度上避免了在参数寻优过程中陷入局部最优解,通过构建降维方法筛选有效的输入变量可以减少神经网络的计算负担同时可以提高模型的预测精度,但传统的神经网络在预测时往往容易出现过度拟合的现象,导致模型的样本外预测能力变差[9]。
与传统神经网络相比,深度神经网络对金融时间序列预测更加具有优势,能够更好地学习输入变量之间的复杂非线性关系,取得更好的样本外拟合结果[10]。随着计算机运算能力的提升,深度学习方法受到广泛关注。以RNN(recurrent neural network),LSTM(long short-term memory)和GRU(gated recurrent unit)为代表的深度学习方法,在股票价格预测领域开展了很多的研究。谷丽琼等[11]使用LSTM和GRU预测股票价格,实验结果发现GRU的预测效果略优于LSTM模型且具有更快的训练速度,总体要好于LSTM模型。朱伟等[12]针对电力负荷时间序列的随机性,使用集合经验模态分解算法结合GRU模型预测短期电力负荷,发现与RNN相比,GRU的预测效果更好。Saud等[13]比较了三种深度学习模型,RNN、LSTM和GRU的股票价格预测性能,发现GRU能够更快更高质量的训练模型,有更好的股价预测能力。张倩玉等[14]将集成经验模态分解算法结合门控循环神经网络进行股票价格预测实验,得出与RNN、LSTM相比,GRU模型能够有效减少预测误差,提高模型预测能力的结论。党建武和从筱卿[15]针对股票数据非线性的特点,将CNN与GRU结合,发现GRU能够利用其独特的门结构学习数据的时间依赖关系和复杂非线性关系。门控循环神经网络(GRU)克服了RNN在学习长期依赖关系时存在的梯度消失和梯度爆炸的缺点[16],能够充分保留时间序列的历史信息且运算速度快,成为了当今预测股票价格走势的热门工具。
Bagging[17]方法是一种集成学习方法,可以将多个预测模型组合起来,每种预测模型都使用经原始训练集采样得到的训练样本集来构建预测模型。当它用于预测时,不仅可以降低预测的误差,还可以降低结果的方差,避免过拟合的发生,使得预测结果更加稳定。例如,Karol[18]将Bagging算法与单个隐含层的前馈神经网络结合预测波兰的通货膨胀数据,通过与单个模型的预测结果比较,该模型表现出更好的预测性能。Yin等[19]使用Bagging方法对股票溢价进行预测,与LASSO方法相比,不管是经济繁荣还是衰退时期均取得了更多的经济收益。王康等[20]为了提高电力系统短期负荷预测精度,引入Bagging算法对双向加权GRU模型进行集成处理来提高模型的预测能力。Khwaja等[21]提出将装袋与ANN结合来改善短期电力负荷预测,通过实际数据证明,与单个ANN相比,两个方法结合后减少了负荷预测误差,并且在不同实例为并行的10个集合中,负荷预测的误差变化较小。
上述研究表明,GRU能够捕获金融时间序列的长期依赖关系且运算速度快,在股价预测中极具优势。Bagging方法用于预测研究时可以减少预测误差,提高预测精度。为此,本文引入Bagging方法并结合GRU神经网络对股价指数进行建模分析。首先,用Bagging方法对训练集进行采样10次,然后使用GRU模型对采样得到的训练集样本分别进行预测,最后对预测结果取平均值得到最终预测结果。通过一个国内指数(上证指数)和一个国际指数(德国DAX)为实验数据对本文构建的预测模型与其他三个基准模型(未加入装袋算法的GRU模型,极限学习机模型ELM和BP)的预测效果进行对比分析,验证本文所提出方法的有效性和实用性。
本文旨在提出一种有效的股价预测方法,为监管部门了解股市运行状况,制定有效的调整政策和帮助投资者规避股市的高风险,提高投资回报率提供一个有力的工具。本文的主要创新之处在于:(1)将Bagging方法引入到股指建模预测中去,通过对训练数据集进行多次采样,引入了随机性,降低了预测结果的方差和误差。(2)针对采样生成的多个训练集,采用GRU对其分别进行预测,GRU模型更好地捕获了复杂金融时间序列的长期依赖性,能够为非线性的金融时间序列建模提供参考。(3)引入Bagging方法与GRU神经网络结合,构建了集成学习框架,给机器学习建模设计提供了参考方向。
1 模型构建
1.1 GRU神经网络
RNN不能很好地学习股票时间序列的长期依赖关系,在训练过程中极易发生梯度消失和爆炸现象,使得模型陷入局部最优解[22]。为了解决这一问题,Hochreiter和Schmidhuber提出了LSTM神经网络模型[23]。LSTM神经网络与RNN相比做了一些改进,增加了能够保存长期状态的单元状态(cell state)结构,以及三个对单元状态进行控制的门(gate)结构,分别是遗忘门(forget gate)、输入门(input gate)和输出门(output gate)。三个控制门的存在,使得LSTM可以保存更长时间的信息。此外,可以通过LSTM的内部参数共享,设置权重矩阵维度控制输出维度。LSTM在输入和反馈之间建立长时间的延迟可以避免产生梯度消失或者梯度爆炸现象,能够很好地学习长期依赖关系。而GRU[24]改进了LSTM复杂的单元结构,减少并且合并了LSTM的门结构,在保证精度的基础上增加了网络训练的速度[25]。与LSTM有三个门(输入门、遗忘门、输出门)相比,GRU只有更新门(update gate)和重置门(reset gate),相关细节如下所示:
(1)将输入门、遗忘门、输出门变为更新门Zt和重置门rt。
(2)将LSTM的单元状态ct与输出合并为一个状态ht,图1为GRU神经元的单元结构。
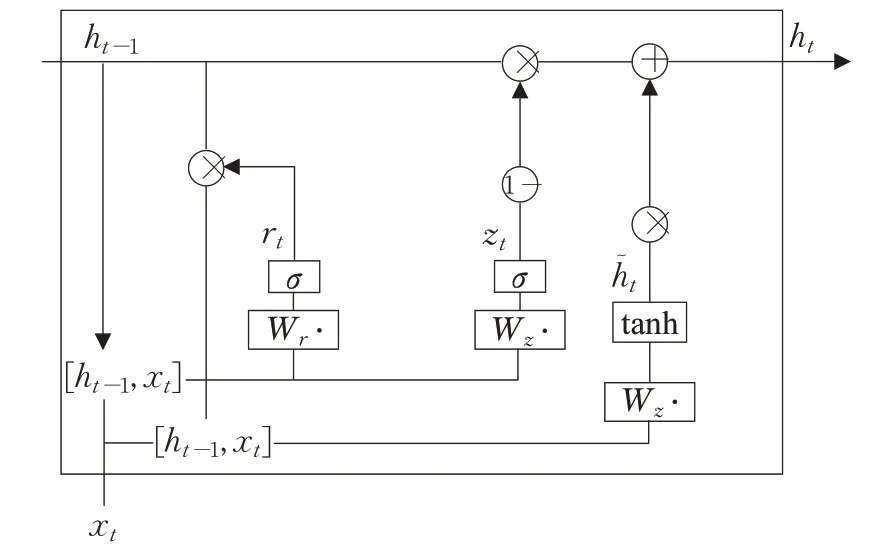
图1 GRU神经元结构Fig.1 GRU neuron structure
更新门Zt决定了上一时刻隐藏状态中有多少信息传递到当前隐藏状态ht中,重置门rt决定了上一时刻隐藏层状态中的信息有多少是需要被遗忘的,h͂t为当前时刻的隐藏层的候选状态,使用重置门可以决定当前候选状态中需要遗忘多少上一时刻隐藏状态ht-1的内容。W是权重矩阵,b是偏差向量,[ht-1,xt]表示两个向量的连接,σ和tanh是S型或者双曲正切函数。GRU单元的工作流程可以归纳为式(1)~式(4):
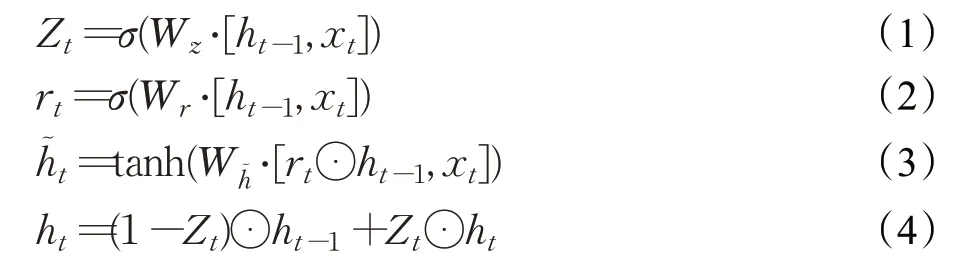
其中,⋅代表矩阵相乘,⊙代表矩阵对应元素相乘。与LSTM相比,GRU仅通过更新门Zt和重置门rt实现对信息的保留和遗忘,加快了训练速度。
1.2 装袋(Bagging)
Bagging[17]方法是一种集成学习方法,可以将多个预测模型组合起来,每种预测模型都使用经过原始训练集采样产生的训练集样本来构建预测模型。当它用于预测时,通过对训练集进行随机化采样处理,可以有效减少预测结果的方差,避免过拟合的发生,使得预测结果更加稳定[20]。Bagging方法的主要过程是从初始训练集中随机有放回地采样得到T个训练数据集,利用采样得到的训练集样本训练基学习器。对于预测问题,将T个预测模型产生的T个预测结果进行平均加权处理得到强学习器。Bagging涉及的步骤如下所示:
(1)输入训练样本集:假设神经网络的输入节点数为p,全部数据集预处理后得到m个样本。则处理后的样本为A1=(x1,x2,…,xp,xp+1),…,Ai=(xi,…,xi+p-1,xi+p),…,Am=(xm,…,xm+p-1,xm+p)。
(2)根据预处理得到的初始训练集D={A1,A2,…,Am},从初始训练集中随机有放回采集m个样本,得到一次采样结果Ft。
(3)迭代次数为T,对于每个t=1,2,…,T:对初始训练集进行第t次随机有放回采样,得到采样集Ft,用采样集Ft训练第t个基模型。
1.3 Bagging-GRU集成模型
Bagging-GRU集成的架构如图2所示,模型结构主要分为数据预处理、随机采样、训练、预测和集合。首先数据预处理将数据分为训练集和测试集,然后从输入层的训练数据集中随机有放回地抽取样本数m的样本集,共采集T次,得到T个训练集。随机有放回采样使得这T个训练集互不影响。将GRU神经网络作为基学习器,用采样得到的样本集训练GRU神经网络。通过T个训练好的GRU模型对测试集数据进行预测,得到T个预测结果,最后将T个预测结果进行平均加权处理获得最终预测结果。
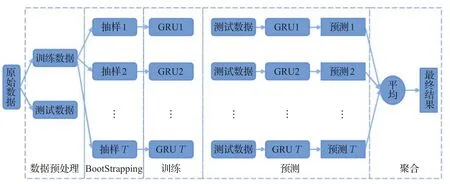
图2 Bagging集成策略Fig.2 Bagging integration strategy
2 实验分析
2.1 数据来源及预处理
本文采用国内上证指数(000001)、沪深300指数和标普500指数、恒生指数的日收盘价数据作为预测变量,数据来源于Wind数据库。为了消除数据之间的量纲差距,首先将指数取自然对数lnP,后对数据进行归一化处理。归一化过程采用以下公式:

上证指数数据和标普500指数时间范围从2016年10月25日起至2020年11月30日止,共1 000条数据。沪深300指数数据时间范围从2017年5月18日起至2021年6月25日止,共1 000条数据。恒生指数数据时间范围从2017年6月7日起至2021年6月25日止,共1 000条数据。为了观察不同预测方法对股指的预测效果,本文取各指数整体数据集最后100天作为测试数据集,剔除测试集即为对应训练数据集。
2.2 模型构建与参数设置
本文的Bagging-GRU和GRU预测模型是在Python3.7中的Keras框架下搭建并完成计算的,Keras版本为2.0.5,采用Keras中的Sequential模型结构,建立GRU预测模型。ELM和BP模型的预测是用Matlab搭建完成的。四种模型,Bagging-GRU、GRU、ELM、BP的神经网络结构都为4-4-1,即输入节点数量为4,隐藏节点数为4,输出节点为1。其中GRU模型的批处理大小(batch_size)为2,迭代次数(epoch)为100。基学习器的数目取10。
2.3 评价指标
为了评估目标模型Bagging-GRU的对股票价格的预测性能,本文采用平均绝对(MAE)、均方根误差(RMSE)、平均绝对百分比误差(MAPE)和平均绝对百分比误差的标准差(SDAPE)[9]四种误差评价指标对模型预测性能进行评价,四种指标的计算公式如下所示:

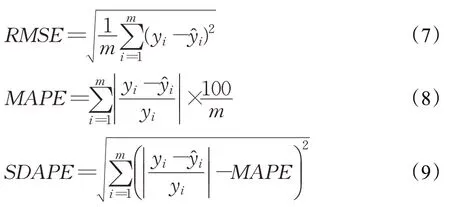
MAE、RMSE、MAPE是用来度量真实值与预测值之间的误差,数值越小证明误差越小。SDAPE的值越小代表预测结果越稳定。
2.4 股票价格预测
为了比较它们的预测性能,进行了对比实验,观察不同模型对同一指数的单步预测效果和同一模型对不同指数的预测效果,对比分析目标模型与其他模型的预测精度和稳定性差异情况。
本文采用100个交易日的长度衡量Bagging-GRU模型与GRU模型,ELM模型和BP神经网络四种预测算法的表现。图3展示了4种建模方法的100天预测结果,表1~表4展示了4个不同指数的测试集的预测误差。

表4 100个交易日恒生指数预测结果Table 4 Hang Seng index forecast results for 100 trading days
从图3中可以看出,四条曲线都围绕在真实值周围上下波动,其中Bagging-GRU的预测曲线与真实值曲线最为接近。从表1~4的误差统计表中可以看出,GRU对上证指数的预测精度高于ELM和BP模型,稳定度低于ELM模型高于BP模型。GRU对标普500指数的预测精度高于ELM和BP模型,稳定度低于上述两种模型。对沪深300指数的预测精度要高于ELM和BP模型,但是稳定度稍微低于ELM模型。对恒生指数的预测精度和稳定度均高于ELM和BP模型。而ELM模型对上证指数、标普500指数、沪深300指数和恒生指数的预测精度和稳定度优于BP模型。将Bagging方法和GRU模型结合以后,显著提高了GRU的预测精度和稳定度。以恒生指数为例,Bagging-GRU模型的MAE、RMSE、MAPE值分别为0.012 7、0.015 8、0.124 0相对于ELM的0.014 7、0.018 6、0.142 9,它的预测精度分别提高了13.6%、15.1%和13.2%;相对于BP的0.016 8、0.021 8、0.163 4,分别提高了24.4%、27.5%、24.1%;相对于GRU的0.013 3、0.017 1、0.129 5,分别提高了4.5%、7.6%和4.2%;Bagging-GRU的预测SDAPE值为0.009 1,相对于GRU(0.010 4)、ELM(0.011 1)、BP(0.013 6)稳定度分别提升了12.5%、18.0%、33.1%,稳定度有了大幅度提升。对于另外三个指数、精度和稳定度都有相似程度的提升。由此可见,Bagging-GRU方法在预测股价指数时,对多种股指数据预测都有效,可提高预测精度和稳定度,对股指预测具有优越性。
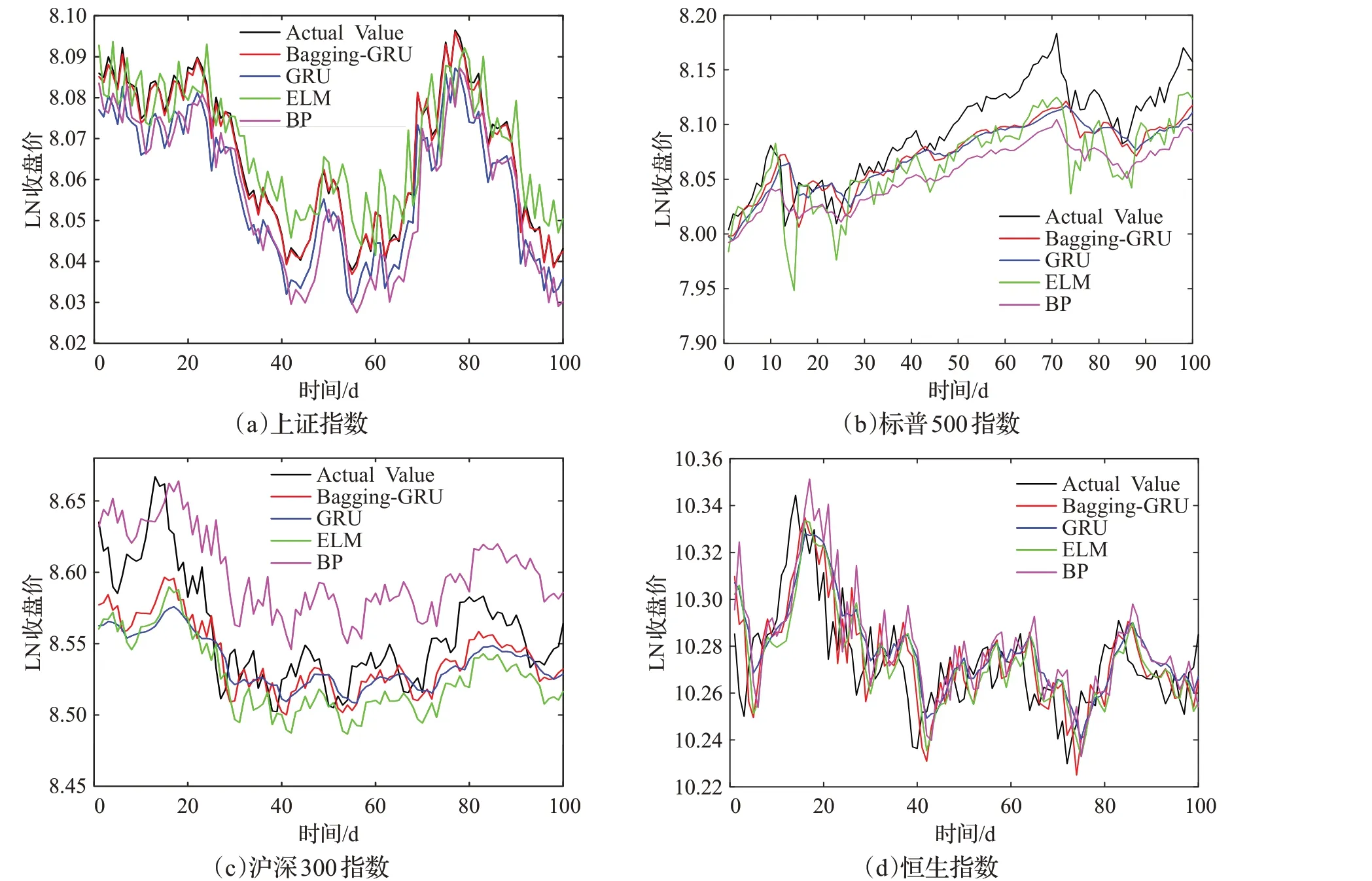
图3 4种建模方法的预测结果对比Fig.3 Comparison of long-term prediction results of four modeling methods
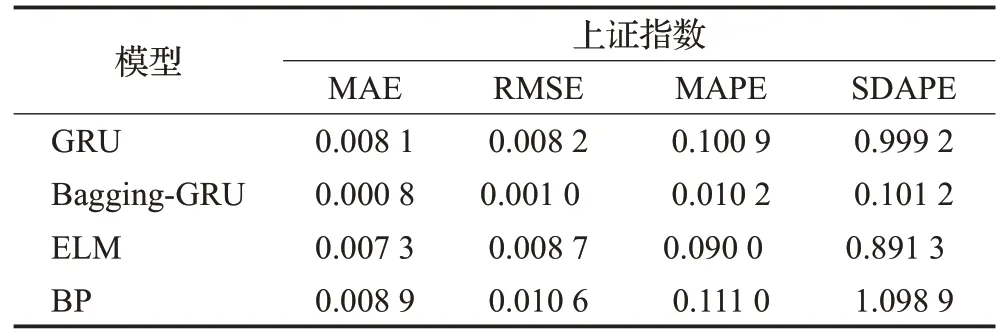
表1 100个交易日上证指数预测结果Table 1 Shanghai Stock exchange index forecast results in 100 trading days
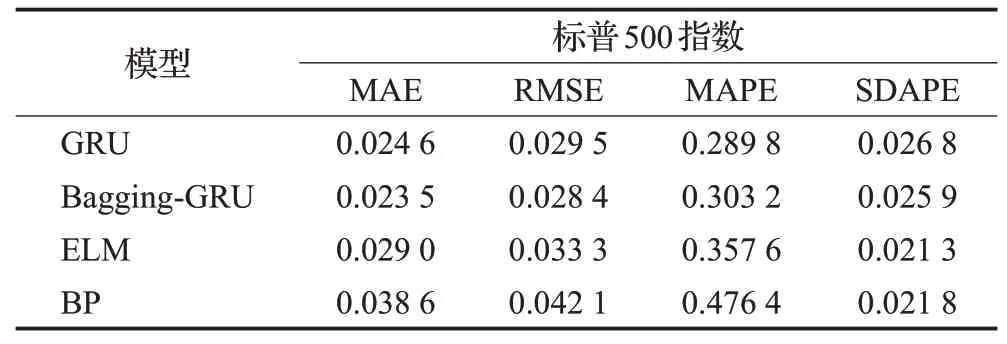
表2 100个交易日标普500指数预测结果Table 2 Forecast results of SPX500 index in 100 trading days
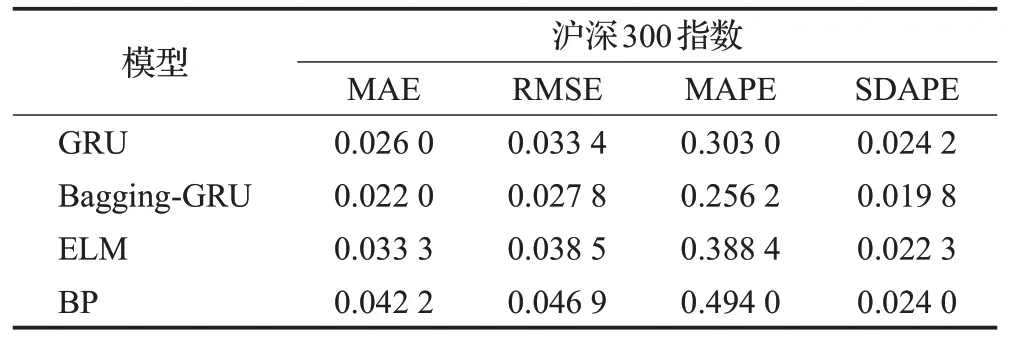
表3 100个交易日沪深300指数预测结果Table 3 Forecast results of the Shanghai and Shenzhen 300 index in 100 trading days
综合来看,GRU模型在对100天股价指数预测时,相对于ELM和BP模型,在大多数情况下都有较小的预测误差和较高的稳定度,比较适合于用来预测非线性、非平稳的股票价格时间序列。将Bagging方法和GRU结合起来对股票价格指数进行预测时,它的预测误差明显小于其他三种对比模型,预测稳定度高于对比模型。由此可见,引入Bagging算法可以进一步提高模型预测精度和稳定度。
3 结语
本文根据股指时间序列长期依赖性的特点,引入目前前沿的深度学习领域的GRU神经网络模型,结合Bagging集成方法,构造Bagging-GRU模型,对国内外代表性股指时间序列进行单步预测研究。同时,与三种对照模型(GRU模型、ELM模型和BP神经网络模型)的100天预测结果进行对比分析,并系统地分析了各个预测模型的评价指标数据,得到如下结论:(1)GRU网络模型确实是比较好的股价预测模型,在预测股价时,能够较好地捕获非线性时间序列的特征,取得更好的预测效果。(2)将Bagging方法与GRU模型结合以后,显著提高了GRU模型的预测效果,该模型的预测结果显示最小的预测误差和最大的预测稳定度。(3)Bagging-GRU模型对多种股指时间序列的预测都有优越的预测效果,非常适合于股票价格预测。
结合上述结论,可以看出本文构建的Bagging-GRU模型能够比较全面、准确地掌握股指数据的变化情况,有助于决策部门和政策制定者对股票市场乃至金融市场提前预判,为相关政策制定提供参考。其次,本文构建的机器学习模型可以监控股票市场变动,帮助投资者发现投资机会,提高投资回报率。本文构建的模型还可以为其他金融市场时间序列预测提供实践经验。由于神经网络的可调节性,未来可以对模型可以进行进一步改进,例如在输入变量上可以选择其他非同质化信息,也可以在技术方面对模型优化和改进,这是未来值得探究的方向。
