基于卷积神经网络的智能找矿预测方法
——以甘肃龙首山地区铜矿为例
2022-06-23李忠潭薛林福冉祥金李永胜董国强李玉博戴均豪
李忠潭, 薛林福, 冉祥金,李永胜,董国强,李玉博,戴均豪
1.吉林大学地球科学学院,长春 130061 2.中国地质调查局发展研究中心,北京 100037 3.自然资源部矿产勘查技术指导中心,北京 100083 4.甘肃省地质调查院,兰州 730000
0 引言
将大数据思维和深度学习方法引入地学领域,并利用数学工具进行数据清理和挖掘,将有助于矿产资源预测[1]。应用机器学习技术进行地质找矿信息挖掘与找矿预测远景区圈定已经成为当今数字地质科学的前沿研究领域。目前地质矿产勘查工作积累了大量的地质、地球化学、地球物理及遥感地质资料,为机器学习及深度学习算法的应用提供了大数据支撑[2]。
近年来,诸多学者致力于利用机器学习的方法进行地质找矿信息挖掘与集成研究。例如:Brown等[3]将多层感知机模型用于多源数据集成,预测澳大利亚部分地区的金矿成矿潜力,结果表明多层感知机的预测性能要好于证据权方法和模糊逻辑方法;Leite等[4]将径向基函数网络应用于巴西北部卡拉加斯矿产省铜-金区域成矿潜力预测,圈定了铜-金成矿的有利远景区;Leite等[5]又将概率神经网络模型应用于巴西亚马逊河流域卡拉加斯矿产省东北部的潜在铂族元素(铂族元素)矿化远景区的预测,绘制了铂族元素矿点矿产潜力图;陈永良等[6]定义了面向矿产靶区预测的三层Boltzmann机模型,根据证据权系数和统计单元证据组合特征计算单元成矿有利度,圈定找矿靶区,并应用于新疆阿勒泰地区的矿产靶区预测研究;Carranza等[7]对比了随机森林、证据权法和逻辑斯蒂回归等模型的成矿预测应用效果,结果表明随机森林方法表现出了更优秀的拟合和泛化性能,且对于缺失值和小训练样本集(小于20个)同样具有较好的处理和能力;Zhao等[8]利用多重分形和人工神经网络方法识别宁强矿区与金铜矿化有关的地球化学异常;Mehrdad等[9]提出了一种基于混合遗传的广义随机森林(GRF)模型,并在伊朗东北部Feizabad地区取得了较好的应用效果;Ghezelbash等[10]提出了一种改进的数据驱动简单加权法生成远景模型的方法和基于径向基函数核的支持向量机(SVM)方法,并在伊朗东北部Moalleman地区圈定铜金成矿有利区,对比发现后者的预测模型更为可靠。
目前,深度学习方法已成功应用于成矿预测和地球化学异常识别研究。例如:Luo等[11]应用深度变分自编码器(VAE)提取地球化学异常,发现VAE识别的地球化学异常与已知的铁多金属矿床具有密切的空间相关性;Zhang等[12]应用自编码器和基于密度的空间聚类相结合的方法识别地球化学异常,证明了自编码器和基于密度的空间聚类适用于多元地球化学异常检测。
卷积神经网络(CNN)是目前应用最广泛的神经网络模型之一[13],在地质学领域,CNN已经成功应用于岩性识别[14]、地质填图[15]和三维地质结构反演[16]等研究。近年来,诸多学者把CNN应用于找矿预测研究。刘艳鹏等[17]应用CNN建立了安徽省兆吉口铅锌矿床地表 Pb 分布特征与矿体就位空间关系模型,并进行成矿预测,得出CNN可以有效挖掘地表元素分布与矿体就位空间关系的结论;Li等[18]提出了一种基于CNN分类的文本挖掘方法,建立了从地学文本数据中提取关键找矿信息的工作流程,以四川拉拉铜矿为例,完成了智能分类与标注,探索了数据之间的潜在关系,实现了地质找矿信息的智能提取;蔡惠慧等[19]以甘肃省大桥地区金多金属矿田为例,提出了利用一维CNN替代传统的人工计算,通过对研究区金多金属矿的地球化学及地球物理数据进行训练,挖掘研究区综合成矿信息,依据训练结果划分出4 类成矿远景区,发现CNN模型能够很好地实现矿产资源智能化预测评价;Zhang等[20]测试了在数据驱动的矿产远景制图中,使用无监督卷积自编码(CAE)支持CNN建模以合成多地理信息的有效性,结果表明利用CAE训练数据建立CNN模型的结果与研究区已知金矿床具有很强的空间相关性,表明其是一种新的潜在的矿产远景填图方法;Li等[21]将CNN用于中国福建省西南部的矿产远景测绘,构造的模型所获得的矿产远景区域与已知矿化位置具有很强的空间相关性;Sun等[22]对比了随机森林(RF)、SVM、人工神经网络(ANN)和CNN等方法,在中国江西省南部进行了数据驱动的钨元素矿产远景建模;Li等[23]将地球化学数据与CNN算法和迁移学习方法相结合,勾勒了中国安徽省东部张八岭地区地球化学金矿找矿远景区。
综上可知,前人基于深度学习方法的矿产预测方法并未将地球化学元素数据和航磁数据结合起来进行讨论。甘肃龙首山地区成矿地质条件良好[24],已发现众多铁、铜、钼和金等矿点,具有巨大的矿产资源潜力,且资料齐全,为开展人工智能找矿预测创造了良好的条件。本文以龙首山高台县臭泥墩—西小口子地区的铜矿为例,利用地球化学元素数据和航磁数据,旨在探讨基于二维卷积神经网络的智能找矿预测方法的应用。
1 地质背景
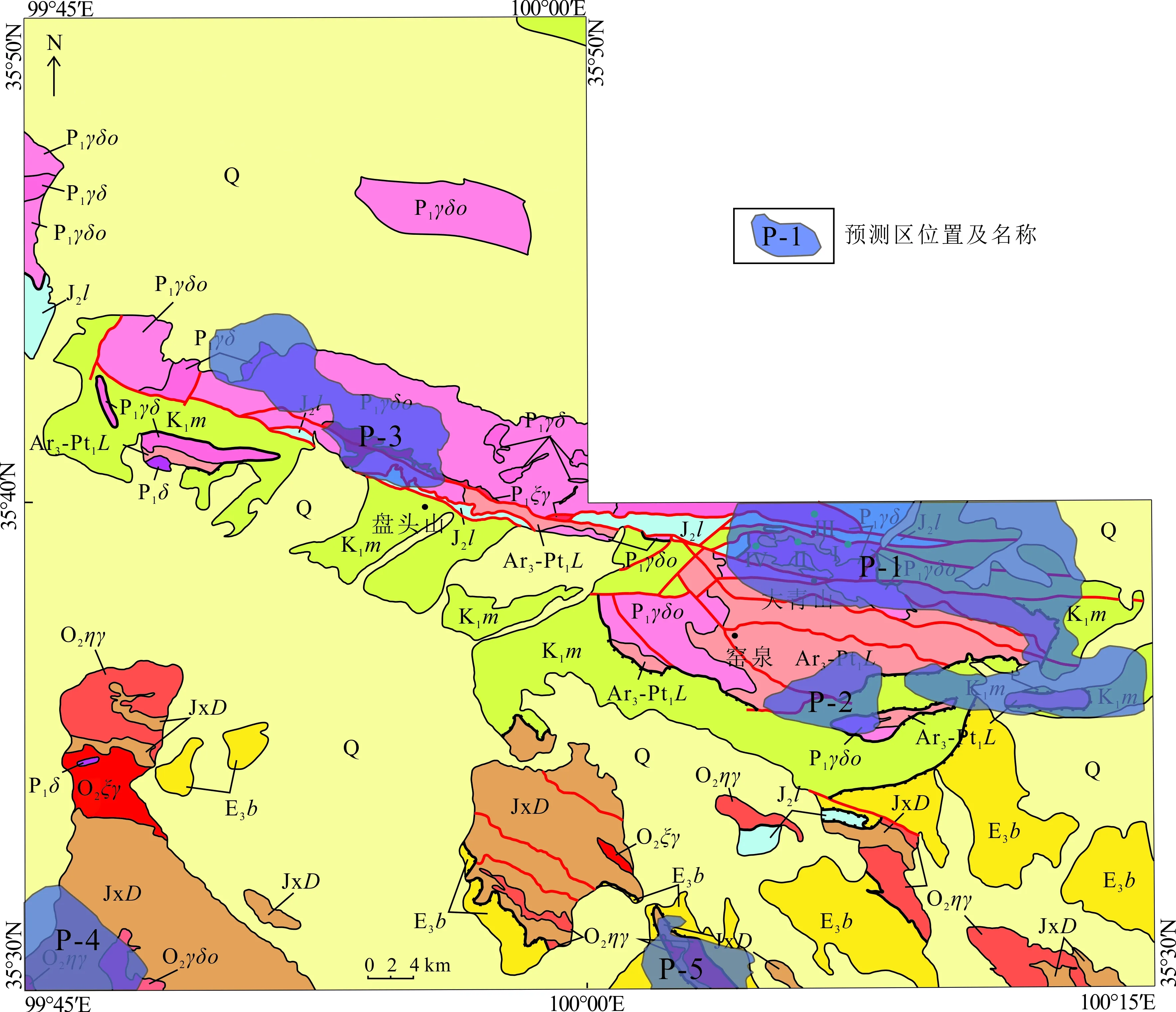
研究区位于甘肃省高台县臭泥墩—西小口子地区,大地构造上位于华北板块阿拉善陆块龙首山基底杂岩带,阿拉善陆块南缘龙首山山体(图1a)。出露地层有新太古界—早元古界龙首山岩群(Ar3-Pt1L.)、中元古界蓟县系墩子沟群(JxD)、侏罗系龙凤山组(J2l)、白垩系庙沟组(K1m)及古近系白羊河组(E3b)。区域构造极为复杂,主要受加里东期和海西—燕山期陆内调整阶段的影响,逆冲构造和伸展构造相互叠加,以EW向和NWW向为主(图1b)。区内以大青山向斜、大青山北冲断层、天城—大孤山弧形褶皱带为主要构造,次级构造发育,且存在隐伏深大断裂,有利于岩浆侵入和矿床的形成[25]。研究区侵入岩较发育,属阿拉善构造岩浆岩带龙首山基底杂岩带构造岩浆岩亚带合黎山后碰撞岩浆岩段,主要为大规模中酸性侵入岩,具中深成相,属钙碱性系列,侵入活动以加里东中期最强烈,岩浆侵入活动与构造运动序次有较明显的依存关系。海西早期侵入体分布于盘头山—窑泉—大青山等EW向构造带内。加里东期岩体主要侵位于研究区南部方架山—小孤山—猴儿头一带。
研究区矿产的形成与岩浆侵入活动紧密相关,尤其与海西早期岩浆侵入活动关系密切,是矿产的主要成矿期,区内矿点、矿化点较多,且矿(化)体具有一定的规模。矿床的形成与地层、构造、岩浆岩有着密切的关系,区内及周边已发现铁、钛、锰、铜、镍、铅和锌等矿种。研究区内现已发现的典型矿床有板凳沟钛磁铁矿、大青山铜矿以及东小口子铁矿等。
研究区内海西期在裂陷拉张环境下形成巨大的岩浆带[26],在岩浆演化过程中形成一系列与岩浆岩有关的矿产,为区内海西期构造-岩浆旋回岩浆岩成矿系列。成矿模式为随着加里东期大规模造山运动的结束,在海西期陆内调整阶段形成拉张的裂陷环境,在海西早期随裂陷的拉伸侵入中基性岩浆,岩浆在侵入过程中分异形成闪长岩和角闪岩;海西中期裂陷进一步拉张,以花岗闪长岩和二长花岗岩为主的中酸性岩浆大规模侵入[27],在中酸性岩浆侵入接触部位形成矽卡岩型铜矿及大规模黄铁矿化蚀变带;海西晚期在断裂构造交汇部位侵入石英二长斑岩体并形成斑岩铜矿;其后随岩浆期后热液活动在构造裂隙中形成裂隙型铜矿,从而形成裂陷构造环境下的岩浆成矿模式。
2 卷积神经网络模型与应用步骤
2.1 基于卷积神经网络的找矿预测模型
卷积神经网络是一类包含卷积计算的深度前馈神经网络[28],在计算机视觉和自然语言处理等领域受到广泛的关注和应用。卷积神经网络的核心就是利用局部感受野(感知域)、权值共享和汇聚层的思想来达到简化网络参数的目的,并且使得网络具有一定程度的位移、尺度、非线性形变稳定性[29]。
卷积神经网络的找矿预测模型主要由数据输入层、卷积层、池化层、全连接层和输出层5种网络层构成[28]。其中:数据输入层是将网格化的化探和航磁数据作为输入数据写入神经单元,卷积层与池化层分别选择合适的激活函数完成对数据特征的提取和下采样,全连接层则是在网络末端实现特征的映射和分类,而输出层可用于结果输出或特征可视化。因此,确定合适的卷积层和全连接层结构对卷积神经网络模型的性能至关重要。本文采用的卷积神经网络模型由4个卷积层、4个池化层和1个全连接层组成(图2)。

1. 第四系冲积物、坡积物、洪积物;2. 古近系白羊河组含砾砂岩、泥质粉砂岩夹砂岩及泥岩;3. 白垩系庙沟组砖红色粉砂质泥岩与浅灰绿色粉砂质泥岩互层,局部夹浅灰褐色细砂岩和中粗粒长石石英砂岩;4. 侏罗系龙凤山组浅灰色粗砂岩、砂砾岩和灰色细砂岩、砂质泥岩呈韵律夹薄煤层;5. 蓟县系墩子沟群二云斜长片岩、黑云斜长片麻岩夹大理岩、花岗质黑云斜长片麻岩、斜长角闪片岩、浅粒岩;6. 新太古界—古元古界龙首山岩群黑云石英片岩、大理岩、黑云角闪斜长片麻岩、二云石英片岩、黑云斜长变粒岩;7. 早二叠世花岗闪长岩;8. 早二叠世英云闪长岩;9. 早二叠世闪长岩;10. 早二叠世正长花岗岩;11.中奥陶世正长花岗岩;12. 中奥陶世英云闪长岩;13. 中奥陶世二长花岗岩;14. 断层;15. 地质界线;16. 角度不整合界线;17. 地名;18. 铜矿及编号。Ⅱ-7-2.陆缘岩浆弧;Ⅳ-7-3.龙首山基底杂岩带;Ⅳ-1-1.走廊弧后盆地。据文献[25]修编。
图1 研究区大地构造位置(a)及地质略图(b)
Fig.1 Geotectonic location (a) and geological sketch (b) of the study area
1)卷积层(convolution):是卷积神经网络的核心,体现了卷积神经网络的局部连接和权值共享特性。卷积时先通过使用特定尺寸的卷积核(权值矩阵)提取整体数据的局部特征,然后通过步长平移的方式提取不同位置的数据特征。卷积核相当于卷积操作中的一个过滤器,用于提取数据特征,特征提取完后会得到一个特征图。
卷积之后,通常会引入非线性激活函数。激活函数也被称为非线性映射函数,激活函数对神经网络模型学习、理解非常复杂的目标域具有重要意义[30]。本文使用的激活函数为RuLU函数,计算公式如式(1)所示:
f(x)=max (0,1)。
(1)
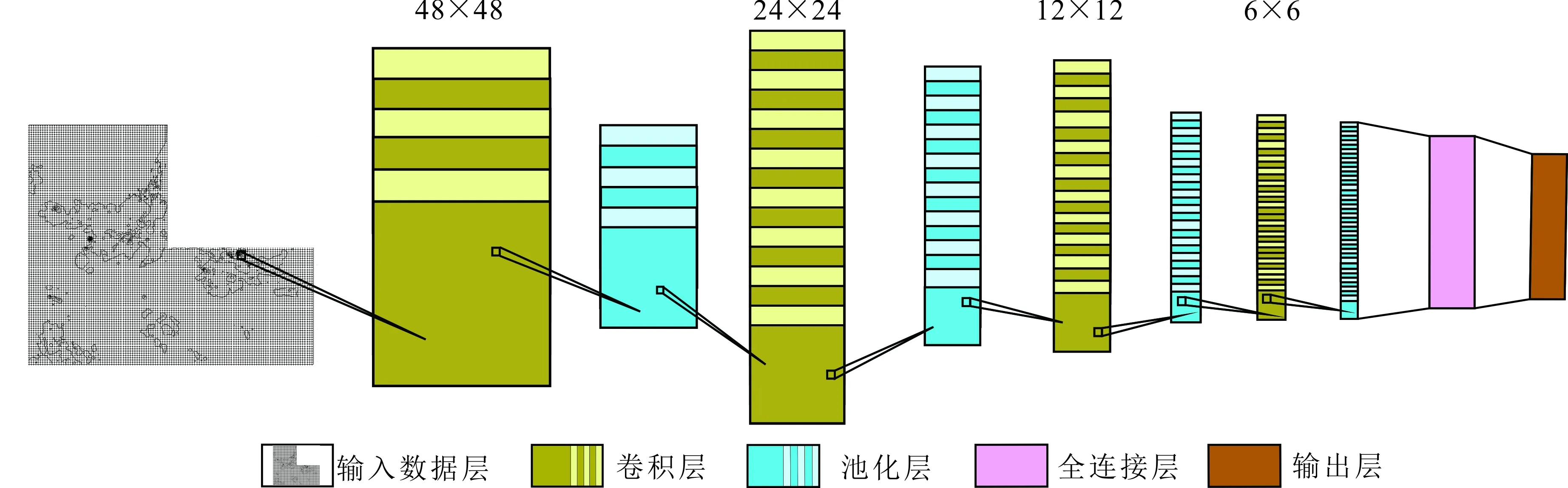
图2 找矿预测卷积神经网络模型架构
该公式在保证训练效果的同时可以加快训练速度。
2)池化层(pooling):对输入的特征数据进行压缩,简化网络计算复杂度,提取主要特征[31]。池化操作相当于降维操作,有最大池化和平均池化,本文使用的是最大池化(max pooling)。经过卷积操作后提取到的特征信息,相邻区域会有相似特征信息,如果全部保留这些特征信息会存在信息冗余,增加计算难度。通过池化层会不断地减小数据的空间,从而使得参数的数量和计算量会有相应的下降,这在一定程度上控制了过拟合。
3)全连接层(fully connected layers):全连接层的每一个结点都与上一层的所有结点相连,用来把之前提取到的特征综合起来。对n-1层和n层而言,n-1层的任意一个节点,都和第n层所有节点有连接。即第n层的每个节点在进行计算的时候,激活函数的输入是n-1层所有节点的加权。
2.2 基于卷积神经网络的找矿预测方法与步骤
基于卷积神经网络的找矿预测方法主要是在对元素地球化学异常数据、航磁数据进行网格化的基础上,先采用数据增强技术获取训练数据和验证数据集,再基于卷积神经网络训练生成模型,并应用训练好的模型预测研究区的有利找矿部位(图3)。
基于CNN找矿预测的具体步骤如下。
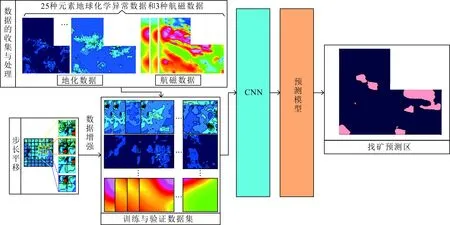
图3 基于卷积神经网络找矿预测流程图
1)数据的收集与处理
收集研究区内已有的元素地球化学异常数据和航磁数据,并将研究区内已知的矿床(点)信息提取出来,为下一步的处理提供数据基础。收集到的数据是在空间上不均匀分布的数据,需要利用插值方法将其转化成规则网格数据。在本文中应用克里格法实现二维数据的格网化,得到25种元素地球化学异常数据和3种航磁数据,具体描述见下文。
2)训练与验证数据集的生成
在矿产预测研究区,通常已知矿床(点)的数量较少,难以满足深度学习对训练样本量的要求,构建大容量训练样本是深度学习找矿预测模型建模过程的一个挑战。本文采用步长平移数据增强方法构建训练样本集,从而得到泛化能力更强的网络,使得结果更具可信度。步长平移数据增强方法是采用一定窗口大小,如48×48=2304个网格单元,通过移动窗口使矿床(点)位于1个网格单元中(图4),提取窗口所包括的所有物探和化探网格数据,遍历所有窗口网格单元。对于1个矿床(点)可以获取2 304个训练单元。如果1个研究区有n个矿床(点),则可以获得2 304n个训练单元。在研究区随机选取已知矿床(点)数2倍的网格单元作为未知区,采用与生成已知矿床(点)训练单元相同的方法获取未知区的训练单元。
3)卷积神经网络模型构建
地质空间的特征是以网格单元为基本单元,每个网格单元上集合了地球化学、航磁等空间特征数据,构建找矿预测CNN模型。利用CNN模型可以提取关键空间特征,挖掘矿床与数据特征间的非线性关系。
4)模型的训练与验证
先采用准备好的训练数据集对模型进行训练与验证,再采用不同参数和超参数对模型进行训练,通过验证数据集选取最优模型。
5)找矿预测区的确定
采用训练好的模型,通过滑动窗口的方式对研究区进行预测,圈定有利预测区,并根据矿产地质资料,分析预测结果的可靠性,从而确定找矿预测区。
3 数据处理与预测结果
本文探讨的是利用元素水系沉积物化探测量数据和航磁数据进行找矿预测区的圈定,在圈定的找矿预测区辅以地质条件分析,具体过程如下。
3.1 数据处理
1)地化数据
研究区有Ag、As、Au、B、Be、Bi、Cd、Co、Cr、Cu、Hg、La、Li、Mn、Mo、Nb、Ni、Pb、Sb、Sn、Th、Ti、U、W和Zn等25种元素水系沉积物化探测量数据,每种元素水系沉积物化探测量数据都反映了该区域不同的元素特征。CNN模型在训练时,能够根据已知的铜矿点确定元素所占的权重。利用Surfer软件对25种元素进行网格化,规则网格的大小需要根据研究目的和工作比例尺来确定。对数据进行网格化,可以将空间上分散的数值转换成规则分布的网格数值,抑制局部噪音,并按规则对空白网格赋予数值,得到统一的空间结构,对数据进行网格化能够充分地反映客体变量的空间模式。

图4 基于CNN的预测方法
综合对比几种插值方法,克里格方法不仅能够反映距离的关系,而且能够通过变异函数和结构分析,确定已知样本点的空间分布及与未知样点的空间方位关系[32]。本文利用克里格插值法,将网格单元大小设为100 m×100 m(表1),得到25种水系沉积物化探网格化数据,总网格单元数为432×316=136512个。

表1 本文地化元素数据网格化标准
选取该区域Cu、Mo、Zn和As等4种元素[33](元素地球化学质量分数单位均为10-6),采用克里格插值法对该元素按100 m×100 m网格单元大小进行网格化,4种元素1∶5万等值线图如图5所示,对比图1,发现4种元素均在大青山附近有明显异常,该地区包含已发现的大青山铜矿区域。Cu、Mo元素地球化学异常在盘头山和窑泉北也有反映,盘头山异常范围大,此异常处于海西中期花岗闪长岩中,有一定找矿潜力;窑泉北异常地处位置边缘有英云闪长岩出露,有一定找矿潜力。Zn、As元素地球化学异常在方架山南也有异常反映,该区域异常有侵入岩体,以加里东期酸性岩为主,出露有二长花岗岩和正长花岗岩区,区域南侧有英云闪长岩,出露面积较小。
2)航磁数据
研究区有3幅1∶5万的航磁数据,利用克里格插值法对航磁数据进行网格化,网格单元大小为100 m×100 m(与表1相同)。利用Geosoft软件对数据进行处理,得到ΔT化极航磁异常图(图6a),考虑到之后需要使用的航磁延拓数据,故对网格化之后的数据分别进行向上50 m(图6b)、100 m(图6c)和150 m(图6d)的延拓。本文需要用到的是ΔT化极航磁异常图、50 m向上延拓图和100 m向上延拓图,将这3种航磁图提取数据并按照表1的标准进行网格化,得到3种航磁数据的网格化数据。
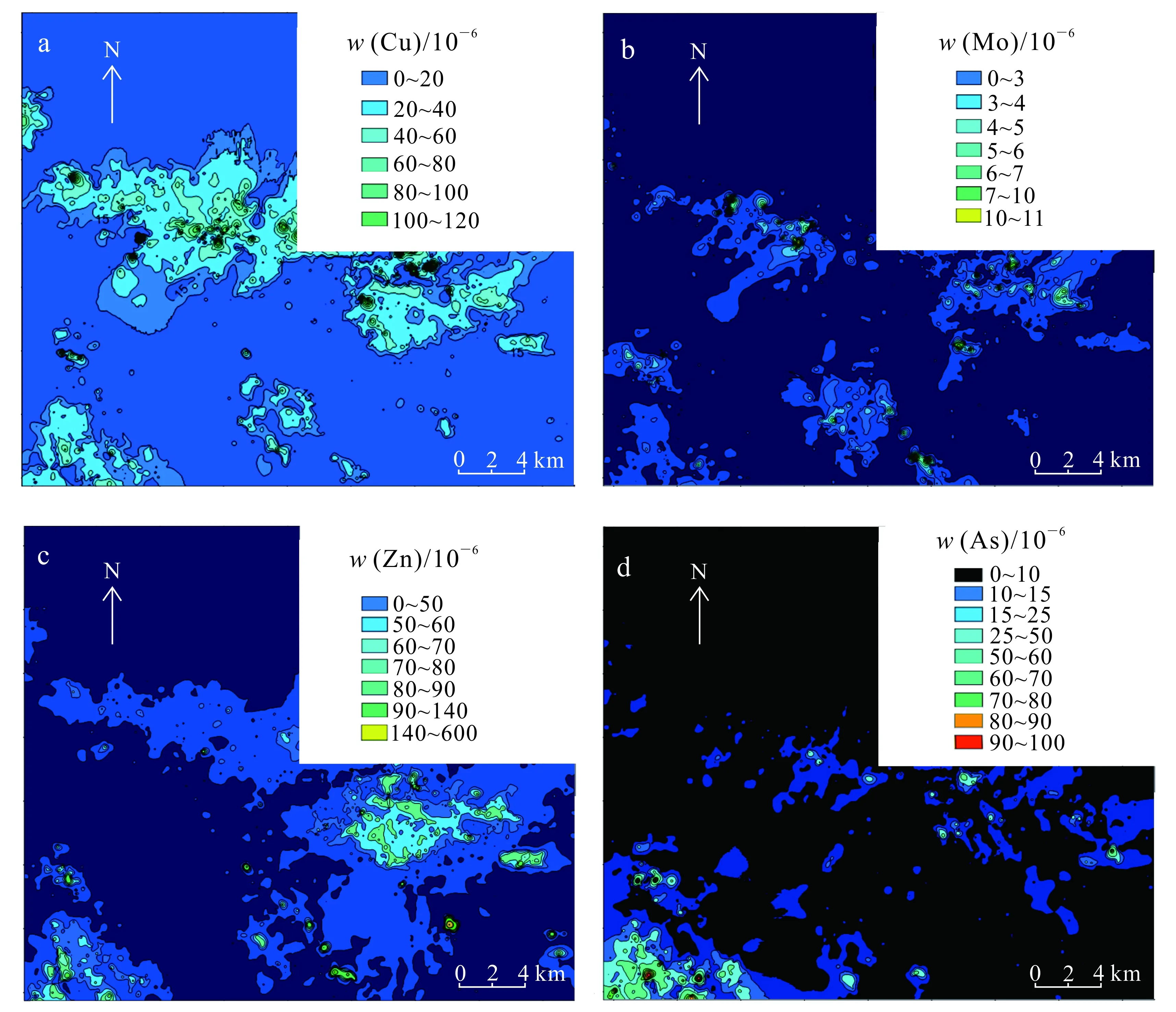
图5 研究区4种元素1∶5万地球化学元素等值线图
由图6a可知:研究区的磁异常条带的延伸方向呈NW向,主要存在南北2个高磁异常带;对比图1可以得到,北部高磁异常带位于该区北部大青山—天城北西西—东西向带状高磁异常区带,带内为以中酸性侵入岩为主的巨大岩浆带,异常大多数由闪长岩体等中酸性侵入岩引起,沿北部磁异常条带发现了铜矿床(点)。
向上延拓主要是对浅部地质体的干扰进行压制或消除,同时能对深部有意义的地质体产生有用的磁性异常进行突出和显示。由向上50 m延拓结果图(图6b)可知:该地区磁异常较为集中,主要集中在研究区中西部及西南部两处。为了进一步消除影响,对该区域继续进行100 m延拓(图6c)和150 m延拓(图6d),发现磁异常区域主要集中在中西部及西南部,在后期进行成矿有利区圈定应该尽量集中在磁异常区域。
为了展现研究区航磁异常方向性的变化特征,对研究区网格化之后的原数据在不同方向上进行求导,分别求出该研究区0°(图6e)、45°(图6f)、90°(图6g)和135°(图6h)的方向导数图。结果表明,在求导之后,研究区航磁异常区主要呈NW向展布,也显示出一些NE向变化特征。
3)矿点成矿地质特征
研究区已知铜矿点有4个,分别为大青山Ⅰ号铜矿、大青山Ⅱ号铜矿、大青山Ⅲ号铜矿、未定名Ⅳ号铜矿,具体位置如图1b所示。铜矿主要发育在大青山地区,铜矿的类型主要为斑岩型铜矿和裂隙浸染型铜矿。
成矿时代主要为海西期,斑岩型铜矿的成矿母岩为石英二长斑岩,斑岩具同心状分布的青磐岩化带、钾化带、绢英岩化带、泥化带和孔雀石化等蚀变带,矿化产在泥化带中。大青山Ⅰ、Ⅱ号铜矿为典型斑岩型铜矿,处于中酸性斑岩体附近。裂隙浸染型铜矿在区内普遍分布,主要分布在花岗闪长岩和二长花岗岩大规模的青磐岩化、钾化蚀变带的裂隙中,主要为浸染状的孔雀石。出露的地层为新太古界—古元古界龙首山岩群,成矿母岩为石英二长斑岩。矿体主要赋矿地质体为石英二长斑岩,该岩体侵入于海西中期花岗闪长岩中,形成于海西晚期,为区内基性—中酸性侵入岩岩浆演化晚期的产物,为钙碱性系列,反映了过渡性构造环境。这种构造环境、岩浆岩类型与斑岩铜矿成矿环境一致。矿体的围岩为石英二长斑岩,矿体与围岩界线呈渐变过渡关系,围岩蚀变以泥化为主。

a. ΔT化极航磁异常图;b. 向上延拓50 m结果图;c. 向上延拓100 m结果图;d. 向上延拓150 m结果图;e. 方向导数为0°的结果图;f. 方向导数为45°的结果图;g. 方向导数为90°的结果图;h. 方向导数为135°的结果图。
矿区内构造主要为窑泉北逆断层,为近EW向—NWW向,切割花岗闪长岩和石英二长斑岩(图1),该断层发育宽20~60 m的断层角砾岩、碎裂岩带并发育强烈褐铁矿化。
3.2 铜矿预测结果
元素地球化学异常及航磁异常与已知矿床(点)具有较好的对应关系,基于化探和航磁资料,采用CNN模型(图4)对研究区有利的铜矿找矿区进行了预测。
元素水系沉积物化探测量数据和航磁数据都已经按照图1的地质图范围进行了限定,输入的数据层为25种元素的地球化学网格化数据、ΔT化极航磁异常、向上延拓50 m、向上延拓100 m的网格化数据,共计28种数据,每种数据都通过Surfer软件按照表1的网格转换成了一个432×316的网格数据层。对每种类型的数据均采用离差标准化方法进行处理,采用主成分分析法(principal component analysis,PCA)把28维数据层压缩为24维。窗口大小设定为48×48个网格单元,窗口覆盖的实际范围相当于4 800 m×4 800 m,每个窗口的输入数据通道数为28,卷积核的大小为3×3,第一层卷积核数量为48,步长设置为1,模型的优化算法选用Adam算法,学习率设为0.001,衰减率设置为默认值。
训练数据集和验证数据集是根据已知3个铜矿点,采用数据增强方法获取了22 934个训练数据。其中:70%的数据用于训练模型,包括16 054个训练数据;30%用于模型验证,包括6 880个训练数据。
采用上述参数及数据集对模型进行了200轮训练和验证。结果显示,当进行了50轮训练后,模型趋于稳定,模型精度为98.1%左右(图7)。
采用训练好的模型对研究区的有利铜矿找矿区进行了预测。从预测结果图(图8)可以看出,通过建立的CNN模型得到研究区5个找矿有利区。
P-1:位于山头窑—窑泉—大青山北一带,预测区内包含已知的4个铜矿点,区内岩体主要为海西期闪长岩和正长花岗岩,具有多期次特征,总体走向与构造线基本一致;中部有后期沉积的侏罗系龙凤山组浅灰色和灰白色砾岩、砂质砾岩、砂岩及泥岩;南部出露于白垩系庙沟组中,且有新太古界—古元古界龙首山岩群。该区域存在Cu元素化探异常高值。
P-2:位于窑泉北东部地区,区内出露有新太古界—古元古界龙首山岩群及白垩系庙沟组;断裂构造发育,且具有多期次。该区域存在铜元素化探异常高值。
P-3:位于盘头山附近,区内有海西期闪长岩、正长花岗岩侵入,具有多期次特征;岩体总体走向与构造线基本一致,南部为侏罗龙凤山组浅灰色和灰白色砾岩、砂质砾岩、砂岩、泥岩、页岩夹薄层煤层及煤线。该区域存在Cu元素化探异常高值。
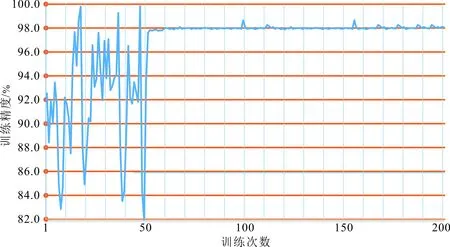
图7 CNN找矿预测模型训练与预测过程
图例同图1。
P-4:预测区主要地层为蓟县系墩子沟群变砂岩、变粒岩,地层总体呈NW—SE向展布,侵入岩以加里东期酸性岩为主,北侧为二长花岗岩和正长花岗岩区,南部为闪长岩。该区域有Cu元素化探异常高值。
P-5:位于研究区南部,区内主要为蓟县系墩子沟群变砂岩、变粒岩,中部出露有加里东期酸性侵入岩,岩性为二长花岗岩。该区域有Cu元素化探异常高值。
4 讨论
4.1 超参数对预测结果的影响
4.1.1 PCA主分量数对预测结果的影响
PCA,即主成分分析方法,是一种使用最广泛的数据降维算法。PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新坐标轴的选择与数据本身是密切相关的[34]。
本文利用CNN对选取的28维数据进行铜矿有利区进行预测(包括25种元素地球化学数据和3种航磁异常数据),由于28维数据对计算机运算太过冗杂,故需要对数据维度进行压缩。对数据维度进行压缩时产生的预测结果不同,对比4种PCA主分量数对预测结果的影响如图9所示。
实验结果表明,维度越高,所得的预测区域越复杂,但总体有一定的相似性。4种方法中,将28维数据压缩为24维数据所得的预测结果更符合实际地质情况。

a. 28维数据压缩为24维数据;b. 28维数据压缩为16维数据;c. 化探数据压缩为14维,航磁数据压缩为2维;d. 化探数据压缩为6维,航磁数据压缩为2维。
4.1.2 窗口大小
窗口大小对训练数据集、预测结果均有一定影响,并对模型精度产生影响。根据训练数据的提取方法可知,窗口越大,能够提取的训练数据集也越大,当窗口大小分别为12×12、24×24、48×48时,可提取训练样本数分别为3 056、8 048、22 934。3种预测结果图如图10所示。
实验结果表明,窗口大小不同会产生不同的预测结果(图10)。采用较大的窗口,获得的训练样本数据较多,则获得的预测范围相对较小,但综合3种窗口大小来看,预测区的总体位置相似。比较3种不同窗口大小,可以看出当窗口大小为48×48时,预测区的范围相对较小,此时产生的训练样本数较多,模型所得的预测区精度较高。
4.1.3 卷积核数量
卷积层中的卷积核数量直接影响了输入的局部特征,不同的卷积核导致的结果也有着一定的差异性。本文试验了第一层卷积核数量(24、48、64)对预测范围的影响,具体预测结果如图11所示。
实验结果表明,卷积核数量不同会产生不同的预测结果(图11)。卷积核数量越多,提取到的局部特征就越多,3种不同数量的卷积核对应着不同的实验结果,但综合3种数量来看,预测区的总体位置相似。比较3种不同卷积核的数量,可以看出当初始的卷积核数量为48时,预测区的范围相对较小,且更符合地质情况。
4.1.4 步长
卷积层中的步长表示卷积核一次移动多少个格子。不同的步长会导致不同的预测结果,本文对比了3种不同的步长结果,具体如图12所示。
对比3种步长所得的预测结果,可以发现,随着步长的增大,所得的预测结果精细程度愈加降低。对比地质图、地球化学元素异常图和航磁异常图可知,当步长为1时更具有可信度。
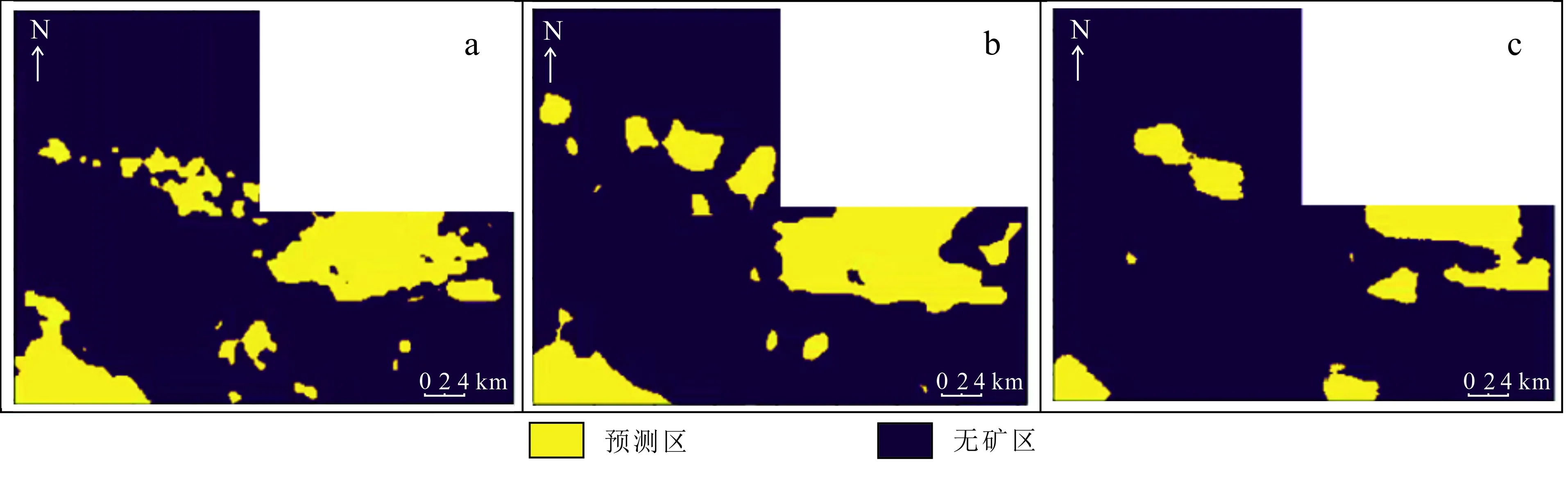
a. 窗口大小为12×12;b. 窗口大小为24×24;c. 窗口大小为48×48。
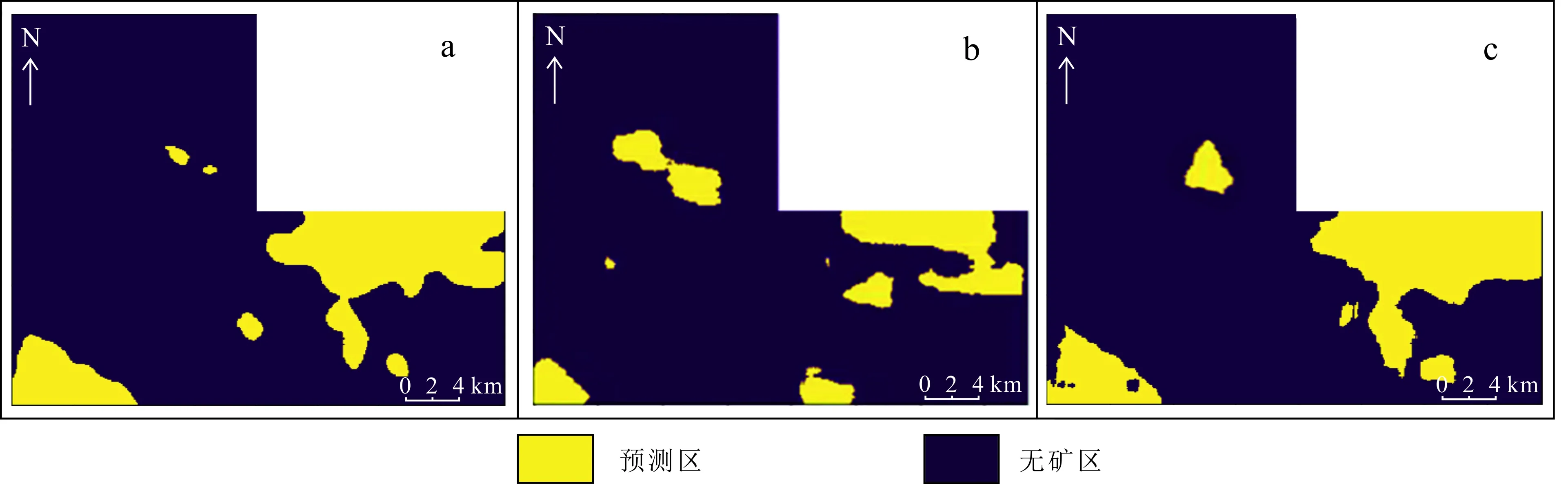
a. 卷积核数量为24×24;b. 卷积核数量为48×48;c. 卷积核数量为64×64。
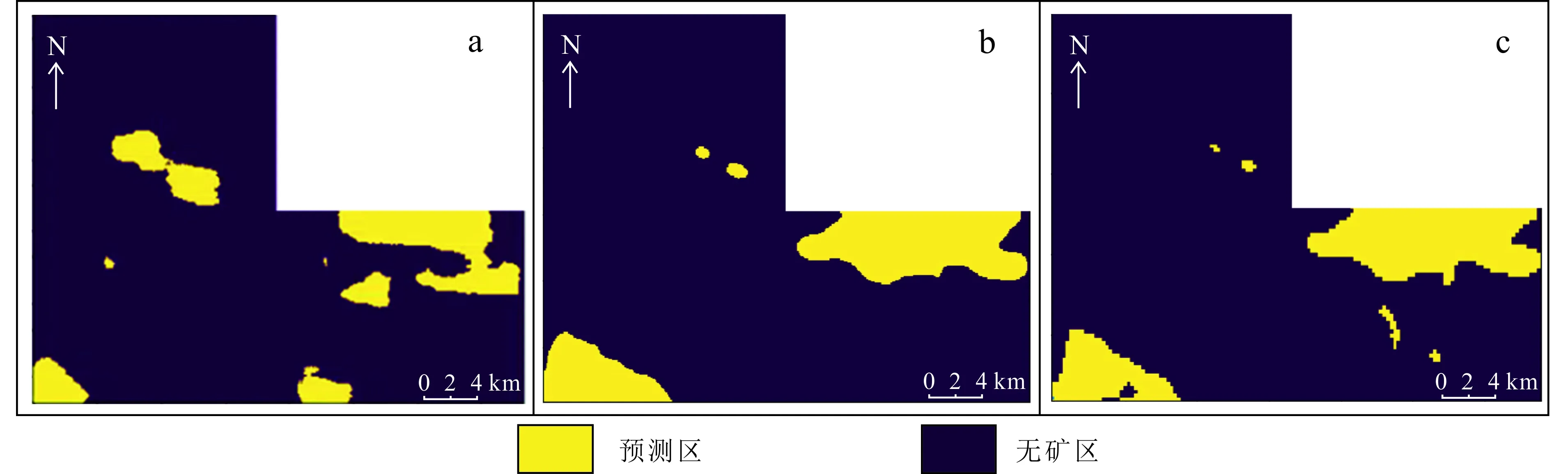
a. 步长为1;b. 步长为2;c. 步长为3。
4.1.5 抓取的样本数量
Batch_size即一次训练所抓取的数据样本数量。适当的Batch_size可以使得梯度方差减小,直接使梯度更加准确,从而使得预测结果更加准确。本文对比3种不同的Batch_size,所得的预测结果如图13所示。

a. Batch_size为32;b. Batch_size为64;c. Batch_size为128。
对比3种不同Batch_size所得的预测结果发现,每一次训练所抓取的数据样本量不同的话,所得的预测结果虽然大体位置相同,但预测面积变化较大。对比元素地球化学异常图、航磁异常图和地质图,发现当Batch_size为64时,所得的预测结果比较可靠。
4.2 不同数据集对预测结果的影响
为了比较不同数据集对预测结果的影响,选取25种化探元素数据、3种航磁数据(化极磁异常,上延50 m和100 m磁异常)、综合25种化探元素数据与3种航磁数据作为输入数据进行了实验(图14)。
实验结果表明,基于化探元素数据的预测结果(图14a)和基于航磁数据所得的预测结果(图14b)有一定的差距,二者所得的预测结果大体位置相同;但综合化探元素数据与航磁数据的预测结果范围相较前两者包含的信息更多,预测范围更加可靠。
4.3 不同网格单元大小对预测结果的影响
为了比较不同网格单元大小对预测结果的影响,设定窗口大小为48×48,卷积核的大小为3×3,第一层卷积核数量为48,步长设置为1,Batch_size为64,输入的数据为压缩24维的化探元素数据和航磁数据,对比50 m网格的输入数据和100 m网格的输入数据,预测结果如图15所示。
实验结果表明,50 m网格和100 m网格得到的预测区域相比,预测区位置大体相同,主要是预测范围有差距,50 m网格得到的预测范围较大。综合该区域地质情况来看,100 m网格预测结果更加可靠。
4.4 预测结果的可靠性与精度
本文采用的是利用PCA压缩得到的24维化探元素数据和航磁数据作为输入数据集,将窗口大小设定为48×48,卷积核的大小为3×3,第一层卷积核数量为48,步长设置为1,采用100 m网格大小得到研究区的预测结果图。前人[25]通过大量野外地质调查、物探和化探分析以及综合研究圈定了研究区铜矿找矿预测区,预测区主要位于山头窑—窑泉、大青山2个地区。本文得到的预测结果图与前人预测结果相比较,所提出的方法(比较)具有较小的预测范围和较高的可靠性。

a. 基于化探元素数据;b. 基于航磁数据;c. 综合化探元素数据与航磁数据。

a. 50 m网格大小;b. 100 m网格大小。
5 结论
1)在融合化探元素和航磁数据基础上,基于深度学习的找矿预测方法可以提高找矿预测的效率和效果。采用本文所提出的方法,可以得到较小的矿产预测范围和较高的预测可靠性。
2)结合前人研究成果和野外检查,基于卷积神经网络在甘肃省龙首山西段高台县臭泥墩—西小口子地区圈定5处找矿预测区,具有良好的铜矿找矿远景,是下一步找矿预测的重点地区。
