基于改进YOLOv3 算法的布匹瑕疵检测研究
2022-06-23苏茂锦
苏茂锦,曹 民
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引言
纺织业作为中国传统经济的支柱产业,其发展备受国家重视。目前,国内纺织业的总产量在国际上处于领先地位,但纺织企业在维持高产量的同时也不可避免会生产很多带瑕疵的布匹,这些瑕疵布匹会让企业利润蒙受大量损失。因此纺织厂会要求员工检查布匹中存在的各种复杂瑕疵,但是人工检查布匹的速度一般为10~20 m/min,效率低下,同时人工成本较大,且人工检测布匹瑕疵检出率约为70%,这在一定程度上也会限制布匹的生产。因此,高效率、低成本的自动化布匹瑕疵检测已经成为计算机、智能化等领域的研究热点。
传统的机器视觉布匹瑕疵检测的方法有频谱分析方法、模型方法等。其中,频谱分析方法比较依赖滤波器组的选择,模型方法计算量较大。这些机器视觉检测方法都需要对图像的特征进行提取,面料不同,图像的提取特征可能也是不同的,常常需要对算法进行重新设计,模型的可迁移性不高,在面对具有复杂背景环境、布匹瑕疵大小差异悬殊、大分辨率的图片时,亟需研发出一种更具一般性、且低训练成本的检测办法。
目前,卷积神经网络(Convolutional Neural Network,CNN)在图像识别领域占据重要地位,不仅对图像中的特征有着强大的提取能力,而且在图像变换不变性的条件下仍然有着很强的分类和泛化能力。因此,CNN 渐渐取代了传统目标检测算法,现已成为目标检测领域的主要方法。
研究可知,基于卷积神经网络的目标检测算法主要分为一步式检测和两步式检测。总地说来,两步式检测预先生成可能包含待检测物体的候选框,然后进行细粒度物体检测。两步式目标检测算法检测精度较高,但很难满足实时需求,代表算法有:RCNN,Fast-RCNN。而一步式检测算法则直接在网络中提取目标特征,并生成预测物体的种类和位置信息。一步式目标检测算法端到端地生成预测信息,在保证精度的同时大幅度地提升了检测速度,代表算法有:YOLO 系列和SSD 系列。尤需指出的是,YOLO 系列里第三代算法(YOLOV3)的提出使得目标检测在工业应用上、包括人脸识别、工业零件计数、工业缺陷检测等等方面都有了很大的进步。
本次研究根据布匹瑕疵大小差异较大、各瑕疵数量不平均导致的训练结果具有偏向性、负样本过多等问题在YOLOv3 的基础上进行改进:在YOLOv3 的FPN 特征金字塔中加入通道注意力机制(SENet 模块),提升网络对重要特征的选择能力。使用深度可分离卷积替代FPN 中的3×3 卷积,降低网络参数量,提升算法检测速度。使用损失函数替换YOLOv3 中的分类损失函数,降低样本类别不平衡产生的影响。
1 YOLOv3 介绍
1.1 YOLOv3 算法原理
YOLOv3将图片划分为个栅格,每个栅格有个边界框(bounding box),如果待检测目标中心落到某个栅格中,则该目标由这个栅格中的边界框进行预测,每个边界框包含3 类信息,分别是:位置信息(,,,)、置信度()以及个类别的概率(),因此最终输出维度为(4+1+)。由预测框的位置信息获取真实框位置信息的计算公式如下:

其中, b,b,b,b为真实框的中心位置以及宽、高信息;p,p为预设锚框的宽、高;c,c为预测框所属栅格左上角的坐标。
置信度信息代表当前边界框是否有对象的概率(Object)以及当边界框有对象时,能够预测的box 与物体真实box 的值。其公式如下:
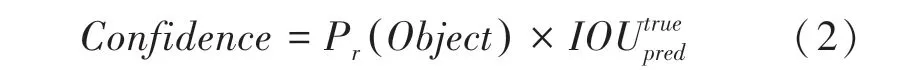
其中,()表示栅格是否包含真实对象:假设栅格包含物体,则取1,否则取0;表示真实框与预测框的交并比,也就是真实框和预测框交集面积与并集面积的比值。
1.2 YOLOv3 网络结构
YOLOv3 的网络结构如图1 所示。结构中采用DarkNet53 作为特征提取主干网络,相对于YOLO2的DarkNet19 引入了残差块,此结构由连续的1×1卷积和3×3 卷积构成,后又通过将残差块的输入与连续卷积后的结果进行跳跃连接得到最终输出。分析可知,该结构特点就是通过加深网络的深度、从而提高网络预测的准确性,同时也缓解了随着网络深度的增加而出现的梯度消失问题。

图1 YOLOv3 结构图Fig.1 YOLOv3 structure
YOLOv3 完成对输入图片的特征提取后会生成3 个特征层,3 个特征层位于主干网络DarkNet53 的不同部分。接下来,利用3 个特征层构建FPN 特征金字塔,将3 个特征层进行特征融合,既利用了深层特征较强的语义信息,又利用了浅层特征的高分辨率信息。
2 基于YOLOv3 的改进算法
2.1 深度可分离卷积
传统的标准卷积在运算过程中会考虑所有的通道数,因此会产生大量参数和计算。假设输入特征图的尺寸为D×D×,卷积核尺寸为D×D×,输出特征图尺寸为D×D×,则标准卷积的参数量为(×D×)×。标准卷积过程示意见图2。

图2 标准卷积过程Fig.2 Standard convolution procedure
深度可分离卷积(Depthwise separable convolution)过程如图3、图4 所示。由图3、图4 可知,这一过程可分为2 步。第一步是深度卷积,用于滤波,尺寸为D×D× 1,共个,参数量为( D×D×1)×,作用在输入的每个通道上,改变特征图的宽、高;第二步是逐点卷积,用于转换通道,尺寸为1×1×,共个,参数量为(1×1×)×,作用在深度卷积的输出特征映射上。两者合起来就是深度可分离卷积。总参数量等于2 个部分之和:


图3 深度卷积Fig.3 Depthwise convolution
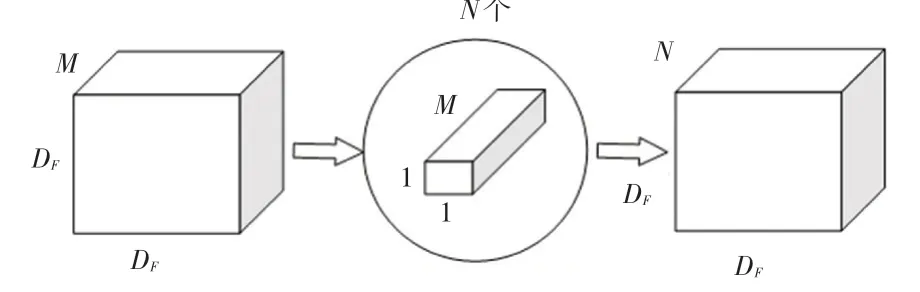
图4 逐点卷积Fig.4 Pointwise convolution
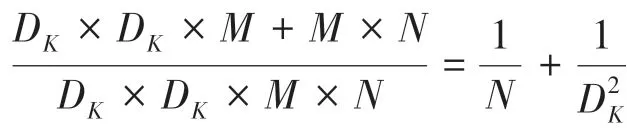
由此可见,使用深度可分离卷积可有效降低网络计算量,提高网络预测速度,本文中将FPN 中的3×3卷积全部替换成深度可分离卷积,降低YOLOv3检测头的参数量,同时也不影响主干网络的迁移训练。
2.2 嵌入SENet
SENet是由胡杰团队于2017 年提出的网络结构,相对于传统卷积只是进行特征的提取,SENet 通过给每个通道进行加权,使每个通道能够获得一个常数权重,从而得到占有更大权重的重要特征。模型可以通过学习的方式自动获取每个特征通道的重要程度,使模型更加关注对当前任务有效的特征、抑制对任务无效的特征。
SENet 的结构如图5 所示。由图5 可知,主要包含2 个过程:以及。对此拟展开分述如下。

图5 SENet 网络结构Fig.5 SENet structure
(1):SENet 将输入的特征图进行一次全局平均池化(global average pool),将一个通道上的整个空间特征编码作为一个全局特征得到一个标量,个通道则会获取到个标量,该过程输出的维度为1× 1×,计算公式如下:

(2):经过操作后网络得到了全局特征,又通过2 层全连接构成微型神经网络模块自学习通道权重(FC-Relu-FC-Sigmoid),得到个0~1 之间的标量作为通道的权重,再将原来输出特征的各个通道进行加权,数学计算公式如下:


其中,×表示全连接过程,表示ReLu 层。
由此得到的结果再与做全连接,得到的输出就是各个通道的权重,最后将权重与输入特征图进行加权就是整个SENet 的输出。
本文通过将SENet 与深度可分离卷积引入到YOLOv3 的特征金字塔,实现对网络的优化,使模型更加关注有效特征、抑制无效特征对输出结果产生的干扰,降低网络参数量以提升算法运行速度。由此文中得到的改进算法的网络结构如图6 所示。

图6 改进后算法结构图Fig.6 Improved algorithm structure diagram
2.3 损失函数改进
YOLOv3 的损失函数主要分为3 类:回归损失、置信度损失以及分类损失,其中分类损失采用的是二分类交叉熵,本文用替代YOLOv3 的分类损失。
是由何凯明团队于2017 年提出的损失函数。函数主要是为了提升一步式目标检测的准确度,研究中认为一步式目标检测算法的准确度往往不如两步式目标检测算法的主要原因就在于样本的类别不平衡。
样本的类别不平衡主要分为2 个方面。一是正、负样本不平衡;二是难、易样本不平衡。实际情况中,易分样本占总体样本比例较高,由此产生的损失函数将主导着总体损失,但是这部分样本本身就能被模型很好地识别出来,如此一来,在整体背景下的损失函数对参数的更新并不会改善模型的预测能力,模型应该关注难分的样本。因此函数的思想是:对于正负样本不均衡,可使用权重来进行平衡,对于难分样本和易分样本,可将易分样本的损失进行一个幂函数降低,具体公式如下:

其中,是平衡因子,主要用于平衡正、负样本之间的数量比例不均;是缩放系数,用于对易分样本产生的损失进行缩放,使模型更关注难分类样本,保证模型不会因为太多易分类而产生偏移。对于布匹瑕疵检测来说,瑕疵与背景区分不明显、难分样本较少,使用会对模型性能提升有很好的效果。
3 实验结果与分析
3.1 实验数据及环境配置
实验数据来源于阿里云天池数据大赛平台,一张图片的分辨率为1000 px×2446 px,且一张图片中可能存在多种缺陷类型,同时缺陷类型大小差异过大、小目标过多,因而具有较大的识别难度。典型样例如图7 所示。

图7 数据集图片样例Fig.7 Samples of data set images
本文选取生产中常见的5 种布匹瑕疵、如三丝、破洞、粗经、结头、整经结来建立布匹瑕疵数据集,图片数量共1544 张,取其中90%作为训练集,10%作为测试集,最后用于训练的图片共有1389 张,测试集为155 张。表1 为各个样本的分布情况。

表1 样本分布情况Tab.1 Samples distribution
实验运行环境:CPU 为Intel(R)Core(TM)i5-10300H,内存为16 GB,GPU 为NVDIA GeForce GTX 1660Ti 6 GB,程序代码使用Windows 环境下的Pytorch 进行实现。
3.2 实验结果与分析
为了验证文中提出的模型性能,将改进算法与YOLOv3 进行性能测试对比,分别计算YOLOv3 与改进网络对目标的召回率()以及准确率()、平均精准度()的结果运算数值。
目标召回率()和检测准确率()可分别由如下公式计算得出:

其中,X表示正确检测出来的目标数;X表示被错误检测出来的目标数; X表示未被检测出来的目标数。
另据研究分析指出,平均精准度是从召回率和准确率两个角度来衡量检测算法的准确性,可以用来评价单个目标的检测效果。
对测试集中的目标进行测试,分别获取YOLOv3 与改进算法的性能指标。
不同算法目标检测结果(、)的对比见表2,不同算法检测结果(、)的对比见表3,不同算法检测效率对比见表4。通过表2、表3、表4 对比后可以发现,改进算法对目标的检测准确率较YOLOv3 提高了37.78%,召回率提高了5.12%,针对粗经、整经结这类难识别、难分类的指标分别提升了12.42%、22.33%,虽然破洞的指标降低了14.51%,但是改进算法的指标提升了4.9%,表明改进算法在全部类别中检测的综合性能更好。在检测效率上,改进算法的指标较YOLOv3 提升了2.14(7%)。

表2 不同算法目标检测结果的对比Tab.2 Comparison of target detection results of different algorithms %

表3 不同算法检测结果的对比Tab.3 Comparison of target detection results of different algorithms %

表4 不同算法检测效率对比Tab.4 Comparison of detection efficiency of different algorithms
改进算法与YOLOv3 检测结果如图8、图9 所示。

图8 YOLOv3 检测结果Fig.8 YOLOv3 detection results

图9 改进算法检测结果Fig.9 Improved algorithm detection results
4 结束语
本文提出了一种针对布匹瑕疵检测的检测方法,首先将YOLOv3 中FPN 里的3×3 卷积替换成深度可分离卷积,提高了模型的检测速度,将SENet 融入到FPN 以及使用了损失函数替代原来的二分类交叉熵函数,有效提升了模型对难检测、难分类瑕疵的检测性能。实验结果表明,该方法具有更好的鲁棒性,相对于YOLOv3 算法,指标提升了4.9%,对于难识别物体的准确率也均获得提升,检测耗时更短,提高了模型的检测性能。
