基于随机森林算法对ERA5太阳辐射产品的订正
2022-06-22王雪洁施国萍周子钦甄洋
王雪洁, 施国萍, 周子钦, 甄洋
(1.南京信息工程大学长望学院,南京 210044; 2.南京信息工程大学地理科学学院,南京 210044)
0 引言
太阳能作为地球最主要的能量来源和基本动力,推动了地表的几乎全部自然地理过程,使地理环境得以形成和有序发展[1]。也是气候形成和演变过程中重要的外参数[2],是陆面过程的主要驱动因子。太阳辐射影响大气圈、水圈、陆地圈层中的物质与能量交换,对太阳辐射研究可以促进对碳循环、水循环等的研究,对全球气候变化也有重要意义。
随着科技的进步,农业、电力和城市建设等行业对太阳辐射的研究提出了新的要求[3-5]。我国太阳辐射观测台站较少,且测站空间分布不均匀。而再分析数据,即经过对太阳辐射观测资料(包括地面观测、卫星,还有雷达、探空等)的质量控制,再同化入全球模式后得到的数据,有着时间序列长、空间分布广的特点,可以极大弥补地面观测数据的不足。但是,再分析数据受资料源、模式等影响,无法完全达到真实模拟大气的程度,具有一定程度的偏差,建立订正模型对于使用再分析数据来说显得极为重要。目前已有相关研究利用地面站点地表辐射数据对再分析辐射数据进行了多尺度的验证。研究表明太阳辐射与云量、气溶胶、水汽等有关[6-7]。再分析资料与我国太阳辐射站点观测资料相比,绝大部分高于台站数据[8-10]。6种再分析地表辐射产品(NCEP-NCAR reanalysis, NCEP-DOE reanalysis, Climate Foreast System Reanalysis (CFSR) ,ECMWF Interim Reanalysis (ERA Interim),Modem-Era Retrospective Analysis for Research and Applications (MERRA) reanalysis,The Japanese 55-year reanalysis),全球月均偏差为11.25~49.80 W/m2,并且发现在中国范围上,云量和气溶胶的低估都可能导致再分析地表辐射的高估,夏秋季节明显好于春冬季节[8-9]。
随着机器学习的发展,越来越多的研究者开始使用机器学习进行不同地区的太阳辐射的预报偏差的订正。大量的研究表明,机器学习模型效果较理论参数模型、经验模型更加准确。陈昱文等[11]利用气象站点的4个观测要素,挖掘观测数据的时序特征并结合气温预报结果训练机器学习模型,对结果进行偏差订正,发现集成学习方法在数值模式预报结果订正中具有较大的应用潜力; 李净等[12]利用ERA5(ECMWF Reanalysis 5)等产品,将人工神经网络、支持向量机和随机森林3种机器学习模拟黄土高原地区的太阳辐射并对3种方法进行比较; Benali等[13]将智能持久性、人工神经网络和随机森林这3种方法进行比较,预测了法国的太阳辐射,二者结果都表明随机森林的模拟精度最高; Yu等[14]利用4种机器学习方法,包括梯度提升回归树、随机森林、多元自适应回归样条和人工神经网络对地面96个站点日、月尺度的太阳辐射进行模拟评估,验证了训练数据集基于随机森林方法的太阳辐射估计值与地面测量值的相关性最好。随机森林的订正方法在海洋环境预报[15]、气温数值预报[16]、空气质量[17]等方面都有应用且精度很高。Babar等[18]利用ERA5和云、反照率、辐射数据集(CLARA-A2)建立随机森林回归模型对挪威地区日平均全球水平辐照度(GHI)进行估计,发现随机森林模型的估计值较原来的预报值更精确,能够更好地估计。但是目前很少有研究对中国范围内的ERA5的高精度太阳辐射数据进行空间订正,没有连续的空间分布订正资料。
本文利用2013年全国93个辐射站的总辐射逐时观测资料对ERA5同期再分析辐射资料进行了评估,并选择相关气象要素及地理要素作为随机森林学习的输入量,对全国93个站点上ERA5辐射量的值进行了订正,进而对ERA5辐射产品进行空间分布上的订正,得到订正后的逐时辐射空间分布图。利用ERA5辐射产品作为输入变量进行随机森林回归,对中国范围内的高空间分辨率格网数据进行逐时数值订正,解决了太阳辐射站点不均的问题,为高精度太阳辐射量空间分布资料的获取提供一种方法。
1 数据源与研究方法
1.1 数据源
①使用欧洲中心天气预报中心(European Centre for Medium-Range Weather Forecasts,ECMWF)发布的第五代再分析数据集ERA5(ECMWF Reanalysis 5)中相关数据进行分析与订正,主要包括太阳下行短波辐射(mean surface downward shot-wave radiation flux,MSDWSWRF)、地表反照率、水汽、总云量、臭氧、高云、低云、中云、冰云、水云产品,时间为2013年,时间分辨率为1 h,空间分辨率为0.25°×0.25°; ②中国93个辐射站点信息(经度、纬度和海拔),以及2013年逐时的太阳总辐射量。
1.2 研究方法
1.2.1 数据评估指标
采用绝对误差(absolute error,AE)、平均绝对误差(mean absolute error,MAE)、均方根误差(root mean squared error,RMSE)和相关系数(R)来分别描述偏离程度、不确定性、准确性和相关性。表达式分别为:
AE=|x-y|
,
(1)
,
(2)
,
(3)
,
(4)
式中:x为估计值;y为观测值;n为样本数;i为样本序号,i=1,2,…,n;Cov(·)为协方差函数;D(·)为方差函数。
本文主要运用MAE,RMSE和R进行逐时资料的再分析资料与实测值、逐时订正值与实测值之间的误差对比分析。AE用于比较ERA5再分析资料的模拟值和随机森林回归值与中国地面站点辐射量的月均实测值之间的差异。
1.2.2 随机森林回归
1)随机森林算法。该算法是基于多棵决策树的一种集成学习算法,且森林中的每一棵决策树之间没有关联,模型的最终输出由森林中的每一棵决策树共同决定。随机森林用于分类时,采用N个决策树分类,将分类结果采用简单投票法得到最终分类,提高分类准确率。选取与太阳辐射有关的因子,即时间、经纬度、地表反照率、海拔、天顶角余弦、总云量、臭氧、水汽、低云、中云、高云、冰云、水云作为输入数据,输出量为每小时辐射值。算法步骤为: ①用有抽样放回的方法(bootstrap)从样本集中选取n个样本作为一个训练集; ②用抽样得到的样本集生成一棵决策树,在每一个决策树节点不重复地选择m个特征,使用基尼指数找到最佳的划分特征; ③重复第二步N次之后生成N棵决策树; ④用训练得到的随机森林对测试样本进行预测,并采用票选法决定预测的结果。
2)特征重要性分析。基尼指数用作对随机森林训练样本特征进行重要性分析,比较每个特征在随机森林中的每棵树所做的贡献。基尼指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。设VIM为变量重要性评分,GI为基尼指数,假设有m个特征X1,X2,…,Xm,则GI的计算公式为:
,
(5)
式中:K为类别数;pmk为节点m中类别k所占的比例。在节点m上,特征Xi在节点m分支前后的基尼指数变化为:
VIMim=GIm-GIg-GIh
,
(6)
式中GIg和GIh为分支后新的基尼指数。特征Xi在第j棵决策树的重要性为特征Xi在决策树j中出现的节点m的基尼指数变化量的和,记为VIMij。若随机森林模型中有N棵树,特征Xi的变量重要性评分VIMi为出现的所有决策树j中的VIMij的总和。最后,把所有求得的重要性评分做一个归一化处理即可。
3)K折交叉验证。该方法用于模型调优,可以减少过拟合的问题。为了进一步检验模型泛化能力,基于独立样本数据,因训练集较大选择5折交叉验证以降低训练成本。步骤为: 将数据分为5组,每次从训练集中,抽取出5份中的一份数据作为验证集,剩余4组作为测试集,重复5次。测试结果采用5组数据的测试误差的平均值作为最后精度评价。原始数据集划分成训练集和测试集以后,其中测试集除了用作调整参数,也用来测量模型的好坏。K折交叉验证对网格搜索(GridSearchCV)是很重要的,用来选择模型的最优参数,本文将全部数据集按照7∶3划分为训练集和测试集进行5折交叉验证。
1.3 随机森林模型
1.3.1 模型参数取值
使用随机森林模型进行学习时,参数对模型准确度意义重大。网格搜索算法(GridSearchCV)是一种通过遍历给定的参数组合来优化模型表现的方法,再利用K折交叉验证,得到最优模型。随机森林算法参数众多,最终优化模型参数取值如表1所示。

表1 模型参数取值
随机森林模型参数优化的一般步骤是: 先保持其他参数为默认值,对待定参数设置范围,然后不断缩小范围,最终确定参数值。子树数量对模型的准确性影响最大,设置过低会导致模型不准确,设置过高会增加模型复杂度,所以首先确定子树数量。设置范围从[50,70]缩小为[50,57],最终确定子树数量为56。其他参数仍然利用网格搜索方法,得到最终模型。
1.3.2 5折交叉验证模型的精度
经过5折交叉验证模型,结果如表2所示,决定系数平均值为0.855,说明建立的随机森林模型的精度较高,模型模拟较优,稳定性良好。
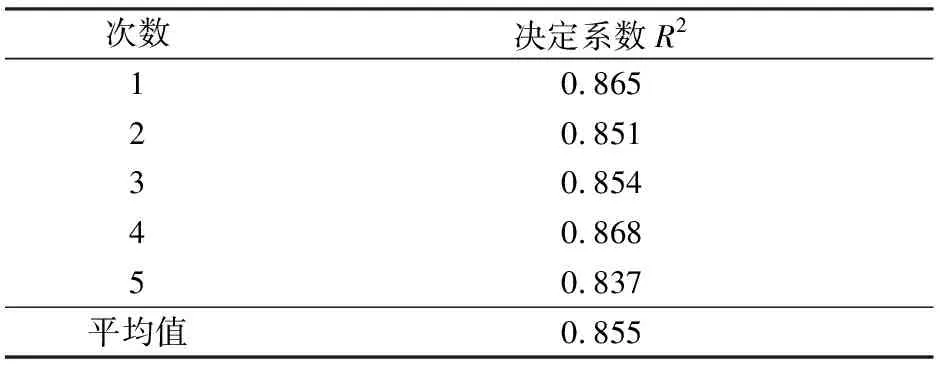
表2 5折交叉验证模型结果
1.3.3 特征重要性分析
特征重要性可以看出每个输入量对模型预报所做的贡献,将时间、经纬度、地表反照率、海拔、天顶角、水汽、总云量、臭氧、高云、低云、中云、冰云、水云作为最终输入量,输出量为每小时辐射量。利用基尼指数作为评价指标来衡量特征重要性。由图1可以看出,天顶角数据重要性最大,为0.325,高云重要性最小,为0.004。说明天顶角对地表太阳辐射量影响较大,高云对地表太阳辐射量影响很小。

图1 特征重要性比较
2 结果与分析
2.1 订正前后的精度分析
图2为1月、4月、7月、10月ECMWF再分析数据与地面站观测数据小时地表辐射的订正前((a)—(d))后((e)—(h))逐时辐射量散点分布对比图。订正前,MAE分别为112.22 W/m2,141.91 W/m2,140.08 W/m2和125.50 W/m2,RMSE分别为155.84 W/m2,201.50 W/m2,196.69 W/m2和175.27 W/m2,R分别为0.74,0.80,0.79,0.77。结果表明不同月份的小时辐射数据误差不同且较大,1月和10月的离散程度小,相关程度也较小,4月和7月的离散程度大,相关程度也较大。订正后,各月份的订正值与站点值的离散程度减小,相关性明显提高,MAE分别为47.99 W/m2,78.77 W/m2,96.44 W/m2和58.38 W/m2,RMSE分别为87.90 W/m2,133.53 W/m2,160.59 W/m2和102.29 W/m2,R分别为0.91,0.91,0.88和0.92; 1月、4月、7月、10月的各误差指标变化幅度不同,MAE分别降低了57.24%,44.49%,31.15%和53.48%,RMSE分别降低了43.60%,33.73%,18.35%和41.64%,R分别提高了0.17,0.11,0.09和0.15,可见4个月中1月的ERA5地表太阳辐射值订正效果最好。

(a) 1月订正前 (b) 4月订正前 (c) 7月订正前 (d) 10月订正前

(e) 1月订正后 (f) 4月订正后 (g) 7月订正后 (h) 10月订正后
2.2 月均辐射值变化
2013年ERA5再分析资料与中国气象站点资料订正前后的月均辐射变化如图3所示。可以看出,订正前ERA5太阳辐射量的值较站点值偏高,总体规律都是夏秋辐射量高、春冬辐射量低。订正后的值接近站点实测值,误差较小。
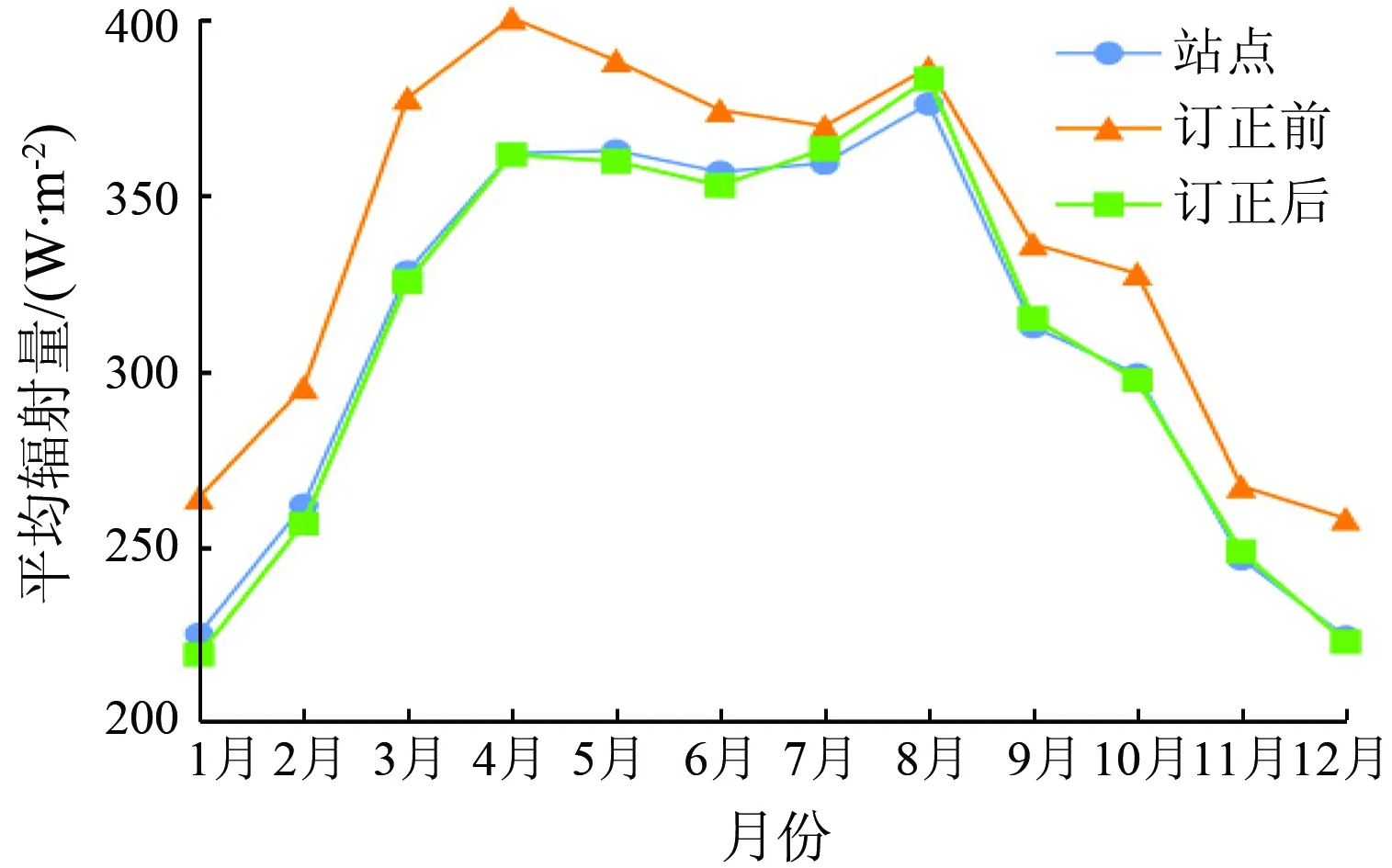
图3 订正前后月辐射均值
误差指标比较如表3所示,订正前的MAE,RMSE和R分别是27.60 W/m2,29.87 W/m2和0.97,订正后三者值分别为3.34 W/m2,3.85 W/m2和1.00。MAE下降了87.90%,RMSE下降了87.11%,R提高了0.03。

表3 3种误差指标比较
2.3 订正前后分月的误差分布规律
图4(a)为ERA5再分析资料与中国地面站点辐射量的月均值绝对误差比较,图4(b)—(d)为对每个月的小时数据求MAE,RMSE和R的分月误差比较。得出的结果是,在订正前,ERA5数据与地面站点的AE在10.28~49.53 W/m2之间,且夏秋季绝对误差小,春冬季绝对误差大;MAE在107.80~142.75 W/m2之间,RMSE在148.85~202.15 W/m2之间,R在0.74~0.80之间; 订正后,AE在-5.91~7.08 W/m2之间,MAE在40.00~98.31 W/m2之间,RMSE在70.98~164.07 W/m2之间,R在0.87~0.94之间。此结果说明: 随机森林模型对ERA5地表太阳辐射量的订正效果较好;MAE和RMSE随着时间的变化也有所规律,明显看出夏秋季2种误差指标较大,春冬季较小。

(a) AE (b) MAE (c) RMSE (d) R
2.4 简单交叉验证
为了进一步验证随机森林模型的稳定性,在中国范围内采用均匀分布的方法选取6个站点(表4),分别为阿克苏、刚察、长春、绵阳、建瓯和北海,将其2013年所有样本数据作为模型的验证数据集,不参与训练,其余站点的样本数据作为训练数据集,进行训练,订正结果的比较如表5所示。从表5中看出,对于本身离散程度大、相关性弱的站点数据,经过随机森林的订正后精度有明显的提高,而本身离散程度小、相关性较高的站点数据,经过随机森林订正后能够保持精度或者有小幅度的提高。说明随机森林的模拟精度高,有较好的稳定性。
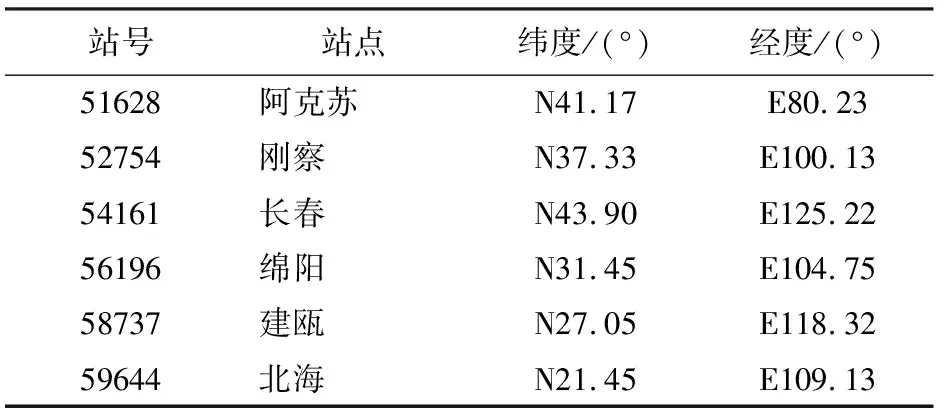
表4 6个站点的信息
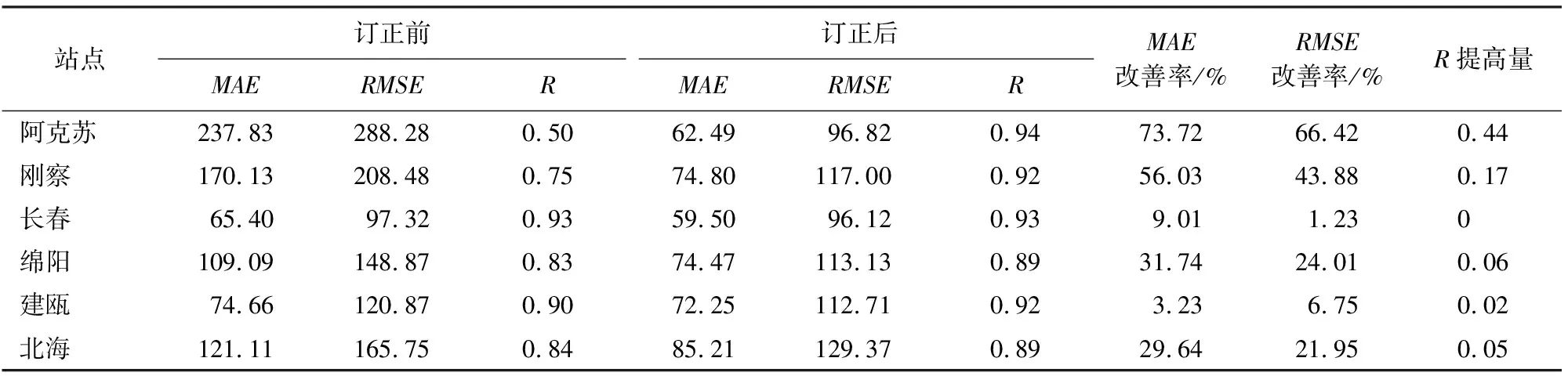
表5 6个站点前后订正的误差指标分析
2.5 订正前后的空间分布变化
图5为利用上述建立的随机森林模型对1月、4月、7月、10月的北京时间15日13时ERA5总辐射进行订正前后的空间分布图。图5(a)—(d)和(e)—(h)分别为订正前后的空间分布结果。由图5可见,太阳辐射量订正前后的宏观分布规律一致,订正后ERA5太阳辐射量在局部地区有明显的下降,对ERA5太阳辐射量偏高的情况有所改进,通过随机森林订正后的分布图局部特征更加明显,精度得到提高。

(a) 1月订正前(b) 4月订正前(c) 7月订正前(d) 10月订正前

图5-1 订正前后太阳辐射的空间分布

(e) 1月订正后(f) 4月订正后(g) 7月订正后(h) 10月订正后
图5-2 订正前后太阳辐射的空间分布
3 结论与讨论
1)本文首先对2013年的再分析资料ERA5和地面观测的太阳总辐射数据进行了对比。从总体上看,两者有较大的差异,ERA5的地表太阳辐射量要高于地面观测数据,这与前人研究一致; ERA5辐射量与站点值的AE夏秋季小,春冬季大; 1月和10月的离散程度小,相关程度也较小,4月和7月的离散程度大,相关程度也较大。订正前,2013年MAE,RMSE和R的值分别是27.60 W/m2,29.87 W/m2和0.97,对小时数据分月比较,ERA5数据与地面站点的AE在10.28~49.53 W/m2之间,且夏秋季AE小,春冬季AE大;MAE在107.80~142.75 W/m2之间,RMSE在148.85~202.15 W/m2之间,R在0.74~0.80之间。
2)利用5折交叉验证和网格搜索选择模型参数,得到模型最优参数和交叉验证的模型得分并评价模型的稳定性,从得分可以验证模型的模拟较优,稳定性较好。将时间、经纬度、地表反照率、海拔、天顶角、水汽、云量、高云等作为输入参数进行随机森林训练。从2013年总体上看,MAE下降了24.26 W/m2,RMSE下降了26.02 W/m2,R提高了0.03,说明随机森林回归模型取得了相对有效的订正结果。对小时数据处理并分月比较,订正后的AE在-5.91~7.08 W/m2之间,MAE在40.00~98.31 W/m2之间,RMSE在70.98~164.07 W/m2之间,R在0.87~0.94之间,订正后的离散程度减小,相关性明显提高。MAE和RMSE随着时间的变化有所规律,明显看出夏秋季2种误差指标较大,春冬季较小。1月、4月、7月、10月的各误差指标增长幅度不同,4个月中1月的ERA5地表太阳辐射量订正效果最好。
3)利用简单交叉验证,进一步验证随机森林模型的稳定性。阿克苏、刚察、长春、绵阳、建瓯、北海站点的太阳辐射量订正后的MAE,RMSE和R均有提高。结果表明对于本身离散程度大、相关性弱的站点数据,经过随机森林的订正后精度有明显的提高,而本身离散程度小、相关性较高的站点数据,经过随机森林订正后能够保持精度或者有小幅度的提高。说明随机森林的模拟精度高,有较好的稳定性。
4)通过随机森林的回归,对ERA5进行了空间分布上的订正,订正前后的宏观规律一致,订正后ERA5太阳辐射量在局部地区有明显的下降,精度得到提高。随机森林模型对ERA5地表太阳辐射量能够进行有效地订正,在实现大样本数据训练时能够保证速度,训练的模型精度较高,实现较为方便快捷,能够更好地进行太阳辐射产品的数据融合,得到的全国范围的连续的太阳辐射数据能够为农业、电力和城市建设等行业研究提供基础数据。
