科技情报中多源信息融合的模式构建
2022-06-21马红岩
马红岩 陈 峰 曾 文
(中国科学技术信息研究所,北京 100038)
0 引言
随着大数据时代的到来,各种类型的信息呈现爆炸似的增长,如何在海量的信息中对不同类型、不同来源的信息进行综合分析变得尤为重要。在科技情报领域,情报检测、热点发现、前沿识别、科技评价、科技查新等都是科技情报工作和科技情报研究的主要任务,而这些任务的完成都需要多种来源的信息[1],即多源信息。对这些多源信息进行综合进而生成有效信息的过程,即为多源信息融合。多源信息融合(又称信息融合、数据融合、多传感器信息融合)起源于20世纪70年代的军事领域,最初目的是美国为解决军事需求,将指挥(Command)、控制(Control)、通信(Communication)和情报(Intelligence)(即C3I)军事系统中的数据进行多源相关性融合,并将其作为国防重点开发项目,此后迅速发展成为一门独立学科[2]。随后广泛应用于各个领域中,而每个领域对其的定义又各不相同。笔者认为,在科技情报领域中,信息融合是指对多源异构的科技数据或科技信息进行整合,以获得更加完整、准确、可靠科技情报的一个过程。在科技情报分析中利用单一信息源提供情报支持显然存在信息不够全面客观、情报具有片面性、对科技决策的支持力度不足的问题。多源信息融合是解决这一问题的主要途径之一。因此,利用多种信息源的融合辅助科技情报的生产是必要的。
鉴于此,本文将在调研科技情报领域中多源信息融合相关研究的基础上,梳理多源信息融合的主要数据类型和特点,分析和总结科技情报研究中多源信息融合的主要数据类型,并结合计算机技术,如机器学习,提出面向科技情报领域主题识别的多源信息融合新模式。
1 多源信息融合的主要数据类型和特点
本文对科技情报研究中多源信息融合的主要数据类型及特点[3-4]进行总结(表1),为进一步提出和构建多源信息融合新模式提供支撑。
2 多源信息融合的分类
国内外学者对多源信息融合展开了大量的研究。在国内,化柏林[5]首先提出在情报分析中要引进融合论,并强调将其作为情报研究工作中的主要方法论,随后他从多源信息类型的角度出发,将多源信息划分为同型异源信息、异质异构信息以及多语种信息,并分析了不同类型多源信息的融合方法[1]。除此之外,化柏林等[6]还系统阐述了大数据环境下多源信息融合的理论基础、融合技术和方法,探讨了大数据背景下多源信息融合的应用。在国外,Avila等[7]融合专利和论文两种数据的直接引用、共被引、文献耦合等3 种关系评估新兴技术的知识建设动态。Wang等[8]提出融合自由贸易区(FTZ)平台共享数据、互联网新闻文本数据和互联网统计数据3 种信息的融合方法。本文按照融合深度不同,将多源信息融合划分为特征及类型融合、关系融合和聚类融合3 种类型,并分别对3 种类型的多源信息融合方法及相关研究进行梳理分析。
2.1 特征及类型融合
2.1.1 特征融合
在特征融合方面,化柏林[1]认为特征融合包括相同特征相同标识、相同特征不同标识、互补型特征、差异型特征等4 种特征类型的融合。张付志等[9]提出了基于度量级融合的论文特征提取方法来提取PDF论文中Title、Author、Abstract、Keywords等4 个字段,并将这些特征集成到统一的框架中。本文认为,特征融合是将多源信息的内部特征(如标题、摘要、关键词等)和外部特征(如作者、时间、被引频次等)融合成统一的形式,包含特征匹配、特征拆分、数据滤重、异构加权等4 个步骤,如图1所示。
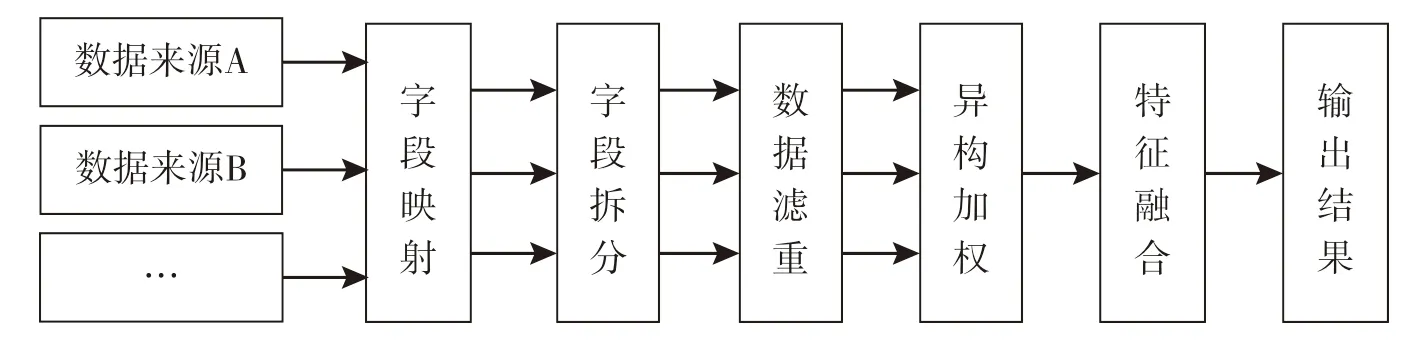
图1 特征融合示意
(1)特征匹配。特征匹配是对相同特征不同标识的数据进行分析与特征映射。同型异源信息其相同特征的表征方式不同,如某一篇论文的标题字段在中国知网(CNKI)被表征为“篇名”,而在万方数据库则被表征为“题名”。对于这种数据首先需要将标识进行统一,如将两种来源的标题字段统一命名为“标题”,然后采用线性融合的方式进行融合。
(2)特征拆分。特征拆分包括多值同特征和多值异特征两种情况。多值同特征,如作者、机构、关键词等特征需要拆分。多值异特征,如德温特数据库中的CP字段既包含引用专利的专利号,又包含引用专利的作者,这样的字段所包含的数据特征是不同的,需要进行拆分。
(3)数据滤重。多种来源的数据相互交叉,重复数据较多,如SCI、EI数据库中收录多种相同的期刊,数据滤重的关键是确定数据的唯一标识,去掉重复数据。如基金项目数据可以使用资助项目号作为唯一标识,期刊论文可以使用DOI作为唯一标识,而对于没有唯一标识的数据,可以采用多种特征相结合的方式作为数据的唯一标识。不同类型的数据其唯一标识不同,需要根据数据的具本情况进行分析。
(4)异构加权。异构加权是对相同特征不同来源的数据采用融合函数进行线性融合,对于融合函数中权重的设置主要有专家打分法和基于统计实证的方法。
2.1.2 类型融合
类型融合是将异质异构信息经过加工处理后融入同一分析目标,涉及特征匹配、特征拆分等处理方法。在数据类型融合方面,Wang等[8]融合自由贸易区(FTZ)平台共享数据、互联网新闻文本数据和互联网统计数据3 种信息,提出融合过程中的关键点是解决多源异构数据之间的不一致性问题,其在文本主题分类和量化过程中采用朴素贝叶斯多标签分类算法,克服多源数据的结构不一致性,采用时差相关分析法解决两个时间序列的时间不一致性。徐璐璐等[10]将收集到的论文、专利以及基金项目数据进行文本格式转换、分词、去除停用词、字符删除及句法分析等预处理后进行词汇语言的合并,对合并后的文本数据进行主题识别。冯佳等[11]不同数据类型中的特征映射到一个统一的框架上,将多种类型数据统一成相同的形式,该框架的目的是以半结构化的方式表征不同数据类型中的情报信息。
2.2 关系融合
关系融合又称多元关系融合,首先获取多种数据的关系包括结构关系(如直接引文、耦合关系、共被引关系、合著关系等)、主题关系(主题词共现)、语义关系等,然后将多种关系融合成一个新的关系以揭示实本之间的关联情况,如图2所示。关系融合的方法主要分为两种:一是将多个距离矩阵进行运算得到关系融合矩阵,二是利用主题模型的方法进行关系融合。
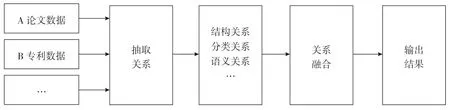
图2 关系融合示意
2.2.1 将多个距离矩阵进行运算得到关系融合矩阵
Amjad等[12]、Calero等[13]、滕立[14]、Bei等[15]根据研究场景的不同选取作者-文献矩阵、文献-期刊矩阵、词共现矩阵、词-文献矩阵、参考文献-文献矩阵、作者共现矩阵、作者-机构共现矩阵、作者-国家共现矩阵和机构-国家共现矩阵等适宜的矩阵进行运算形成融合矩阵,分别应用在领域主题分类、科学出版物间知识创造和流动过程分析、总结领域中知识交流模式等应用场景中。Zhang等[16]融合文本内容的语义关系和IPC分类信息的分类关系进行专利组合的混合相似度计算,并应用到技术相似性的研究中,实证表明基于语义关系和分类关系的相似度计算具有一定的可靠性。Avila等[7]构建论文-专利在多关系(直接引用、共被引、文献耦合)呈现下的单一知识网络,用于评估新兴技术的知识建设动态。谭晓等[17]结合多源数据进行知识融合,将多种实本和多种数据关系进行融合,并将其与主题模型进行关联,形成包括结构关系、语义关系和共现关系3 种关系融合的网络。
2.2.2 利用主题模型的方法进行关系融合
Tang等[18-19]融合作者、期刊、文档3 种信息对LDA主题模型进行改进,提出ACT(Authorconference-topic)模型。Xu等[20-21]和史庆伟等[22]对LDA主题模型进行改进,将主题、作者与时间关联提出作者主题演化模型(Author-Topic over Time,AToT),用于挖掘科技文献中隐含的主题和作者的研究兴趣随时间变化的规律。Du等[23]将专利的作者合作网络和专利-发明人网络融合成一个新的异质网络,并利用该网络对发明人的重要性进行排序。冯佳等[11]从载本-特征-关系3 个层面深入全面的构建多源数据融合模型,其中关系融合从内容相关性和逻辑语义性两个方面采用LDA主题模型来实现多元关系的融合。此外,Xu等[24]从融合方式、融合范围、融合深度以及融合数量等多个角度对关系融合方法进行阐述。
2.3 聚类融合
聚类融合又称聚类集成,是对同一类型数据多次聚类的聚类结果或对多种来源多种类型数据的聚类结果进行融合,其中聚类算法可以采用同一聚类算法或不同聚类算法,融合方法主要是利用融合函数对聚类簇进行融合从而得到最终聚类结果[25]。聚类融合如图3所示。具本描述如下:给定包含N个数据类型的数据集X={x1,x2,…,xN},其中第i种数据集xi={xi1,xi2,…,xiH},i表示第i种数据类型(i=1,2,…,N),H表示第i种数据类型中数据的个数。对数据集X进行N次聚类得到N个聚类结果的聚类成员集β={β1,β2,…,βN},其中第i种数据类型的聚类结果βi={ci1,ci2,…,cik},i=1,2,…,N,k是聚类成员βi的聚类簇的数量。聚类融合的目的是设计一种融合函数θ将所有的聚类成员β1,β2,…,βN融合为一个新的聚类结果βθ。
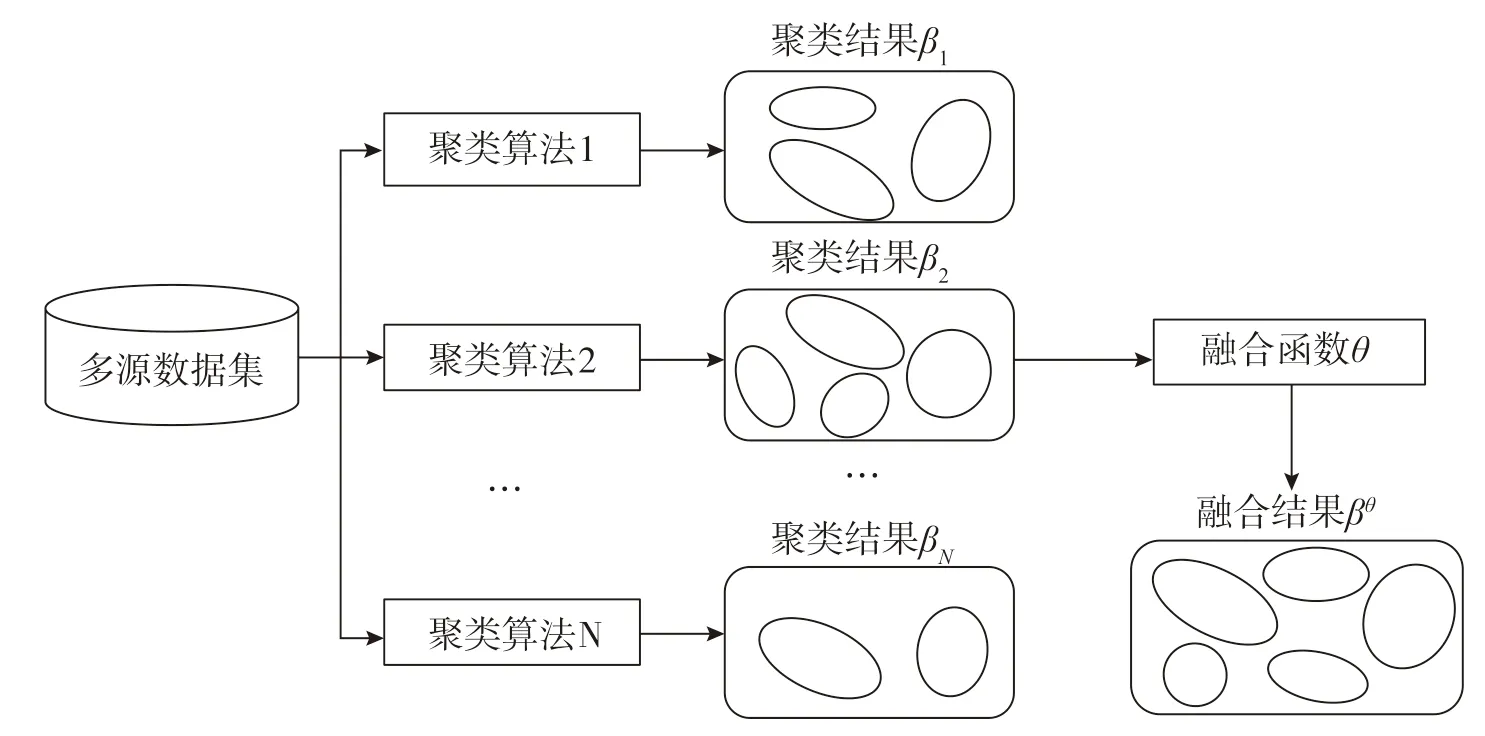
图3 聚类融合示意
聚类融合过程中的重点是融合函数的设计。融合函数又称一致性函数、共识函数,是指通过对聚类成员进行融合,得到一个统一的聚类结果,是聚类融合过程中的一个重要步骤,融合结果的好坏取决于融合函数的确定。常用的融合函数及代表性研究参见表2。
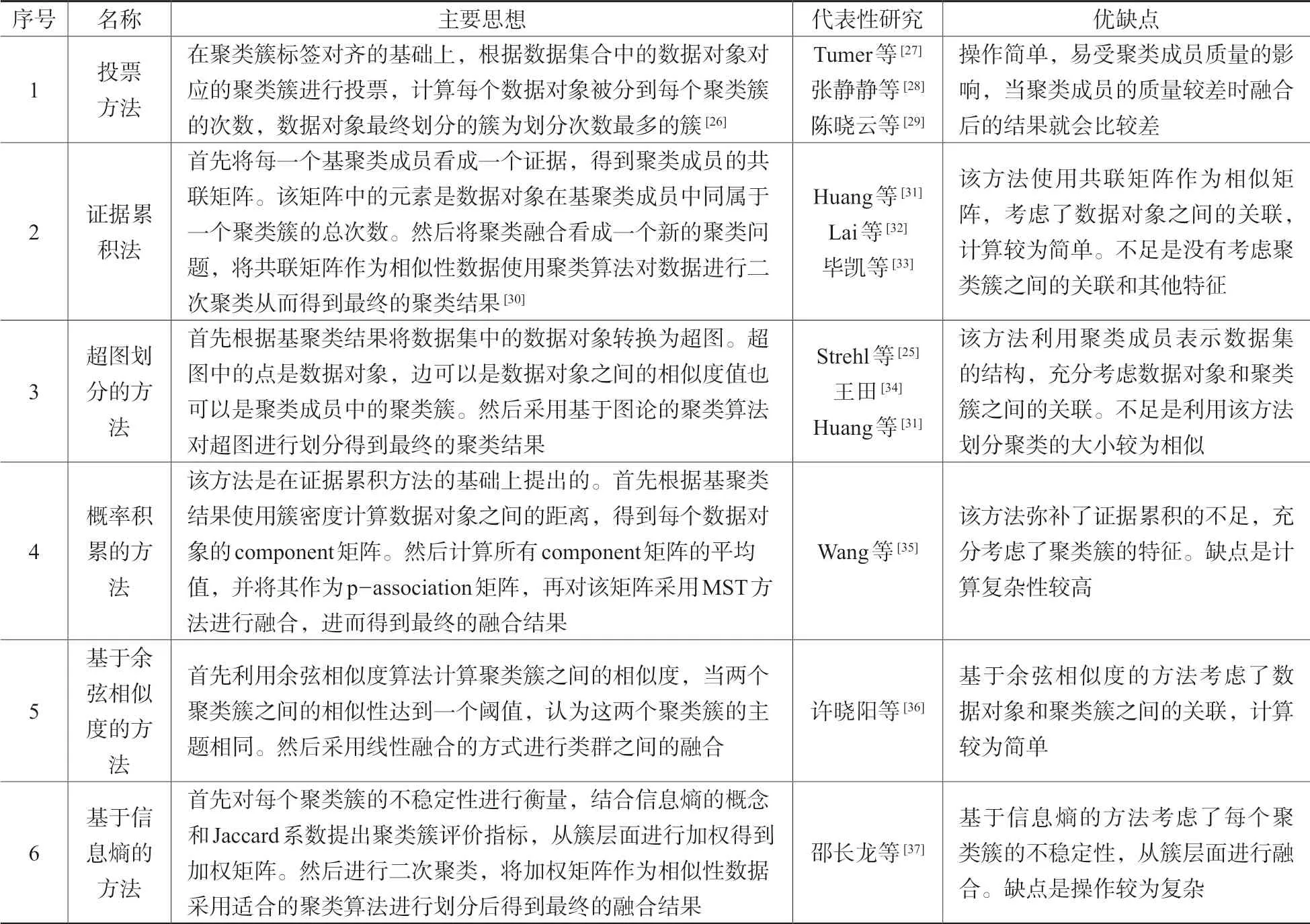
表2 常用的融合函数及代表性研究
3 多源信息融合的新模式
科技情报研究中不同数据类型具有不同的特点,数据类型的选取与研究问题相关。本文针对现有研究方法的局限性,以面向科技情报领域的主题识别问题为例,选取论文(期刊论文和会议论文)、专利、基金项目等3 种类型的科技数据,从特征及类型融合、关系融合、聚类融合3 个层面提出并构建了多源信息融合新模式,如图4所示。
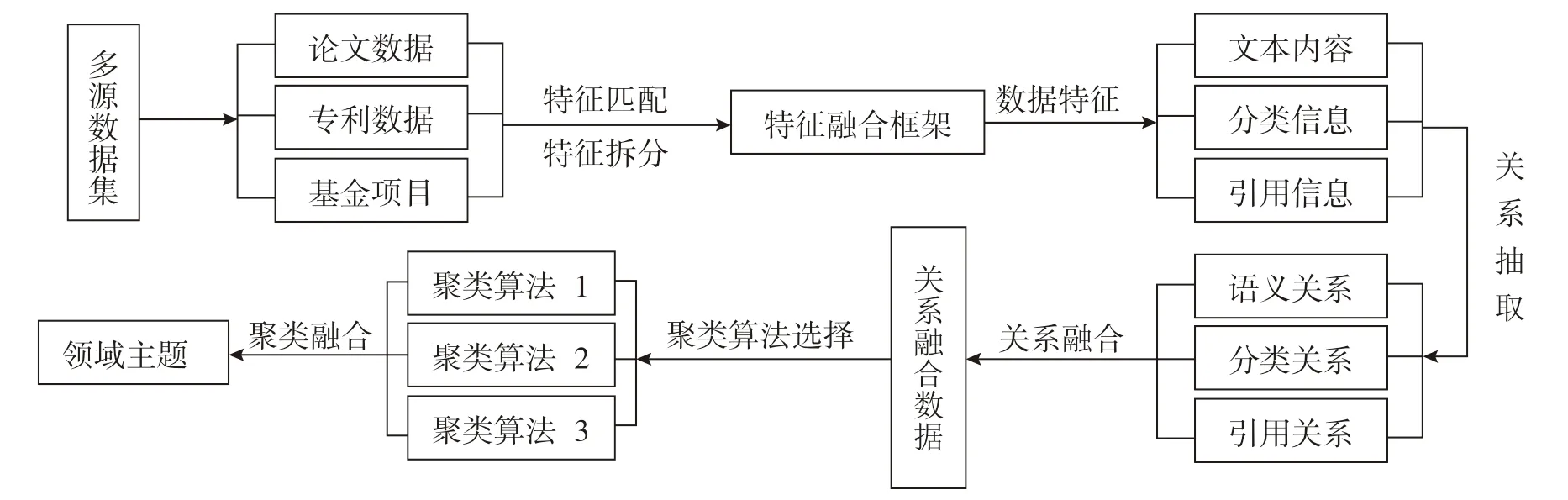
图4 多源信息融合模式
以下是信息融合模式的基本思路及采用的方法。
第一层:特征及类型融合。选择一个发展相对成熟,边界相对清晰的领域作为分析对象,收集该领域多种来源的会议论文、期刊论文、专利、基金项目数据,经过特征匹配、特征拆分等处理后融合到一个统一的框架上。该框架包含内部特征和外部特征两个部分,如图5所示。
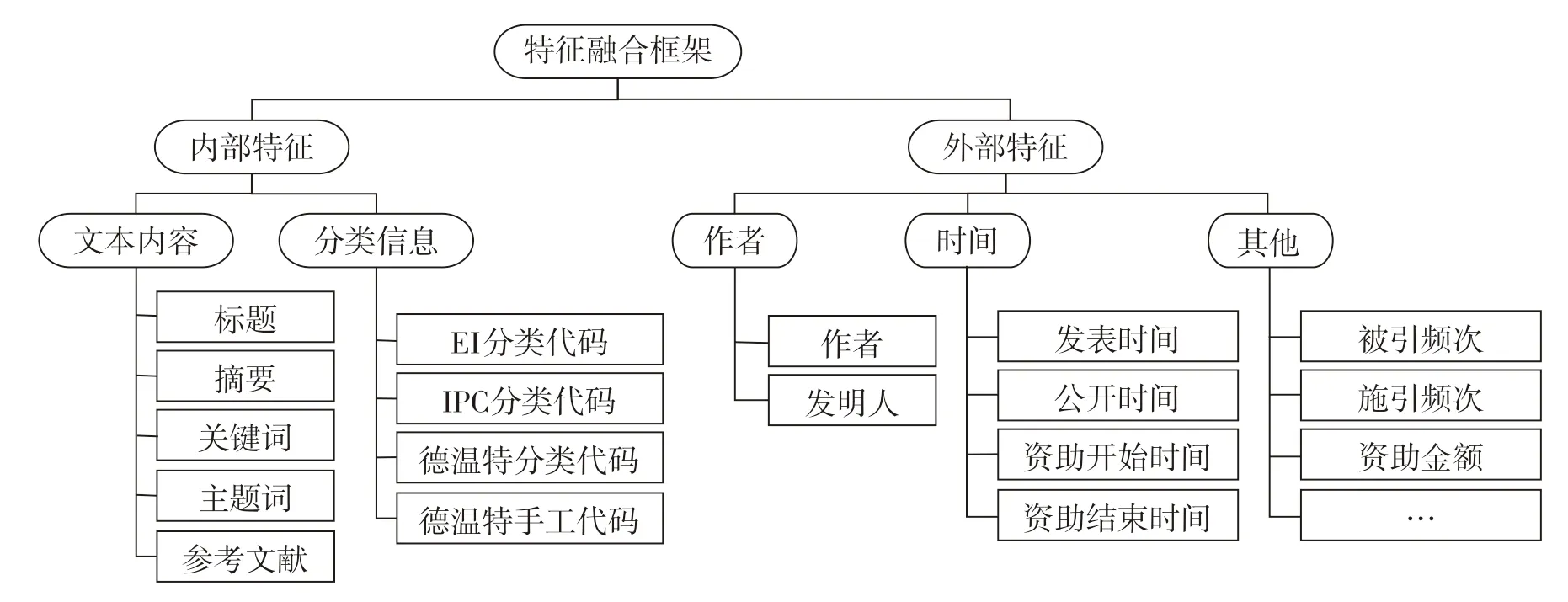
图5 特征融合框架
第二层:关系融合。根据应用场景的不同获取不同的关系,科技领域主题识别的多源信息融合模式主要融合基于文本内容的语义关系、基于分类信息的分类关系、基于参考文献的引用关系,形成基于多关系融合的文本相似度矩阵,用于后续的文本聚类。
步骤1:构建文本向量获取语义关系。首先抽取文献的标题和摘要,对其进行分词、去标点符号、去停用词等处理;然后选择如Doc2vec模型、Word2vec模型、词袋模型等文本向量化技术构建文本向量。
步骤2:构建分类向量获取分类关系。首先获取文献的分类信息,如EI数据库下载的论文包含EI分类号字段,Web of Science数据资源中下载的论文包含研究方向字段,论文的分类信息可以从EI分类号、研究方向等字段获取;专利数据的分类信息可从IPC分类号字段中获取;基金项目数据目前没有分类信息。然后通过获取的分类信息构建分类向量,向量的元素值是该文献与其他文献的共同分类强度,即两篇文献共同的分类号数量与二者分类号并集中元素数量的比值。两篇文献共同分类号的数量越多,表明这两篇文献的研究主题越相似。分类向量元素值计算公式为:

其中,i,j分别表示第i篇和第j篇文献,Aij表示第i篇文献第j个元素值,Bij表示第i篇文献和第j篇文献共有分类号的数量,Cij表示第i篇文献和第j篇文献分类号并集中的数量。
步骤3:构建引用向量获取引用关系。根据文献的参考文献构建引用向量,向量的元素值是该文献与其他文献的共同引文强度值,即两件文献共同的参考文献数量与二者参考文献并集中文献数量的比值。两篇文献共同参考文献的数量越多,表明这两篇文献的研究主题越相似。引用向量元素值的计算公式与分类向量元素值的计算公式相同。
步骤4:关系融合即向量融合。将构建好的文本向量、分类向量和引用向量通过首尾相连的方式进行融合获得文献的多关系向量。假如给定某一篇文献的文本向量为[a1,a2,a3,…,an],分类向量为[b1,b2,b3,…,bn],引用向量为[c1,c2,c3,…,cn],则融合后的多关系融合向量为[a1,a2,a3,…,an,b1,b2,b3,…,bn,c1,c2,c3,…,cn]。
第三层:聚类融合。首先计算第二步构建的多关系向量在空间上的距离和相似度,形成文本相似度矩阵,然后选择适合的如K-means、DIANA、OPTICS等聚类算法分别对论文、专利、基金项目进行聚类。聚类算法既可以选择相同的算法,也可以选择不同的算法。文本聚类后需要选择合适的聚类融合方法如余弦相似度、投票法等对3 种类型数据形成的聚类簇进行聚类融合。
4 结语
多源信息融合在情报领域已得到一定的应用,相关研究多集中在数据类型融合和关系融合上。数据特征及类型融合主要侧重于信息融合过程中的多源异构信息的标准化,是多源信息融合的基础性工作。关系融合是多源信息融合的关键,在不同的应用场景中,各种关系类型的重要程度不同,承担的作用也不同。因此,面对不同的应用场景,如何选择合适的关系类型并进行融合是研究的重点内容之一。目前,在科技情报研究领域,对关系融合的研究较为丰富,在已有的关系融合方法中,简单的线性融合方法居多。从检索文献来看,在科技情报分析中,仅有文献[36]利用了聚类融合方法。对相关文献的梳理发现,目前科技情报研究中的多源信息融合深度不够,缺少统一的融合框架。本文认为,在科技情报研究中,利用多源数据进行情报分析是科技情报领域研究的关键问题之一。不同类型数据所包含的科技信息的侧重点各不相同。在科技情报研究中只有根据不同的研究目的而选取多种类型的数据进行信息融合,才能使科技情报分析的结果更加科学和客观。此外,随着计算机技术、机器学习等相关技术的不断发展,科技情报领域的多源信息融合方法和技术不再局限于数据类型本身的融合,更多强调的是融合的深度以及融合的模式。本文在梳理多源信息融合相关研究的基础上,总结现有研究方法的不足,以科技领域主题识别问题为例,从特征融合、关系融合、聚类融合3 个层面提出并构建新的多源信息融合模式。该模式的提出为全面、深入地识别领域主题提供了借鉴与支持。
