档案管理中文本数据的增量多模态聚类方法
2022-06-21刘丽华
刘丽华
(内蒙古财经大学 档案馆,呼和浩特 010010)
海量档案文本数据急剧增长,也伴随着文本数据描述的多样化[1]。例如,一则新闻消息可以通过不同的语言进行表达和传播;一个文本可以利用不同的特征描述(Word2Vec、TF-IDF等)进行分析。这样的数据称为多模态数据,不同领域或不同描述形式可以代表一种模态。通常,不同模态之间可以为语义相同的数据对象相互补充信息,结合多个模态的数据信息对一个物体进行描述相比于单模态可以更加全面地了解该物体的特征并且精准对该物体进行辨别。另外,随着档案文本不断增长,给档案管理带来了一定困难,有效对档案数据进行聚类、划分,能够按主题对档案文本进行分类管理,便于后期查阅、处理。
近年来多模态文本数据聚类或分类算法的研究备受关注[2]。例如,Amini等[3]将不同语言的文档看作是原始文档的不同模态,成功设计了多视图多数投票和多视图共分类[4]等方法对文档进行学习;Bickel等[5]研究了众多多模态数据形式下的聚类方法,例如k-means、k-medoids和EM(expectation-maximization)等。挖掘不同模态结合过程中潜在的数据信息是研究者们共同的目标,由此可见,研究多模态数据融合的有效方法已成为文本大数据分析中的重要方向。文中针对海量档案文本数据的多模态特点,研究有效的增量多模态文本聚类方法。
非负矩阵分解[6](NMF, nonnegative matrix factorization)是一种经典的矩阵分解技术,它可以将每个观测对象解释为非负基向量的线性组合相加后得到的结果[7],这恰好符合了人们在大脑和心理上所习惯的“局部构成整体”的思想[8-9]。近几年内,NMF已经被广泛运用于数据聚类中,它与许多先进的无监督聚类算法相比,其性能极具竞争力[10]。例如,Xu等[11]将NMF应用于文本聚类,取得了较好的结果;Brunet等[12]在生物数据聚类方面也获得了类似的成功。这些基于NMF的单模态聚类算法都取得了不错的成果。如果将NMF技术应用于多模态档案文本数据将取得令人期待的结果。NMF本身具有属性降维的功能,可以很好地解决多模态档案文本大数据存在的维数灾难问题。然而,基于NMF的多模态文本数据聚类方法也将面临以下问题:多模态文本数据存在异构性,如何充分结合多个模态的数据信息是首要的挑战;当多模态的文本数据出现爆炸式增长的时候,传统的学习方法需要损耗大量的空间和时间成本。
针对以上问题,文中将研究基于NMF的增量多模态文本聚类方法。与传统的非负矩阵分解方法使用得到的系数矩阵进行数据分析不同,文中提出的方法将直接用融合后的共享特征矩阵进行聚类分析,检测融合数据的效果。该方法是基于语义的,在考虑每种模态的实际意义的情况下求得所有模态的共享特征,并且在多模态数据语义融合的基础上引入图规则化的思想,保证各模态数据与共享特征的几何结构相似性,力求能够获得更好的特征学习与聚类分析效果。然而,当大规模档案文本数据遇到实时性的需求时,传统的多模态数据融合算法无法满足在短时间对大量数据进行处理的任务,因此实现2种增量自适应文本数据特征学习方案,并求解对应的增量优化规则,可以节约数据处理的时间成本,同时学习的增量方法在一定程度上也更加节省数据占据的存储空间。2个实际文本数据集上的实验结果表明:文中提出方法优于现有的一些增量和非增量学习方法,能够对多模态文本数据进行有效划分。
1 相关技术
1.1 非负矩阵分解
给定一个M×N大小的非负矩阵X(矩阵中的元素均为负),每个列向量代表一个数据实例,数据实例大小为N,每个行向量代表一种特征属性,共有M维特征属性。这个矩阵被近似分解为一个M×d的基矩阵U和一个N×d的编码矩阵V,其原理如图1所示[6]。
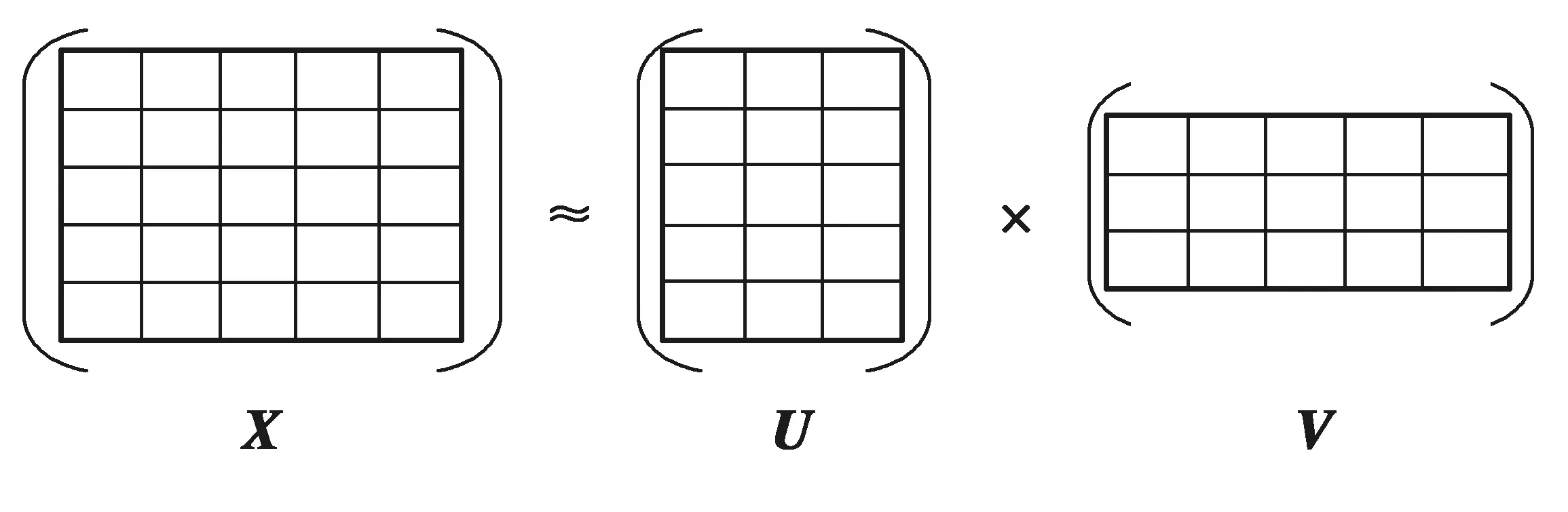
图1 非负矩阵分解原理原理Fig.1 The principle of non-negative matrix factorization
通常,设定d的数值远远小于N,假设d为数据聚类的类数。非负矩阵分解可以形式化表示为
X≈UVT(U≥0,V≥0 )。
(1)
为了求得矩阵X的近似表示,可以将目标函数最小化:
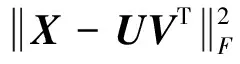
(2)

(3)
(4)
按照式(3)和式(4)依次对U、V进行交替迭代直到函数收敛,求得最后的U、V矩阵。
非负矩阵分解将一个原始矩阵分解成一个基矩阵和一个编码矩阵相乘的形式,要求得到的基矩阵和编码矩阵非负,因此原矩阵中的某一行数据可以看作编码矩阵中所有列向量的加权和,具体的系数对应编码矩阵中列向量的元素。该分解过程可以理解为一种特征提取的行为,编码矩阵则为原始矩阵的潜在特征表示。
1.2 多模态非负矩阵分解

(5)
通过共享矩阵V的耦合,联合迭代更新各变量,得到优化后的多模态共享特征。
2 增量多模态文本聚类方法
文中提出的增量多模态算法考虑每个模态的语义信息,使用NMF抽取出多模态数据的共享特征子空间。为提升其学习特征的有效性,算法还嵌入图拉普拉斯正则化项,保证高维数据在降维过程中尽量维持其原始的数据结构,进一步提升共享特征学习的准确性。最后,为每个模态设立模态权值,通过权值的自适应更新,合理控制每个模态对于特征子空间的贡献。在实际应用中,数据往往是分批到来的,这导致了非增量算法时间开销巨大。因此,在上述基础算法的基础上,进行算法的2种增量改进来大幅度减少时间消耗。第一种增量改进算法基于数据相对独立这一假设[13]:当新数据到来时,它仅通过计算新数据的特征子空间从而减少时间开销。第二种增量改进算法结合了缓冲区的思想[14],为数据开创时间缓冲区,通过缓冲区来减少时间开销。
2.1 基于图规则化的多模态NMF
拉普拉斯特征映射是一种基于图的降维方法,它可以使图中原本相近的2个点在降维后依然尽量地靠近。因此,拉普拉斯矩阵使数据中具有相似性的实例在降维后的空间内依旧保持高度相似,以达到后续更好的特征学习效果[15]。
根据数据间的欧氏距离,采用p-最近邻算法构造出一个邻接矩阵W,Wij表示数据实例i和数据实例j的相似度,要求在降维后的子空间内原本靠近的数据仍旧相近,即在共享特征子空间V中,原始空间相近的行向量vi与行向量vj(Wij较大)的距离要尽可能的小。故得到目标函数:
Tr(VDVT)-Tr(VWVT) =Tr(VLVT),
(6)
式中:L是图的拉普拉斯矩阵,L=D-W;W是邻接矩阵;D是度矩阵,它是一个对角矩阵,其每一行的对角元素是W矩阵中对应每一行或列之和。
根据上述方法计算得到每一个模态数据的拉普拉斯矩阵L(v)后,便可得到基于图规则化的多模态NMF的目标函数:
s.t.V≥0,U(v)≥0,v=1,2,3,…,nv。
(7)
式中,λ为图正则化项的控制参数。
2.2 增量自适应图规则化多模态NMF
基于2.1节的图规则化的多模态NMF,文中提出增量自适应图非负矩阵分解模型(IAGNMF, incremental adaptive graph regularized multi-modal NMF)。模型中假设新数据与原有数据是相对独立的,因此对于新到来的数据,在保持原有数据共享特征子空间不变的基础上为新数据开辟新的特征子空间。对于图的增量计算则是对每个模态新数据在全局数据集合空间上的分布特点进行拟合,保证新数据对应特征子空间分布与各个模态所有数据分布相似。最后为每个模态设立一个模态权值,通过权值自适应更新来控制各模态对于新数据特征子空间学习的贡献,具体细节如下:

(8)

(9)
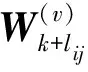
(10)
最后,在式(10)的基础上为模态添加自适应权重因子(α(v))γ,其中,α(v)为第v个模态的权重因子,γ为控制权重分散程度的参数。自动更新自身模态权重,约束不同模态对特征子空间的影响。这样得到了目标函数:
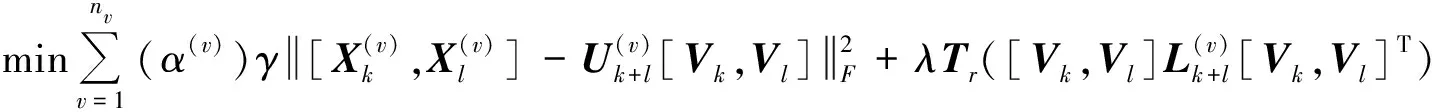
(11)
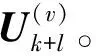
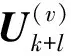
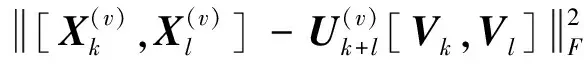
(12)
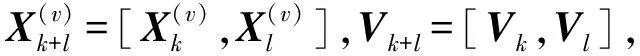
(13)
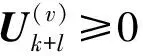
(14)
(15)

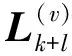
(16)
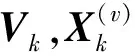
(17)
利用拉格朗日优化函数对式(17)进行优化表示得到:
(18)
其中:∅为限定条件Vl≥0的拉格朗日乘子,用式(18)对Vl求偏导得到:
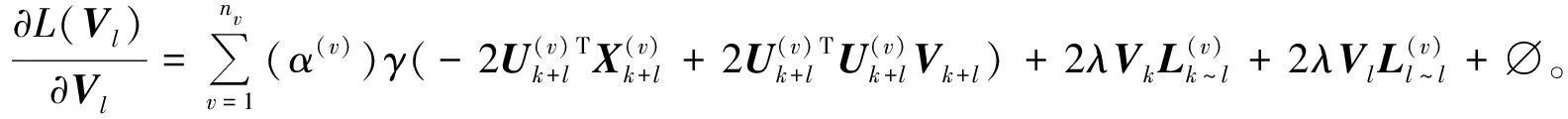
(19)
通过KKT(Karush-Kuhn-Tucher)条件(∅)ij(Vl)ij=0,得到Vl的更新规则为:
(20)
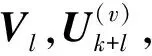
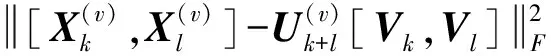
(21)
利用拉格朗日优化公式对式(21)进行优化表示得到
(22)
利用式(22)对α(v)求导,使导数为0,得到:
(23)
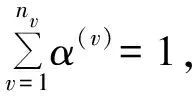
(24)
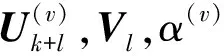
2.3 在线自适应图规则化多模态NMF
与IAGNMF不同,在线自适应图非负矩阵分解(OAGNMF, online adaptive graph regularized multi-modal NMF)假设新数据总是与它到达时间相近的数据关联性更强,而与到达时间较远的数据关联更弱。因此,模型中设立一个固定大小的缓冲区,总是存放s个最近到来的数据,将其他较早到来的数据丢弃。运用缓存区的数据进行特征子空间学习。
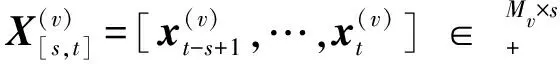
因此,在构造图正则化项时,仅需要计算缓冲区实例的p-最近邻图即可。顶点对应缓存区的实例,同样采用余弦距离来衡量文本实例的相似度:
(25)
(26)

类似的,目标函数(26)是非凸的,采取同样的策略寻找局部最优解:
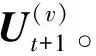
(27)
(28)
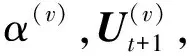
同理,对目标函数(26)进行拉格朗日优化表示后对Vs求导,通过KKT条件使导数为0得到Vl的更新规则:
(29)

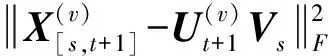
(30)
2.4 复杂度分析

设多模态数据平均模态维度为M,算法IAGNMF的空间复杂度为O(V(Mk+Ml+MMc+3(k+l)2+1)+Mc(k+l)+2)(V(Mk+Ml+MMc+3(k+l)2+1)+Mc(k+l)+2)≈O((k+l)2)。假设迭代更新平均收敛次数是tt,多模态数据平均模态维度为M,算法IAGNMF一次增量过程的时间复杂度为O(Vt(2MMc(k+l)+Ml(k+l))+VMvl(k+l))≈O(k)O(Vt(2MMc(k+l)+Ml(k+l))+VMvl(k+l))O(Vt(2MMc(k+l)+Ml(k+l))+VMvl(k+l))。
设多模态数据平均模态维度为M,算法OAGNMF的空间复杂度为O(V(Ms+MMc+3s2+1)+Mcs+2)≈O(1)O(V(Ms+MMc+3s2+1)+Mcs+2)O(V(Ms+MMc+3s2+1)+Mcs+2)。假设迭代更新平均收敛次数是tt,多模态数据平均模态维度为M,那么算法OAGNMF一次增量过程的时间复杂度为O(Vt(2MMcs+Ms2)+VMvs2)≈O(1)O(Vt(2MMcs+Ms2)+VMvs2)O(Vt(2MMcs+Ms2)+VMvs2)。
3 实验分析
为验证文中提出算法的有效性,设计了一系列算法对比实验,并在多模态文本数据集LegalText和Webkb上验证算法IAGNMF和OAGNMF和现有的一些相关算法:ConcatNMF(concatenation NMF)[6],INMF (incremental NMF)[13],MultiINMF (multi-view Incremental NMF)[10]和MultiGNMF(multi-view graph NMF)[15]的性能。一是比较共享特征学习效果,将算法提取出来的低维特征进行k-means聚类分析,分析聚类的准确度(ACC, accuracy)和纯度(PUR, purity)。二是比较运行算法的时间开销。
3.1 数据集
3.1.1 数据集LegalText
LegalText数据集是具有7个大类6 300个法律案例的文本数据,分别是渎职,妨害社会管理秩序,破坏社会主义市场经济秩序,侵犯财产,侵犯公民人身权利、民主权利,贪污受贿,危害公共安全。通过预处理得到150维word2vec特征和500维tfidf特征2个模态。
3.1.2 数据集Webkb
Webkb数据集[16]源自于康奈尔大学计算机科学系的网页文本内容,该数据集包含属于4个类别的8 282个数据样例,共有2 500维网页中的文本特征属性和1 380维网页中超链接的锚文本特征属性2种模态信息。
3.2 算法比较
文中基于NMF提出2种增量多模态聚类算法,实验中,将提出的2种算法与现有的一些基于NMF的增量和非增量方法进行比较,验证提出算法的性能。具体比较算法包括:①ConcatNMF:将多模态数据的所有模态属性进行直接拼接后进行非负矩阵分解[6];②INMF[13]:为单模态增量非负矩阵分解方法,实验中对数据集中多有模态数据进行单模态增量学习,并采用最好模态结果;③MultiINMF:为多模态非负矩阵分解MultiNMF的增量算法[10],其增量实现与INMF相同;④MultiGNMF为基于图规则化的多模态数据融合算法,其实现拓展了图正则化NMF[15]到多模态数据。
3.3 实验设置
实验当中,比较算法ConcatNMF、INMF、MultiINMF和MultiGNMF的参数选择与其原始文献中相同。文中提出的IAGNMF图正则化参数λ=15,权重分散程度参数γ=1.3;OAGNMF图正则化参数λ=15,权重分散程度参数γ=1.3,缓冲区大小设置为40%数据集大小。每次实验非重复地取1/10数据集的实例作为新到来的实例运行算法学习其低维共享特征,运行10次之后完成对整个数据集的特征学习。对于增量算法,每次学习新实例的低维共享特征后,记录学习时间,与已经完成特征学习的实例的低维共享特征一起进行聚类分析验证学习效果;对于非增量算法,新实例和已完成特征学习的实例一起进行特征学习,记录学习时间,将学习到的所有实例的低维共享特征进行聚类分析验证学习效果。对于每次模型运行,都能得到其时间开销,聚类精度和纯度。每个实验重复运行15次,并取其均值输出比较结果。
实验环境为Windows10操作系统,Matlab R2018a软件平台,硬件环境为Intel®CoreTMi5-7300HQ CPU @ 2.50GHz处理器,8G内存。
3.4 结果分析
LegalText和Webkb 2个文本数据集上的各算法聚类有效性比较结果如图2和图3所示。
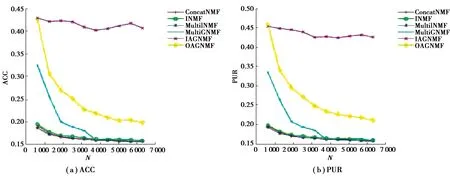
图2 LegalText数据集上的聚类结果比较Fig.2 Comparison of clustering results on LegalText dataset
从图2和图3可以看出,相比于ConcatNMF、INMF、MultiINMF和MultiGNMF,文中提出的2种增量多模态文本聚类方法具有一定的优势。例如,在LegalText数据集上IAGNMF在ACC和PUR 2种聚类指标上一直优于所有比较算法,这是因为IAGNMF实现了增量的图规则化机制保证了融合空间特征与原始数据具有一致的几何相似结构,此外IAGNMF实现了模态权重的自适应调整,保证了各模态的有效信息。同样OAGNMF和MultiGNMF也是用了图规则化项,也得到了较好的结果。OAGNMF采用数据缓存机制,假设一段时间内数据具有相似性,而在实际的数据集LegalText中这个假设很难保证,但在标准数据集Webkb中便能得到较好的效果(如图4)。MultiGNMF实现没有考虑各模态的权重,所以相比于文中提出的算法其性能略有下降。
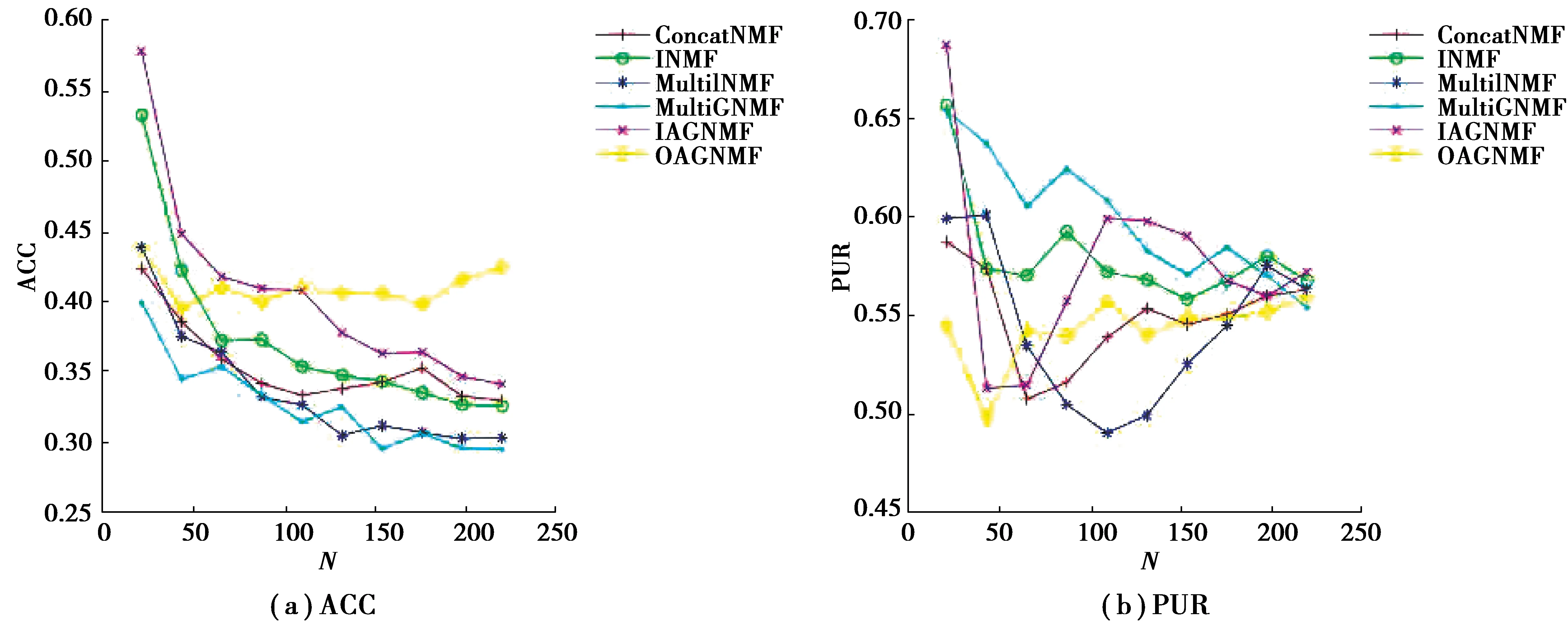
图3 Webkb数据集上的聚类结果比较Fig.3 Comparison of clustering results on Webkb dataset
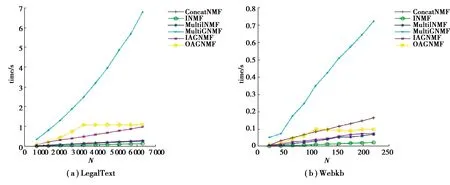
图4 2个数据集上的时间开销比较Fig.4 Comparison of time consumption on two datasets
图4给出了几种比较算法的时间性能。从图中可以看出,基于图规则化的MultiGNMF比ConcatNMF、INMF和MultiINMF需要消耗更多的时间。IAGNMF和OAGNMF同样使用图规则化提升算法的性能,但其增量实现能够有效减少算法的时间开销。
综上,相比于比较算法文中提出的2种算法在聚类性能和时间消耗上均具有一定的优势,适合海量多模态文本数据的增量融合学习与聚类分析。当数据集中数据样本随采集时间有一定的前后依赖时,采用数据缓存机制的OAGNMF算法能够得到较好的性能;而当数据间没有时间依赖时,采用增量图相似结构度量的IAGNMF算法具有更加的聚类性能。
4 结束语
文中提出2种增量多模态文本聚类算法,基于NMF构建多模态文本数据特征学习基本模型,利用局部相似图规则化保证学习特征空间的结合结构与原始数据空间的一致性,提升多模态融合特征学习的准确性。设计了2种增量多模态数据特征学习机制,并对各模态权重进行自适应调整,实现海量多模态文本数据的快速、有效融合学习。通过2个实际文本数据集上的实验结果表明,文中提出的2种算法具有一定的优越性。
