基于非局部高分辨率网络的轻量化人体姿态估计方法
2022-06-21孙琪翔何宁张敬尊宏晨
孙琪翔,何宁,张敬尊,宏晨
(1.北京联合大学 机器人学院,北京 100101; 2.北京联合大学 智慧城市学院,北京 100101)(∗通信作者电子邮箱xxthening@buu.edu.cn)
基于非局部高分辨率网络的轻量化人体姿态估计方法
孙琪翔1,何宁2*,张敬尊2,宏晨1
(1.北京联合大学 机器人学院,北京 100101; 2.北京联合大学 智慧城市学院,北京 100101)(∗通信作者电子邮箱xxthening@buu.edu.cn)
人体姿态估计是计算机视觉中的基本任务之一,可应用于动作识别、游戏、动画制作等领域。当前深度网络模型的设计大多通过加深网络以获得更好的性能,结果导致计算资源的需求超出嵌入式设备和移动设备的计算能力,达不到实际应用要求。针对上述问题,提出了一种融合Ghost模块结构的轻量级网络模型,即使用Ghost模块替换原高分辨率网络中的基础模块,从而减少网络模型的参数量。此外,设计了非局部高分辨率网络,即在网络1/32分辨率阶段融合非局部网络模块,使网络具有获取全局特征的能力,从而提高人体姿态估计的准确率,并在保证模型准确率的前提下降低网络参数量。在MPII人体姿态估计数据集和COCO人体姿态估计数据集上的实验结果表明,所提网络模型与原高分辨率网络相比,在网络模型参数量降低40%的情况下,人体姿态估计准确率提升了1.8个百分点。
人体姿态估计;非局部模块;轻量化;Ghost模块;高分辨率网络
0 引言
人体姿态估计是指从一张图片中找出人的各个部分或各个关节点位置的过程[1]。人体姿态估计是人体动作识别[2]、人机交互和姿态跟踪等几种实际应用要求的基本技术。现阶段人体姿态估计网络的主流研究思路是通过增加网络宽度和网络深度,或增大输入图像尺寸提高人体姿态估计准确率,此类方法需要的庞大计算资源远远超出嵌入式设备和移动设备的计算能力,达不到应用要求,因此如何在降低网络模型参数量的前提下提高模型的精度是亟需解决的问题。
人体姿态估计主要有自上而下和自下而上两种方法。自上而下的方法依赖检测器检测人体实例,通过检测器生成针对单个人体边界框,然后将问题转变为单人姿态估计。Fang等[3]提出了一个局部多人姿态估计(Regional Multi-person Pose Estimation, RMPE)框架,通过提高检测器的精度提高单人姿态估计的精度;Chen等[4]提出了级联金字塔网络(Cascaded Pyramid Network, CPN),该网络将RefineNet和特征金字塔网络(Feature Pyramid Network, FPN)进行融合,进一步提高了预测关键点的准确率;相似地,Huang等[5]利用多尺度监督并融合多尺度特征提高预测结果准确率;Xiao等[6]提出了Simple Baseline网络进行多人姿态估计和跟踪;Newell等[7]提出了堆叠沙漏网络(Stacked Hourglass Network),主体网络采用对称设计,通过融合不同尺度的特征,获取人体关键点之间的空间关联,从而能显著提高模型的准确率;在Hourglass的基础上,Yang等[8]提出了金字塔残差模块(Pyramid Residual Module)提高应对身体部位尺度变化的能力。自上而下的方法会把大小不同的检测框统一到一个尺度进行学习,因此对人体尺度的敏感性相对较弱,对小尺度的人体也更容易估计。然而这种方法对目标检测要求较高,如果检测器的误差较大,后面就难以准确估计人体的姿态,并且计算量受图片中人数的影响较大。
自下而上的方法,首先要找到图片中人体的所有关键点,比如所有头部、膝盖、左手等,然后把这些关键点连接成一个个人。Pishchulin等[9]提出了DeepCut,生成关节候选区域集合,该集合代表了图像中所有人的所有关节点的可能位置,然后将分配问题建模成整数线性规划(Integer Linear Programming, ILP)问题。针对该问题,Iqbal等[10]提出了局部求解ILP的方法。Insafutdinov等[11]提出了DeeperCut,用更深的ResNet[12]估计人体关键点。Levinkov等[13]通过局部搜索算法提供了一个可行的解决ILP问题的方案。Varadarajan等[14]提出了一个贪婪分配算法,通过降低ILP问题的复杂度达到算法实时性。Cao等[15]提出了OpenPose,利用关键点之间的关系建模成关节亲和力场(Part Affinity Fields),因此,OpenPose在速度和准确率方面,相较之前的方法有大幅提升,可以实现实时级别的多人姿态估计。Newell等[16]为了帮助关键点组别分配,提出了关联嵌入(Associative Embedding)方法,引入标记热图(Tag Heatmap)概念。Xia等[17]提出的语义部分分割(Semantic Part Segmentation)侧重于对关键点部件的聚类。Papandreou等[18]提出的PersonLab直接聚集同一个人的关键点,同时学习关键点和其相对位移。Tang等[19]提出了一种组合模型表示人体各部分层次关系,可以解决底层关键点模糊问题。自下而上的方法不受目标检测误差影响,计算量与图像中的人数无关,因此效率较高;但是,对尺度较为敏感,通常对小尺度的人体比较难预测。
网络轻量化方法分为网络参数轻量化、网络裁剪和直接设计轻量化网络。网络参数轻量化指的是减少表征网络参数[20]。Vanhoucke等[21]探索了一种8位整数定点激活实现消除冗余参数的方法;Gong等[22]提出了一种利用矩阵分解法和矢量量化法压缩密集连接层中参数的方法;此外,Binary Connect[23]、Binarized Neural Networks[24]和XNOR-Net[25]等虽然能有效地降低网络参数量的冗余,但是会降低网络的准确率;Hanson等[26]提出了基于偏置参数衰减的网络裁剪方式;李小夏等[27]提出了改进的相关性剪枝方法,以神经元输出值的方差作为相关性条件进行剪枝,取得了较好的效果[20];赵蓉等[28]通过剪枝和并枝两个阶段实现网络结构优化,提高了网络的数值效能。最后是直接设计一种轻量级的网络模型结构。和常规网络相比,轻量级网络结构所需的网络参数量和每秒浮点运算次数(FLoating-point Operations Per Second, FLOPS)更小[20]。因此,轻量级的网络结构更适合在嵌入式设备和小型移动终端上进行部署[20]。Iandola等[29]设计了SqueezeNet,精度上和AlexNet相当,网络量只有AlexNet的1/50;Howard等[30]设计了MobileNets网络结构,具体而言,结合两个超参数宽度乘法器和分辨率乘法器设计了轻量化网络结构,与标准卷积方法相比,参数量降低了8/9。
综上,直接设计轻量级网络可以有效地降低网络参数。本文以高分辨率网络结构[31]为基础,首先,结合Ghost网络结构[32],设计了Ghost模块代替高分辨率网络中原有的基础模块,从而大幅减少网络参数。然后,在Wang等[33]提出的非局部神经网络基础上设计了非局部网络模块,在基础网络的1/32分辨率阶段融合非局部网络模块,使网络具有获取全局特征的能力,从而提高人体姿态估计的准确率[20]。最后,在MPII(Max Planck Institut Informatik)[34]和COCO(Common Objects in COntext)[35]人体姿态估计数据集上验证了所提方法的有效性。
1 人体姿态估计方法
传统用于关键点热图估计的卷积神经网络(Convolution Neural Network, CNN)由类似于分类网络的主干网络(Backbone Network)组成,主体采用分辨率由高到低、再由低到高的方式进行多尺度信息的融合,例如:沙漏(Hourglass)网络[7]通过对称的由低到高分辨率过程恢复高分辨;级联金字塔网络(Cascaded Pyramid Network, CPN)[4]构建级联金字塔模型得到多尺度特征,再经过上采样至高分辨率进行姿态估计;Simple Baseline[6]采用转置卷积层生成高分辨率特征表示;DeeperCut[11]利用膨胀卷积使得恢复高分辨率的过程变得轻量化。上述网络结构如图1所示。
所提方法目的在于降低网络参数量的同时,提高网络估计精度,因此骨干网络结构选择高分辨率网络(High-Resolution Network, HRNet),HRNet[31]为并联结构,通过并行连接高分辨率到低分辨率卷积,并通过重复跨并行卷积执行多尺度融合增强高分辨率特征信息。HRNet由4个并行子网络组成,同一子网络特征的分辨率不随深度变化而变化,并行子网络特征图分辨率依次降低一半,同时通道数增加到两倍。HRNet的深度可以分成4个阶段,第1阶段由1个子网络构成,第2阶段由2个子网络构成,第3阶段由3个子网络构成,第4阶段由4个子网络构成,每个阶段之间由融合模块构成,融合模块将不同分辨率特征信息融合,以增强网络特征表示性能,如图2所示。不同分辨率的特征图,关注原图像中不同尺度的区域,通过融合这些存在互补性的特征,可以得到更好的人体特征表示。

图1 传统人体姿态估计网络结构Fig. 1 Traditional human pose estimation network structure

图2 包含4个阶段的HRNet结构Fig. 2 HRNet structure with 4 stages
2 Ghost网络模块
受限于内存和计算力,在嵌入式设备上部署神经网络是困难的。例如,给定输入数据,其中代表输入数据的通道数,和分别是输入数据的高和宽[20]。用于产生个特征映射的任意卷积层的操作,如式(1)所示:
一个训练好的深度神经网络通常有很多冗余特征图,Han等[32]提出的Ghost卷积可以有效地解决这个问题。假设有个固有特征图,通过初始卷积生成[20],如式(2)所示:

图3 常规卷积Fig. 3 Conventional convolution

图4 Ghost卷积Fig. 4 Ghost convolution
针对本文提出的网络模型,设计了如图5所示的Ghost模块,类似于HRNet中的原始基础模块。Ghost模块由两个Ghost卷积组成,第一个Ghost卷积用作扩展层,增加了通道数,接着利用批归一化(Batch Normalization, BN)和线性整流函数(Rectified Linear Unit, ReLU)加快训练过程。第二个Ghost卷积减少通道数到原始通道数,两个Ghost卷积间通过一个步长为2的深度卷积进行连接,同样每一层增加BN,最后结合残差网络原理,使用shortcut连接输入和输出。
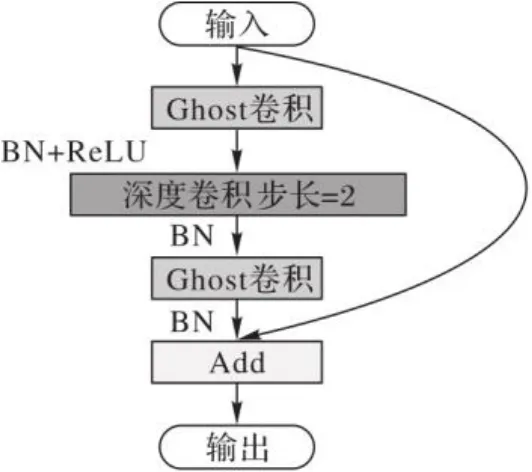
图5 Ghost卷积模块Fig. 5 Ghost convolution module
3 非局部网络模块
HRNet是现阶段人体姿态估计领域的最优网络架构,可以兼顾准确率和网络参数量,但是HRNet和传统网络一样都是使用卷积神经网络(CNN)作为特征提取的方式。卷积神经网络有一定局限性,例如在卷积中,卷积滤波器有25个像素,目标像素的值参照自身和周围的24个像素来计算,这就意味着卷积只能利用局部信息来计算目标像素,而局部卷积操作往往因为无法参考全局信息而造成一些偏差。当然有很多方法可以缓解这个问题,比如,使用更大的卷积滤波器或者更多卷积层的深度网络。但是这些方法往往会带来较大参数量,而结果的改善很有限。在人体姿态估计领域,对于人体的关节点结构性特征,利用传统的卷积提取方式,无法有效地在局部就获取到人体的全部特征,而增加了全局特征就能更好地提取到人体的全部姿态特征,从而提高了人体姿态估计的准确率。为了获取人体姿态的全局特征,Wang等[33]结合非局部均值[36]的特点,提出了一个泛化、简单、可直接嵌入到当前网络的非局部网络模块,非局部网络模块的描述如式(5)所示:
本文方法融合了非局部网络模块和HRNet。因此,对非局部网络模块封装,具体定义如式(6)所示:

图6 非局部网络模块Fig. 6 Non-local network module
4 轻量级HRNet模型
结合分析上述Ghost网络模块结构和非局部网络模块,本文提出了轻量化融合非局部网络模块的高分辨率网络NGHRNet(Non-local block with Ghost High-Resolution Network),结构如图7所示,网络包含4个阶段,主体网络结构和HRNet类似,本文将原始HRNet中的基础模块用Ghost模块代替。为了解决网络参数减少而导致的准确率下降的问题,根据文献[31]可知,越小的分辨率包含越强的语义信息,因此为了更好地获取底层特征,本文在网络的第4个分支上融合非局部网络模块,即在1/32分辨率阶段增加非局部网络模块。

图7 融合Ghost模块和非局部网络模块的HRNet架构Fig. 7 HRNet architecture integrating Ghost module and non-local network module

图8 在NGHRNet的最低分辨率阶段融合非局部模块结构Fig. 8 Fusing non-local module structure at lowest resolution stage of NGHRNet
5 实验与结果分析
5.1 实验环境和数据
实验环境为:64位Ubuntu 18.04,Intel Xeon CPU E5-2678v3@2.50 GHz,内存12 GB,显卡RTX2080Ti以及Cuda10.0.130、Cudnn7.5、Pytorch1.4和Python3.6平台。网络预训练模型使用在ImageNet数据集上预训练的参数。
COCO数据集由超过200 000张样本图片组成,包含250 000个人体目标及17个标注的姿态关键点,采用基于物体关键点相似度(Object Keypoint Similarity, OKS)的平均准确率(Average Precision, AP)作为评价标准。MPII人体姿态数据集是从YouTube视频中提取,其中30 000个人体实例用于训练,10 000个人体实例用于测试,每个人体有16个标注的关键点,采用基于以头部长度作为关键点归一化参考的 (Percentage of Correct Keypoints of head @0.5,PCKh@0.5)作为评价标准。
5.2 评价指标和训练策略
PCKh评价标准[34]通过对测试图像中每个人进行明确的边界限定获得检测准确率。给定边界框框内的候选区域包含原始关键点坐标位置,控制相关阈值得到不同准确率判断预测的关键点是否定位合理,选择阈值。PCKh用于人体躯干大小代替头部框大小,将该尺度用于归一化其他部件的距离,采用欧氏距离方法计算。如果检测关键点与标签关键点的欧氏距离在该阈值范围内,则该检测结果是正确的。以第类人体关键点为例,PCKh的计算如式(7)所示:
其中:PCKh()是第个关键点的PCKh值,其累加和的均值为最终结果;在第个图片中的第类人体关键点的标签值为,对应关键点的预测结果为;样本总数为。以头部框的尺度结合距离归一化系数为判断条件,该阈值越小表示评价标准越严格,PCKh@0.5则表示当时,以距离阈值为0.5进行对真值和预测值的距离比较。
OKS评价标准[35],基于COCO评估指标OKS。AP是对于不同关键点类型和人物大小尺寸的归一化,是关键点之间的平均关键点相似度,在[0,1]内,预测越接近原值则趋向1,反之趋向0。OKS的定义如式(8)所示:
本文将人体检测框的高度和宽度扩展到固定比值,高∶宽= 4∶3,然后将人体检测框从图像中裁切出来,并重新调整到固定大小;同时本文对数据增强的操作包括随机旋转、随机尺度和翻转。
在优化器的选择上,本文使用Adam优化器[37],学习率的设定遵循文献[6],基础学习率设定为,在第170个epoch和第200个epoch分别降为和。最终训练过程在210个epoch结束。对于MPII的数据增强和训练策略与COCO数据集一致,此外为了更好地与其他主流方法对比,本文将MPII数据集裁切并调整到固定大小为。
5.3 结果分析
MPII验证集上的实验结果如表1所示,与HRNet[31]的实验结果基线相比,准确率提升了0.2个百分点,由文献[31]可知,造成这种小幅度提升的原因是MPII数据集的准确率趋于饱和。所提方法主要关注人体关键点估计,将MPII数据集的实验结果可视化,如图9所示,其中实心圆为姿态估计模块定位的人体关键点。
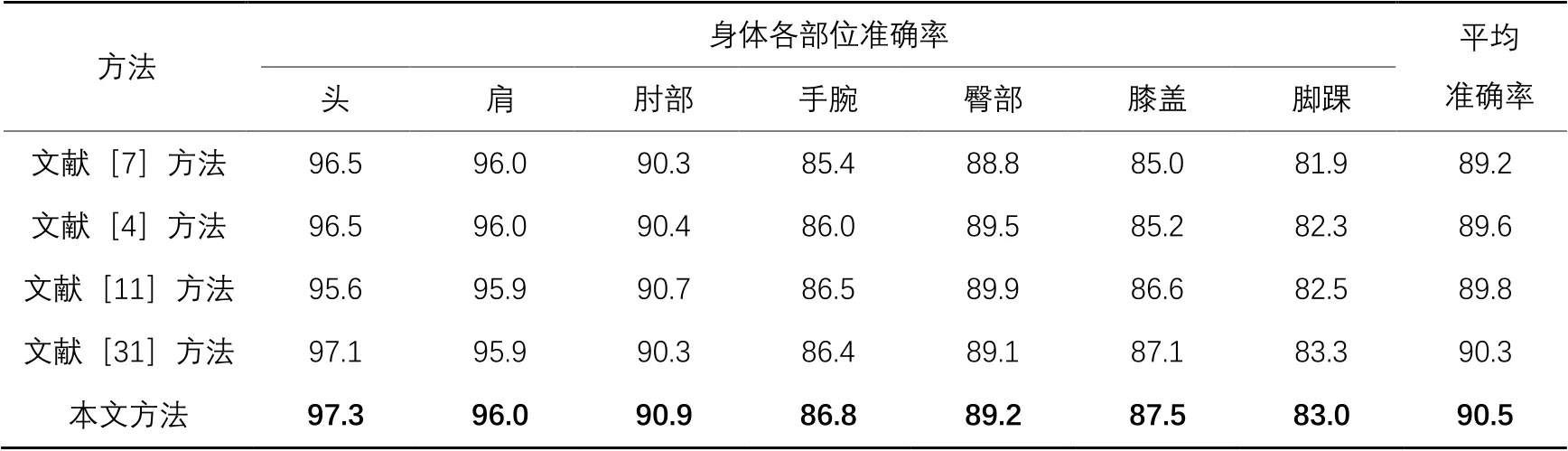
表1 MPII验证集上的实验结果(PCKh@0.5) 单位: %Tab. 1 Experimental results on MPII validation set (PCKh@0.5) unit: %

图9 MPII数据集检测结果示例Fig. 9 Examples of MPII dataset detection results
COCO数据集上不同方法的实验结果如表2所示。由表2可知,在图像输入大小为的前提下最高准确率可以达到76.9%,即使是32通道的网络,准确率仍能超过HRNet的48通道网络;在图像输入大小为的48通道网络上达到的最高准确率为78.0%。从网络参数量来看,本文提出的网络所需参数量远少于作为基线网络的HRNet,且在网络模型参数量降低40%的情况下,人体姿态估计准确率提升了1.8个百分点。
针对COCO数据集,本文采用可视化工具,将被估计出的人体关键点进行连接,得到如图10所示的人体姿态估计图,给出了包括不同视角、多人和不同目标大小的人体姿态估计结果。
5.4 消融实验
从最高分辨率阶段到最低分辨率阶段分别插入一个非局部模块,实验结果如表4所示,网络主体架构为轻量化网络,0代表没有融合非局部网络模块。由表4可知,在网络的最低分辨率增加非局部模块可以得到最优准确率。

表2 不同方法在COCO数据集上的性能对比Tab. 2 Performance comparison of different methods on COCO dataset

图10 COCO数据集检测结果示例Fig. 10 Examples of COCO dataset detection results

表3 网络轻量化消融实验结果Tab. 3 Ablation experimental results of network lightweight
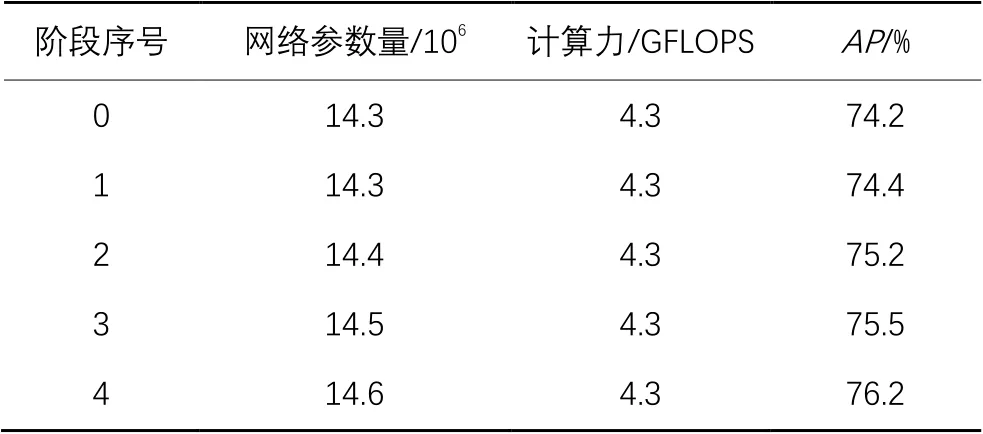
表4 非局部网络模块消融实验结果Tab. 4 Ablation experimental results of non-local network module
6 结语
本文从提升人体姿态估计精度的角度,提出非局部网络模块,通过获取全局特征,实现更高的人体姿态估计精度;提出了Ghost模块替换HRNet的基础模块,降低了网络参数量。综合上述两种方法的实验结果,可以看出本文所提方法的优越性。如何在提高精度的前提下,更好地控制网络参数量是未来的研究重点。
[1] 王冉.基于深度卷积神经网络的人体姿势估计研究[D].成都:电子科技大学,2016:11-12.(WANG R. A research of human pose estimation based on deep convolutional neural network [D]. Chengdu: University of Electronic Science and Technology of China, 2016:11-12.)
[2] YAN S J, XIONG Y J, LIN D H. Spatial temporal graph convolutional networks for skeleton-based action recognition [C]// Proceedings of the 2018 32nd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2018:7444-7452.
[3] FANG H S, XIE S Q, TAI Y W, et al. RMPE: regional multi-person pose estimation [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2353-2362.
[4] CHEN Y L, WANG Z C, PENG Y X, et al. Cascaded pyramid network for multi-person pose estimation [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7103-7112.
[5] HUANG S L, GONG M M, TAO D C. A coarse-fine network for keypoint localization [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017:3047-3056.
[6] XIAO B, WU H P, WEI Y C. Simple baselines for human pose estimation and tracking [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11210. Cham: Springer, 2018:472-487.
[7] NEWELL A, YANG K Y, DENG J. Stacked hourglass networks for human pose estimation [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9912. Cham: Springer, 2016:483-499.
[8] YANG W, LI S, OUYANG W L, et al. Learning feature pyramids for human pose estimation [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 1290-1299.
[9] PISHCHULIN L, INSAFUTDINOV E, TANG S Y, et al. DeepCut: joint subset partition and labeling for multi person pose estimation [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016:4929-4937.
[10] IQBAL U, GALL J. Multi-person pose estimation with local joint-to-person associations [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9914. Cham: Springer, 2016:627-642.
[11] INSAFUTDINOV E, PISHCHULIN L, ANDRES B, et al. DeeperCut: a deeper, stronger,and faster multi-person pose estimation model [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9910. Cham: Springer, 2016: 34-50.
[12] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE,2016:770-778.
[13] LEVINKOV E, UHRIG J, TANG S Y, et al. Joint graph decomposition amp; node labeling: problem,algorithms, applications [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1904-1912.
[14] VARADARAJAN S, DATTA P, TICKOO O. A greedy part assignment algorithm for real-time multi-person 2D pose estimation [C]// Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2018: 418-426.
[15] CAO Z, SIMON T, WEI S E, et al. Realtime multi-person 2D pose estimation using part affinity fields [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1302-1310.
[16] NEWELL A, HUANG Z A, DENG J. Associative embedding: end-to-end learning for joint detection and grouping [C]// Proceedings of the 2017 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017:2274-2284.
[17] XIA F, WANG P, CHEN X, et al. Joint multi-person pose estimation and semantic part segmentation [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6769-6778.
[18] PAPANDREOU G, ZHU T, CHEN L C, et al. PersonLab: person pose estimation and instance segmentation with a bottom-up, part-based, geometric embedding model [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11218. Cham: Springer, 2018:282-299.
[19] TANG W, YU P, WU Y. Deeply learned compositional models for human pose estimation [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11207. Cham: Springer, 2018:197-214.
[20] 孙琪翔,何宁,张聪聪,等.轻量级图卷积人体骨架动作识别方法[J/OL].计算机工程.[2021-06-25].https://doi.org/10.19678/j.issn.1000-3428.0061304.(SUN Q X,HE N, ZHANG C C, et al. A lightweight graph convolution human skeleton action recognition method [J/OL]. Computer Engineering. [2021-06-25]. https://doi.org/10.19678/j.issn.1000-3428.0061304.)
[21] VANHOUCKE V, SENIOR A, MAO M Z. Improving the speed of neural networks on CPUs [EB/OL]. [2021-02-12]. https://storage.googleapis.com/pub-tools-public-publication-data/pdf/37631.pdf.
[22] GONG Y C, LIU L, YANG M, et al. Compressing deep convolutional networks using vector quantization [EB/OL]. [2021-06-25]. https://arxiv.org/pdf/1412.6115.pdf.
[23] COURBARIAUX M, BENGIO Y, DAVID J P. BinaryConnect: training deep neural networks with binary weights during propagations [C]// Proceedings of the 2015 28th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2015:3123-3131.
[24] COURBARIAUX M, HUBARA I, SOUDRY D, et al. Binarized neural networks: training deep neural networks with weights and activations constrained toor[EB/OL]. [2021-06-25]. https://arxiv.org/pdf/1602.02830.pdf.
[25] RASTEGARI M, ORDONEZ V, REDMON J, et al. XNOR-Net: ImageNet classification using binary convolutional neural networks [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9908. Cham: Springer, 2016:525-542.
[26] HANSON S J, PRATT L Y. Comparing biases for minimal network construction with back-propagation [C]// Proceedings of the 1988 1st International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 1988:177-185.
[27] 李小夏,李孝安.一种改进的神经网络相关性剪枝算法[J].电子设计工程,2013,21(8): 65-67.(LI X X, LI X A. An improved correlation pruning algorithm for artificial neural network [J]. Electronic Design Engineering, 2013, 21(8): 65-67.)
[28] 赵蓉,唐楚淇,刘伟林,等.一种新的基于灰色关联分析的BP神经网络剪枝算法[J].科技创新与应用,2016(13):17-18.(ZHAO R, TANG C Q,LIU W L, et al. A new BP neural network pruning algorithm based on grey relational analysis [J]. Technological Innovation and Application,2016(13): 17-18.)
[29] IANDOLA F N, HAN S, MOSKEWICZ M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and lt;0.5 MB model size [EB/OL]. [2021-06-25]. https://arxiv.org/pdf/1602. 07360.pdf.
[30] HOWARD A G, ZHU M, CHEN B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications [EB/OL]. [2021-06-25]. https://arxiv.org/pdf/1704.04861.pdf.
[31] SUN K, XIAO B, LIU D, et al. Deep high-resolution representation learning for human pose estimation [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 5686-5696.
[32] HAN K, WANG Y H, TIAN Q, et al. GhostNet: more features from cheap operations [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 1577-1586.
[33] WANG X L, GIRSHICK R, GUPTA A, et al. Non-local neural networks [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018:7794-7803.
[34] ANDRILUKA M, PISHCHULIN L, GEHLER P, et al. 2D human pose estimation: new benchmark and state of the art analysis [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE, 2014: 3686-3693.
[35] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8693. Cham: Springer, 2014: 740-755.
[36] BUADES A, COLL B, MOREL J M. A non-local algorithm for image denoising [C]// Proceeding of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2005: 60-65.
[37] KINGMA D P, BA J L. Adam: a method for stochastic optimization [EB/OL]. [2021-06-25]. https://arxiv.org/pdf/1412. 6980.pdf.
Lightweight human pose estimation method based on non-local high-resolution network
SUN Qixiang1, HE Ning2*, ZHANG Jingzun2, HONG Chen1
(1.College of Robotics,Beijing Union University,Beijing100101,China;2.Smart City College,Beijing Union University,Beijing100101,China)
Human pose estimation is one of the basic tasks in computer vision, which can be applied to the fields such as action recognition, games, and animation production. The current designs of deep network model mostly use deepening the network to obtain better performance. As a result, the demand for computing resources is beyond the computing power of embedded devices and mobile devices, and the requirements of actual applications can not be met. In order to solve the problems, a new lightweight network model integrating Ghost module structure was proposed, that is, the Ghost module was used to replace the basic module in the original high-resolution network, thereby reducing the number of network parameters. In addition, a non-local high-resolution network was designed, that is, the non-local network module was fused in the 1/32 resolution stage of the network, so that the network has the ability to obtain global features, thereby improving the accuracy of human pose estimation, and reducing the network parameters while ensuring the accuracy of model. Experiments were carried out on the human pose estimation datasets such as Max Planck Institut Informatik (MPII) and the Common Objects in COntext (COCO).Experimental results indicate that, compared with the original high-resolution network, the proposed network model has the accuracy of human pose estimation increased by 1.8 percentage points with the number of network parameters reduced by 40%.
human pose estimation; non-local module; lightweight; Ghost module; high-resolution network
TP391.4
A
1001-9081(2022)05-1398-09
10.11772/j.issn.1001-9081.2021030512
2021⁃04⁃04;
2021⁃06⁃02;
2021⁃06⁃03。
国家自然科学基金资助项目(61872042);国家重点研发计划项目(2018AAA0100804);北京市教委科技计划重点项目(KZ201911417048);北京市教委科技计划面上项目(KM202111417009);北京联合大学人才强校优选计划项目(BPHR2020AZ01,BPHR2020EZ01);北京联合大学研究生科研创新项目(YZ2020K001)。
孙琪翔(1994-),男,黑龙江大兴安岭人,硕士研究生,主要研究方向:数字图像处理、计算机视觉; 何宁(1970-),女,辽宁盘锦人,教授,博士,主要研究方向:数字图像处理; 张敬尊(1980-),女,河北衡水人,讲师,博士,主要研究方向:数字图像处理; 宏晨(1974-),男,宁夏青铜峡人,副教授,博士,主要研究方向:多媒体信息处理。
This work is partially supported by National Natural Science Foundation of China (61872042), National Key Research and Development Program of China (2018AAA0100804), Key Program of Science and Technology Plan of Beijing Municipal Education Commission (KZ201911417048), General Program of Science and Technology Plan of Beijing Municipal Education Commission (KM202111417009), Premium Program of Strengthening University by Talents of Beijing Union University (BPHR2020AZ01,BPHR2020EZ01), Research and Innovation Program for Graduate Students of Beijing Union University (YZ2020K001).
SUN Qixaing, born in 1994, M. S. candidate. His research interests include digital image processing, computer vision.
HE Ning, born in 1970, Ph. D., professor. Her research interests include digital image processing.
ZHANG Jingzun, born in 1980, Ph. D., lecturer. Her research interests include digital image processing.
HONG Chen, born in 1974, Ph. D., associate professor. His research interests include multimedia information processing.
