基于客户行为数据卷烟推荐算法设计
2022-06-20张晓博
□文/张晓博
(河南省烟草公司新乡市公司卷烟营销中心 河南·新乡)
[提要] 为推动河南烟草商业数字化转型,提升资源要素配置效率,本文以客户行为数据为分析对象,构建卷烟推荐算法。首先阐述推荐技术的分类和特点,论述协同过滤算法的实现路径和基本原理,以零售客户卷烟推荐为场景,从数据获取、相似度计算、生成推荐策略、结果修正等方面论述基于用户的协同过滤推荐算法(UserCF)和基于项目的协同过滤推荐算法(ltemCF)构建过程,论证相似度系数对算法“马太效应”的影响,通过复杂度分析得出ltemCF 在扩展性方面优于UserCF 的推论,通过编程和离线实验,验证推论的正确性、算法的可行性,揭示推荐结果的流行度、覆盖率与邻居数量k 的关系。
引言
在信息技术的推动下,新一轮科技革命和产业变革快速发展,推动着社会进步,深刻影响着人们的工作和生活。2019 年,我国数字经济增加值达到35.8 万亿元,占GDP 比重达到36.2%。“十四五”规划和2035 年远景目标纲要对“加快数字化发展,建设数字中国”谋篇布局,强调要“迎接数字时代,激活数据要素潜能”,烟草行业作为国家经济体系的重要组成部分,同样在加快自身的数字化转型步伐,2021 年全国烟草工作会议的精神之一就是要“推进实施数字化转型战略”。 烟草行业经过多年信息化建设,已基本实现了数据资源的原始积累,如何聚焦新场景、新服务、新要求,进而发挥数据要素潜能、优化资源配置,是行业在数字化转型过程中需要解决的突出问题。
一、推荐技术
客户行为数据是企业最具价值的数据资源之一,蕴含着客户的消费轨迹和个性偏好,通过对此类数据的分析、挖掘,从数据角度建立对客户行为的理解,企业可以更深入地洞察客户消费心理、发现潜在需求、提高商品销售。在行业外,客户行为数据的主要使用途径是推荐系统。电子商务推荐系统(Recommendation Systems for E-Commerce)是“利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买的过程”。推荐系统的研究内容包括:用户信息的获取和建模、推荐技术研究、推荐算法评价三个方面。其中,推荐技术是构成推荐系统的核心,决定着推荐效果,根据其所采用的算法原理,推荐技术可分为以下几类:
(一)基于规则的推荐技术。通过预置一系列触发条件或规则,根据条件判断生成推荐结果。例如,数据挖掘领域的关联规则(Association Rule),其原理是通过多次迭代构造出频繁项集,根据提升度、置信度、支持度等指标建立关联规则,从而帮助企业给顾客提供购买建议、制订合理的交叉销售方案。简单关联规则属于无监督学习算法,当前项数量和项目集元素数量过多时,会造成运算速度慢、资源开销大的问题,同时规则质量也难以保证。
(二)基于内容的推荐技术。核心原理是通过标签库、隐语义向量等技术分别对用户和商品进行画像,根据画像结果计算出用户和商品之间的关联性,再根据关联性的高低进一步的排序和筛选得出推荐方案,该技术的推荐结果具有良好的解释性,缺点是很难为用户推荐其关注点之外的商品,对用户的潜在兴趣挖掘有限。
(三)基于邻域的推荐技术。其基本原理是kNN,根据相关性寻找与客户最相似的k 个邻居,将邻居最感兴趣的若干物品推荐给客户。协同过滤算法是邻域推荐技术的典型代表,其能够以类似“爱屋及乌”的方式将相似物品推荐给用户,更容易挖掘潜在需求。缺点是当用户或物品数量规模较大时,相似性计算的效率会变的非常低,除此之外还存在数据稀疏性、冷启动、可扩展性三大问题。
以上算法中,协同过滤技术以其较为优秀的需求挖潜效果和良好的“效率-质量”平衡性,在电子商务领域得到了广泛应用,例如Netflix、YouTube、亚马逊等。在烟草行业,浙江省局在构建“互联网+”烟草商业模式的过程中将协同过滤技术用于卷烟商品推荐,取得了良好成效。但目前,河南烟草商业在零售客户卷烟商品推荐方面主要还是采用传统的“专家系统”(即客户经理口头宣传),主观性较强,缺乏从数据角度分析客户潜在需求的能力。客户行为数据涉及方方面面,本文以其中的卷烟订购数据为例,论述了协同过滤推荐算法的实现过程,分析了算法存在的“马太效应”,在理论推导的基础上,通过实验论证了基于物品的协同过滤推荐算法的可行性和运算优势。
二、协同过滤算法的原理
(一)实现路径。推荐系统基本通过三种途径建立用户与物品的联系:(1)用户-用户-物品。即若用户A 与用户B 具有相似的兴趣,则可认为用户B 喜欢的物品对用户A 来说同样喜欢,可将B 用户购买过的物品推荐给A。(2)用户-物品-物品。即若用户喜欢某个物品,则可将与该物品相似的物品推荐给用户。(3)用户-特征-物品。利用人与物的联系,即若用户具有某种特征或标签,可将与该特征或标签相似的物品推荐给用户。以上(1)、(2)即是协同过滤技术的基本思想。当需要为目标用户推荐商品时,可以先找到与目标用户相似的用户(或与目标用户购物篮物品相似的物品),然后将相似用户喜欢的物品(或与购物篮中物品相似的物品)推荐给目标用户。根据相似对象的不同,协同过滤技术总体可分为两类:以路径(1)为代表的基于用户的协同过滤(User-based Collaborative Filtering,UserCF),以及路径(2)为代表的基于项目的协同过滤(Item-based Collaborative Filtering,ItemCF)。
(二)算法模型。无论是UserCF 还是ItemCF,其主要实现过程可分为以下两步:(1)计算用户相似度或物品相似度。(2)根据相似度和用户历史行为数据生成推荐策略。下面以卷烟商品推荐为例,论述算法模型构建步骤:
1、构建客户-卷烟数据矩阵。假设全市有n 个卷烟零售客户,用集合U={U1,U2,…,Un}表示,销售i 个规格的卷烟,用集合M={M1,M2,…,Mi}表示,构建矩阵R=(rni),rni表示客户Un在卷烟Mi上的特征(其中,Un∈U,Mi∈M),该特征可以是订购量,也可以是订购次数、商品评分、销售比重等各类客户行为。矩阵Rn×i中的一行代表一个客户在所有卷烟上的特征,每一列表示一个卷烟在所有客户上的特征。
2、构建相似度矩阵。与聚类算法类似,协同过滤算法也使用“距离”作为用户或物品之间的相似性度量。常见的“距离”计算方法有以下几种:
(1)欧氏距离。假设客户Ua,Ub∈U,则两者的欧氏距离可通过以下公式计算:
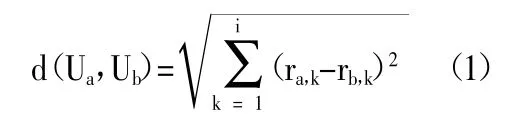
(2)Jaccard 系数。若客户Ua,Ub订购卷烟的集合分别是Ia,Ib(Ua,Ub∈U 且Ia,Ib∈M),则Jaccard 系数可表示为:

(3)余弦距离。如果把用户(或卷烟)的特征看作向量,则向量的余弦距离等于向量的内积与向量长度乘积的商。如果两个向量长度相近,同时方向相同或相反,则其余弦距离的绝对值接近1;若两个向量长度区别较大,或相互垂直接近正交,则余弦距离的绝对值接近0。假设用户Ua,Ub∈U,余弦距离可表示为:

除此之外,还可以采用欧式距离的平方、皮尔逊相关系数等。无论采用哪种算法,归根到底是要对相似度进行量化,为相似性判断提供客观的、可比的数值依据。
对于式(2)和式(3),特征矩阵R 的元素取值将直接决定距离的计算结果。一般的,rni通常取用户对商品的评分,但由于目前新商盟系统尚未集成卷烟评分功能,所以本文对rni的取值采用以下规则:当用户订购了某卷烟时,对应的rni为1,否则rni为0。在距离算法方面,采用式(3)的余弦距离作为相似性度量标准。
构建矩阵W=(wi,j)作为相似度矩阵。若采用UserCF,则wa,b(wa,b∈W)表示零售户a 与零售户b 的相似度,若采用ItemCF,wa,b(wa,b∈W)表示卷烟a 与卷烟b 的相似度。W 为方阵,其维数与零售客户或卷烟规格的数量相同。
3、生成推荐策略。如前文所述,协同过滤技术采用了kNN,推荐策略基于k 个最相近邻居生成。选择邻居的过程即是算法字面中“协同”的过程,在把邻居喜好的卷烟正式推荐给客户前,需要将推荐列表中目标客户已订购的卷烟“过滤”掉,只留下目标客户未订购过的卷烟,以提高推荐策略的有效性。具体过程是,当用UserCF 算法为客户Ua推荐卷烟时,首先从用户相似度矩阵W 中检索wa,j(j=1,2,…,n),根据wa,j找出k 个与Ua相似度高的客户,k 个客户与目标客户的相似度用集合w={w1,w2,…,wk}表示,然后建立这k 个客户订购过的卷烟的集合i={i1,i2,…,im},并从i 中移除Ua已经订购过的卷烟。接着对集合i中的每个卷烟计算推荐度pi,计算公式见式(4)。最后将集合i 按照pi降序排列,生成推荐结果。
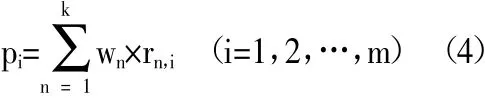
ItemCF 生成推荐策略的过程与UserCF 类似,可按照式(5)计算推荐度pi。其中,N(Ua)表示客户Ua已订购的卷烟规格种类数量。
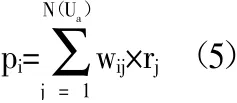
式(4)和式(5)中带有下标的r 是相似度修正系数,假如其取值为订购量,以ItemCF 为例,其作用可解释为:即使客户已订购的卷烟ia和备选卷烟ib有较高的相似度,但如果客户对ia的兴趣度较低(表现为订购量少或订购次数少),则仍不能将ib推荐给客户,因此要对给w 进行修正,得出一个较低的pi值。需要注意的是,若r 取值不当,不但不能起到修正效果,反而会进一步放大荐算法的“马太效应”,也就是说算法会更倾向于向目标客户推荐热门卷烟,而忽视处于“长尾”的卷烟,不利于挖掘潜在需求。
例如,假如表1 为计算得出的物品相似度矩阵,客户订购了卷烟I2和I3,数量分别是40 条和5 条,采用ItemCF 生成推荐策略,如果将订购量作为r 值,那么pi1=0.8×40+0.2×5=33,pi4=0.2×40+0.8×5=12,算法将优先推荐I1。但实际情况很可能是I1和I2属于热门主销规格,而I3和I4属于补充规格,但由于客户对I3的订购量少,使得在r 的作用下,其他卷烟很难从I3得到相对较高的推荐度,这种“连坐”惩罚明显会让“强者更强,弱者更弱”,即“马太效应”。为降低这种效应,让所有卷烟获得相对公平的推荐几率,本文将r 取值为1,重新计算得到,pi1=0.8+0.2=1,pi4=0.2+0.8=1,在计算结果上,让I1和I4有了均等的“出镜”机会,从而使算法能更好地发现客户的“尾部”需求。(表1)

表1 物品相似度矩阵一览表
三、算法的评价和复杂度分析
推荐算法最终要应用于实际场景。在实际使用前应当对算法的可用性、准确性、运算性能等进行评估,以确定最优运行参数、确保使用效果。推荐算法不但要对高维度的用户和商品数据进行运算,而且要将推荐结果快速呈现给用户,所以对计算速度有着较高要求。
(一)评价指标。协同过滤算法可以通过以下几个指标进行评价:
1、系统性能。包括算法的时间复杂度和空间复杂度。时间复杂度是指算法的时间开销,常见的时间复杂度包括常数阶、对数阶、线性阶等;空间复杂度体现了算法的存储资源开销,与算法采用的数据结构密切相关。
2、准确率。指在推荐结果集中有多少比例的卷烟被零售客户实际订购。
3、招回率。指在零售客户的订单中有多少比例的商品来自推荐结果集。
4、流行度。如果流行度很高,说明推荐结果偏热门,不太能够为客户带来新颖的推荐结果。卷烟Im的流行度按照式(6)计算,其中N(Im)指订购卷烟Im的客户。算法的流行度用推荐结果集的平均流行度表示,即其中n 为推荐结果集中的元素个数。

5、覆盖率。表示推荐结果集中的卷烟规格占规格总数的比例,如果所有的卷烟都被至少推荐给了1 个客户,那么该算法的覆盖率就是100%。覆盖率越高,就有越多的卷烟进入客户的推荐列表,算法就越能发挖长尾需求。
由于目前尚不具备将推荐算法植入新商盟在线运行的条件,无法验证算法的准确率和招回率,所以本文对算法的评测主要基于离线实验,并选择流行度、覆盖率作为评价标准。
(二)算法复杂度。如引言部分所述,当用户或物品的数量规模较大时,协同过滤算法的资源开销会急剧增大,尤其在相似性计算上,效率会变得非常低,这个问题被称为算法的“扩展性”。
根据复杂度的定义及算法原理易知,UserCF 的运算用时和存储空间开销与用户数的平方成正比,而ItemCF 在此方面则与卷烟规格数成正比。就地市级烟草公司来说,零售客户的基本在104数量级,卷烟规格的数量级在102,客户的月平均品牌宽度数量级在101。所以,可以推断,当零售客户数量增大时,UserCF 的资源开销将远高于IterCF,在扩展性方面,ItemCF 将优于UserCF。
四、实验设计
按照前述算法模型编写程序代码,计算流行度、覆盖率、算法运行时间三个关键数据,记录不同k 值(即邻居数量)下的算法表现,评估算法的可行性和运算效能。
(一)实验环境。本文实验的软件环境为Windows7 操作系统、Python3.8.7 编程语言,硬件环境为CPU Croe i5-3470,8G DDR3 1600内存。
(二)实验步骤
1、数据准备。抽取新乡市2021 年4 月5 日至4 月30 日零售客户卷烟订购数据,共669,538 行,保存为csv 格式,第1 列是许可证号,第2 列是卷烟代码,第3 列是订购量。
2、编写代码。编写数据读取、相似度计算、卷烟推荐、流行度计算、覆盖率计算5 个功能模块,对代码进行优化,对每个模块进行单元测试,确保功能正常、结果准确。
3、复杂度实验。分别取前0.05%、1%、2%、3%、4%、5%、100%的原始数据,形成7 个分组,每个分组进行1 次实验,记录客户数、平均品牌宽度、相似度矩阵运算耗时数据。
4、流行度和覆盖率实验。采用全量数据,计算并记录不同k 值下推荐结果的流行度和覆盖率,观察三者之间的关系。
(三)实验结果。在原始数据中,用户数u 等于20,543,户均品牌宽度i 等于32.59,规格总量I 等于133。图1 为便于观察曲线走势,图中4 个指标各自做了0~100 标准化,展示了UserCF 和ItemCF 耗时随数据条件的变化趋势,图2 是不同k 值下ItemCF 推荐结果的流行度和覆盖率的变化曲线。(图1、图2)

图1 不同分组的耗时曲线图

图2 不同K 值下ItemCF 推荐结果流行度和覆盖率变化趋势图
(四)实验结论。从图1 和图2 不难看出,UserCF 的耗时曲线与u2走势基本一致,呈指数增长,ItemCF 耗时曲线与u×i2高度吻合,呈线性增长,从而证明了当用户数量远高于商品数量时,ItemCF 要比UserCF有着更好的扩展性。
k 值的选择对推荐结果的流行度和覆盖率有直接影响。随着K 逐渐变大,流行度逐渐下降,这种下降可以解释为k 值的增大为更多冷门卷烟提供了进入到推荐列表的机会,同时也从侧面印证了协同过滤算法本身更倾向于推荐相对热门的商品。覆盖率随k 值逐渐上升,并且覆盖率的上升速度随k 值增大而逐渐放缓。可见,k 值的选择并非越高越好,一方面k 值对提升覆盖率的边际效用递减;另一方面如果推荐列表中的商品过多,反而会失去其对客户订购行为的指导意义。
结语
由于新商盟系统功能的限制,烟草行业对客户行为数据的收集能力仍十分有限,在大数据快速发展的今天,不得不说是一种遗憾。协同过滤推荐算法作为互联网时代最为流行的推荐算法之一,有着广阔的应用前景和改进空间,开源组织Apache 甚至已将协同过滤算法作为功能模块之一集成到了Mahout 项目当中。笔者通过编写代码实现协同过滤算法,一方面考虑了烟草业务的特殊性;另一方面也希望通过动手实践对算法原理有更加深入地体会和了解。本文所述算法模型和实验代码仅涉及了协同过滤的基础功能,对冷启动、数据稀疏性、代码优化、相似性惩罚等问题并未做深入研究,在实际应用前,仍需要进一步完善和优化。
