基于多智能体强化学习的勤务保障指挥调度方法
2022-06-20戴明强纪丽娜
吴 靳,戴明强,侯 腾,纪丽娜
(1. 海军工程大学,湖北 武汉 430032;2. 中国船舶系统工程研究院,北京 100036;3. 中国船舶集团有限公司第七一三研究所,河南 郑州 450015)
飞机出动架次率是衡量大型水面舰船履行战术使命的核心指标,影响架次率的关键因素是勤务保障作业的指挥调度效率。然而,舰船甲板是一个极其复杂且高不确定性的动态环境,在保证作业人员及保障装备安全的前提下,实现动态、高效且可靠的多机并行资源供给保障,要求对一组待保障飞机进行合理的指挥调度。鉴于大型水面舰船飞行甲板勤务保障组织与指挥的复杂性,建立勤务保障指挥与调度模型,求解安全可靠的勤务保障作业组织指挥方案,成为当前研究的热点和前沿。
勤务保障组织指挥及调度问题,不仅具备多阶段特征,也是一个时空资源受限的调度任务。针对此类多阶段多资源受限的调度问题,从20世纪 50 年代起的数十年中,国外专家学者就已经进行了长期的、大量的研究和探索工作,典型的解决方案涵盖线性规划、目标规划、动态规划、整数规划及决策分析等运筹学方法。美国海军先后经历了人工飞机移动及勤务作业规划的Ouija board系统、运用电子化追踪手段获取飞机状态的甲板作业规划信息系统(OPIS)、基于人机交互的甲板作业规划决策支撑系统(DCAP)。目前,依赖数字孪生、边缘计算等新兴技术的新一代智能化勤务指挥辅助决策系统也在加紧部署测试。相比之下,我国相关科研工作起步较晚,近十年我国开始逐步探索利用自动化的决策手段,辅助指挥官完成复杂勤务保障指挥调度任务,研究成果包括勤务流程编排优化、舰载机阵位优化、弹药补给调度优化及舰载机调运避碰规划。但是,现存方案对人、机、环全要素的整体优化不足,更重要的是,指挥调度智能化水平不足,动态应急导调能力弱。
近年来,以深度学习、强化学习为代表的人工智能技术,为飞机舰面勤务保障作业指挥与调度问题提供了新的解决思路。为此,本文探索将强化学习与多智能体技术深度融合,面向飞机勤务保障指挥与调度任务,提出了一种基于多智能体深度确定性策略迭代算法的决策调度方法,运用深度神经网络实现了勤务保障高层次态势特征的感知及提取,辅助指挥人员为待保障飞机快速制定实用的勤务保障计划。最后,本文构建了飞机勤务保障仿真原型系统,模拟飞机空中遇到特情后须返航迫降的非典型场景,验证了决策调度方法的有效性和先进性。
1 任务分析
勤务保障指挥与调度任务是为实现各型飞机在舰船甲板面上安全、高效地执行各类勤务作业而进行的保障阵位、保障装备的调配调度。即通过集中式的指挥调度,以提高飞机出动架次率为目标,按既定保障作业执行流程,为每一架待出动飞机选定合适的保障阵位,分配保障所需的各类保障装备,从而在最短时间内保障飞机具备出动状态。勤务保障指挥与调度,需要遵守一系列保障作业执行约束。本文梳理了核心勤务保障场景的约束如下。
1)保障流程约束
各类勤务保障作业的有序执行,有赖于规范的作业执行流程。本文假设飞机甲板勤务保障过程包括如图1所示的全部保障作业(mission_1至mission_15),且存在复杂的串、并行作业先后执行关系。
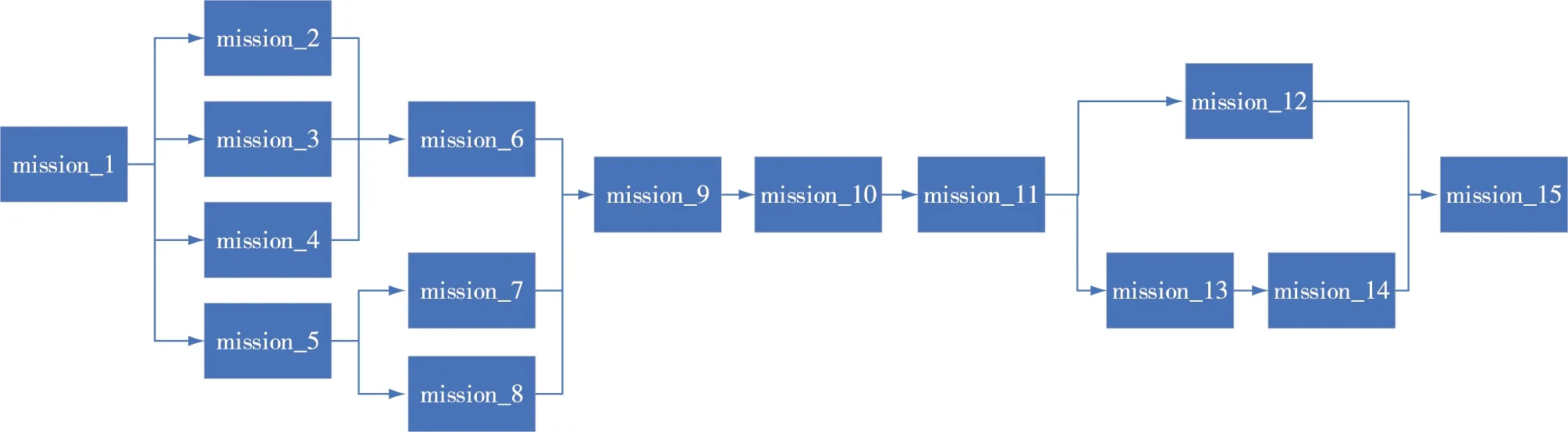
图1 飞机勤务保障作业流程
本文利用定义保障作业的前继作业的方式,表征复杂作业执行流程。若第′个保障作业为第个保障作业的前继作业事件,则后继作业必须在其所有前继作业完成后才能开始执行,如式(1)所示。
,≥′,
(1)
其中,,表示第架飞机第个作业的开始执行时间,,表示第架飞机第个作业的执行完成时间。
2)保障资源约束
不同类型的勤务保障作业执行所需的保障资源不尽相同。具体而言,与图1包含的作业种类一一对应,每个勤务保障作业执行所需的装备资源(类型包含Dev_1至Dev_8)、专业人工资源(Man)和作业时长被列在表1中。

表1 勤务保障作业信息表
3)保障阵位约束
在飞机勤务保障过程中,每架飞机每一个保障作业能且仅能在一个保障阵位上完成,且该作业必须在飞机到达指定保障阵位后才开始执行。每一个保障阵位在整个勤务保障过程中可供若干架飞机完成其若干个作业,但是每个保障阵位同一时刻仅供一架飞机使用。
2 基于MA-DDPG的勤务保障指挥调度算法
针对飞机勤务保障指挥调度任务,提出了一种基于多智能体深度确定性策略迭代(MA-DDPG,Multi-agent Deep Deterministic Policy Gradient)改进的指挥与调度方法。改进的指挥与调度算法是一种多智能体(Multi-agent)技术与强化学习深度融合的勤务保障指挥调度算法,其基于Actor-Critic强化学习框架完成模型训练及运用。在本算法中,每架待保障飞机都会被分配一个智能决策代理Agent,独立Agent的Critic阶段能够获取所有Agent的作业调度决策动作信息,然后,进行中心化训练,Actor阶段只使用局部态势观测信息进行调度动作选择。
2.1 勤务保障指挥与调度MDP模型
勤务保障指挥与调度可转变为一个序列化决策任务。在每个指挥调度决策步内,首先,感知获取当前舰船保障态势;之后,识别提取保障态势的高层次态势特征,利用智能决策代理Agent,输出当前决策步内的指挥决策动作;最后,基于确定的决策动作,完成相应飞机的阵位迁移及相应保障作业的开展,最终实现勤务飞机和各类保障装备的状态更新,以完成整体甲板保障态势变更。
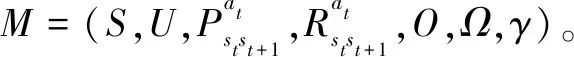
1)勤务保障状态集合:表示时刻所有可能的构成的集合;由时刻勤务保障场景内全部飞机信息、舰面环境信息、保障资源(即保障装备和人员)信息构成;全部飞机信息包含飞行甲板内每架飞机的编号、出动批次、放飞时机和状态标识符,其中,状态标识符含义为:0:闲置状态;1:勤务保障执行;2:故障维修;3:离舰飞行。舰面环境信息是指舰船甲板飞机保障阵位的状态信息,其中,每个勤务保障阵位具备状态标识符(0:该阵位上无飞机停靠; 1:该阵位上有正在执行勤务保障作业的飞机; 2:该阵位上有临时停放且处在闲置状态的飞机; 3:该阵位异常不可用)、阵位已被锁定标志符(0:未被锁定;1:已被锁定)、当前阵位上的保障飞机编号编码(若当前未停靠飞机,则编码为-1)和阵位可调用到的全部保障资源编号列表。

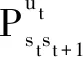
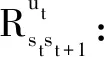
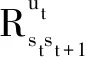

(2)
其中,,为权重系数,且+=1。和分别为从作业执行效率和飞机移动次数两方面,评估此指挥决策步骤所选阵位的优劣。
的计算方式如下:
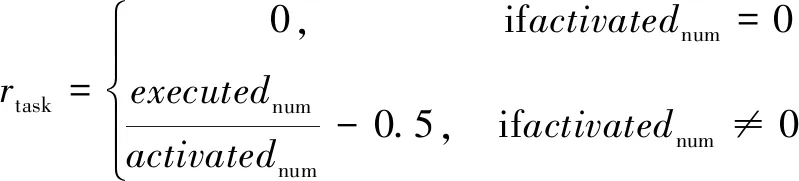
(3)
其中,为全部待保障飞机基于保障作业流程确定的满足时序激活条件的作业总数;为受所选阵位所能调用的勤务保障资源的限制,全部待保障飞机实际真正可执行的作业总数。的数值越高,说明待保障飞机在选定阵位上的多勤务作业并行执行效率越高。同时,对频繁执行目的地保障阵位迁移的指挥决策进行相应的惩罚,惩罚系数与飞机阵位移动总数目成负相关,计算方式为
=-(*)
(4)
其中,,,为预先设定的模型超参数。
5)局部保障观测函数:表示在状态执行决策动作后观测到的概率是(,,),即(××)→[0,1]。
7)为历史折扣因子,并且∈[0,1]。
2.2 指挥调度算法构建
本节将基于构建的勤务保障指挥与调度MDP模型,研究决策调度算法(以下简称为JMBZ-DDPG)构建过程。
JMBZ-DDPG算法是以MA-DDPG强化学习为基准模型,采用Actor-Critic框架完成模型训练及应用,其具有四个由深度神经网络(Deep Neural Network)构成的网络组件,分别是 Actor网络、Actor target网络、Critic网络、Critic target网络。Actor网络根据感知的舰船甲板勤务保障状态,为待保障飞机生成一个目的地阵位指挥决策动作,然后由Critic网络基于状态-动作映射函数估算一个Q值,作为对决策的阵位指挥动作的评价反馈。JMBZ-DDPG算法训练可划分为Actor阶段和Critic阶段,Critic阶段依赖Critic网络估算的Q值和实际决策执行后反馈的真实Q值之间的数学距离来进行网络系数的反向梯度优化,而Actor阶段依据Critic网络输出的Q值来指导更新指挥决策策略迭代。
JMBZ-DDPG算法采用了集中训练与分散执行的策略。在算法训练的Critic阶段,为实现更精准的Q值估算,智能体不仅仅能根据自身感知的甲板勤务局部观测信息,还能根据场景中其余智能体的观测及动作来评价确定的决策行为的价值。为此,Critic网络需要完整输入场景环境信息,具体是指场景内全部决策智能体感知的状态和输出的动作,这体现了集中训练的核心含义。分散执行指的是,待JMBZ-DDPG算法充分训练后,单一智能体即可依赖Actor网络,根据自身感知的局部勤务保障观测信息采取合适的阵位指挥决策动作,此过程无须显式构建通信链路,以获取其他智能体状态或者行为,保证了JMBZ-DDPG算法的易部署性。JMBZ-DDPG算法的训练学习流程如图2所示。
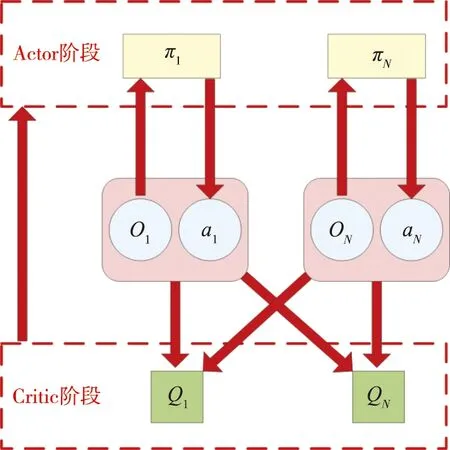
图2 JMBZ-DDPG算法的训练学习流程图
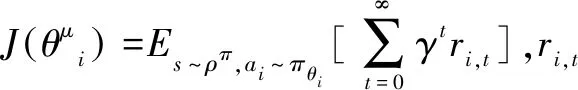
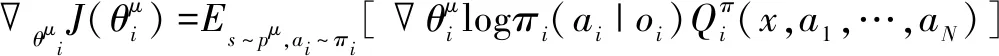
(5)
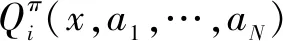
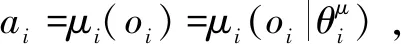
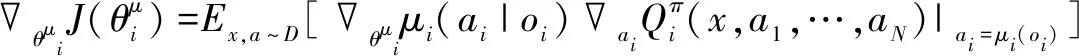
(6)
其中,是一个经验存储库,中的元素均为(,′,,…,,,…,)。
集中式的Critic网络参数更新策略借鉴了深度Q值网络(Deep Q Network,DQN)迭代策略中的时间差分(TD)与Target网络运用思想,计算Q值估计误差梯度如式(7)。
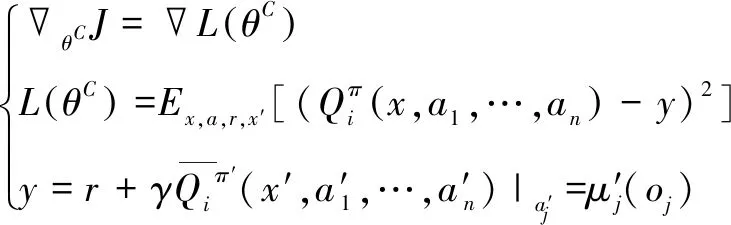
(7)
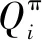
综上所述,JMBZ-DDPG算法实现的伪代码如下。

面向多机并行勤务保障指挥调度的JMBZ-DDPG算法随机初始化JMBZ-DDPG算法的Actor网络参数、Actor target网络参数、Critic网络参数、Critic target网络参数Num = 0for episode =1 to M do 初始化配套仿真环境,新建决策调度任务 获取初始舰船甲板勤务保障态势x=(o1,…,oN) for t=1 to max-episode-length do 针对每架待保障飞机i绑定的Agent, 基于Actor网络选定目的地保障阵位ai=μθioi()执行联合决策动作a=a1,…,aN(),利用仿真反馈生成当前决策步内的奖励r,并将勤务仿真环境推进至新的勤务保障态势x′存储x,a,r,x′()入经验回放池D更新勤务保障态势x:x←x′for Agent i=1 to N do 随机采样S个 (xj,aj,rj,x′j) from Dyj=rji+rQπ′ix′j,a′1,…,a′N()|a′k=μ′k(ojk) 利用时间差分策略更新Critic网络参数:∇θπJ≈1S∑j∇θπ[(Qπi(xj,aj1,…,ai,…,ajN)-yj)2] 利用确定性策略迭代策略更新Actor网络参数:∇θμiJ≈1S∑j∇θμiμioji()∇aiQπixj,aj1,…,ai,…,ajN()|ai=μi(oji) Num = Num + 1 end for if Num ≥ 100 And Num % 20 = 0 利用Actor/Critic网络参数更新Actor/Critic target网络参数θ′i←τθi+(1-τ)θ′i end if end forend for
3 仿真实验
本文利用飞机紧急返航作为保障场景,验证所提出的JMBZ-DDPG指挥调度算法的先进性和有效性。测试环境为一个包含18个飞机保障阵位、8架待保障飞机的舰船甲板仿真环境,其中8个阵位处于甲板着舰跑道干涉位置,另外10个阵位不与着舰跑道相交。8架待保障飞机依次停放在8个与着舰跑道相干涉的保障阵位上,即8架待保障飞机会受紧急返航飞机影响,无法正常执行勤务保障作业。在JMBZ-DDPG算法收到有飞机需要执行迫降的指令后,将立刻中断位于着舰跑道干涉阵位上飞机正在执行的勤务作业,并快速将这些飞机移动到JMBZ-DDPG算法指定的目标阵位,以继续完成待执行的勤务保障作业,从而确保在紧急返航飞机安全着舰的前提下,尽早完成受迫降干扰的其他飞机的勤务保障任务。
表2展示了此仿真测试环境中,与10个可用候选阵位相关联的保障资源列表。与表1所示的保障资源类型对应,Dev_1到Dev_8分别代表8种不同勤务作业执行所需的保障装备,Man代表专业勤务人员。表2中的通用阵位,代表该阵位上的飞机可单独调用一组包含上述所有装备类别的保障资源组。

表2 阵位与资源的关联关系表
8架待保障飞机在紧急返航指令下达时刻具有相同的勤务保障进度,即都未开展任何勤务保障作业,并都需要按既定保障流程执行所有勤务保障作业。
本文应用JMBZ-DDPG勤务保障指挥算法,在上述仿真场景下,快速生成可靠安全的多机勤务保障执行方案。由图3可知,随着训练迭代数的上升,JMBZ-DDPG算法的勤务指挥调度能力不断增强,即利用JMBZ-DDPG算法从仿真系统中获取的总调度反馈奖值随着算法迭代次数的增加而上升。
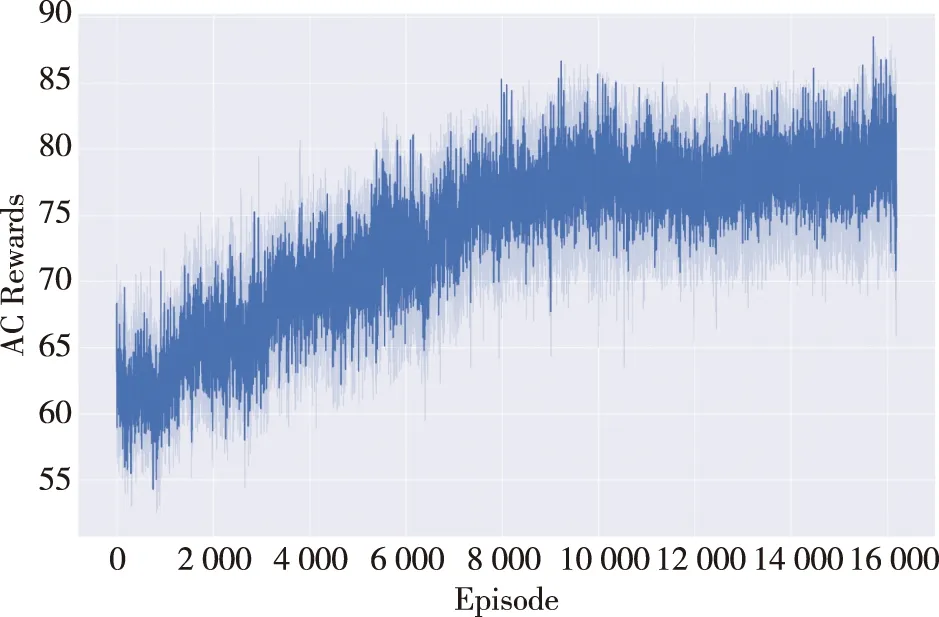
图3 JMBZ-DDPG算法的总调度奖励值随训练代数的变化趋势图
本文利用JMBZ-DDPG指挥调度算法,与多种其他成熟调度算法进行对比,展示了所提出指挥调度策略的先进性。对比算法如下:
1)FIFO规则式算法:先入先出调度策略,即先执行完上一保障任务的飞机先进行目标阵位选择;
2)LFL规则式算法:长任务优先调度策略,即剩余未完成保障作业最多的飞机先进行目标阵位选择;
3)PPO强化学习算法:运用独立强化学习(Independent Reinforcement Learning,IRL)多智能体调度框架和近端策略优化(PPO)调度策略的勤务保障决策调度策略。
本文将JMBZ-DDPG决策调度算法与上述三种成熟调度方法,均应用于8机重调度勤务保障指挥场景,获取保障计划甘特图如图4~7。
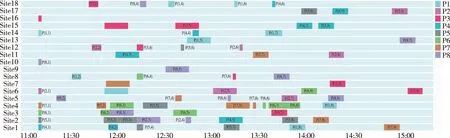
图4 FIFO策略下的保障计划甘特图(保障完成时长为246 min)
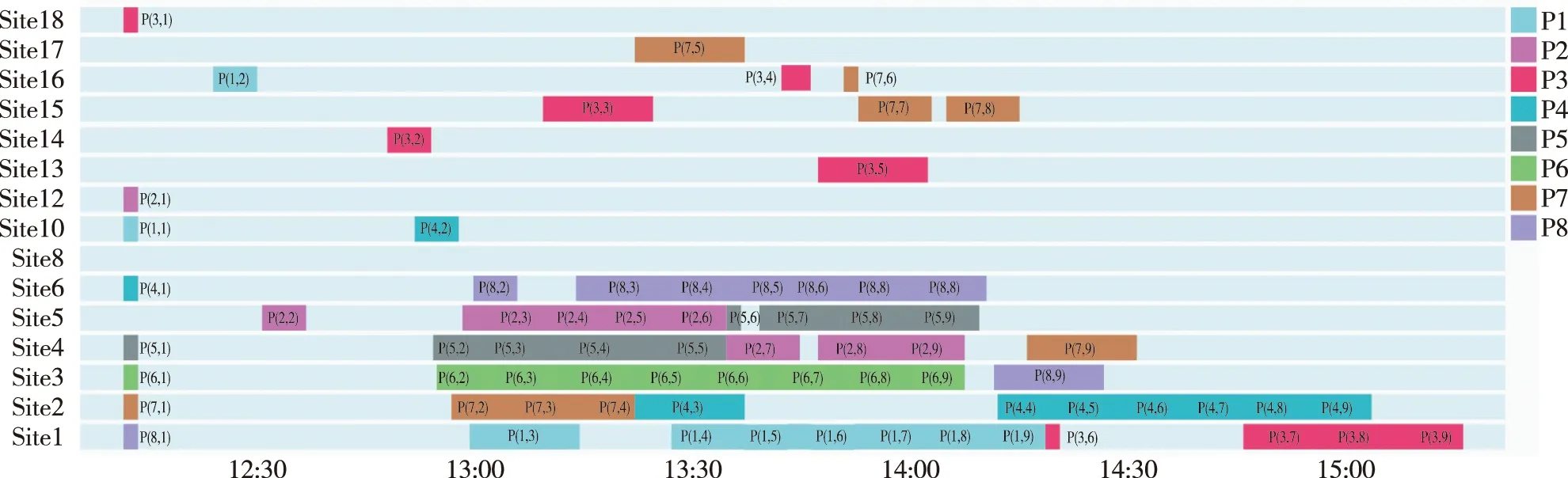
图5 LFL策略下的保障计划甘特图(保障完成时长为160 min)
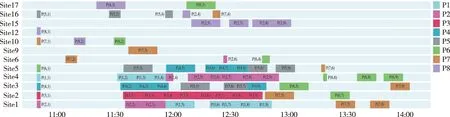
图6 PPO策略下的保障计划甘特图(保障完成时长为155 min)
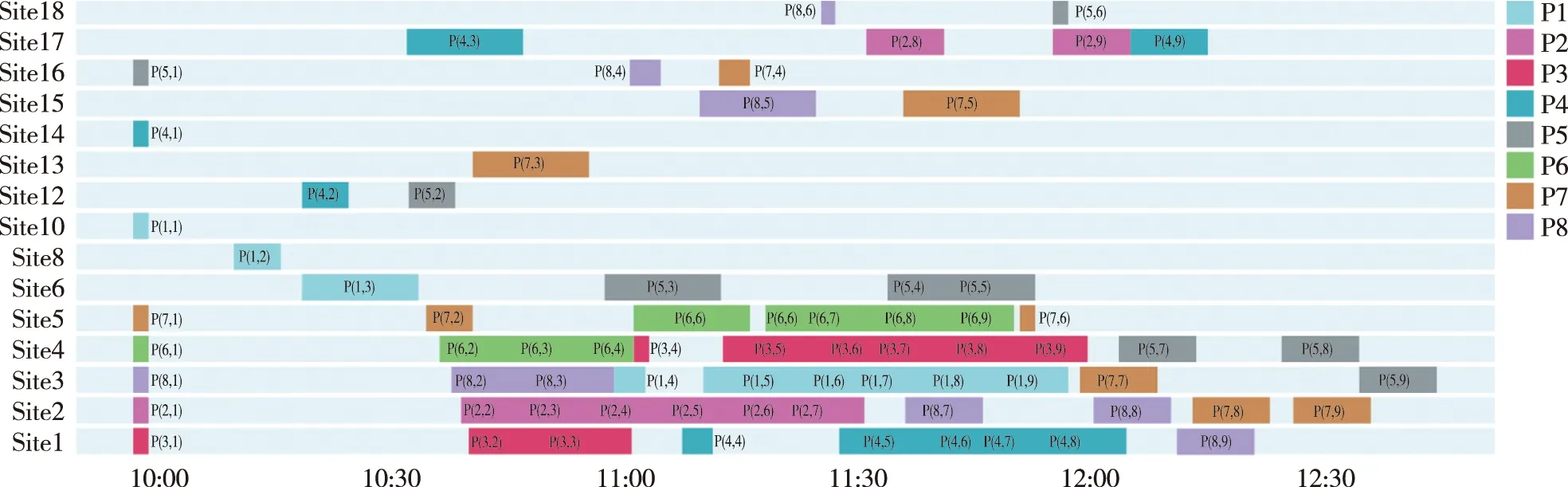
图7 JMBZ-DDPG策略下的保障计划甘特图(保障完成时长为140 min)
实验结果显示,针对8机勤务保障指挥场景,JMBZ-DDPG算法具备较优的决策调度能力,相较另外三种现存保障决策调度策略,性能分别提升了43%(相较FIFO)、12.5%(相较LFL)、9.7%(相较PPO)。
4 结束语
本文提出了一种高效、可靠的飞机勤务保障指挥与调度算法JMBZ-DDPG。JMBZ-DDPG算法能有效适应复杂、时空受限的勤务保障场景,将多智能体技术与深度强化学习有机融合,有效协调了多机并行保障可能存在的保障资源抢占现象。经与现存成熟调度方案的性能对比测试,JMBZ-DDPG算法能实现更优的勤务保障决策调度,并为后续开展自动化、智能化的勤务航空保障指挥决策系统研究奠定了基础。
