危化品领域专业分词库构建与应用研究*
2022-06-16蒋瀚
蒋 瀚
(中石化安全工程研究院有限公司,山东青岛 266104)
0 前言
自然语言处理(NLP)是计算机科学领域与人工智能领域的重要研究方向之一,主要围绕计算机与人之间使用人类语言进行有效通信的理论和方法展开研究[1],可实现对文档数据的深度挖掘和高效利用[2,3]。分词库作为自然语言分析处理技术的基础,其设计的合理性将影响整个分词系统的性能[4]。其中,专业分词库涵盖了该专业领域的专有名词词汇、词性、定义、同义词等信息,以其对专业领域较强的适应性,能够实现检索概念在数据库中最大限度的匹配,为专业领域文本挖掘与分析、行业领域知识图谱的建设[5,6]提供重要的大数据资源。
目前,医学、电气等领域已有专业分词库构建的研究[7,8],主要通过对现有专业数据库进行字段筛选与组合实现,而针对危化品安全领域的分词库研究尚无有效文献支撑。因此,需要从以下角度开展研究:①对所收集到的非结构化文本数据进行统一的预处理,从而提高分词准确率;②危化品安全专业术语具有多样性,例如组织机构全称和简称、化学品学名和俗名等,亟需针对性地设计词条结构;③设计合理的索引方式对词条进行组织,以适应现有词汇含义的变化及新专业词汇的加入[7],同时提高词条在专业领域内开展分析的针对性。
基于上述分析,以危化品领域文本资料为基础,采用结合机器学习分词结果与人工判读的方法进行新词提取,开展分词库词条和词表构建,研究词表、字数、词条三级树状结构的索引与编码方法,为面向危化品安全领域的自然语言处理技术奠定基础。
1 危化品专业语料提取
1.1 文本数据采集及预处理
作为专业词库的来源,文本数据采集的广泛性、全面性至关重要。危化品专业的文本数据主要有两个来源:
a) 从危化品领域相关信息系统中获取的文本数据,经收集整理、爬虫程序爬取互联网资源、文本批量去重及人工筛查4个处理环节,形成了结构化的字典表信息,能够直接作为词条加入到词库中,构成词库的基础。
b) 从危化品企业登记信息、危化品事故调查报告/事故详情等资源中获取非结构化的文档数据,需要通过文本预处理以挖掘专业词汇。对文本的预处理包括以下步骤:①将收集到的PDF、doc以及docx文档统一转换为UTF-8编码的文本文档,以便于计算机程序识别和分析;②去除文本长度小于所设置阈值的文档;③去除标点符号与“了”、“之”、“也”等汉语中没有实际含义的停用词,以达到减少噪声的效果。
1.2 基于机器学习算法分词结果的新词提取
传统的人工构建词库方法工作量大、主观性强,而单纯采用计算机算法则难以保证词库的专业性和可靠性[9],因此采取以机器学习算法为主进行文本分词、辅以人工筛选的方式进行危化品专业语料提取。
专业词汇的获取流程主要有2种。
a) 直接从其他系统的结构化表单数据中提取危化品安全相关专业词汇,如职业病、机械伤害、高空坠物等。所获取的专业词汇经添加词性项、初始化词频项后,可直接构成词条。
b) 应用THULAC[10]等预训练分词算法,将预处理后的文档数据进行分词,产生分词词汇,再由人工筛选出危化品相关专业词汇加入词库中。为减少分词词汇与已有专业词汇的重复录入,可将已有的专业词汇作为用户附加词典加入分词工具中辅助分词。
2 危化品专业词库架构设计与实现
词库的架构设计主要包括词条分类方法与组织形式的制定、各词表及对应词条索引模式研发、词库中词表调用机制的开发3方面内容。通过建立领域覆盖完善、分类方式合理、索引效率较高、调用逻辑正确的词库,能够有针对性的组合词表形成自定义词典用于文本分析,提升灵活性及基础数据的价值。
2.1 词库结构设计
词库主要由词表与词条构成,结构如图1所示。词表将词库划分为代表不同实体含义的若干类别。词表由若干词条构成,并以其所包含的词条的实体含义命名。

图1 专业词库的结构
词条为词库的最小数据单元,包括专业词、同义词、词性和词频4个属性。其中,专业词项即与危化品安全相关的词汇本身,同义词项包括专业词的简称及同义词汇,词频项统计基于本专业词库开发的自然语言处理应用所识别的词汇出现次数,词性项为根据专业词的特点划分的词类。
将收集的词条按其在危化品安全领域中所具有的实体含义进行分类。专业词库包含的词表为固定装置名称、机关处室全/简称、化工企业板块、人员公职、员工名称、中国行政区划、组织机构全/简称、事故类型等31类。
对形成的词表进行编号,然后对各个词表中的专业词汇按字数进行排序,形成词库标识树如图2所示。标识树的根结点不参与特征向量的构成,可任意定义。词库中所有的词表作为标识树的第一层节点,词汇的字数作为标识树的第二层节点,所有词汇作为叶子节点。
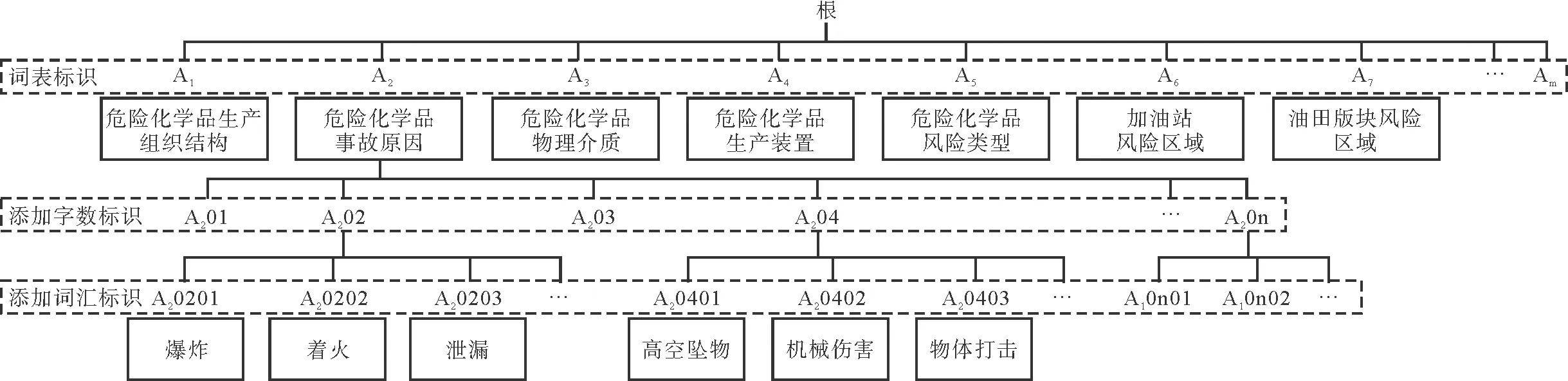
图2 词库标识树
2.2 词库特征向量索引构建
词库的特征向量索引由词库标识树得来。由标识树可构建词库的特征向量矩阵W,记为:
W=k*(k+m*n+m)
(1)
式中:k——词库中全部词条的数量;
m——词库中词表的数量;
n——词库中最长词汇的字数。
构建词条特征向量的策略为,对于某叶子节点,逐层向上搜索至根节点,将该叶子节点与经过的非叶子节点在向量对应列的值均写为1,其余列的值全部写为0,即可构成该词条的特征向量。按同样的方式,可将词库中所有词条的特征向量求出。将求得的特征向量堆积,每个词条的特征向量占一行,即可构成词库的特征向量矩阵W。
由于词条数量庞大,通过上述方法生成的特征向量维数(行*列数)很高,因此需要建立压缩与还原机制加快存取过程。对于特征向量为Aw(m1,m2,m3…)的词条w,压缩后词条的索引值Iw(n1,n2,n3)可由公式(2)得出:
(2)
例如,对于特征向量为M的词条a,由根节点出发搜索至a所经过的节点均已在a的特征向量中写为1,其余值均为0,如表1所示。词条a的索引值的含义则为,从左开始特征向量中所有非0数值的数位,使用公式(2)可求得Ia为(1,2,5)。反之,根据索引值的含义,可快速还原出词条的特征向量。

表1 词条a的特征向量M
根据建立的词库标识树,可以生成各个专业词条的特征向量,如图3所示。依据特征向量矩阵及计算公式,可以计算出词条的索引值分别为:爆炸(6,8,9),着火(6,8,10),泄漏(6,8,11),高空坠物(6,13,14),交通事故(6,13,15),自然灾害(6,13,16),非计划停工(6,17,18)。

图3 专业词条的特征向量
3 分词库应用与效果分析
3.1 应用jieba模型结合分词库建立分词模型
jieba是一个中文分词工具,其整体工作流程为:首先,将原始词典与用户自定义词典结合,生成Trie树,同时将每个词的出现次数转换为频率[11]。Trie树是一种前缀树结构,根据词语中汉字出现的顺序进行索引,其优势是检索速度较快。其次,将待分词的句子置于Trie树中查询,生成所有可能的句子切分,并采用有向无环图(DAG)记录句子中词语的开始位置和所有可能的结束位置。再次,确定句子中切分出的词语的出现频率,对于词典中已有记录的词语,则采用词典中最小的频率值作为该词的频率。最后,采用动态规划,对句子从右往左反向计算最大概率得到最大概率路径,从而得到最大概率的切分组合。
对于未记录在词典中的词,采用基于汉字成词能力的隐马尔科夫(HMM)模型[12]进行新词发现。HMM属于生成模型的有向概率图模型,通过联合概率建模:
(3)
式中:t——当前时刻;
S——状态序列;
O——观测序列。
HMM的解码问题为:
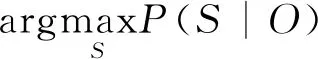
(4)

(5)
则用于HMM解码问题的Viterbi算法递推式为:
(6)
jieba分词模型将每一个字表示为B/M/E/S,分别代表出现在词头、词中、词尾以及单字成词。将B/M/E/S作为HMM的隐藏状态,连续的各个单字作为观测状态,其任务即为利用观测状态预测隐藏状态,采用Viterbi算法对HMM模型进行求解。
Viterbi动态规划算法的基本思想是,如果最佳路径经过点ε,则起始点到ε的路径一定是最佳路径[13]。假设从起始点到结束点经过n个时刻,整个过程可以划分为k个状态,则最佳路径一定经过起始点到时刻n中k个状态最短路径的点。则t时刻隐藏状态i所有可能的状态转移路径i1到i2的状态最大值为:
δt(i)=maxxi1,i2,…,it-1
P(it=i1,i2,…,it-1,ot,ot-1,…,o1|(A,B,π))
(7)
式中:A——HMM的转移概率矩阵;
B——HMM的观测概率矩阵;
π——HMM的初始状态概率向量。
根据公式(7)可由初始时刻依次向后计算出每一个时刻的最大概率隐藏状态,进而得到使最终时刻联合概率最大的路径。
3.2 分词结果及分析
结合来源于信息系统的结构化文本数据及专业文档的非结构化文本数据两方面数据,危化品专业分词库总计收录161 262个危化品安全专业词汇,根据其实体含义被分为31个词表。词库词表的统计明细如表2所示。

表2 词库词汇数量统计明细
基于目前形成的专业分词库,抽取其中的组织机构全/简称、危险化学品目录、事故简报等词条组合形成用户自定义词典,导入jieba模型对预留的验证集数据进行分词。在未加入专业分词库时,如聚氯乙烯、氯乙烯气柜、危险化学品、危险化学品重大危险源、企业名称等词汇均无法被正确切分。在加入专业分词库后,除部分复合型词汇,例如危险化学品重大危险源等,其他专业词汇均可被正确切分。可知,专业词库的加入能够有效提升专业领域文本的分词效果。
为进一步评估文本分词效果,建立定量评估指标包括准确率P、召回率R和F值。其中,P为算法正确识别的词数与分词得到的总词数的比值,R为算法正确识别的词数与实际词数的比值,F值为准确率和召回率的调和平均值,其计算公式如下:
(8)
假设人工分词的结果完全正确,将未使用专业词库的分词结果、导入专业词库的分词结果分别与人工分词的结果相比较,引入混淆矩阵分别计算准确率P、召回率R及F值,分词效果的评估结果如表3所示。与未加入专业词库的分词结果相比,导入专业词库能够使得分词的准确率P提升23%,召回率R提升33.9%,F值提升29%。
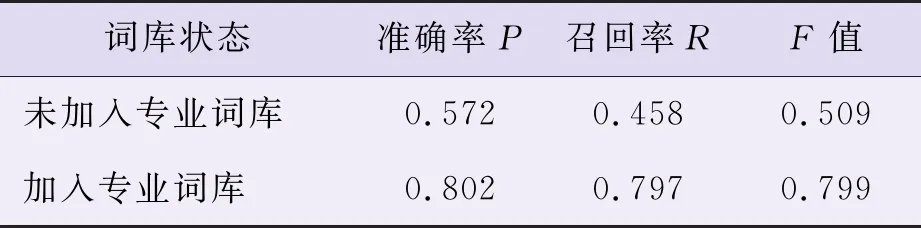
表3 分词结果的混淆矩阵评估结果
4 结论
通过整理获取大量的危化品文本数据库,采用基于机器学习分词结果与人工筛选整理相结合的方式提取专业语料,设计危化品安全领域专业词库的架构、内容和组织方式,形成了收录31个词表约16万词的专业分词库,同时构建了危化品安全领域专业词库的词向量计算与压缩方式。实验验证表明,所构建分词库能够提升危化品领域文本的分词效果,准确率、召回率与F值分别达到80.2%、79.7%及79.9%。虽然初步构建了危化品安全领域内专业词库,但从应用效果来看,词库的词汇数量、覆盖范围仍有提升空间。词库的建设是一个长期积累的过程,后续研究中将通过文本训练数据的丰富、词库应用过程中的错误反馈收集来不断进行词库的更新和完善。
