基于CRNN 和EnCTC 的英文手写体识别研究*
2022-06-16朱世闻
朱世闻
(南京邮电大学自动化、人工智能学院 南京 210000)
1 引言
目前离线手写体识别是OCR 领域的研究热点与难点,现在无纸化办公成为了社会发展的主流,比如票据识别[1],试卷自动批阅等,随着深度神经网络的不断发展,印刷体字符在自然场景中识别已经能够准确地识别出来[2~3]。由于每个人之间的书写风格存在差异,手写字符存在着文字的重叠、扭曲、粘连以及断开,这些导致了手写体字符识别率相对较低。
手写识别模型大多数的识别方法是利用CNN网络强大的非线性映射能力和特征表达能力,一般作为底层网络来对手写图像特征提取,然后利用不同的循环层和转录方法来完成对手写体的识别。Bhagyasree P V[4]等使用一个DAG 模型与CNN 混合神经网络来训练,将每一层的卷积的输出都输送到softmax 层,参与分类决策,这样就能够保证更多的原图片的决策信息。Sun[5]等使用全卷积网络(FCNN)进行图像特征提取,使用多维LSTM 作为递归网络单元,取得了不错提升效果。Chen[6]等使用能够同时进行脚本识别和手写体识别的多任务网络,它们使用LSTM 单元的变体SepMDLSTM 来作为递归网络。Sueiras[7]等通过CNN 提取图像特征后,利用BILSTM 网络进行编解码,最后以Attention 作为转录层。王鑫悦[8]等利用BILSTM 作为编码器,LSTM 作为解码器,在中间加入了Attention机制的结构来对中文手写进行识别。石鑫等[8]利用多层LSTM 形成堆栈式结构和CTC 转录层来对中文手写体进行识别,识别率也得到了提高。大部分学者在CNN或RNN的网络结构下在各自的手写数据集上都取得不错的效果[9~12]。还有不少学者在此基础上通过数据增强的方法来提高识别率[13~14]。
本文将手写体字符进行整体识别,避免了字符的分割,利用CRNN[3]的网络结构,它结合CNN 网络和RNN 网络各自的特性,在转录层使用了EnCTC[15]损失函数。同时也对图像数据进行增强,有助于神经网络更好地学习特定于手写图像的不变性,本文还使用合成数据集对神经网络进行预训练,有效地提高了识别精度,来提高模型的泛化能力。
2 模型设计
单词识别是将图像中的文本内容变成机器可理解的文本问题,本文采用CRNN的基础结构框架,但CNN 网络之前,插入空间转换网络层(STN)[16],之后接着卷积神经网络(CNN),在之后接着一个堆栈式的双向长短记忆网络(BiLSTM),最后以转录层结束,结构图如图1所示。

图1 整体模型网络结构
2.1 空间网络层(STN)
STN 网络是一个端到端的可训练层,它对输入端进行几何变换,从而矫正手写体因为手的移动而造成的字形的扭曲,从而弥补了CNN 网络容易受到数据空间多样性中的影响,该网络不要图像中关键的标定,能够根据训练过程中分类的结果自适应地将数据进行空间的转换和对齐,包括平移、缩放、薄板插条变换等几何变换,同时STN可以插入到卷积层任意一层,帮助CNN 能够更好地学习到图像的特征。
2.2 卷积神经网络层(CNN)
本文采用的卷积神经网络是VGG16[17]的深度神经网络,包括13个卷积层,13个激活函数层,4个最大池化层,去除了网络中的3 个全连接层,利用神经网络中的卷积层和池化对手写单词图像进行特征提取,形成特征序列输入到BiLSTM 中进行序列特征提取。激活函数采用的是Mish[18]激活函数,该激活函数相对于之前常用的RELU 激活函数能够对负值能够轻微的允许,使神经元学到更多的特征内容,也具有平滑的特性,平滑的激活函数能够使神经网络学到的特征信息更加深入,从而得到更好的准确性与泛化能力。Mish 激活函数曲线如图2所示。
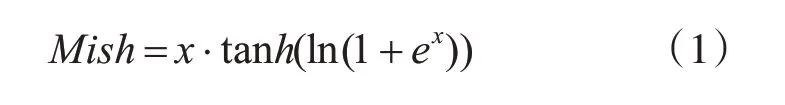

图2 Mish激活函数曲线图
2.3 循环层(BiLSTM)
本文采用的RNN 结构为双向长短记忆网络(BiLSTM),RNN 结构能够更好地获取单词内容的上下文本信息,从而提高识别率,长短记忆网络能够很好地解决RNN 本身存在梯度消失的问题。LSTM 由输入门it,遗忘门ft和输出门ot三个门控单元以及记忆单元组成,记忆单元负责储存过去的上下文信息,遗忘门负责选择丢弃记忆单元的上下文信息,读取当前细胞的输入值xt,和上层输出状态ht-1,当前输出ht计算出输入门it,输出门ft,和遗忘门ot的值:
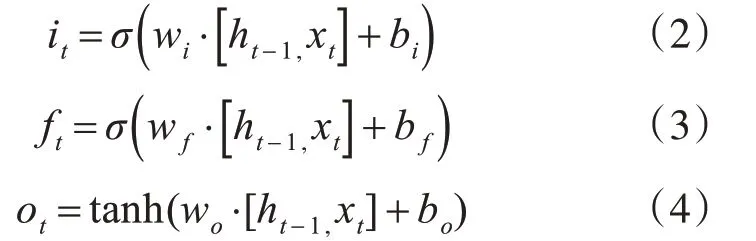
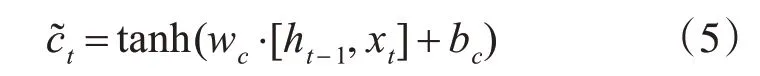
最后LSTM 的输出ht为输出门状态值乘以激活函数激活后的上下文状态ct:
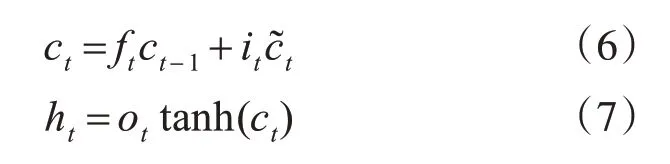
LSTM网络是单向的,LSTM都只能依据之前时刻的时序信息来预测下一时刻的输出,但在英文单词识别任务中,当前时刻的输出不仅与之前的状态有关,还可能和未来的状态有关系,还需要考虑它后面的内容,真正做到基于上下文判断。BiLSTM由两个LSTM 上下叠加在一起组成的,方向分别向前和向后,输出由这两个LSTM 的状态共同决定,本文采用的是双层双向的LSTM,在保证获取上下文信息的同时,通过加深网络的深度来提取更加深层的特征信息。
2.4 转录层
转录层采用的是基于最大熵的CTC改进算法[15],CTC[19]模型是手写识别常用的作于序列预测对其的模型,将双向LSTM 中的输出序列的预测结构转换成标签序列进行输出,并使得输出序列与输入序列对齐,CTC 引入空白标签blank进行参与预测,避免了图像的分割,实现端到端的识别,当数据进入CTC层时,假设数据的维度是L,在每个时间的数据预测有T 种可能性,共有LT种可能,每一种可能称为一个Path,条件概率公式(8)如下:
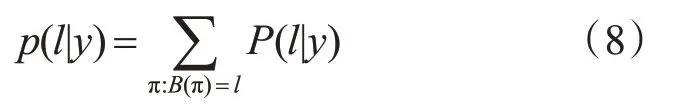
其中,y=y1,y2…yT-1,yT为输入序列,T 为序列长度,π 代表路径Path,l代表序列结果。
CTC 可以认为是多实例学习的一种,多条路径经过many-to-one 操作后输出相同的字符串,如果某条路径π 的概率较大,那么CTC会加强该路径直至占有所有路径的绝大部分,是一种正反馈的作用,且由于空白标签blank 在多数路径都存在,blank也会加强,直至充满主要路径,这种现象称之为CTC尖峰分布,尖峰的存在对路径的正反馈导致网络容易陷入局部最小值之中,也会对序列的分割造成影响,造成对齐不准确的情况。因此在CTC损失函数中加入最大熵正则项项来解决尖峰分布的问题,减少CTC 正反馈的影响,选择出最佳转录路径,提高训练过程中的探索能力和模型的泛化能力。CTC 的损失函数为式(9),Enctc 损失函数为式(10):
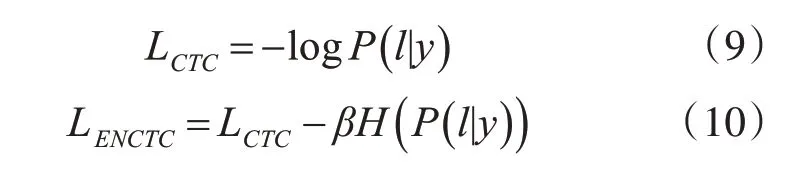
其中,β为比列系数:

3 实验验证
3.1 数据集
本文采用的数据集有IAM[20]英文手写公开集和采集的学生样本真实手写集,IAM 手写集来自657 位不同的作者,包括115320 的手写单词,本文采用数据中的分开好的训练集,测试集和验证集部分。学生真实数据集包括5000 个单词,其中4000个作为训练集,500 个作为测试集,500 个作为测试集。数据集样本如图3 所示。第一行为学生真实数据集,第二行为IAM手写集。

图3 数据集样本
3.2 数据增强和预训练模型
本文对训练集数据样本进行随机的旋转、缩放,平移,旋转的角度范围在5°之间,上下平移5 个像素以内,左右平移20 个像素以内,缩放的倍数在0.8倍到1.1倍,并随机加入少量的噪声。
深度学习模型往往有大量的带学习的参数,因此需要大量的数据来进行学习提高模型的泛化能力,防止模型过拟合。本文利用计算机合成和仿手写字体等方式进行数据合成,得到一个百万单词的英文手写体合成数据集,通过采集大量的手写体字母的基本元素根据单词的拼写顺序进行合成。同时本文在合成数据集上对数据样本随机加入高斯噪声、椒盐噪声、伽马变换等操作。在此数据集上进行预训练,得到预训练模型。
3.3 实验环境和设置
本文使用两块Nvidia GTX 1080Ti 11GB 显存GPU、双核CPU主频在4.2GHz以上,深度学习开发框架为PyTorch1.2.0 版本,开发语言为Python3.6 版本,GPU 并行环境为CUDA 10.0 版本、CuDNN7.0 版本。本实验所有图像高度统一缩放到32 像素,优化器算法使用Adam,同时由于网络结构较为复杂采用了Batch Normalization 的方法加快训练速度,学习率设置为0.0001,β设置为0.2[12],迭代次数为100次。
3.4 实验结果分析
CRNN1+CTC是文献[3]中的方法,采用的是原始的网络结构。CRNN2是将CNN 网络中的激活函数改变为Mish激活函数。
STN+CRNN2+CTC 是在上述结构的基础上,在卷积层之前加入STN层,并和上述实验应同样的方法。
STN+CRNN2+EnCTC是在上述结构的基础上,利用EnCTC损失函数替换CTC损失函数。
预训练+STN+CRNN2+EnCTC是在上述结构的基础上,先通过合成数据集的预训练,得到网络模型的参数,并在手写数据集进行参数的微调。
通过表1、表2 可以看出,STN 网络对输入图片的纠正的作用是明显的,但由于采集的真实手写集样本相对于IAM 公开集而言,字迹相对工整,字体扭曲的情况较少,在真实手写体上的提高不大,EnCTC 损失函数很好地解决了CTC 损失函数的尖峰问题,提高了模型在训练过程中的探索能力,从而提高了模型的识别率。通过在合成数据上进行模型的预训练能够提升训练速度,提高模型的识别性能,从数据集的角度来看,通过对数据集进行适当的平移,旋转,随机加入少量噪声等数据增强的方式来扩充数据集,可以保证CRNN 网络能够学到更多的特征信息,从而提高模型的识别精度与泛化能力。本文方法通过利用数据增强,预训练模型,STN 网络,更改激活函数和损失函数的方式。与原始算法相比,在IAM手写公开集上训练准确率提高了5.5%,测试准确率提高了5.1%。在真实学生手写集上训练准确率提高了2.21%,测试准确率提高了2.68%,提升效果还是很明显的。

表1 在IAM手写数据集上的研究

表2 在学生真实手写集上的研究
4 结语
本文在CRNN 结构的基础上,通过在合成数据集上进行模型的预训练,以及对手写集的预处理和数据增强,利用STN网络作为神经网络初始部分对扭曲图像进行矫正,有效地提高了卷积神经网络对特征的提取效果,从而提高识别效率,利用EnCTC损失函数很好地解决了CTC 损失函数存在的尖峰分布问题,抑制了由尖峰问题带来的正反馈的影响,同时也提高了模型的泛化能力,在IAM 手写数据集以及学生真实数据集两个数据上都显著地提高了识别效果,同时整体的网络结构是端到端的,减少了网络的复杂度。
