基于卷积神经网络的目标检测算法综述*
2022-06-16李炳臻姜文志顾佼佼
李炳臻 姜文志 顾佼佼 刘 克
(海军航空大学岸防兵学院 烟台 264001)
1 引言
目标检测作为计算机视觉的重要任务,用于在图像上检测特定类别的目标。近年来随着卷积神经网络[1]技术的成熟应用,目标检测发展迅速,在人脸识别、车辆识别等方面取得了广泛的应用。近些年来,应用比较广泛的的目标检测算法主要分为两个类别[2],它们分别是One-stage 与Two-stage 算法,算法过程中有无候选区域目标推荐的步骤,是它们两类算法间最大的区别。
Two-stage 算法,主要基于区域检测的基本思路,将检测过程划分为两个步骤[2~3]。首先,提取候选框的特征信息;然后,利用卷积神经网络(CNN)对候选框(ROI)位置进行分类(classification)与位置 回 归(bounding box regression)。 故 称 之 为“Two-stage”,较之于One-stage算法精度更高,但是速度较慢[4]。典型代表有R-CNN、Fast-RCNN、Faster-RCNN等。
One-stage 算法则根据回归的基本思路,利用用卷积神经网络(CNN)的卷积特征,得到待检测目标的信息参数,包含所属类别概率值与位置坐标值,结构更加简洁,具有有更快的检测速度,典型算法有YOLO V1/V2/V3、SSD、DSSD等。
2 Faster-RCNN算法
2.1 前任算法
2.1.1 RCNN
RCNN[5]是将CNN(卷积神经网络)应用到目标检测领域的开山之作,由美国工程师Ross Girshick于2013 年提出。采用Selective search[14]方法提取目标图片的候选区域[7],再利用CNN提取候选区域的特征,完成目标检测。整个过程分为四步:
1)采用Selective search 对输入图像提取约1~2千个候选区域;
2)候选区域wrap(缩放)成统一大小输入CNN,提取特征;
3)将上一步提取出的特征送入每一类的SVM分类器,判断是否属于该类;
4)使用NMS(非极大抑制)排除重叠的候选框,再使用Bounding-box regression(线性回归模型)修正候选框位置[8]。
RCNN网络结构如图1所示。

图1 RCNN网络结构图
RCNN 的创新点:1)采用Selective search 生成候选区域再检测,降低信息冗余度;2)首次采用CNN 提取特征,特征提取更充分提高了检测精度。缺点:1)每个候选区域都要通过卷积网络提取特征,速度较慢;2)wrap操作会改变图片形状,对检测精度产生一定影响。
2.1.2 SSP Net(Spatial Pyramid Pooling Net)
为解决wrap后图片形状改变的问题,SSP Net[9]应运而生,它最大贡献是输入任意尺寸的图片都会得到固定大小的输出。
设计思想是在卷积层与全连接层之间加入某种结构,使得输出特征满足全连接层的输入大小,这个结构就是SSP。RCNN 与SSP Net 的流程对比如图2所示。

图2 RCNN与SSP Net流程对比图
卷积层后加入的SPP 层,可将任意尺寸的输入按比例转化为一些固定维度的bin,再对每个bin做池化[10],并输入全连接层。应用到目标检测如图3所示。
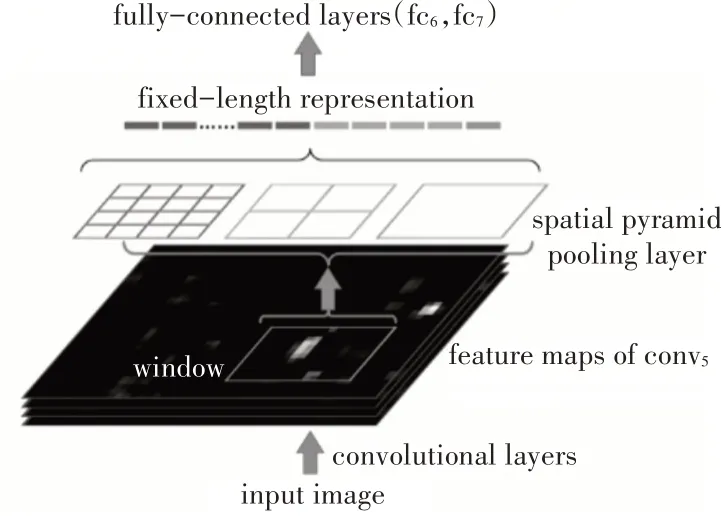
图3 SSP应用于目标检测示意图
SSP Net 的创新点:1)加入SSP 层,使得图片输入的大小可以是任意尺寸;2)只需对输入图片提取一次特征,提高了检测速度。缺点:相比于RCNN,本质并没有发生改变,检测精度没有很大提升。
2.1.3 Fast RCNN
Fast RCNN 采用了SSP 的思想对RCNN 进行了改进。图4给出了Fast RCNN[11]的网络结构图。
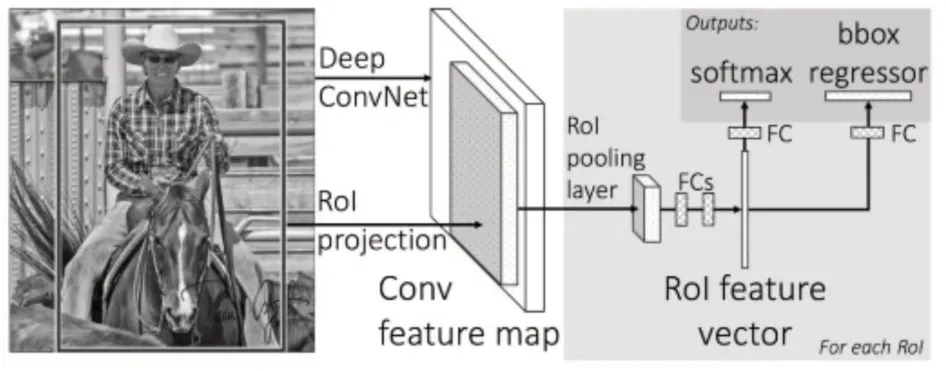
图4 Fast RCNN网络结构示意图
简要流程分为四步:
1)采用Selective search提取候选区域[12];
2)将图片输入CNN,并把候选区域映射到到conv5的feature map上,输出卷积特征图;
3)特征图中的候选框经过ROI 池化层进行池化得到固定长度的特征向量,输入全连接层[13];
4)全连接层后分成两个分支,一个采用softmax做分类;另一个采用Bounding-box regression做定位。
Fast RCNN 创新点:1)卷积层加入了ROI pooling 层(SSP Net 精简版);2)使用multi-task loss(多任务损失函数),并将Bounding-box regression 加入到CNN 网络中进行训练[14];3)使用softmax 分类器代替SVM 分类器;整个检测过程都在一个网络中进行(Selective search除外)速度和精度都有了大幅度的提升。
2.2 Faster RCNN设计思想
Fast RCNN 仍然采用Selective search 生成候选区域,耗时耗力。为此,Faster RCNN专门针对这个缺点,在算法中引进了Region Proposal Networks(区域检测网络),也就是大名鼎鼎的RPN 网络,用来替换原来的Selective search 方法,专门用以生成待检测目标的候选区域[15],同时在算法中加入了新的概念——anchor box。换句话说就是Fast RCNN 使用了一个单独的卷积神经网络,专门用来进行候选区域的特征提取,同时将这个网络与之前的主检测网络一起进行大数据训练与目标检测,提高训练效率。
Faster RCNN最大的创新点就是引入了RPN网络,其本质是通过卷积神经网络生成候选区域,并输出目标候选框矩阵及得分[16],网络示意图如图5所示:卷积核就是滑窗,每个滑窗位置对应输出k个候选框的信息,2k个分类信息,4k个坐标信息。
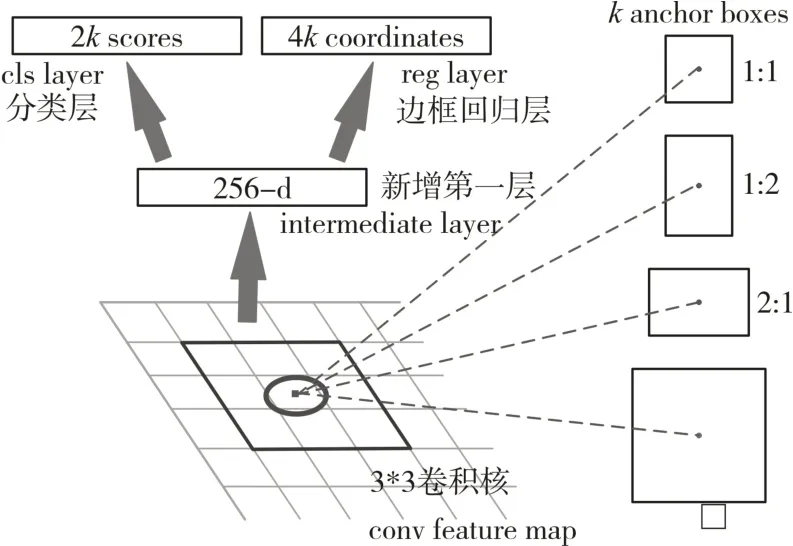
图5 RPN网络结构示意图
前文及图中提到的anchor 在本质上是一组形状、大小均固定的模板或者称为参考窗格。根据它们的面积比例,首先可以分成三组,面积分别为128*128、256*256、512*512。而在这三种面积中,每一种面积根据长宽比例的不同(1∶1、1∶2、2∶1),又可以分为三组,总共的分类就是九个,如图6 所示。
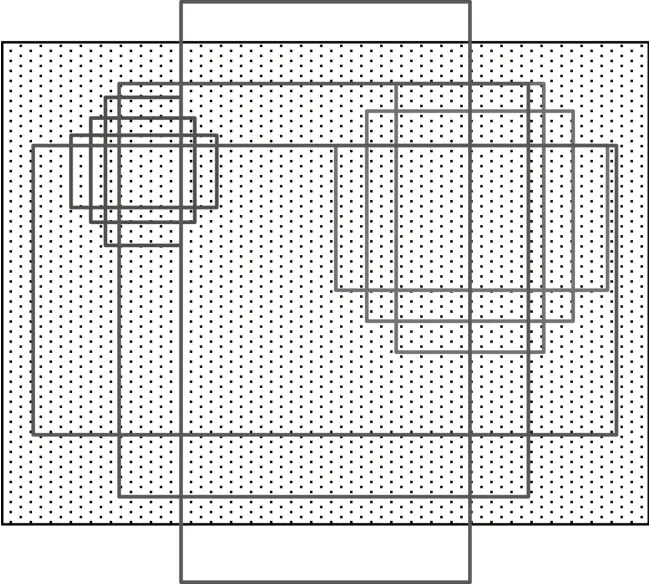
图6 anchor示意图
对于每一个窗格,可以采用计算anchor的中心点所对应原图的中心点,可以通过anchor中心点与anchor的大小得到窗格位置同原图的映射,RPN 网络可以通过这种映射得到这个anchor 中是否包含待检测目标。
2.3 Faster RCNN网络架构
网络架构如图7所示。

图7 Faster RCNN网络结构图
Faster RCNN算法具体的检测步骤如下。
1)网络结构中的卷积层,首先提取输入图片的特征,生成特征图(feature map),然后将这个特征图输入后续的网络,同时输入RPN 网络,使得后续的网络与RPN网络共享卷积特征;
2)根据前一步得到的特征图,RPN网络生成初步的检测目标候选区域,同时输出候选框信息参数;
3)特征图接下来输入到网络中的ROI pooling层,该层对特征图与上一步RPN 网络传输的候选区域进行池化的操作,并将池化操作后的图片输入网络的全连接层;
4)根据前一步得到的候选区域及特征图,全连接层对候选区域进行类别分类,接下来进行检测框的回归,也就是bounding box regression,然后得到最终检测框的参数信息,具体为检测框在图片上的位置信息与分类的类别得分。
需要特别注意的是,对于网络的训练过程,Faster RCNN 需要训练两个网络,一个是用来生产候选区域的RPN 网络,另一个则是分类网络;一般情况下采用交替训练的方法,即在一个batch size中,首先训练RPN 网络,再训练分类网络。此算法的优点是使用RPN 生成候选区域,减少冗余计算,提升了精度与速度。
3 YOLO V3算法
YOLO V3 是one stage 算法的典型代表,是YOLO(You Only Look Once)系列算法的第三代。其核心思想是将目标检测问题看做回归问题求解,检测速度快是其最大特点。
3.1 前任算法
3.1.1 YOLO V1算法
在YOLO V1[17]中,将图片划分成S*S 个网格,每个网格直接预测B 个Bounding boxes 信息,YOLO V1 借鉴了GoogleNet[18]的网络设计,但用1×1 和3×3 卷积层替代了GoogleNet 中的24 个卷积层和两个全连接层[19],网络结构如图8所示。

图8 YOLO V1网络结构图
YOLO V1的损失函数为
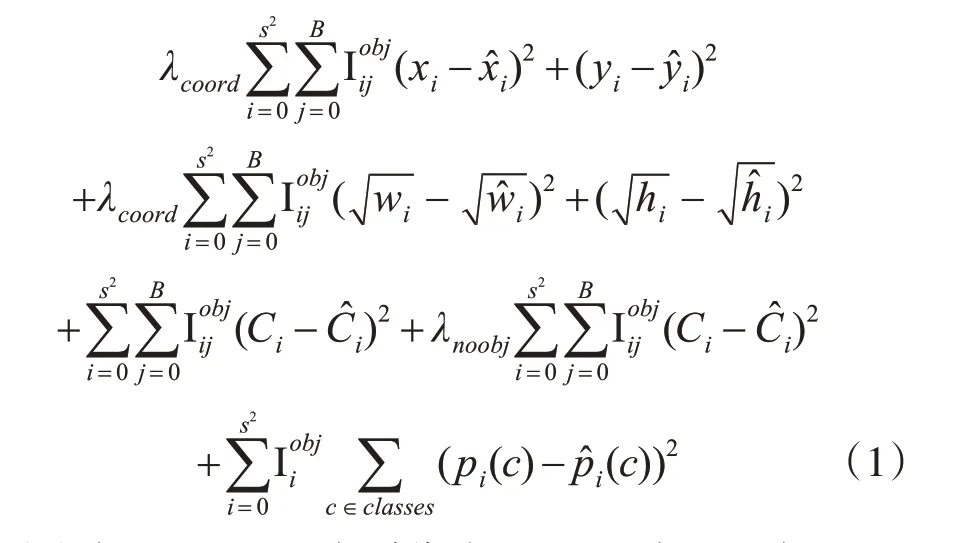
式(1)中x,y,w,h分别代表Bbox 的中心坐标对于网格边界的相对值以及长宽比例值,S,B代表图片的网格数以及Bbox 数,判断第i个网格中第j个Bbox 是否包含检测对象;判断是否有物体中心落在第i个网格中;式(1)中前两行代表坐标预测,第三行分别代表包含物体的box 的置信度预测以及不包含物体的置信度预测,最后一行是类别预测。
YOLO V1 的检测速度很快,对于背景图像的误检率低,但识别物体的准确度比较差,其将目标检测看作一个回归问题求解为目标检测算法的发展提供了思路。
3.1.2 YOLO V2 算法
针对YOLO V1 的不足之处,YOLO V2[20]做了相应的改进。基础网络采用DarkNet-19,包含大量卷积,并采用1*1 卷积核用以压缩特征,砍掉全连接层,采用anchor的思想等。具体采用的改进方法以及描述如表1所示。
从表1 可以看出,Batch normalization(BN)使得mAP 提高2%,即在卷积后加入BN 层,归一化下一次卷积输入的数据。能够加速训练收敛,增大了有效迭代次数;采用High Resolution Classifier,提升输入的分辨率,使得mAP 提升了4%;采用Dimension Clusters 通过k-means 的方式对训练集的Bboxes 做聚类,以找到合适的anchor box;Direct location prediction 则是采用YOLO 算法中直接预测坐标位置的方式。结合这两项anchor box 改进方法,mAP 获得了5%的提升。

表1 YOLO V2技术改进及对应的mAP值一览表
3.2 YOLO V3网络架构
YOLO V3[21]重新设计了网络结构,采用logistic取代了softmax 完成对象分类任务,性能的提升。网络结构图如图9所示。
图9 中下方的a,b,c是为网络图做的解释图;a中的DBL 是YOLO V3 中的基本组件DBL=卷积+BN+Leaky relu(激活函数);ResN 是YOLO V3 中的大组件,N代表代表有N个Res_unit,具体组成由b,c 所示,基本构件也是DBL;concat 代表张量拼接,将Darket中某一层和后面一层的上采样进行拼接,扩充张量的维度;整个YOLO V3 模型中没有池化层和全连接层,张量尺寸的变换是通过改变卷积核来实现的。
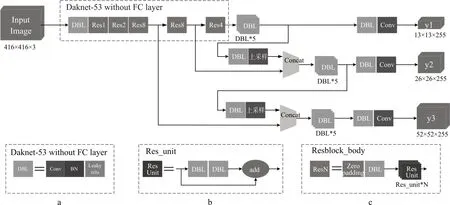
图9 YOLO V3网络结构图
3.3 YOLO V3特点分析
YOLO V3 采用多尺度预测以提高检测精度,如图9 所示卷积后分为三个尺度:尺度1 在基础网络之后,增加了一些卷积层,输出box 信息;尺度2从尺度1 的DBL 之后经过上采样再与基础网络的特征图进行张量拼接,卷积后输出信息;尺度3 与尺度2 类似;并且YOLO V3 采用logistic regression取代softmax 预测类别得分,softmax 的分类基于类别相互独立,但某类物体可能属于不同的类别,因此softmax 不适用于多标签分类,而logistic regression 则预测每个类别的得分,并设定一个阈值,高于阈值分数的就是真正的类别,能够提升算法的准确度。
YOLO V3 优点:一是基于端到端的网络模型,简洁高效,训练与检测速度非常快;二是背景误判率低;三是通用性强,工程上应用广泛。缺点:一是漏检率比较高;二是识别物体位置精准性较差。
4 SSD算法
4.1 设计思想
SSD 同时借鉴了Faster RCNN 与YOLO 的设计思想[22]:SSD 借鉴YOLO 中基于回归的模式,直接回归出物体的类别和位置;同时采用Faster RCNN中区域的设计思想,生产尺度不一的特征图用于检测目标,其中尺度大的特征图在网络结构中生成位置比较靠前,对于小目标的检测效果很好;而尺度比较小的特征图,在网络结构中生成位置比较靠后,对于大目标检测效果很好。除此之外,SSD 还根据尺度与长宽比不同的先验框进行初步检测。值得一提的是,这个先验框,在Faster RCNN中就是前文提到的anchor。
4.2 SSD网络结构
SSD 的主干网络结构是VGG16(也可以采取VGG,ResNet,MobileNets等来代替),网络结构如图10所示。从图中可以看出,SSD利用了多尺度特征图进行目标检测。
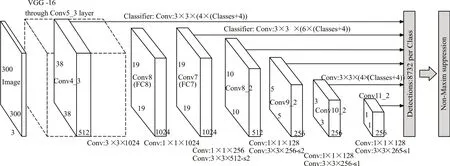
图10 SSD网络结构图
SSD 将VGG16 中最后两个全连接层及输出层替换成卷积层,并在最后又额外增加了四个卷积层。这样一来,就增加了网络提取目标特征的能力。其中,用于目标检测的第一个特征图是由主干网络VGG16中的卷积层Conv4_3提取得到的,后续五个特征图,分别是由网络后续的卷积层提取得到的,网络中总共提取了6个卷积特征图,其大小分别是(38,38)、(19,19)、(10,10)、(5,5)、(3,3)、(1,1)不同特征图设置的先验框数目不同。各个特征图的先验框尺度分别为30、60、111、162、213、264。对特征图进行卷积操作,得到进一步的检测结果,检测结果同其他检测算法得到的检测结果类似,包括两个部分,分别是类别置信度也就是分类分数与检测边界框的位置信息,在这些信息的基础上,再分别采用一个3×3 的卷积来进行优化检测,最后再使用NMS(非极大抑制值)得到边界框的最优解。
SSD 创新点:1)采用多尺度特征图,在SSD 中,不仅在最后一个特征层产生anchor,在之前的几个高层特征层中也会产生anchor,特征层依次递减,低层特征对应于细节信息,用以检测小目标,而高层特征则对应于抽象的语义信息,用以检测大占比目标,可以使得SSD能够检测不同尺度的目标。2)在检测过程中采用了先验框的检测方法,采用大小与长宽比不同的先验框作为检测结果中最终检测框的基准,这种检测思路在降低了网络训练的训练难度。
缺点:用于小目标检测的低层卷积仅有一层Conv4_3,因此小目标检测效果较差。
4.3 改进算法
DSSD[23]是SSD 改进算法中效果最为显著的一个,在VOOC2007上,mAP值达到了81.5%,fps只有6fps;DSSD基础网络采用Resnet-101[24]代替VGG16,提高特征提取能力;并在SSD添加的辅助卷积层后又添加了反卷积层形成“沙漏”结构,对小目标的检测度上有了很大的提升,图11 给出了DSSD 的网络结构图。
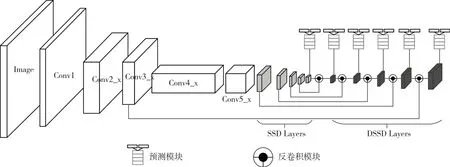
图11 DSSD网络结构图
图中的浅色部分是在基础网络的基础上添加的辅助层,深色部分是DSSD添加的辅助层,将其反卷积之后并与对应卷积层中的语义信息相融合再送入上面Prediction Module 模块进行分类回归,并输出信息。
创新点是预测模块和反卷积模块,预测模块用于提取更深维度的特征用于分类回归;反卷积模块则更充分利用浅层的特征,使小目标和密集目标的检测率上有很大的提高。
5 结语
基于深度学习的目标检测算法中,最经典的无异于Faster RCNN、YOLO V3 以及SSD 算法,Faster RCNN 毫无疑问是检测精度最高的,但速度确比不上其他两种算法;SSD 速度和精度都不差,但是对小目标检测效果却不好;YOLO V3 速度快,易上手,在工业检测方面应用十分广泛。目前各类新的算法层出不穷,但是大都是基于经典算法之上改进而来。
虽然目标识别发展迅速,但某些问题仍然得不到很好的解决:比如小目标物体的检测,由于小目标物体在图像中分辨率低、信息量少,因此还没有针对小目标物体检测效果较好的算法出现。除此之外还有被遮挡的物体、在环境干扰下的目标识别问题等,都是仍然存在的难题。而当目标检测应用到实际情况中时,如何获取清晰全面而又高质量、高数量的数据集以满足训练模型的需要也是一大难题。
目标检测技术未来的发展方向:1)应用在生产生活中时如何将能耗降低;2)如何集成化、定制化的应用到不同需求的产业上;3)实际应用中,如何在检测精度与速度间取得绝佳的平衡等这些都是目标检测技术的发展方向。
