基于多尺度注意力引导的遮挡行人检测方法*
2022-06-16谢东军刘志刚刘苗苗
谢东军 刘志刚,2 黄 朝 田 枫 刘苗苗
(1.东北石油大学计算机与信息技术学院 大庆 163318)(2.东北石油大学应用技术研究院博士后工作站 大庆 163318)
1 引言
随着深度学习应用研究的深入,行人检测的性能有了较为明显的改善,在很多实验场景下开始尝试应用到安防监控、辅助驾驶、应急救援等领域。但真实场景中,受遮挡、视角、光照等多种因素影响,行人检测距离工业化的应用还存在很大距离。
与其他因素不同,遮挡会在行人的表征特征中引入噪声干扰,是直接造成精度下降的重要原因,该问题近年来引起了国内外学者的广泛关注。文献[1]提出一种多标签学习方法联合训练身体不同部分检测器以捕获多种遮挡模式。文献[2]利用遮挡行人目标可见部分估计分支和全身估计分支进行联合学习,产生的互补输出可以进一步融合以提高检测器性能。文献[3]提出一种遮挡感知池化单元,将人体先验信息与可见区域信息集成到检测网络。文献[4]提出一种全新的排斥力回归损失函数,使预测框尽可能接近真实目标框,远离干扰目标框。文献[5]提出利用通道注意力机制来处理不同的遮挡模式,这是注意力机制首次用于遮挡行人检测领域中。文献[6]提出逐级定位拟合策略,以单阶段检测器SSD[7](Single Shot Multibox Detector)为基础,将默认锚框(anchor)逐步演化为精确的检测结果。
但是,上述均为基于锚框(anchor-base)的行人检测方法,在检测过程中需要生成大量anchor,导致参数量过大,影响检测速度。近年来,基于关键点的无锚框(anchor-free)检测方法为行人检测领域提供了新思路,文献[8]提出的CornerNet以及文献[9]提出的CenterNet 都是利用关键点回归直接预测边界框,解决了生成大量anchor所带来的参数冗余问题,使模型更加轻量化。2019 年,Liu Wei[10]等提出一种基于anchor-free 的中心点和尺度预测(Center and Scale Prediction,CSP)行人检测方法,直接通过生成行人目标中心位置和尺度对目标边界框进行预测。CSP 对常规场景下的行人目标有着很好的检测效果,但是它并没有重点解决行人检测中的遮挡问题。
综上,本文以CSP 作为基础网络架构,提出一种专注于遮挡问题的注意力引导模块,引导网络模型关注遮挡行人目标的可见区域,削弱遮挡部分对网络模型特征提取过程带来的影响,增强行人特征的抽取与表征,提高对遮挡行人目标检测的准确度。通过多次迭代,所提出模块可以具备两个优点:一是增强行人目标可见部分区域的特征判别力;二是学习全局特征,提升模型泛化能力。
2 相关理论
CSP 是anchor-free 在行人检测领域的首次应用,并取得了良好的检测效果。该方法的网络结构主要分为两个部分:特征提取部分和边界框预测部分。
特征提取部分使用ResNet50[13]进行特征提取,卷积层分为五个阶段,下采样比例分别为2、4、8、16 和32。其中,为了保证深层特征图的高分辨率,通用做法[14]是利用空洞卷积,保持第五阶段的下采样比例为16。此外,为了兼顾浅层特征图的位置信息和深层特征图的语义信息,需要对不同尺度特征图进行融合。该方法经过实验验证,选取第3、4、5 层特征图进行通道维度的特征拼接生成用于边界框预测的多尺度特征图,并且下采样比例为4时,模型检测性能最优。边界框预测部分首先利用3×3 卷积核降低输入特征图的通道数至256,之后利用三个1×1 的卷积核分别生成目标中心位置特征热图、尺度预测图以及中心位置偏移量预测图,最终,利用中心位置和尺度,通过简单几何运算得到目标检测框的大小。
CSP 的总损失表示为L,由中心预测损失、尺度预测损失和中心偏移回归损失加权相加得到,损失函数如式(1)所示:

其中,λc、λs和λo为对应损失平衡权重因子,分别设置为0.01、1和0.1。
3 所提方法
3.1 模型设计
为了进一步处理行人检测领域中的区域遮挡问题,设计一种针对遮挡问题的多尺度注意力引导模块(Multi-scale Attention Guided Block,MAGB)。所提方法以CSP作为基础架构,在经过特征提取过程后,引入多尺度注意力引导模块进行注意力特征调制,增强特征图目标可见区域特征表现力,为后续边界框预测部分生成行人目标中心位置,高度以及中心位置偏移量提供更为准确的分类引导。关于多尺度注意力引导模块,将在3.2 节中详细阐述。所提方法总体网络结构如图1所示。
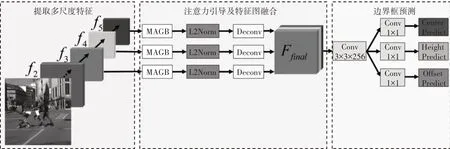
图1 模型总体网络结构图
3.2 注意力引导模块
注意力机制在特征提取阶段可以引导网络模型更好地关注特征中有用的信息,抑制无用的信息,让网络模型自动调节关注位置,提升特征提取能力。近年来,注意力机制对计算机视觉领域产生了重要影响,被广泛应用于目标检测[15]、图像分类[16]、语义分割[17]等任务中。
受到注意力机制的启发,为了提高网络模型对遮挡行人目标的检测效果,本文提出一种基于多尺度的注意力引导模块。该模块主要是对不同尺度特征图的注意力特征进行空间域的调制,利用预处理的行人目标可见区域标注作为外部监督信息,使网络模型将注意力主要聚焦于遮挡行人目标可见区域,充分提取有限的行人特征,抑制无用的遮挡部分特征,提高边界框预测的精确性。多尺度注意力引导模块整体结构如图2所示。

图2 多尺度注意力引导模块结构图
多尺度注意力引导模块的输入是不同尺度的特征图fn,在通道维度上对其分别进行最大池化(Max Pooling)与平均池化(Average Pooling),之后利用一个3×3 的卷积核进行特征平滑操作,并通过sigmoid 激活函数输出得到空间自注意力图Matt,其中Matt中每个像素强度与特征判别力成正比。然后,设置目标可见区域注意力增强分支,该分支利用行人目标边界框标注作为外部监督信息,生成目标可见区域注意力增强图Mvis,具体如下。
1)对数据集进行预处理,将行人目标边界框可见区域像素值置为1,全身区域像素值置为γ,其中γ的值为0~0.5 间的随机值,背景区域像素值置为0。对γ这样设置的原因是为了在边界框预测阶段能够得到更为准确的中心位置真值,即抑制遮挡区域特征影响的同时,也要对其进行像素值弱化保留;
2)引入可见区域像素值损失Lvis指导模型重点关注行人目标可见区域。Lvis为二分类交叉熵损失函数,表示预测像素值与标签像素值之间的损失,可以通过式(2)得到:
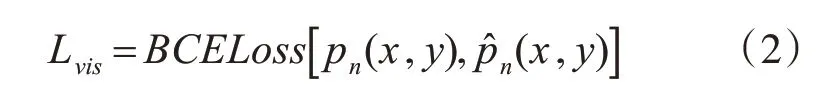
其中,pn(x,y)表示行人目标标注对应位置像素,表示目标可见区域注意力增强分支产生的对应位置预测像素。通过可见区域像素值损失Lvis,遮挡行人目标可见区域与全身区域的像素值将会分别趋近于1 和γ,引导网络模型重点关注行人目标可见区域。
然而,在模型的每次迭代训练过程中都应用目标可见区域注意力增强分支,将会造成网络模型对外部监督信息的过度依赖,导致模型泛化能力变弱。为解决此问题,将该分支得到的目标可见区域注意力增强图Mvis以空间相加的方式作用于自注意力图Matt,所得到的全局注意力图Mglobal不仅增强了行人目标可见区域特征,同时并未完全摒弃背景特征,这种处理方法会更好地抑制模型对外部监督信息的依赖,从而提升模型泛化能力。最终,将全局注意力图Mglobal以空间点乘的方式作用于输入的特征图fn得到最终特征图Fn。
引入多尺度注意力引导模块后,网络模型的总损失表示为Lfinal,将可见区域像素损失Lvis与式(1)提到的中心预测损失、尺度预测损失和中心偏移回归损失进行联合优化训练,损失函数如式(3)所示:

其中λv为可见区域像素损失平衡权重因子,为了突出多尺度注意力引导模块在整体网络模型训练中的作用,本文将其设置为1。
4 实验分析
4.1 实验设置
实验环境:所用服务器配置为Intel Xeon(R)E5-2640 CPU、8G 内 存 和NVIDIA RTX2070Super GPU。算法主要基于Pytorch深度学习框架实现。
数据集选择:为了验证本文所提方法的可行性,分 别 使 用Citypersons[11]行 人 检 测 数 据 集 和Caltech[12]行人检测数据集进行相关实验。
评估标准:为了验证网络模型的性能,使用每张图片的误检率(False Positives Per Image,FPPI)介于[10-2,100]之间的对数平均漏检率(Log-average Miss Rate,MR-2)作为模型评估标准。MR-2的值越低,说明网络模型的检测性能越好。
参数设置:利用随机水平翻转,随机裁剪等技术对数据进行增强扩充,提高数据集多样性。利用Adam方法进行参数优化,使用平均权重移动策略[18]控制梯度下降过程,初始学习率设置为2×10-4,Batch Size设置为2,共训练120个Epoch。
4.2 MAGB消融实验分析
为了验证MAGB 对遮挡行人目标检测的有效性,消融实验以CSP 作为测试基准(Baseline),将通用注意力模块SENet[15],CBAM[16]分别添加至测试基准特征提取部分第3、4、5 层特征图之后,与添加MAGB 的本文方法进行对比。消融实验在Citypersons 数据集所提供的合理子集(Reasonable,R),重度遮挡子集(Heavy Occlusion,HO),部分遮挡子集(Partial)和轻微遮挡子集(Bare)上进行验证评估。结果如表1所示。
由表1 可以清晰地看出,与测试基准对比,添加MAGB 后的检测器在合理子集和三种不同遮挡子集上的MR-2均有显著下降,特别是在重度遮挡子集(HO)上,MR-2下降了2.2%。此外,与通用注意力模块SENet 和CBAM 相比,测试基准添加MAGB 后,在合理子集和三种不同遮挡子集上的检测指标均表现出一定的优势。

表1 在Citypersons数据集上的消融实验结果MR-2/%
通过以上结果分析得出,在CSP 的基础上,MAGB 在特征提取阶段引入了外部数据标签监督信息,通过像素级别的可见区域损失,指导模型对行人目标可见区域及全身区域进行不同级别的像素增强,同时,对背景区域像素进行像素置0 的遮罩抑制,经过对模型的迭代训练,这种操作能够有效地引导检测器将背景噪声与行人目标特征分离,关注遮挡行人目标可见区域,有效地提取行人特征,增强网络模型的特征判别力,并且,该遮罩机制可以在一定程度上抑制前置遮挡物体的特征,削弱遮挡噪声对检测器性能的影响。而作为对比方法,测试基准引入SENet 与CBAM 模块后,检测器的性能提升并不明显,甚至还会对测试基准的检测效果产生消极影响,产生这种现象的原因在于,以上两种通用注意力模块只是通过对通道特征或通道空间混合特征的随机调制去提升网络模型的性能,但是对于行人检测中的遮挡问题,可能会在注意力特征调制过程中受到遮挡噪声与背景噪声的影响,将行人目标特征的所对应的特征权重降低,这种操作的结果会影响模型对目标特征的学习能力,进一步降低检测器的检测效果。
4.3 MAGB对比实验分析
为了进一步验证MAGB 对遮挡行人目标的检测性能,选取OR-CNN[3],RepLoss[4],ATT-part[5],ALFNet[6],CSP[10]等五种主流遮挡行人检测方法与本文所提方法进行对比实验。对比实验在Citypersons 数据集所提供的合理子集(Reasonable,R),重度遮挡子集(Heavy Occlusion,HO),部分遮挡子集(Partial)和轻微遮挡子集(Bare)上进行验证评估。结果如表2所示。

表2 在Citypersons数据集上的对比实验结果MR-2/%
由表2 可以清晰地看出,本文方法在重度遮挡子集(HO)上取得了47.1%的MR-2,领先CSP 2.2%,这是因为通过MAGB的调制,网络模型的注意力通过像素级的损失调制产生了空间维度的转移,即重点关注行人目标可见区域特征,对前置遮挡及背景特征进行擦除,这个过程可以让网络更好地提取遮挡行人目标的特征,增强对行人特征的表征能力,抑制前置遮挡物体特征及背景噪声对检测过程的影响,为边界框预测部分提供了更具鲁棒性的行人特征。此外,本文方法在合理子集(R)及部分遮挡子集(Partial)上均领先于其他对比方法,在轻微遮挡子集(Bare)上本文所提方法取得了7.1%的MR-2,仍然具有不错的检测效果。
4.4 MAGB的跨数据集实验分析
由于本文所提方法的网络训练过程在Citypersons 数据集上进行,因此,为了证明所提方法的适用性,需要在不同数据集上进行验证实验。
验证实验在Caltech 数据集所提供的合理子集(Reasonable,R),重度遮挡子集(Heavy Occlusion,HO)和整体数据集(ALL)上对测试结果进行验证评估,将测试结果与RepLoss[4],ATT-part[5],ALFNet[6],CSP[10],DeepParts[19],F-DNN[20]等六种主流遮挡行人检测方法进行对比,通过对比结果对所提方法的泛化性能进行验证。泛化性能验证实验通过绘制FPPI-MR 曲线比较不同行人检测方法的性能,曲线下方面积越小,检测器性能越出色。合理子集(R)验证结果如图3(a)所示,重度遮挡子集(HO)验证结果图3(b)所示,整体数据集(ALL)验证结果图3(c)所示。
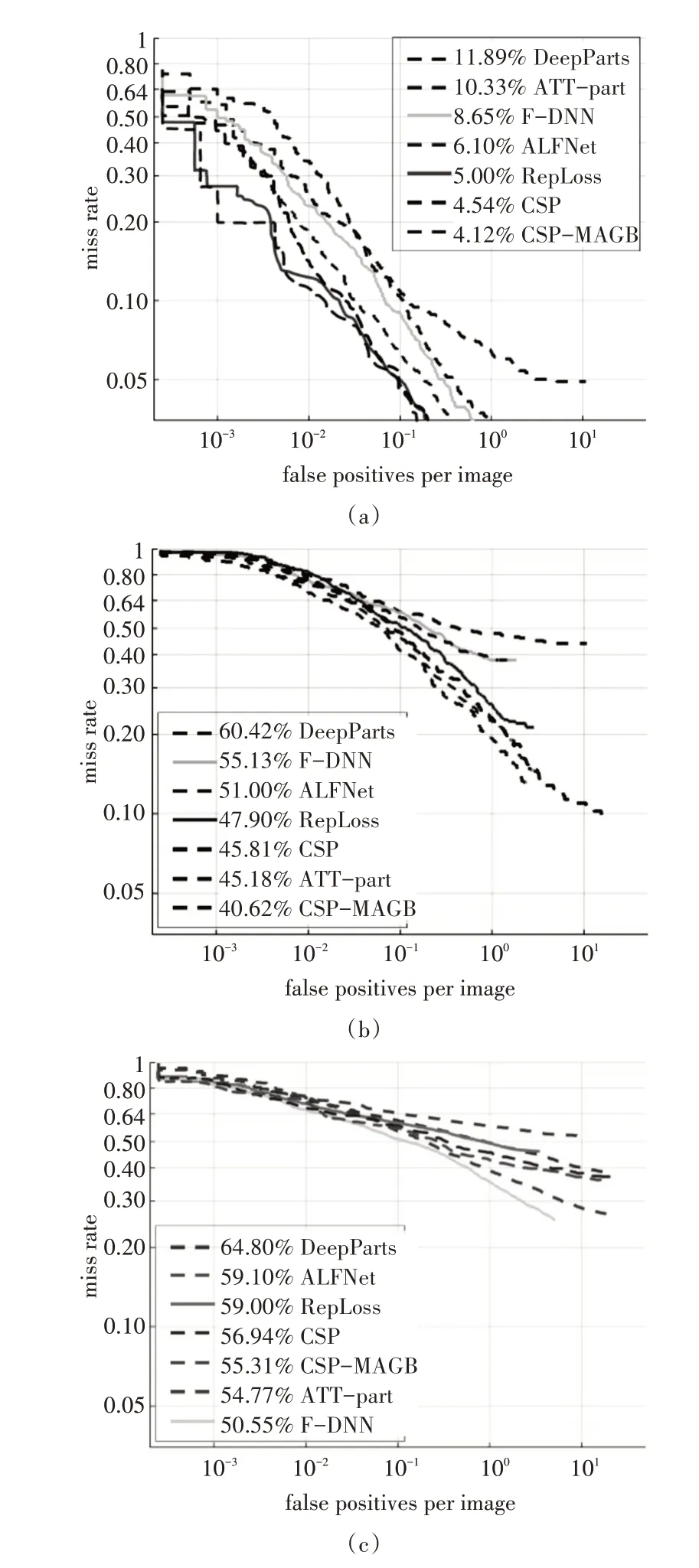
图3 FPPI-MR曲线
通过以上结果,可以清晰地看出,在Caltech 行人检测数据集的合理子集(R)上,本文所提方法达到了4.12%的MR-2,对比CSP 下降了0.42%,在Caltech 行人检测数据集的重度遮挡子集(HO)上,本文所提方法达到40.62%的MR-2,对比ATT-part下降了4.56%。在Caltech 行人检测数据集的整体数据集(ALL)上,虽然相比于CSP下降了1.63%,但是,并未达到目前最优水平,仍然有提升空间。
实验结果表明,本文所提方法在不同数据集上仍然可以有效地应对行人检测中的区域遮挡问题。经过分析,所提出的多尺度注意力引导模块在进行局部特征增强的同时,通过多尺度注意力模块的双分支融合结构保留了全局特征,这减少了该模块对外部监督信息的依赖性,提升了模型的泛化能力,得以使模型在不同数据集上均有较强的适用性。
4.5 真实场景检测仿真实验分析
为了验证本文所提方法在真实场景的检测效果,对测试基准CSP与本文所提方法进行真实场景检测仿真实验,实验分别在Citypersons 数据集和Caltech 数据集上各选取一张具有遮挡场景的样本图片上进行。不同数据集检测结果分别如图4(a)和(b)所示,其中左侧和右侧分别代表测试基准和本文所提方法。

图4 不同数据集检测效果
上述结果中,浅色检测框代表行人目标真实标注框,深色检测框代表测试基准CSP 的检测结果,白色检测框代表本文方法的检测结果。可以看出,在面对真实场景中的不同遮挡模式时,测试基准均不能有效地检测出遮挡行人目标,其检测过程会受到遮挡噪声,重叠行人特征的影响,最终导致漏检现象的发生。而上述示例可以看出,本文所提方法分别将每个行人目标准确检测出来,这证明了专注于遮挡问题的多尺度注意力引导模块的有效性,以及对不同遮挡模式均具有良好的鲁棒性。
5 结语
针对行人检测领域所面临的遮挡问题,本文在基于anchor-free的行人检测方法CSP 的基础上,提出了一种多尺度注意力引导模块,用于引导网络模型更多地关注遮挡目标可见部分区域,抑制遮挡物的特征表现力,消除外部噪声影响,进一步增强行人特征判别力。在Citypersons 行人检测数据集上的实验结果表明,所提方法有效地增强了网络模型对行人特征的提取能力,提升了对遮挡行人目标的检测精度,与其他主流行人检测方法相比,本文所提方法对遮挡目标的检测能力更为出色。在Caltech 行人检测数据集上的泛化实验结果表明,本文方法不过度依赖外部监督信息,在不同数据集上均实现了高质量的检测效果,具有良好的泛化能力。
