基于强化学习的5G URLLC承载网切片流量调度优化
2022-06-11甘浩宇陈立丰郭娘容李佳灏
甘浩宇 陈立丰 郭娘容 李佳灏

摘要:随着5G通信技术的发展,各式各样的网络业务层出不穷。与此同时,新型网络业务使得传统通信承载网的基础设施面临着新的挑战。一方面,有一部分新型网络业务需要在5G网络的超低时延超高可靠性条件下(Ultra-reliable and Low Latency Communications, URLLC)场景下进行服务,此业务需要5G网络提供超低时延以及超高可靠性的通信保障。另一方面,此类型业务流量在传统承载网架构下容易形成局部链路拥塞从而影响交付质量。为解决这些问题,提出了一种基于SDN软件定义网络与强化学习URLLC场景承载网切片流量管理方法。此方法利用SDN转发与控制分离特性并借助深度强化学习来进行决策,从而达到最小化网络负载的效果。通过仿真实验,提出的流量调度方法优于传统的基本管理方法。
关键词:5G;网络切片;SDN;深度强化学习;负载均衡
中图分类号:TN914 文献标识码:A
文章编号:1009-3044(2022)13-0009-05
1 概述
近年来随着通信技术的不断发展,各式各样的新型网络通信业务应运而生,呈现出多场景、差异化特点[1],这对目前网络基础设施中有限的网络资源提出更大的挑战。
一方面,有相当一部分的网络业务需要超低时延、超高可靠性的通信保障,另一方面,不同的网络业务有不同的通信需求,例如:对于无人机巡检,需要实时传输检测视频数据,传输数据量大,对带宽要求较高;对于毫秒级精准负荷控制,则对时延要求较高[2],必须满足不同业务的实际需求,才能保证业务服务质量。
5G通信技术的飞速发展为解决上述挑战提供了一种新的思路与方法。5G是新一代蜂窝移动通信技术,是面向2020年以后移动通信需求而发展的新一代移动通信系统[3]。在文献[4]中,作者设计了一个支持URLLC场景的无线系统模型,满足URLLC场景下超低时延、超高可靠性的通信需求;文献[5]则针对5G网络中三种异构通信服务,提出一种沟通理论模型,保证服务质量。因此,研究和探讨针对5G网络切片的资源管理方法是有必要的。
针对URLLC场景下的业务需求,传统承载网的基础网络架构暴露出较多缺陷[6]。比如,传统通信网络中的流量管理往往基于最短路径转发原则,无法适应WAN网络流量的动态变化,经常使得网络设施中某处通信链路负载过大,而资源丰富的链路或者节点则被空置的状况。
目前传统的网络流量调控往往是基于单独节点的网络设备进行管理,无法从基于全局从整体性上对整个网络拓扑进行监控与调节从而实现全局最优。
SDN(软件定义网络)技术作为5G通信的基础技术,可以在网络流量管控过程中发挥巨大作用。相较于传统流量调度技术,SDN技术实现了节点控制与流量转发解耦的能力,以此达到了针对整个拓扑网络的全局统一控制,使得网络监控应用能够实现流量的动态调度[7]。例如,当网络流量发生异常波动而导致拥塞,传统网络管理技术需要针对所有网络设备进行排查与调整,而 SDN 架构由于控制功能和底层物理设备相分离,控制功能由控制器集中管理,只需要简单地修改应用指令就可以实现对网络的管控,相对于传统网络管理的烦琐工作, SDN 架构使工作效率大大提高,网络更加稳定[8]。
目前传统蜂窝网络中流量调控与负载均衡算法已被大量研究,如小区呼吸技术[9] 已被广泛应用于第二代和第三代移动通信网络中。由 X. Lin 和 S. Wang 提出的 Cloud RAN 中的高效 RRH 切换机制在考虑系统能效条件下实现了流量负载优化[10]。C. Ran 和 S. Wang 等人[11] 从另一个角度提出了 Cloud RAN 中的最佳负载均衡算法。通过周期性地监控衡量均衡度的公平指数,当其低于特定阈值时,则重新设计每个小区覆盖的区域以实现系统的负载均衡。
綜合考虑面向5G网络通信资源的管理和流量调度管理,在实际资源管理过程中,传统的算法往往是基于启发式算法进行流量调控,在计算的过程中一般会增加控制器的计算负担,并且随着用户数量的增加,需要在巨大的决策空间中选择最优决策,耗时较长,而人工智能领域一个新的研究热点——深度强化学习,将深度学习的感知能力与强化学习的决策能力相结合,能让模型在不断的学习过程中自主选择最优策略,降低决策时间[12]。
基于上述的考虑,本文针对URLLC场景下网络切片,提出了一种基于深度强化学习的承载网网络流量调度管理方法。可以动态地依据整体网络拓扑运行状况,弹性地为不同的通信业务流量分配链路资源,针对不同业务,在保证其时延和可靠性要求的同时,满足不同业务的个性化需求,同时优化整体网络拓扑的负载程度。
2 系统模型
如图1所示,针对URLLC场景下多种业务需求可将承载网通信管道切分为软件管道,在SDN上的实现主要是依据需求将物理链路资源映射为不同的虚拟子网切片,为不同的网络业务分配切片资源,在保证其时延和可靠性要求的同时,满足不同用户的个性化需求。如在物联网领域,URLLC场景下业务大致可分为移动应用类、信息采集类和生产控制类三种[13]。
本文针对5G承载网切片网络中的流量调度问题以优化网络负载均衡状况为切入点,在通过网络虚拟化工作将网络拓扑映射为若干个虚拟子网后,通过强化学习智能体对不同业务在各个虚拟子网中的流量导向进行调控,从而达到整体网络负载较为均衡的状况。
2.1 整体架构
本文提出的切片网络流量优化技术架构主要如图2所示,各层级介绍如下:
基础物理架构层是由一系列SDN可控交换机组成的物理拓扑[14],该层接受SDN控制器的流量监控、重定向以及链路映射指令。
子网切片层是利用SDN的网络虚拟化工具,将不同链路映射为对应的虚拟子网,并通过流量重定向将流量走向重定向至由不同链路以及节点组成的虚拟子网,以此实现不同业务之间的端到端切片。
而由OpenDaylight及其VTN组件组成的控制层则负责监控整体网络流量,连接应用层与网络拓扑,统筹全局网络,并使用北向接口接受应用层的控制策略,同时借助南向接口向切片层传递控制信息。
顶层为运行网络流量负载均衡优化算法的强化学习智能体,其收集整个网络的拓扑资源信息以及数据流量状况从而生成控制策略,然后将控制策略下发至控制层。
2.2 负载均衡模型
负载均衡中流量调度问题可以被建模成一个多商品流问题,多商品流问题(Multi-Commodity Flow Problem)是多种商品(或货物)在网络中从不同的源节点流到不同宿节点的网络流问题。多商品流问题的目标是以最小的成本实现商品在网络中的流通,且不能超过每条边的承载能力。
本文中的拓扑模型可泛化作为无向图G=(V , E)其中V是图G所有节点即物理交换机的集合,E是图G中所有边的集合即整个网络拓扑中的物理链路。本文涉及网络切片多业务场景,故记[I]为所有业务组成的集合。对于业务[i∈I],一个相邻节点对之间的单条链路可表示为[wi],则[wi∈E],不同链路中资源与能力存在一定差异,每条链路中的总带宽资源记为[cw]。
对于V集合中任意一组节点对记为v,所有节点对的集合为K,记v之间的一条链路记为业务i的业务切片[si],则K集所有节点对之间网络切片记为S,节点对v之间针对业务i的所有流量路径集合记为[Pvi]。将整体拓扑中所有节点对之间的流量请求矩阵记为M,则v之间的业务i流量请求可记为[mvi]。在多业务运行过程中,不同业务会在同一切片中产生竞态情况,也就是同一切片中可能会经过多种业务流量,所以这里需要定义变量[xsi∈[0,1]]表示业务i在切片s中的與其他的业务资源占比,当业务i优先级高于其他业务或者无其他业务存在时,[xsi=1],如果当前网络切片不存在业务[i]或者优先级完全低于其他业务时[xsi=0],当业务[i]需要与其他业务部分共享切片资源时变量[xsi∈(0,1)]。
本文的关键在于如何找到多商品流问题的资源分配问题,其目标主要是依据业务优先级以及资源分配需求,保证主要业务在多业务运行环境下的网络拓扑中运行性能。
首先针对切片资源占有进行建模,定义业务[i]的整体切片资源占有率[Ui],用以表示当前业务流量大小和当前所在物理链路带宽的比值,从而可以反映出链路的资源使用情况。
[Uiw=pi∈Pw∈pis,d∈Kxwimvicw] (1)
计算出链路的资源使用后,可通过所有链路中的不同业务上的链路利用率的最大值与最小值的差值的平均值来反映链路上负载均衡状况,值越小,说明资源分配较为均衡,负载处于较为均衡状态。
[δ=i∈ImaxUiw-minUiwI] (2)
同时由于网络流量存在瞬时激增或速降的状况,当前时刻的负载均衡值并不能良好地反映网络状况,以至于干扰后续拓扑链路决策,本文采用梯度更新的方式对负载均衡值进行更新。
[δ=δt+?δt-δt-1] (3)
对于流量传输过程中的时延信息,一般认为链路上的时延与流量拥堵程度成正比,因此对于整体网络拓扑的时延,其定义如下:
[Ti=αEwi∈Emvicw] (4)
3 目标函数及解决方法
3.1 问题描述
在本文中,我们希望系统可以在满足业务时延要求和高可靠性的条件下,尽量采用负载均衡度高的切片链路分配与虚拟子网映射方案来进行任务的传输。因此我们定义整个系统所要优化的目标函数如下所示:
[min δ] (5)
[p∈Pvixwi=1][] (6)
[xwi∈0,1] (7)
式(5)为目标函数,其目的是最小化网络负载均衡度;式(6)表示当前时刻业务i所有的流量请求都会被分配到对应的虚拟子网切片上。式(7)保证分配到各自虚拟子网切片以及多重映射的链路的业务占比不得为负值或者超过链路资源。
3.2 解决方法
针对以上场景,本文提出一种基于DQN(Deep Deterministic Policy Gradient)流量管理方法,其网络结构如图3所示。其基本原理是DQN智能体与环境不断交互,获得当前环境状态,然后随机抽样选择一个动作执行,执行完该动作后,环境会从当前状态以某个概率转移到另一个状态,同时智能体会接收到环境反馈的一个奖励或惩罚。在此过程中不断收敛Q函数,并增大从环境中获取的奖励。
DQN智能体每完成一次虚拟子网切片间的流量调度,进而得到该网络拓扑的整体负载均衡程度,从而给智能体反馈一个奖励或者惩罚。智能体将当前环境状态、资源分配动作、反馈奖励和环境下一个状态组成一个四元组,作为一个样本存储到记忆池。通过记忆回放机制,智能体会根据训练周期配置从记忆池随机选取mini-batch样本数据对智能体进行强化训练,从而不断更新神经网络的系数来降低损失[15]。
将上述过程可转成强化学习语言,即状态空间State、动作空间Action和奖励回报函数Reward这3个基本要素[16],针对本文场景,定义如下:
1)状态空间,表示当前一次网络测量中所有流量请求和所有链路的时延,链路利用率以及链路策略信息,具体与前文中三个变量相对应:整体拓扑时延[Ti],资源利用率[Uiw]以及链路分配比重[xiw]。
2)动作空间,表示DQN智能体根据环境状态所做出的策略合集,在本文场景中对应着业务流量在不同虚拟子网路径中的分流比重。DQN智能体每获取一个状态,便会根据Q值从动作空间选择相应动作执行。对于DQN网络中的策略函数[π],其动作空间函数与策略函数关系如式(8)所示。
[at=πst] (8)
3)奖励回报函数。表示环境交互所反馈的奖励回报。在每次迭代中,智能体都会根据当前的环境状态选取并执行一个动作,然后环境转移至下一个状态并反馈给智能体一个回报奖励。本模型中,负载均衡优化模型的优化目标是最小化负载均衡度[δ],本文将奖励定义为负载均衡度的倒数,以此来最大化奖励。定义如式(9)所示,[rt]和[δt]分别表示t时刻奖励与负载均衡度,[β]为奖励系数。
[rt=βδt] (9)
3.3 算法流程
1. 随机初始化动作值函数Q即网络Q
2. 初始化replay memory D
3. 初始化经验池
4. for each episode:
5. 初始化网络输入[s1=x1],计算出网络输出
6. for t = 0 to T:
7. 根据概率密度函数随机采样动作[at]
8. 否则选择[at=maxαQ*?st,a,θ]
9. 执行动作[at],得到奖励[rt]和下一个网络的输入[xt+1]
10. [st+1=st,?t+1=?(st+1)]
11. 将[(?t,at,rt,?t+1)]作为此刻的状态存入到D
12. 随机从D中取出mini batch个状态[(?j,aj,rj,?j+1)]
13. [yj=rj for terminal ?j+1rj+γmaxa'Q(?j+1,a';θ) otherwise]
14. 执行梯度下降
15. end for
16. end for
4 实验仿真
4.1 环境配置
本文实验利用Mininet网络仿真平台来搭建网络拓扑,使用OpenDaylight控制器作为调控整个网络流量的控制器,并使用OpenDaylight的VTN组件进行流量调度。强化学习算法基于TensorFlow框架实现。网络拓扑架构基于traffic-matrices-anonymized提供的其中四个网络拓扑结构实现,每个拓扑模型其中包含23个交换机拓扑节点和48条物理链路,每条链路的带宽资源承载能力都存在一定差异。
4.2 仿真数据
针对URLLC场景下的多种业务的流量特点,仿真数据源应满足以下特点:
网络中应经常有碰撞、拥塞等情况的发生。
不同的端系统可能在短时间内同时发送多个数据流,且大小、持续时间各不相同。
承载网承担着不同的应用,各应用产生的数据流的优先级不同。
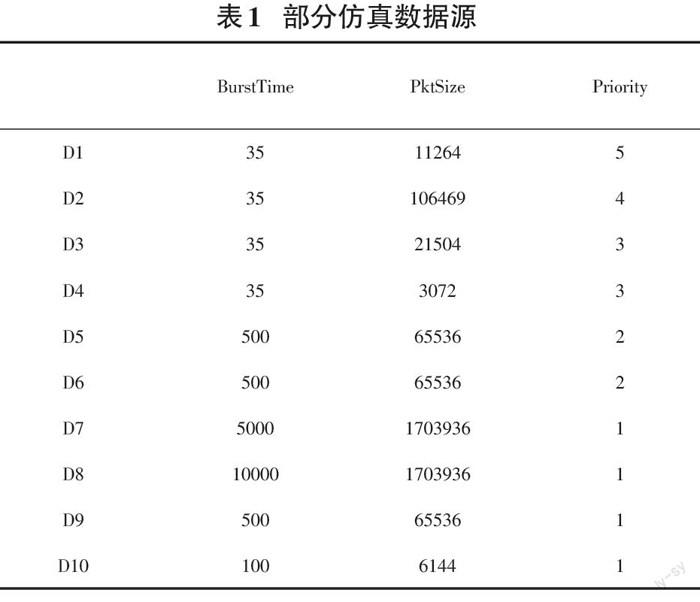
基于以上考虑,仿真所用的部分数据源如表1所示,BurstTime为数据流的持续时间(ms),PktSize 是其大小(KB),Priority 为数据流本身的优先级。
4.3 仿真结果
4.3.1算法收敛
图4描述了算法收敛性描述了基于DQN的网络流量调控管理算法的收敛性,随着训练次數增加,损失函数值逐渐趋近于局部最优值,算法收敛。
4.3.2 方案对比
除了本文提出的流量调控方案,还设置了三个对比方案。
1)最短路径优先,根据该策略,在传输数据过程中会优先选择长度最短的路径作为数据通路,但该方案没有考虑到负载堆积状况,容易陷入局部链路拥塞。
2)固定权重分配,该方案会针对路径设置固定权重,并依据不同链路之间的权重占比来决定该由哪条链路进行数据传输。
3)k路最短路径,该策略会在两点之间分配路径最短的前K条链路路径作为工作的虚拟子网切片,以此来承载流量传输业务。
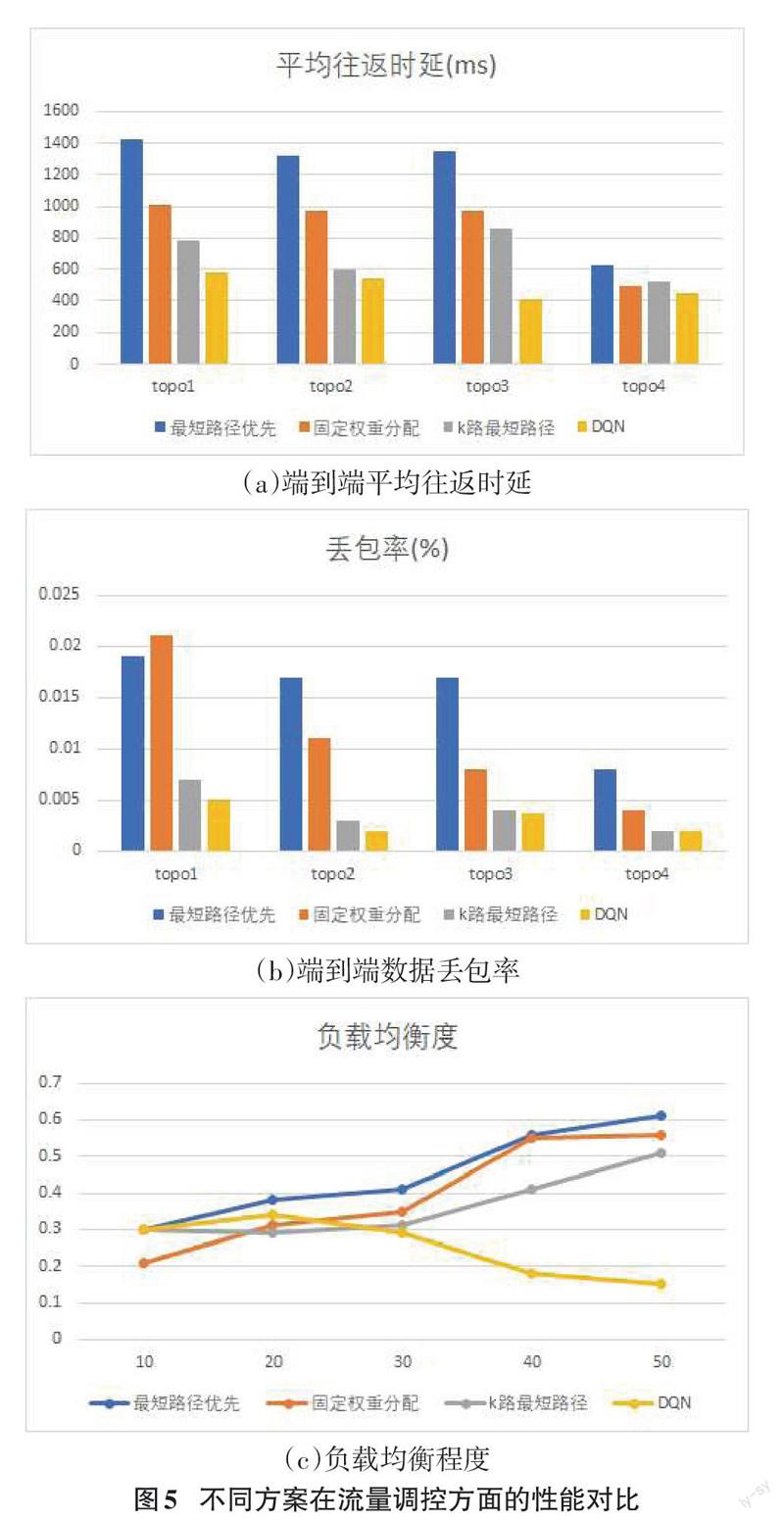
图5(a)、(b)可以看出在不同拓扑模型中,在网络时延以及稳定性方面采用本文DQN控制策略明显优于传统负载均衡策略,并且随着流量请求速率不断增大,采用DQN策略的流量调度方案有着更好的性能。
5 结束语
在5G时代的通信承载网系统中,一方面要面临大量用户接入网络流量同时涌入而导致擁塞的风险,另一方面,不同的业务有不同的通信需求,需要为不同的互联网业务提供个性化的通信服务,面对这样的挑战,设计一种基于切片网络的弹性流量调控方法至关重要。本文提出了一种面向5G承载网切片网络的多业务流量优化方案。该方案基于深度强化学习,能够依据划分的虚拟子网切片,制定链路策略,对拥塞链路进行疏导。与传统算法相比,本文提出的方案确保了流量传输时延和数据丢包率,提高了整体网络的负载均衡度,提高了网络的可靠性。
参考文献:
[1] 5G White Paper V1.0[R]. Germany: NGMN, 2015.
[2] Liu C F,Bennis M,Poor H V.Latency and reliability-aware task offloading and resource allocation for mobile edge computing[J].2017 IEEE Globecom Workshops (GC Wkshps),2017:1-7.
[3] Popovski P,Trillingsgaard K F,Simeone O,et al.5G wireless network slicing for eMBB,URLLC,and mMTC:a communication-theoretic view[J].IEEE Access,2018,6:55765-55779.
[4] Anand A,de Veciana G.Resource allocation and HARQ optimization for URLLC traffic in 5G wireless networks[J].IEEE Journal on Selected Areas in Communications,2018,36(11):2411-2421.
[5] 施巍松,孙辉,曹杰,等.边缘计算:万物互联时代新型计算模型[J].计算机研究与发展,2017,54(5):907-924.
[6] 丁泽柳,郭得科,申建伟,等.面向云计算的数据中心网络拓扑研究[J].国防科技大学学报,2011,33(6):1-6.
[7] 张朝昆,崔勇,唐翯祎,等.软件定义网络(SDN)研究进展[J].软件学报,2015,26(1):62-81.
[8] 樊自甫,李书,张丹.基于流量调度的SDN数据中心网络拥塞控制算法[J].计算机科学,2017,44(S1):266-269,273.
[9] Niu Z S,Wu Y Q,Gong J,et al.Cell zooming for cost-efficient green cellular networks[C]//IEEE Communications Magazine.IEEE,2010:74-79.
[10] Lin X J,Wang S W.Efficient remote radio head switching scheme in cloud radio access network:a load balancing perspective[C]//IEEE INFOCOM 2017 - IEEE Conference on Computer Communications.May 1-4,2017,Atlanta,GA,USA.IEEE,2017:1-9.
[11] Ran C,Wang S W,Wang C G.Optimal load balancing in cloud radio access networks[C]//2015 IEEE Wireless Communications and Networking Conference.March 9-12,2015,New Orleans,LA,USA.IEEE,2015:1006-1011.
[12] 刘全,翟建伟,章宗长,等.深度强化学习综述[J].计算机学报,2018,41(1):1-27.
[13] Gungor V C,Sahin D,Kocak T,et al.A survey on smart grid potential applications and communication requirements[J].IEEE Transactions on Industrial Informatics,2013,9(1):28-42.
[14] Lei K,Liang Y Z,Li W.Congestion control in SDN-based networks via multi-task deep reinforcement learning[J].IEEE Network,2020,34(4):28-34.
[15] Wu Z Q,Wei J,Zhang F,et al.MDLB:a metadata dynamic load balancing mechanism based on reinforcement learning[J].Frontiers of Information Technology & Electronic Engineering,2020,21(7):1034-1046.
[16] MS Ali,Coucheney P,Coupechoux M.Reinforcement Learning Algorithm for Load Balancing in Self Organizing Networks[EB/OL].[2021-08-10].https://onlinelibrary.wiley.com/doi/10.1002/9781119471509.w5GRef137.
【通联编辑:梁书】
