移动边缘计算环境下容器实时迁移方法
2022-06-11江凌云
罗 艺,江凌云
(南京邮电大学,江苏 南京 210003)
0 引言
作为计算范式的下一次演进,移动边缘计算(Mobile Edge Computing,MEC)使计算、存储和通信更接近最终用户[1,2]。与云计算相比,它允许移动用户将其计算密集型任务,如图像处理,卸载到附近的边缘服务器,以显著减少端到端(End-to-End,E2E)延迟。边缘计算的主要挑战之一是保证服务质量优于传统云服务,同时将服务卸载到离最终用户最近的边缘服务器上[3]。然而,当最终用户离开附近的边缘服务器时,由于网络连接的恶化,服务质量将显著下降。理想情况下,当最终用户移动时,边缘服务器上的服务也应该实时迁移到附近的新服务器上,以响应用户的移动性,确保最短的延迟和最佳的边缘服务供应。
服务迁移可以分为有状态迁移和无状态迁移。无状态迁移不移动应用程序的运行状态,只是将用户的请求重定向到一个新的服务器上,并有一个单独的服务实例在运行,这适用于不为用户保留状态的应用。然而,对于当今越来越流行的交互式服务,如主动安全预警、移动多媒体和移动在线游戏等应用,很可能需要为每个用户保留一些状态。因此,本文中重点讨论有状态的迁移,它涉及移动应用程序的运行状态,在这种情况下,用户连续一段时间接受服务,服务应用可能需要为用户保留一些内部状态,如一些中间数据处理结果。迁移完成后,程序完全恢复到迁移前的状态,因此迁移被归为实时的。但是服务迁移也有副作用,它可能会导致性能下降,甚至在迁移期间中断正在进行的服务。因此,高效完整地实时迁移对于在边缘计算环境中实现边缘服务的移动性至关重要[4]。
虚拟化是云计算和边缘计算的一个重要方面。将云服务或边缘服务作为虚拟环境,如虚拟机、容器,可提供极大的弹性和隔离性,从而允许多租户提高资源利用效率。一个边缘服务器承载多个虚拟环境或卸载的服务,每个虚拟环境运行一个用户卸载的任务,对封装在虚拟机或容器中的服务进行节点间迁移,这种方式具有高度灵活性和适应性。与传统的虚拟机(Virtual Machine,VM)创建完整的客户操作系统不同[5],容器技术是一种轻量级虚拟化技术,它共享相同的操作系统内核并将应用程序进程与系统的其余部分隔离开来。因此,容器不仅解决了环境依赖问题,而且显著减少了内存占用、初始化和迁移开销[6]。本文利用容器特性,将容器分为基础层和数据层,对于基础层,只迁移目标节点缺失的那些层,以减少数据传输量;对于数据层迁移,采用预转储的方法,在服务迁移开始之前,迭状转储包括内存数据和执行状态等信息到目标节点上,在服务迁移触发后,此时只用传输一小部分改变的状态信息,大大减少了服务的停机时间,提高了服务质量。
本文的第1节介绍近年来有关虚拟化环境下容器的服务迁移方法的相关研究;第2节介绍Docker的分层架构和基于检查点/恢复技术(Checkpoint/Restore In Userspace,CRIU)的容器预转储迁移方法的详细过程;第3节评估所提方法的性能;第4节对论文进行总结,并在当前的工作基础上做进一步的展望。
1 相关工作
虚拟化环境下进行容器迁移并保证服务质量一直是一个热门话题,引起了许多学者的关注。文献[7]和文献[8]研究了云计算中心场景下的服务迁移,然而边缘网络中的服务迁移受到一些在云环境中不存在的影响,例如,相比于云中心环境,边缘网络的吞吐量更低,要求迁移过程中传输的数据量越少越好。文献[9]提出了一个在数据中心环境中实时迁移Linux容器(Linux Container,LXC)的基本解决方案。然而,LXC将容器视为整个系统的容器,没有分层存储。因此,在容器迁移过程中,该容器的文件系统的所有内容必须一起迁移,同时还包括所有的内存状态。文献[10]提出了基于远程同步(rsync)增量功能的、支持分层的容器的实时迁移;然而,由于它只支持预定义的整个系统的2或3层,在容器运行时同步文件系统有可能遇到rsync文件争夺问题,此外文献[10]中基础层的重复复制可能会产生更多的性能开销。文献[11]支持容器的有状态迁移,并将CRIU的内存迁移与联合挂载的数据联合功能相结合,以最大限度地减少迁移停机时间,然后通过源主机和目标主机之间的数据联合视图,容器可以在目标主机上立即恢复运行;然而,仅通过在节点之间同步根文件系统来迁移图像,没有考虑底层的分层存储,这使得迁移在网络边缘的速度较低。文献[12]在实时迁移过程中保证了边缘服务器场景下Docker容器的组件完整性;但由于从中央镜像注册中心提取镜像进行镜像迁移,消耗了镜像注册中心的巨大带宽,导致可扩展性差和无法容忍的停机时间,影响了迁移性能。
综上所述,以上提出的关于容器迁移的解决方法,对于Docker容器的分层存储特性没有加以利用,并且对于容器的基础层和数据层迁移方法没有一个统一完整的解决方案;因此,本文设计一个通用的容器迁移框架,根据实际情况选择不同粒度的服务迁移,减少不必要的信息传输,以最小化服务的停机时间和总迁移时间。
2 容器迁移方案
本节首先给出Docker容器的架构,其次给出基于容器分层存储架构和CRIU的迁移机制。
2.1 Docker架构
Docker容器的架构和层级架构分别如图1、图2所示,Docker使用客户端—服务器架构,用户借助Docker客户端与Docker daemon完成对话,Docker daemon负责编排容器、镜像管理、执行逻辑、提供REST API等重要功能。1个Docker容器是在1个Docker镜像之上创建的,镜像有多层存储,每个Docker镜像都引用了一个代表文件系统差异的只读层列表[13]。当1个新的容器被创建时,1个可读可写的存储层被创建在镜像层的堆栈之上,上面的新层被称为容器层。对容器所做的所有改变,例如创建、修改或删除任何文件都会写入这个容器层。
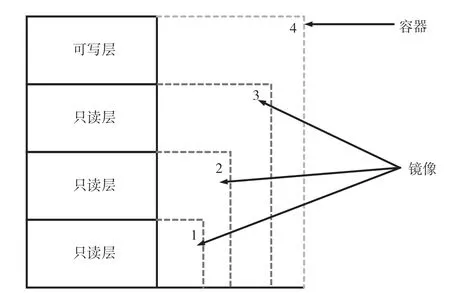
图2 Docker层级架构
2.2 迁移机制
图3详细介绍一个实时迁移的流程。本文把提出的解决方案分为磁盘迁移阶段和内存迁移阶段两个主要部分。最初,迁移行动的需求是由管理平面检测出来的,它可以是ETSI网络功能虚拟化(ETSINetwork Functions Virtualization,ETSI-NFV)的架构的一部分[14]。本文假设用户移动性可以预测,在迁移目标服务器已知的情况下使用迁移方法完成迁移。
内存迁移检查(图3中的步骤1)是最初的测试,在这里,克隆镜像(基本镜像和应用程序)在目标MEC主机中的可用性得到了验证。如果可用,就开始克隆过程,然后进行内存迁移。
部分迁移检查(图3中的步骤2)是在克隆镜像不可用的情况下进行的。在目标MEC进行验证,以找到基本镜像,例如,在Ubuntu的情况下,Trusty一旦找到,就开始克隆基本镜像,然后将应用数据从源MEC复制到目标MEC并进行内存迁移。
完整的迁移检查(图3中的步骤3)代表了最后一步和最坏的情况,因为它们在目标MEC中不存在,需要将整个文件系统(rootfs)、应用程序和内存转移到目标MEC。

图3 迁移机制流程
以上3个步骤针对目标MEC容器的磁盘进行迁移,磁盘迁移针对的迁移对象是持久性数据,在完成迁移后,紧接着迁移内存数据。在边缘计算的环境下运行的服务,经常碰到执行瞬时数据分析和时间关键控制这类情况,那么针对这些非持久性数据,如何快速迁移到目标MEC上也是一个很重要的问题。因此,本文提出了一种基于CRIU的预转储实时迁移方法。CRIU工具将被用来反复转储容器的内存,当它在运行时,转储到源MEC主机的一个tmpfs挂载的目录;然后,每个转储都会通过网络复制到目标主机的tmpfs-mounted目录中;最后,容器将在目标MEC主机上被恢复。之所以称为预转储迁移,是因为它在冻结容器之前反复转储容器的内存到源MEC主机的一个tmpfs挂载的目录,接着,每个转储都会通过网络复制到目标主机的tmpfs-mounted目录中,然后进行最终的转储和状态传输,最后容器在目标节点上恢复运行。在预转储阶段执行多次迭代迁移,每次迭代只转储和重新传输在前一次迭代期间修改的那些内存页面(第一次迭代转储和传输整个容器状态)。图4描述了迭代迁移的详细步骤,修改后的内存页称为脏页。

图4 内存迭代迁移
此实现基于CRIU,它提供了必要的基本机制(例如,-pre-dump 选项)来预转储容器的运行时状态并在之后恢复它。预转储迁移的停机时间受传输脏页数量的影响,预转储迭代迁移产生的脏页数量会受到两个因素的影响:首先是容器托管服务的页面变脏率,即服务修改内存页面的速度;其次是预转储阶段传输的数据量,因为该阶段传输的数据越多,服务修改页面的时间就越多。值得注意的是,这两个因素应该始终对照源节点和目标节点之间的可用带宽来考虑。当然,迭代迁移并不是无休止地迭代,通常,预转储阶段的迭代是收敛的,即持续时间越来越短。如果迭代,预转储阶段通常在达到预定迭代次数时或者脏页阈值时结束。因此需要定义一个明确的内存页数,以保证最短的停机时间,或者使用一个固定的迭代次数,以避免无限循环,即页面数量永远不会低于预先定义的脏页阈值。当连续迭代中的增量内存检查点文件的大小低于阈值时,应该开始停止并复制。在此方案中,判断迭代过程是否发散的依据是本次迭代中增量内存的大小是否大于上一次迭代。
3 结果评估
3.1 实验设置
本节评估所提出的容器迁移解决方案。使用虚拟化节点,宿主虚拟机分别从一台物理机上获得2 GB虚拟内存和2个虚拟中央处理器(Central Processing Unit,CPU)核,物理机配置有2.6 GHz的英特尔酷睿i7和16 GB内存。两个虚拟机运行Ubuntu 16.04 LTS和Linux 4.15.0通用内核,并作为MEC在其间进行迁移,CRIU版本是3.16,docker版本是20.10。实验使用Linux tc实用程序设置虚拟节点间不同带宽(带宽分别设置为10 Mbit/s和100 Mbit/s),模拟拥塞和理想的网络条件。容器运行时大小设置为100 MB,本文考虑的是已经安装在目标节点上的服务,因此迁移对象是容器的数据层。考虑脏页变化率对实验结果的影响,在移动性场景下,边缘设备会频繁地请求数据更新,这对于内存来说消耗巨大[15],设置两种脏页变化率(分别为10 KB/s和300 KB/s)模拟方案对于脏页变化率的敏感度。
迁移容器所花费的总时间主要由以下几部分 组成:
(1)预转储阶段将生成的预转储数据从源节点传输到目标节点的时间;
(2)在转储阶段将生成的转储数据从源节点传输到目标节点的时间;
(3)迁移到目标节点后容器恢复的时间。
服务的停机时间主要由传输转储数据导致。
3.2 结果分析
本文通过实验评估所提方案的性能,并与传统的冷迁移进行了对比,对比实验分别在不同脏页变化率和不同带宽的条件下进行,对比结果如表1、表2所示。冷迁移的步骤主要分为3步:首先冻结/停止容器以确保它不在修改状态,其次在容器停止时转储整个状态并转移它,最后当所有状态都可用时,在目的地恢复容器。

表1 脏页变化率为10 KB/s时的性能对比
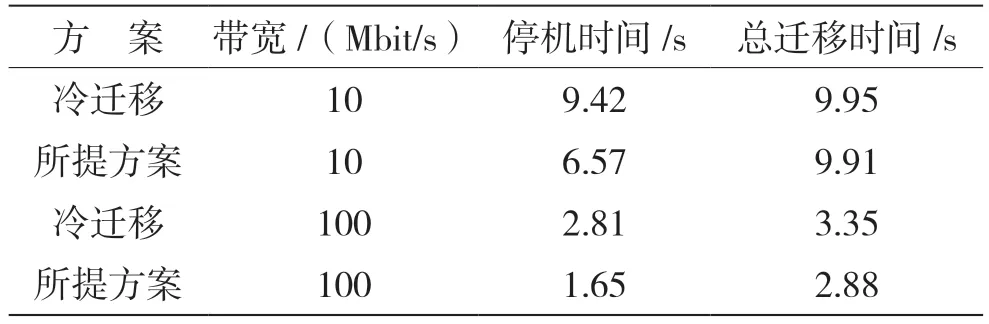
表2 脏页变化率为300 KB/s时的性能对比
从总迁移时间角度分析,无论何种网络情况、何种脏页变化率,冷迁移的总迁移时间最长,因为该方法没有考虑容器的分层存储特性,每次进行服务迁移时,迁移整个容器到目标节点,传输的数据量远远超过所提方案。但是,当脏页变化率提高一个量级之后,所提方案的总迁移时间在网络条件较差的环境下与冷迁移接近,这是因为冷迁移在迁移过程中不考虑内存页变化,它总是将容器整体打包传输给目标节点,所有的内存页只传输一次。而所提方案考虑将内存页迭代迁移,在脏页变化率增大的情况下,预转储阶段被弄脏的页面数量与该阶段转移的页面数量相当,导致内存页传输了不止一次,预转储迁移的数据转储量相当大。在网络条件理想的情况下,虽然脏页变化率增大,但是远不及网络吞吐量,所以转储阶段迁移不受影响。
从停机时间角度考虑,无论何种网络情况、何种脏页变化率,冷迁移的停机时间最长,几乎与其总迁移时间吻合。这是因为冷迁移和预转储迁移之间的主要区别在于其转储的性质,冷迁移中的转储代表整个容器状态,因此始终包括所有内存页面和执行状态。相反,预转储迁移中的转储仅包括在预转储阶段修改的那些内存页面,以及执行状态的更改;因此,预转储迁移的停机时间比冷迁移的停机时间短。但是冷迁移的迁移性能不受脏页变化率的约束,在同样的网络条件下停机时间几乎一致。而所提方案在网络条件较差、脏页变化率变高的条件下,停机时间增加明显,性能下降,原因在于此情况下脏页变化率数量级更接近带宽,导致最终转储的脏页数量增多。但是当所提方案在网络条件理想的情况下,停机时间不受脏页变化率的影响,这是因为在这些条件下,很少有内存页在预转储阶段被修改,所提方案在转储阶段传输的数据量几乎一致。
4 结语
容器化和容器迁移是边缘计算的一个基本方面,移动边缘计算是一种范式,在网络边缘附近提供计算、存储和网络的资源及服务。本文批判性地分析了现有的容器迁移技术,并特别关注它们对边缘计算环境的适用性,结合现有的迁移技术和工具,提出了基于容器分层特性的预转储迁移方案,该方案利用容器的镜像层与容器层分离的特性,在迁移过程根据目标节点的实际情况,只传输缺失的镜像层,以此减少网络负担。在考虑到迁移过程的停机时间时,本文采用预转储方法,在迁移开始前迭代迁移内存页,以此减少转储过程中传输的状态信息,降低服务迁移停机时间。最后在实验平台上对该方案进行了全面的性能评估,观察它在不同的网络条件和页面变脏率条件下的迁移性能。在评估了总迁移时间、停机时间后,结果表明所提方案表现优异,在网络条件理想的情况下,停机时间接近1 s。
在未来工作中,将继续探索容器的服务迁移方法,利用人工智能的手段来决定和执行服务迁移的触发时间,以提高方法的性能。
