大规模主题词自动标引方法
2022-06-07韩红旗张运良翁梦娟悦林东
韩红旗,桂 婕,张运良,翁梦娟,薛 陕,悦林东
(1.中国科学技术信息研究所,北京 100038;2.富媒体数字出版内容组织与知识服务重点实验室(国家新闻出版署),北京 100038)
1 引 言
主题标引(subject indexing)是对文献主题及其他有检索意义的特征进行分析、表示、提炼和归纳,然后用某种检索语言(自然语言、受控语言)标注出来,作为信息存储与检索依据的信息处理过程[1]。简而言之,主题标引是对文献内容进行主题分析、赋予主题词标识的过程。按照使用主题标引语言的不同,主题标引可以分为受控标引和自然语言标引(或自由标引)。其中,受控标引是采用叙词表(或主题词表)中选用的规范词对文献进行标注,自然语言标引是直接选择自然语言词汇对文献进行标引。主题标引是数据资源加工和分析的基础工作,我国国家标准《科学技术报告、学位论文和学术论文的编写格式》(GB 7713-87)明确规定论文关键词应尽可能采用《汉语主题词表》等词表提供的规范词。
主题标引是数字资源组织的有效手段,它的准确性是保证数字资源检索和利用的关键因素。在大数据时代,文本信息的规模和增速非常大,靠人工标引不仅不可行,而且不可能,自动标引的价值凸显。当前,虽然全文检索技术已经非常成熟,但自动标引能实现信息精炼、提升、过滤,使检索更有效率、检索结果更准确,因此其重要性愈发凸显[2]。自动标引是指利用自动化技术从文献中抽取检索标志的过程。相比于人工标引,自动标引具有速度快、成本低以及稳定性和一致性高的优点,更适合大数据时代的数字信息资源标注[1]。按照标引词的来源不同,自动标引可以分为抽词标引和赋词标引[2-3]。其中,抽词标引是从文献(题名、摘要、关键词或全文)中抽取关键词来作为检索标识;赋词标引则是根据文献的内容特征,从受控词表中选择叙词或主题词来作为检索标识。抽词标引法由于获得的标引词可能不是受控词表中的主题词,不利于根据主题进行文献检索或主题关联,给标引结果的使用带来不便,所以,在商业类型的文献数据库中,多采用赋词标引而不采用抽词标引。
然而在大数据时代,自动标引面临着非常大的挑战。挑战主要来自三个方面:一是如何判断一个文本与一个主题词的语义相关性,尤其是在文本中没有出现的主题词;二是因为主题词表中的主题词数量往往非常大,一般领域的主题词有成千上万,综合性的主题词表则可达10万以上,例如,《汉语主题词表》共收录19.6万个优选词、16.4万条非优选词[4],《中国分类主题词表(2版)》正式主题词有110837个[5],面对如此大规模的类目标签,常规的机器学习分类算法难以发挥作用;三是如何将层出不穷的新词快速地纳入自动标引算法是一个问题,现有的算法常常不得不花费大量时间再次训练复杂的模型。
现有的自动标引技术多是利用一些统计指标或语言学方法从文本中抽取关键词,再映射到主题词实现赋词标引[6]。然而,这种方法一般无法抽取文本中没有的主题词。基于机器学习的主题标引方法称为多标签分类学习。该类学习算法可以分为两类[7]:一类是传统的多标签分类,标签数量一般较少,往往几个或数十个,无法适应标签规模成千上万的情况,更不用说10万以上了;另一类称为极端多标签文本分类(extreme multi-label text classifi‐cation,XMTC),可以处理规模庞大的多标签分类,然而这个方法要求每一个标签都有训练样本数据,可现实中有些类很难找到训练数据或训练数据偏少,限制了该类算法的应用。除此之外,标签分类常常面临着类目数据不均衡问题所带来的分类精度低,以及难以快速响应新增标签分类的困境。
本研究面临的是采用数万或10万以上主题词对大规模文本进行标引的情况,而且没有带标签的训练数据,无法使用XMTC方法,显然传统机器学习方法也无能为力。在从大规模主题词表中选择若干语义相关的主题词赋予一个文本时,既要解决主题词与文本语义上的匹配,又要适应海量数据的快速标引以及新词的标引。采用的主题词表由中国工程科技知识中心(下文称“知识中心”)委托中国科学技术信息研究所建设。知识中心词表在20余家分中心领域词表的基础上形成了“核心集+扩展集”的架构,其中核心集为主题词表,共包含18.39万条主题词,未来将不断补充新的主题词。知识中心建设中需要对大量未标注关键词的文献、报告、新闻等数据标注主题词,用于后续的检索、主题分析等工作。
2 相关研究
2.1 自动标引技术
美国学者卢恩(H.P.Luhn)在1957年首次开展了主题标引实验[2-3],并在IBM公司的研究刊物上发表了第一篇有关自动主题标引的论文,题名为“文献处理机械化编码和检索用的统计学方法”。卢恩在该文中提出了词频统计加权方法和“自动抽词标引”的基本思想,奠定了自动主题标引的基础。
自动主题标引方法按技术可以分为四类:统计标引法、语言分析标引法、机器学习标引法和混合方法[2-3]。
统计标引法的主要思想是:词在文档中出现的频率是该词对文档重要性的有效测量指标。通常认为,处于高频和低频之间的那部分词汇才最适宜做标引词。也有学者使用词频之外的其他一些显著统计特征,如共现、逆文档词频、熵、互信息等。统计标引法可细分为词频统计、加权统计、概率统计、分类判别统计等。例如,李素建等[8]通过建立最大熵模型的特征集合实现关键词自动标引;柯平等[9]基于词频统计从文本中抽取高频词实现标引,并与关键词进行匹配对比,说明统计方法的可行性。
语言分析标引法是指对被标引对象进行词法分析(lexical analysis)、句法分析(syntactical analy‐sis)、语义分析(semantic analysis)和篇章分析(text analysis)等,从而达到自动标引的目的。词法分析主要是分词、词性标注和获得词汇的详细特征。句法分析标引法是通过从语法角度来确定句子中每个词的作用(比如,是主语还是谓语),以及词与词之间的相互关系(比如,是修饰关系还是被修饰关系)来实现的。语义分析标引法是在分析词和短语在特定上下文环境中的确切含义的基础上,选择与主题含义相同的标引词来描述文献的。篇章分析主要是通过找出篇章中内容相关的片段,从篇章角度提取能反映文本主题的词语。例如,丁芹[10]提出一种利用语义格进行文献语义表述的方法,对标引词的语义格加权算法做了较合理的解释和推导,并引入一种计算词语之间相似度的方法实现自动标引;赵丹[11]利用句法分析器对文献提取出来的主题句进行成分标注、短语结构标注、词性标注,进一步利用统计信息、词或短语结构的词间的联系实现主题标注。
基于机器学习的自动标引方法是利用计算机来理解和模拟人类特有的智能系统活动,学习人们如何运用自己所掌握的知识,去解决现实中的问题。目前基于机器学习的自动标引方法一般通过训练集来获得相关统计参数,通过有监督或无监督的过程进行自动标引。机器学习法可以分为分类、聚类、集成学习、深度学习等。例如,章成志[12]整合统计机器学习模型与集成学习方法的优势,对文档进行基于多分类模型综合投票实现自动标引;王新[13]利用词嵌入将文献向量转换为富含词汇间语义关系的张量,再利用深层卷积神经网络实现文献主题国别的自动标引;陈博等[14]基于文本挖掘技术和可视化工具实现可视化主题自动标引。国外文献近些年的此类研究集中在对MeSH(medical subject headings)主题词标引的挑战赛BioASQ上。其中,Mork等[15]提出MTI(medical text indexer),通过将MetaMap、PubMed相关引文与聚类排序方法结合实现近3万条MeSH主题词的标引,因为该方法性能较优而被作为BioASQ挑战赛的基准[16];其他MeSH主题词的标引 方 法 有MeSHLabeler[17]、DeepMeSH[18]、FullM‐eSH[19]、MeSHProbeNet[20]、卷 积 神 经 网 络[21]、BERTMeSH[22]、MeSHProbeNet-P[23]等。这些机器学习方法的突出特点是将深度学习技术应用于主题词标引,依赖于大量的人工标引数据进行模型训练。
以上三类方法各有优缺点。统计标引法简单,实现容易,但准确率相对较低,一般用于抽词标引,不适合于赋词标引。语言分析标引法相对准确率高,但容易受到语言“规则库”的影响,通用性差;它既可用于抽词标引,也可用于赋词标引,但用于赋词标引时,一般无法将受控词中的词与待标文档的整体语义进行比较,获得的标引词可能存在与待标文档语义关联性不高的问题。机器学习标引法具有较好的移植性,即同一方法可以很方便地应用到不同的领域,但是该方法对于不同类型数据需要训练多个分类器,训练时间较长,可能存在数据稀疏问题及过拟合学习问题;该方法一般用于赋词标引,但往往受制于算法的复杂性和受控词类别的数量,一般不适合于大规模受控词表的标注。
混合方法则是上述方法的综合运用,例如,先利用统计标引法获取初步标引结果,再利用语言分析法过滤统计分析结果以获得更好的标引词,或加入启发式知识,如词的位置、词长、词的排版规则、HTML标记等。例如,李纲等[24]利用词语语义相关度算法对词汇链的构建算法进行了改进,并结合词频和词的位置等统计信息,实现关键词的自动标引;Gil-Leiva[25]结合参考文献、标题、摘要等的位置启发式规则和TF-IDF实现对科学文章的自动标引。
机器学习标引法和混合方法是近年来得到广泛采用的方法,但这些方法均未开展大规模主题词标注的研究,或者解决的只是抽词标引问题。例如,陈白雪等[26]以中文核心期刊论文中作者标注的关键词和分类号为源数据,形成9万多的关键词词表,然后使用TF-IDF算法和位置加权算法实现科技项目数据的标引,该研究虽然涉及较大规模的关键词,但只是一种抽词标引方法;唐晓波等[27]针对目前的标引系统仅以文档为标引单位、无法深入到文本内容的问题,引入本体语义扩展和神经网络模型训练等技术,提出了基于文本知识片段标引的方法,获得比传统方式精度更高的结果,但实证仅对构建的一个小型糖尿病本体开展;FullMeSH[19]和BERTMeSH[22]利用全文本代替标题和摘要的MeSH词表标注方法,实现大规模PubMed论文的标注,但这个大规模主要体现在论文的规模上,而不是词表的规模上。
2.2 分布式词向量
分布式词向量是自然语言处理领域中的一类重要技术,其核心是对文本中的单词建模,用一个较低维的向量来表征每个单词[28-30]。词向量的生成方法很多,目前性能最佳的是基于深度神经网络的语言模型生成的分布式词向量,它通过无监督的机器学习方法从海量数据中自动学习词汇的语义特征,不需要人工标注和复杂烦琐的特征工程。分布式词向量不像传统的词向量那样维度高且稀疏,而是一种嵌入式向量,将单词表示为一个连续的、低维的、实值向量(通常为100~300维),每一维度代表了一定的语义。
word2vec词向量是2013年由Mikolov等[31]从海量的Google新闻语料中训练得到的,是目前使用最广泛的神经网络词向量。word2vec利用深度学习的思想,通过训练,将每个词映射成维实数向量(一般为模型中的超参数),通过词之间的距离(如co‐sine相似度、欧几里得距离等)来判断它们之间的语义相似度。词向量距离越近,词汇表示的语义就越相似。后来的研究者借鉴词嵌入向量的思路,提出了一些新的词向量模型,如GloVe(global vec‐tors)[32]、ELMo(embeddings from language mod‐els)[33]、BERT(bidirectional encoder representations from transformers)[34]等。分布式词向量现在已被广泛应用于分类、聚类、命名实体识别、词性分析等自然语言处理任务中。
3 方法
3.1 自动标引实现的基本思路
为了实现将一个主题词赋予一篇待标引文本,需要确定它们之间的语义相关性。从大规模语料中训练的分布式词向量较好地保留了词汇的语义信息,如果能利用分布式词向量将主题词和待标引文本表示为同样维度、可语义计算的向量,那么就可以使用欧几里得距离或cosine相似度等指标计算一个主题词和待标引文本之间的相似度,如图1所示。在计算了所有主题词与待标引文本的相似度指标后,就可以对所有相似性指标值进行排序,然后选择排名靠前的主题词输出,作为文本主题标引的结果。

图1 主题词与文本之间相似性计算的基本思路
这需要解决两个关键问题,一个问题是如何利用预训练的分布式词向量生成主题词和待标引文本的表示向量,另一个问题是如何解决主题词和文本向量之间的巨量计算。主题词数量庞大,如果将其全部和待标引文本计算相似度将耗费大量的计算时间,使得标引方法实际上不可用,显然也没有必要这样做,因为与文本紧密相关的主题词数量一般不会特别多。对于第一个问题,我们借鉴doc2vec[35-36]的基本思想来解决。对于第二个问题,我们使用了一种被称为sampling block的技术生成文本的候选主题词[37],只需将待标引文本与数量较少的主题词进行向量相似度计算。
3.2 自动标引实现的基本过程
本研究提出的自动化标引方法的流程如图2所示,可以分为6个步骤:①主题词表示向量生成;②普通词与主题词的映射关系表生成;③待标引文本的预处理;④待标引文本的表示向量生成;⑤待标引文本向量候选主题词生成;⑥文本的主题标引。分别对应图2中标注了数字1~6的虚线矩形方框。
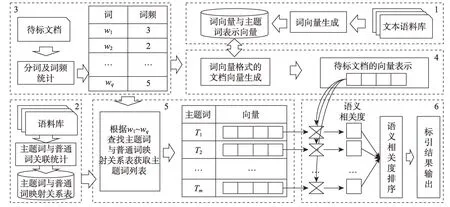
图2 主题标引实现流程
1)主题词表示向量生成
获取大规模的文本语料数据,对语料数据进行无用标签删除、分词、数字文本过滤、格式转换等处理,形成可机器批量处理的规范格式数据,基于词向量技术(本研究使用word2vec,也可以采用其他词向量技术),将词表示为具有特定维数的稠密的嵌入式向量,形成词向量库W。经过词向量技术处理后,可以获得语料库中每一个词的向量表示,设向量的维数为k,则对于一个词w i,其向量可以表示为[w i1,w i2,…,w ik]。
利用训练好的词向量库生成主题词的表示向量。首先获取受控词表中的主题词列表,然后逐词循环采用如下方法获得每一个主题词的向量表示。对一个主题词,假设为T i,去词向量库W中检索,若存在,则用词向量库中的向量表示[wi1,w i2,…,w ik]作为该主题词的向量表示;若不存在,则将该主题词切分为p个短词,将其中无意义的连接词去掉,假设一个主题词T i切分后为将每一个短词去词向量库W中检索,获得每一个短词的向量表示,则采用这些短词向量的平均值作为该主题词的向量表示,计算方法为

2)普通词与主题词的映射关系表生成
如上文所述,一般受控词表规模会很大,将文本与整个受控词表的主题词进行相似度计算将带来很大的运算量。为了避免将待标引文本与受控词表中的每一个主题词进行对比,通过大规模文本语料库建立一个主题词与若干个普通词的映射关系,实现文本向量与主题词向量比对过程中的运算约减处理。建立的主题词与普通词的映射关系如表1所示。
建立映射关系表(表1)的具体方法为:从受控词表中获取主题词的列表,对每一个主题词The‐saurusi,在大规模文本语料中进行检索,获取包含该主题词的全部文本集合,然后对文本集合中的全部文本进行分词和停用词处理,计算文本中全部词的TF-IDF值,按照从大到小排序后取前n个普通词(Wordi1,Wordi2,…,Wordin)作为该主题词关联度强的词汇列表。该工作也是主题标引的准备阶段,目的是生成与每一个标引的主题词语义关联度特别强的词汇集合。利用主题词与普通词的映射关系表,对于一个普通词来说,可以通过查表获得与其关联性高的主题词列表。
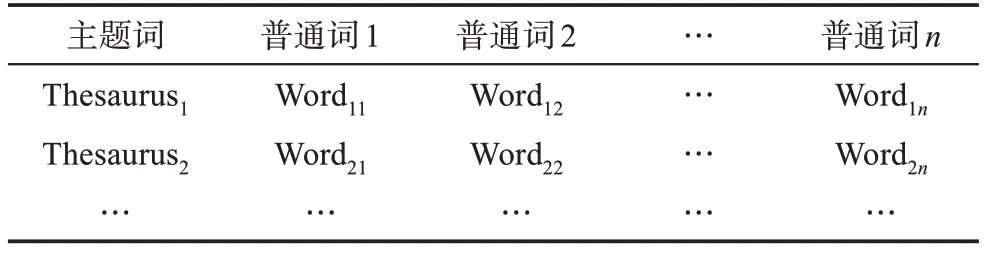
表1 主题词与普通词的映射关系
3)待标引文本的预处理
在前两个准备阶段工作完成后,就可以正式开始文本的自动标引工作。对一个待标引的文本首先进行分词、停用词处理等预处理工作,获得文本中包含的词列表,统计每个词出现的数量(词频)。该工作主要是为下一步生成待标引文本的表示向量和其可能主题词集合做准备。
4)待标引文本的表示向量生成
对一个待标引文本做预处理后,可以获取其包含的词列表以及各词在文本中出现的次数,记为[(w1,f1),(w2,f2),…,(w q,f q)],其 中,w1,w2,…,w q为 文本中包含的词列表,f1,f2,…,f q是它们在文本中出现的次数。利用词列表及其频次,基于平均词向量法(avg-w2v)获得该待标引文本的k维向量表示,即以文本中各词向量的加权平均值作为文本的表示,其中权重为文本中各词的词频,计算方法为

其中,w j1,w j2,…,w jk是w j在词向量库W中的向量各分量值。获得的待标引文本的表示向量与主题词的表示向量的维数一致,均为k维,而且它们都是基于同一词向量库W生成的,为计算待标引文本与主题词的语义相关度提供了保障。
5)待标引文本向量候选主题词生成
待标引文本预处理后形成了词列表,基于构建的主题词与普通词的映射关系表,可以获得与待标引文本关联强的候选主题词列表,我们称这项技术为sampling block,它使对文本主题标引时不需要进行大量的向量相似度计算,只需要将文本向量与数量不大的主题词表示向量进行比对,可以有效减少比对的次数,大幅减少运算量,从而大大提高标引效率。
图3说明了候选主题词产生的方法。对于文本分词预处理后形成的每一个普通词w1,w2,…,w q,到主题词与普通词的映射关系表中查找,得到一个可能的候选主题词集合,这个集合一般来说只有几十个或数百个,具体跟文档长度及包含的词数量有关。

图3 候选主题词生成的方法示意图
6)文本的主题标引
有了候选主题词列表后,就可以将待标引文本的表示向量和筛选出来的受控词表中候选主题词的向量进行语义相似性比较。语义相似性计算采用余弦方法,对于一个文档表示向量d→=[d1,d2,…,d k]和一个主题词表示向量=[T1,T2,…,T k],计算公式为

也可以采用其他方法。
对待标引文本表示向量和全部候选主题词表示向量的相似度结果进行排序,选择排名靠前的m个主题词对文本进行标注。m可以根据需要设定,也可以输出全部的主题词。
4 实 验
4.1 数据
根据本研究提出的方法开发了自动化的主题标引工具,利用该标引工具对近亿条记录进行了标注,标注速度达到每秒60余条记录。后期对标引工具进行了优化,标引速度达到每秒160余条记录,能较好地满足中国工程科技知识中心数据资源标引的需求。在信息检索中,关键词作为一个揭示文本主题的单位,标引关键词的数量适合定在9个词以内[3]。基于该认识,以及对部分样本的人工分析结果,一篇文本的机标主题词最多保留8个(下文称“标引主题词”)。我们从标注好的文献中抽取了100万条数据,字段包括标题、摘要、作者关键词和标引主题词。对该数据集中作者关键词字段中不包含主题词的记录进行删除,剩余671607条数据,下文将这个数据集称为index-dataset,统计后发现其包含的主题词有63053个。
为了评估提出的自动化标引方法的效果,基于抽取的100万条数据,使用结巴关键词工具生成了对比数据集jieba-dataset。首先采用结巴关键词工具从100万篇文献的标题和摘要中抽取关键词(下文称“结巴关键词”),同样结巴关键词最多保留8个,形成字段包含标题、摘要、作者关键词和结巴关键词的数据集合,并删除作者关键词中没有出现在结巴关键词的词汇形成jieba-dataset。
4.2 评价指标
评价指标采用多标签分类评估指标flat mea‐sure[18]。该评价指标包括基于实例的方法(examplebased method)和基于标签的方法(label-based method)两类。基于实例的方法把评价过程分解为单个实例的评价,然后求所有实例的均值。基于标签的方法把评价过程分解为基于单个标签的评价,然后求所有标签的均值;其又可以进一步分为宏平均(macro average)和微平均(micro average),其中宏平均对每个类别赋予相同的权重,而微平均对每个文档的分类结果赋予相同的权重。因为主题标引更强调对一篇篇文档标引的效果,采用基于实例的方法或微平均相对而言更适合。这里采用基于实例的评价方法,其计算方法为:设文档总数量为M,标签总数量为K。对于M个文档中的任意一实例文档i,其真实标签列表记为y i,预测标签列表记为̂,它们均有K个标签元素,每个元素的取值为{0,1},即某个标签出现时取值为1,不出现时取值为0。则对一个实例文档i,有

其中,EBPi是该实例文档标签预测的准确率;EBRi是标签预测的召回率;EBFi是标签预测的F1-mea‐sure值。进而得出整体上的评价指标:
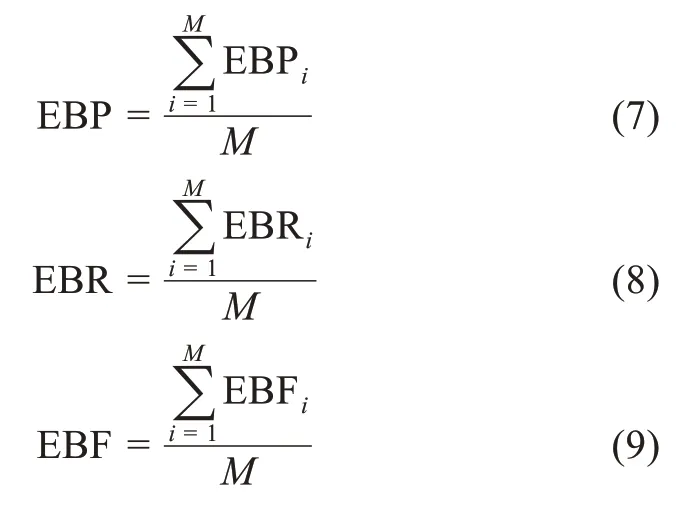
4.3 实验结果及讨论
为了评估本研究提出方法的效果,首先统计了index-dataset和jieba-dataset两个数据集中不同作者关键词数量下的文档数量分布。这里的作者关键词数量指一篇论文包含的作者关键词数量。其中,in‐dex-dataset数据集中,作者关键词中已经去除了不在主题词表中的词汇;jieba-dataset数据集中,作者关键词中则去除了没有出现在结巴关键词中的词汇。不同作者关键词数量下的文档数量分布如表2所示,其中文档数量(标引)表示的是index-datas‐et数据集中不同关键词数量下的文档数量分布,文档数量(结巴)表示的是jieba-dataset数据集中不同关键词数量下的文档数量分布。
从表2可以看出,在1个作者关键词数量的情况下,结巴关键词的文档数量超过了本文自动化标引算法的文档数量;而在其他作者关键词数量下,本文自动化标引算法标引的主题词数量均大于结巴关键词的文档数量,而且数量优势明显。考虑到在形成index-dataset和jieba-dataset数据集时,分别去掉了作者关键词中没有出现在标引主题词和结巴关键词的词汇,说明作者关键词数量为1的情况下结巴关键词与作者关键词有较高的重合数,而在多作者关键词数量下,本文自动化标引算法标引的主题词与作者关键词有较高的重合数,标引算法总体上比结巴关键词算法有优势。

表2 不同作者关键词数量下的文档数量分布
分别计算了两个数据集在不同作者关键词数量下的EBP、EBR和EBF指标,如图4所示。其中,数据点标记为正方形的线条表示index-dataset上的结果,数据点标记为圆形的线条表示jieba-dataset上的结果;EBP指标用实线(solid line)表示,EBR指标用短划线(dashed line)表示,EBF指标用点线(dotted line)表示。相对而言,两个数据集上的EBR指标值较EBP大,这主要是因为预测的标签数量平均较大(最多保留了8个主题词或结巴关键词),而大多数论文中关键词数量在3~5个,且去除了未出现在机器标引词中的关键词。
从图4可以看出,不管是标引主题词还是结巴关键词方法,随着作者关键词数量的增加,准确性在提高而召回率在下降,且本文标引方法召回率下降速度更快。结巴关键词在3项指标上均有优势,尤其是EBR指标,具有明显的优势。这主要是因为作者关键词一般按顺序从标题、摘要和正文中抽取,而结巴关键词是从标题和摘要文本中抽取的,自动化标引算法标注的主题词不一定在论文中出现。因此,相对而言,结巴关键词具有较好的准确率和召回率,而且召回率下降较慢。从图3上还可以看到,在关键词数量为1时,标引主题词与结巴关键词的准确率EBP基本相同,随着作者关键词数量的增多,两者的准确率都在增加,但结巴关键词的准确率稍高一点,说明结巴关键词与作者关键词有较高的重合率,标引主题词与作者关键词的重合率则较低,标引算法赋予待标引文本更多的非作者关键词词汇。

图4 主题标引与结巴关键词标引结果对比
为了进一步说明这个问题,统计了作者关键词数量、结巴关键词数量、标引主题词数量,以及未出现在论文文本中的作者关键词数量、结巴关键词数量和标引主题词数量。作者关键词的数量为4576513个,其中747981个未出现在标题和摘要中,占比为16.34%,即大多数作者关键词都出现在论文文本中。结巴关键词数量为7925997个,全部出现在标题和摘要中。相比而言,标引主题词总数量为6988176个,其中有3842968个未出现在标题和摘要中,占比达54.99%,主题词未出现在标题和摘要中的文献比例高达86.14%,即绝大多数文献都被赋予了未在文献文本中出现的词汇。这也解释了结巴关键词指标更好的原因。
为了较公平地比较两个方法,进一步去掉了标引主题词中未出现在论文文本中的词汇,同时去掉结巴关键词中不是主题词的词汇,这样结巴关键词和标引主题词均是文本中出现的主题词。再次计算两个方法的3项指标(图5),其中数据点标记为正方形的线条是主题标引数据集index-dataset上的结果,数据点标记为圆形的线条是结巴关键词数据集jieba-dataset上的结果。同样,实线表示EBP指标,短划线表示EBR指标,点线表示EBF指标。
在图5中,本文提出的自动标引方法在每一个关键词数量下的EBP指标值均超过了结巴关键词方法,EBR除了在关键词数量为1时超过了结巴关键词方法,其他情况下均低于结巴关键词方法;而且能够明显看到,标引主题词方法的召回率下降速度很快,而结巴关键词方法下降比较慢,只有在关键词数量超过5个后才出现快速下降。这也进一步说明,从论文文本抽取的结巴关键词与作者关键词有较多的重合,而标引主题词生成了更多非作者关键词的词汇,所以标引方法的召回率下降更快,但同时自动标引方法提供了更多的、可靠的语义标签。

图5 主题标引与结巴关键词标引结果对比(去除非文本词和非主题词)
为了更进一步说明本文方法的效果,将本文方法和人工标引进行对比。实验数据集由中国工程科技知识中心林业分中心提供。该数据集共包含3411条文献及人工标注的主题词。每一篇文献一般有3~8个主题词。同样,在实验中,我们去掉了知识中心主题词表中不存在的人工标引词。实验结果如图6所示。

图6 主题标引与人工标引结果对比
从图6可以看出,随着人工标引主题词数量的增加,本文提出的自动标引方法的EBP指标值不断增加(图中的实线),而EBR指标值不断下降(图中的短划线),但EBF指标值基本是不断增加的(图中的点线),说明随着人工标引词数量的增加,机器标引的整体效果在不断提升。当人工标引主题词数量小于等于2个时,EBR指标值下降较快;而当人工标引主题词数量多于3个时,EBR指标值下降的速度明显变慢,这说明在人工选择较多的主题词时,机器标引结果与人工标引结果的一致性在增加。
5 结语
本研究提出了一种对文本进行大规模主题词标注的混合型标引方法,它综合了统计分析和语义分析技术实现数量达数十万规模的主题词在海量数据上的标注,可以应用于搜索引擎、新闻服务、电子图书馆等领域,也可在全文检索、文本分类、信息过滤和文档摘要等任务中发挥作用,能够更好地应对信息资源的快速增长造成信息相对过剩的问题,提高信息组织的效率,方便人们高效地管理和检索文档。本研究基于大规模文本语料上训练的分布式词向量,生成相同维度的主题词表示向量、待标引文本表示向量,通过两者向量相似度计算和排序为文本赋予语义关联强的主题词,实现了自动的主题标引。为了减少计算量,建立主题词和普通词映射关系表,在标引时通过该表为文本生成语义关键性强的候选主题词列表,从而实现文本向量与较少数量主题词的相似度计算。与现有的自动标引方法相比,该方法不需要机器学习算法所需的大量带标签的训练数据,不仅能实现赋词标引,还能对数量规模超过10万的综合型主题词表进行标注,而且对大规模文本的主题标注效率较高。
利用本研究提出的方法开发了自动标引工具,实现了对近亿篇文献的快速标注。为了验证该方法的效果,提取100万篇标注数据生成实验数据集,以作者关键词为基准,采用flat measure多标签分类算法评价指标,与结巴关键词工具抽取的关键词结果进行对比,发现该方法能抽取更多的文本及作者关键词中未出现的主题词,为揭示文本信息提供了更多的语义标签。虽然总体上结巴关键词在指标上取得了较好的数值,但其抽取的关键词与作者关键词重合较多,且均出现在文本中。如果标引主题词只保留出现在文本中的词汇,而结巴关键词只保留主题词,则本研究提出的方法在准确率上更好,但召回率较低,主要原因是结巴关键词大多出现在作者关键词中,而标引主题词大多不在作者关键词中。将本研究提出的方法与人工标引对比时发现,在人工选择较多的主题词时,机器标引的结果与人工标引结果的一致性在不断增加。
本研究虽然实现了大规模主题词在海量文献上的自动标注,但还存在一些需要提高或完善的地方。一方面是本研究使用word2vec技术实现分布式词向量,该技术出现后有了一些新的词向量技术,如BERT[34]、XLNet[38]等,它们可能会带来更好的效果,未来将尝试这些词向量技术,了解并对比它们在自动标引上的效果。另一方面是本研究采用了多标签分类算法评价指标,没有采用人工方法来评判,无法判断那些未在文本中出现的标引主题词是否是合适的,主要是因为人工判别会存在主观性大、一致性差、成本高等问题,少量的抽样不一定能说明问题。实际上,我们抽取了少量的标注结果给领域专家,他们对该方法的结果表示了不同程度的满意度。未来将考虑抽取多个领域的标注结果,交给多个领域专家评判该方法的效果。
