基于引文重要性的知识流动主路径分析
2022-06-07夏红玉王忠义
夏红玉,胡 潜,王忠义
(华中师范大学信息管理学院,武汉 430079)
1 引 言
卡尔·波普尔的科学知识增长论将知识的生产增长过程描述为达尔文进化论式的过程,是知识在流动过程中优胜劣汰的过程[1],而这个过程通过学术文献的引用过程得以体现。学术文献之间的引用关系反映了知识采集、组织、生产、传播和应用的过程,引用信息表明,知识从被引文献传播到施引文献。因此,引文网络中的知识流可用于跟踪技术或科学知识的发展轨迹。1964年,科学引文索引之父Garfield基于学术文献间知识的溯源与继承关系,提出通过分析引文关系来追寻科学研究的历史脉络的想法[2];随后学者们相继通过分析引文网络来追踪科学的历史和发展脉络[3-5]。然而引文网络通常是巨大且复杂的,需要有效的方法来降低引文网络的复杂性,从而识别出最重要的路径来追踪科学发展的轨迹。1989年,Hummon等[6]提出了主路径分析方法,从引文网络的内部结构衡量引文链接重要性,然后按时间顺序追踪这些链接,建立引文网络中最重要的路径,研究特定科学领域的发展轨迹。
作为一种定量分析方法,传统基于引文网络分析的主路径方法没有考虑引文对施引文献的相对价值,认为施引文献中的所有引文对该文献具有同等的重要性,导致主路径分析方法无法客观体现引文网络中知识流的传播、利用与创新的关系。本文以Altmetrics主题研究领域为例,收集了1985—2020年Web of Science核心数据集中的512篇全文数据,在施引文献全文引用位置和全文引用频次统计基础之上,构建引文重要度指标来表示引文对施引文献的重要性,用来加权调节主路径分析的链接遍历计数,探索提高主路径分析方法的可靠性和合理性,并测度了改进后的主路径分析方法在提取知识流方面的性能表现。
2 相关研究
2.1 识别重要引文的相关研究
引文分析对于评估被引文献的科学贡献具有重要意义,但传统基于引文著录分析的方法对所有引文一视同仁,不区分引文对施引文献的重要性,导致作为科学影响力衡量标准之一的引文计数的准确性与合理性饱受质疑[7]。学者们指出,每次引用行为背后的原因各有不同,一篇文献的全部引文中只有少数引文对施引文献研究的影响大于其他文献,因此需要对引文的重要性进行区分[8]。Moravcsik等[9]的研究显示,在大多数科研文献中40%的引文仅提供常识和背景知识,并指出将引文一视同仁的计量方法会影响引文分析定量评估的准确性。1965年,Garfield[10]通过定性分析引文出现的位置和引文上下文信息总结出15种引用动机,首次通过引用动机来对引文进行分类。起初大多数研究侧重于区分引文的不同意图或引用的目的[11-14],后来学者们开始关注如何识别对施引文献具有核心影响力的引文[15-17]。目前学者们发表了许多识别引文对施引文献重要性的研究,例如,从引文动机的角度选择衡量指标[18-19];基于全文引文计数[8,20-21],基于引文和施引文献的标题、摘要、关键词或引文上下文信息等内容之间的相似度[22-25],基于引文的引用位置[26],基于引文句子长度[27-28]等来识别重要引文。但这些研究中使用的特征相对有限,无法比较并准确捕获能够有效用于区分引文重要性的特征。事实上,每次引用行为都从统计学角度和语义内容角度为我们提供了分析引文重要性的途径。引用行为的统计学角度包括引用的次数、引文的句子长度、引用出现的段落,引用行为的语义内容角度包括引文的极性(态度)、引用位置、引文与施引文献的相似度等[29]。因此,在最新的研究中,Wang等[30]从统计学和语义内容角度提取了21个指标来构建识别重要引文的特征空间,研究结果显示,统计学角度的全文引用频率、引用句子总长度最能有效识别重要引文,语义内容角度的引用位置、引文与施引文献的内容相似性等指标也能有效识别重要引文。
本文从引用行为的统计学视角和语义信息视角分别挑选全文引用频次和引用位置,作为综合衡量引文重要性的指标。事实上长久以来众多关于全文引文分析的研究都试图根据被引文献在施引文献全文中出现的引用次数,或者引用位置来确定引文对施引文献的相对价值。目前众多学者对此已经达成了初步共识:①被引文献对施引文献的重要程度与其在施引文献全文中的引用频次成正比。Voos等[8]认为,引文对施引文献的重要性可以用其在全文中的引用频次来计算。胡志刚等[31]认为基于全文引用频次的统计方法用于科学评价与预测具有更好的效果。Zhu等[16]和Hou等[32]的研究显示,引文在全文中出现的频次可以代表该引文对施引文献的知识价值贡献;并且随着全文引用次数的增加,引文对施引文献的价值贡献也会增加[33]。②在文献介绍性部分(引言、相关研究)之外提到的参考文献对施引文献的价值往往更高。Maričić等[34]在研究了357篇文献的全文引用语境与位置后提出,应根据引文在文献中引用位置的不同来对其进行重要性的评估。学者们发现,大部分引文出现的位置集中在文献的开头(引言、相关研究)和结尾(讨论和结论),但出现在介绍性章节之外的引文对于施引文献往往更有价值[20,35]。出现在文献方法与结果部分的引文对施引文献的价值比仅出现在简介或引言部分的引文更高[36-38]。
2.2 主路径分析相关研究
主路径分析方法自提出以来,已被广泛应用到学术论文和专利文献的引文网络分析中,用于跟踪研究领域的发展历史和演化路径,如绘制技术轨迹[39]、检测技术变化[40]、探索知识的传播和技术的扩散[41-42]、进行文献综述[43-44]等。在主路径分析的发展过程中,学者们从主路径分析方法的不同角度对其进行了改进,如优化主路径分析的链接遍历计数方法。2003年,Batagelj[45]提出了搜索路径计数(search path count,SPC)的方法来计算引文链接重要性,改进了主路径分析方法;Verspagen[46]提出最优主路径演化网络(network of the evolution of top path,NETP)算法,通过划分不同时间间隔来计算最优主路径,考察路径节点的知识流随时间的发展情况;Choi等[47]提出前向引证节点对统计值算法(forward citation node pair,FCNP),通过前向引文节点对数确定连边的权值来识别主路径。针对主路径方法产生的知识轨迹单一,无法展示知识体系多分支、知识流融合的局限性,学者们从不同角度扩展了路径搜索算法。Liu等[48]提出了关键路径搜索(key-route search)方法进行修正,对主路径中所遗漏的关键路线进行了补充;Park等[49]提出基于知识遗传适应性的前后路径方法,减少了对重要节点的遗漏;冷伏海等[50]和万小萍等[51]提出了基于主路径算法的综合运用来解决知识轨迹单一问题;刘向等[52]提出了构建基于引文路径叠加的主路径发现方法。
传统主路径分析方法认为每篇引文对施引文献的价值同等重要,而事实上学术文献中的引用动机和引用情景非常复杂[53],每次引用行为都从统计学角度和语义内容角度为我们提供了分析引文重要性的信息,将所有引文一视同仁的研究方法会使传统主路径分析方法无法客观体现引文网络中知识流的传播、利用与创新的关系。因此,学者们将引文与施引文献的内容相关性用于衡量引文的重要性,从引用行为语义分析角度改进主路径分析法。例如,陈亮等[54]将文本相似度引入主路径搜索过程,通过用语义相似度衡量路径重要性来计算主路径;彭泽等[55]设计了一种基于文本相似度的知识流量计算方法,结合知识流动路径类型提取主路径。或者通过数据库的内容相关度标引项来表征引文相关性,例如,Liu等[56]利用法律数据库West Law中KeyCite标引项,通过引入4级内容相关度对链接遍历计数进行加权调节来确定主路径。
虽然已经陆续有相关学者从引用行为的语义分析角度,通过计算引文内容的语义相似度来提高主路径分析方法的可靠性和合理性,但目前尚没有文献从引用行为的统计学层面和语义信息层面综合区分引文重要性,探讨引文对施引文献的重要性对构造主路径的影响。本文选择全文引用频次和引用位置作为引文重要性识别的特征,拟从统计学角度和语义内容角度更好地区分引文的重要性。
3 基于引文重要性的主路径构造
为了提升主路径分析方法的可靠性,改善该方法在分析引文网络知识流动路径的性能,本文试图构建引文重要度指标来加权调节引文链接的重要性,对主路径分析方法中的链接遍历数进行调节,并作为路径搜索的参考变量,提高主路径方法在衡量链接权重指标的合理性与准确性。主路径分析方法的链接遍历计数基准方法采用SPC方法,引文重要度指标使用引用频次和引用位置加权方法。
3.1 引文重要性计算
结合上文所述,本文采用引用位置和引用频次相结合的方法来计算引文对施引文献的重要性。首先将文献根据IMRaD(Introduction,Materials and methods,Results,Discussion)科研论文写作结构将引文出现位置标记为4级位置权重参数,然后计算引文在该处的引用权重,最后计算引文在该处的引文重要性。某篇引文在文献某处的单次引文重要度r等于其出现的位置权重参数L乘以它在该处的引用权重w,即
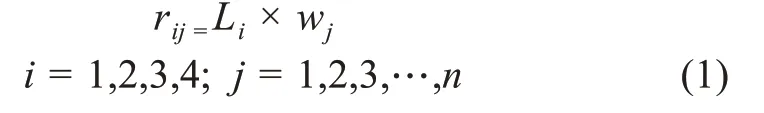
在科学文献创作中引文与引用之间是多对多关系,一篇引文可以被同一文献多次引用。引文在文献中的引用权重,通常采用引用句子长度计算法或引用频次整数计算法,但这两种方法都会导致权重高估问题[33,57]。Pak等[58]发现引用频次分数计数法可以有效解决引用计数的权重高估问题,因此,本文采用基于引用频次的分数计算法。引用内容是包含参考文献引用的句子或短语。若引用内容仅有一条参考文献,则称之为“独立引用”;若引用内容包含多条参考文献,则称之为“非独立引用”。学者们认为独立引用的参考文献贡献大于非独立引用的参考文献,因此,每条非独立引用的引文在计算“引用权重”时应将贡献平均分配给每条参考文献[58]。假设某处引文内容包含m条参考文献,则该处每条参考文献的“引用权重”w为

引 文1:“Batagelj(2003)further improves that method by proposing fast algorithms to calculate the sig‐nificance of citation links.”
引文2:“The concept of main path analysis has since been used to map technological trajectories(Fon‐tana et al.,2009;Verspagen,2007).”
引文1仅引用了一条参考文献,参考文献“Batagelj(2003)”为“独立引用”;引文2同时引用了两条参考文献,参考文献“Fontana et al.,2009”和“Verspagen,2007”为“非独立引用”。因此,文献“Batagelj(2003)”的引用权重是1,文献“Fon‐tana et al.,2009”和“Verspagen,2007”的引用权重是1/2。引用权重的取值范围为0<w≤1。因此,引文在单篇文献中的总体引文重要度R等于其在全文中的单次引文重要度之和,即
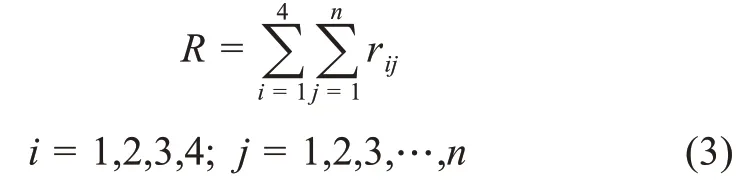
在使用分数计数的情况下,L i是引文的位置权重,n是文献全文内的引用数量,w j是第j条引文在文献中的引用权重,由上文可知,引文在一篇文献全文中的引文重要度R是其在全文中参考文献的对应位置权重与对应引用权重乘积之和。
3.2 传统主路径构造方法
在引文网络中知识从被引节点流向施引节点,节点之间的链接关系代表了知识流动的方向,节点之间通过链接通道传播知识。给定节点连接到终端节点的一系列链接称为“搜索路径”。在一个复杂的引文网络中,一个给定节点可以有多个搜索路径,但每个搜索路径的意义可能不同。主路径是在引文网络所有搜索路径中最重要的搜索路径,代表着引文网络中最重要的知识流动的序列。构造主路径通常分为两步。首先,采用某种遍历计数方法作为衡量引文网络链接显著性的指标,将二元引文网络将转化为加权网络,每个链接的权重表示链接的重要性。其次,在遍历计数后,采用某种路径搜索算法来构造主路径[6]。采用遍历计数作为引文网络链接显著性指标的逻辑是,如果引用链接占据了大量知识流动的路径,那么它必须在知识传播过程中具有一定的重要性。SPC算法是当前主路径分析中链接遍历计数的经典算法,它通过计算相邻两节点之间的链接被网络中所有的路径所遍历的次数,来衡量该链接在网络中的重要性[59]。假设一个引文网络N=(D,R)是由一组文档D构成的,这些文档的关系由R表示,其中R⊆D×D,而(u,v)表示文档v引用文档u。如图1a所示,引用网络被其他节点引用而未引用其他节点的文档,称之为“源(source)”;引用其他节点而不被其他节点引用的文档,称之为“汇(sink)”;引用了其他节点并被其他节点引用的文档,称之为“中间文档(intermediate)”。知识沿着引文网络中的链接在文档之间传播流动。
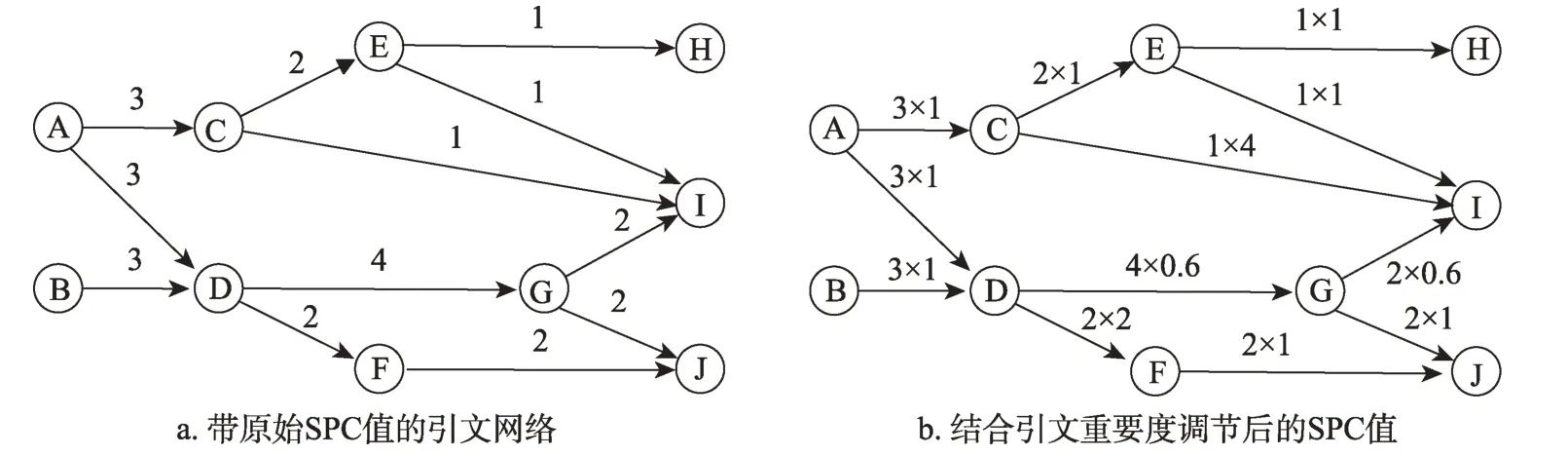
图1 不同SPC值的主路径计算方法
假设知识从文档u传递到文档v,根据Batagelj[45]对搜索路径计数(SPC)的定义,链接(u,v)的遍历计数是从源点到u的路径数与从v到汇点的路径数的乘积,计算方法为其中,

因此,图1a中有A和B两个源点,以及H、I和J三个汇点。对于链接(D,G),从源点A、B到D有两条路径(A-D,B-D),因此,从G到汇点I、J有两条路径(G-I,G-J),因此,2;链接(D,G)到Wspc(u,v)=4。对于链接(A,C),因此其SPC值为3。
3.3 基于引文重要性的主路径搜索
传统的主路径分析对所有引用链接都一视同仁,直接使用遍历计数来搜索主路径。但考虑引用链接的相关性时,应该将遍历计数与引文重要度权重结合起来。因此,基于引文重要度的遍历计数计算方法为

其中,R(u,v)是文献u和v之间的引文重要度;Wspc(u,v)是链接u和v之间的搜索路径计数。假设引用链接(D,G)、(G,I)的重要度为0.6,(D,F)的重要度为2,(C,I)的重要度为4,其余链接重要度为1,则调整后它们的链接遍历重要性如图1b所示。根据调整后的链接遍历计数在引文网络中搜索主要路径。全局搜索算法强调总体重要性,选择最大总体遍历计数的路径作为主路径[48]。图2展示了基于原始SPC值和利用引文重要度调节引文网络SPC值后的引文网络全局搜索算法的主要路径。以图2a为例,路径A-D-G-I、A-D-G-J、B-D-G-I和B-D-G-J的SPC总值都为11,在所有潜在路径中SPC总值最大。图2a与图2b主路径的差异表明,考虑引文重要性会改变主路径。因此,我们将所有信息转化为引文网络,构造了一个加权有向网络,其中文献是节点,引用频次和引用位置被转化为以相应的“引文重要度”指标作为权重的链接。从这一引文网络出发,运用主路径分析法探讨了引文与施引文献的重要性对构造主路径的影响。

图2 不同SPC值调节后的主路径
4 实验结果与分析
本文构建了基于引文重要度指标的主路径分析方法,探讨了Altmetrics的知识流动路径。随着社交媒体的发展,传统的学术评价方法不能全面有效反映出科学研究工作的影响力,因此2010年Alt‐metrics一经提出便获得了广泛的关注[60]。Altmetrics通常被译为“替代计量”或“补充计量”,它作为一种补充性指标用于计量网络环境下的学术影响力[61],因其可评价多种类型学术资源、开放性强和及时的特点,许多学者讨论了Altmetrics指标的优势、缺陷和应用价值,探究了其指标的内涵及其与引文指标之间的相关性。在一定程度上,这些文献围绕Altmetrics形成了一个研究的主题领域,在这个研究领域中必然存在着相应的知识流动。因此本研究在Web of Science核心数据集中,以检索词=“Altmetric*”或“Alt-metric*”或“Alternative met‐ric*”在主题项中进行检索,检索时间为1985年1月1日至2020年11月9日,得出检索结果512条,共计21109条引文。
4.1 数据处理
先将根据科研论文的IMRaD写作结构将文献划分为Introduction、Method、Results、Discussion这4个部分。其中262篇文献能根据论文章节的标题顺利划分为四段体,其他论文并不完全符合IMRaD写作结构。然后采用引用频次分数计数法计算每条引用内容处相关引文的引用权重,并记录引文出现的位置。在如图3所示的引文文档关系中,文档D1、D2与引文C5的引文关系可表示为:D1:C5(1,L1);D1:C5(1/2,L3);D2:C5(1,L0)。其中,“:”表示施引关系;括号内的值分别是引用权重与引用位置;文档D1是可划分为IMRaD结构的文档,文档D2为非IM‐RaD结构文档;L1=Introduction位置,L2=Method位置,L3=Results位置,L4=Discussion位置,L0为非IMRaD结构文献的引文位置标记。

图3 文献的引文分布
4.2 引文的引用权重与位置分布
对512篇文献的引文在全文中的引用强度进行计算后,发现引文在全文中的引用权重的值分布在[0.06,18.33]。“0.06”表示在21109条引文数据中,某些引文在全文中仅提及一次,且为非独立引用(引用权重为1/16);“18.33”表示某条引文在全文中提及多次,经检查发现该条引文在全文中共计出现22次,其中16次为独立引用,6次为非独立引用。表1为引用权重值域区间的分布情况。引用权重≤0.5的引文有7546条,占总体引文的35.75%,说明有近35.75%的引文在全文中仅出现一次,且为非独立引用,这部分引文在施引文献全文中没有独立的知识价值贡献;引用权重≤1的引文占总体的79.74%,即有近80%的引文在全文中仅独立引用一次,或非独立引用几次;1<引用权重≤2的引文占总体的12.81%,引用权重>2的引文占总体的7.45%。表2为262篇符合IMRaD结构文献的引文分布情况,统计了其中文献占比排名前六位期刊的引用位置平均分布情况,发现这些分布相对稳定,大部分引用更多地集中在引言部分中,约83.27%,方法部分的引用相对少于结果和讨论部分。整体引用在不同位置的数量分布为:Introduction部分>Dis‐cussion部分>Results部分>Method部分。虽然学者们认为出现在方法、结果和讨论部分的引文对施引文献的价值比仅出现在简介部分的引文更高,但对各部分出现引文的重要程度并无统一论断。张琳等[62]在使用IMRaD结构测量文献的学科交叉度时,采用熵值法计算出四个部分引文的权重。本研究对其参数进行归一化处理后得到各个位置的权重分别为:L1=1,L2=1.5,L3=1.35,L4=1.1;对不能划分位置的引文位置权重L0赋值为1。
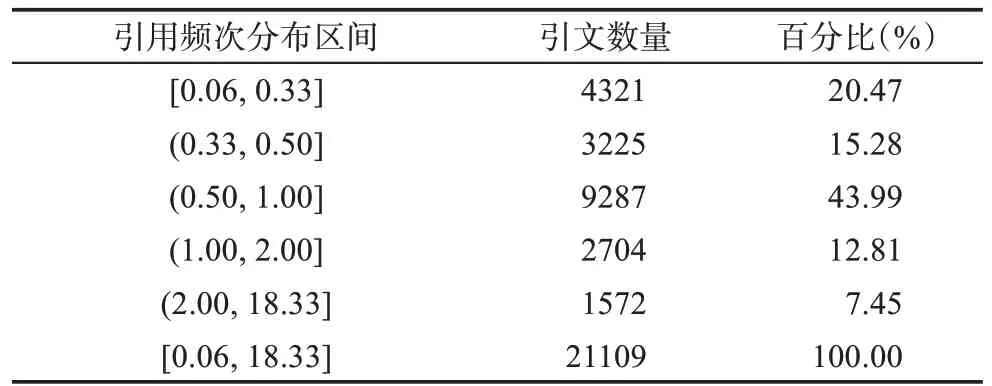
表1 基于全文的引文权重分布

表2 基于全文的引用位置分布
4.3 实验结果分析
本文在构造主路径时计算了4种“遍历计数”方法,作为衡量引文网络链接重要性指标:①传统搜索路径链接计数(SPC);②基于引用频次加权的搜索路径链接计数;③基于引用位置加权的搜索路径链接计数;④基于引文重要度的搜索路径链接计数。接着为了展示基于引文重要度的加权调节对知识流动主路径产生的影响,分别采用全局(glob‐al)和关键主路径(key-route)两种路径搜索算法来构造主路径。全局搜索算法构造的主路径使一个领域的主要发展路径清晰可见,关键主路径搜索算法有助于从不同的角度揭示许多重要的发展路径[20]。根据已采集的数据集的特征,实验分为两个数据集进行。图4是数据集1的512篇文献构造的主路径,图5是数据集2的262篇文献构造的主路径。每张图中所有的节点和链接为关键主路径(keyroute)搜索算法构造的主路径,加粗链接是采用全局(global)搜索算法构造的主路径;箭头指示知识流的方向。
主路径分析作为一种定量分析方法,从给定的引文网络中提取出重要路径,并将其作为知识通过引文链接从被引文献向施引文献的传播轨迹。从图4a与图5a可以看出,数据源的不同会直接影响主路径分析结果。图4的主路径来自512篇文献,21109条引文构造的32162条链接所形成的引文网络;图5的主路径来自262篇文献,10797条引文构造的17564条链接所形成的引文网络。数据集的不同会导致主路径不同,如果缺失的文献具有一定的重要性或是潜在的主要路径文献,那么结果将受到很大影响。
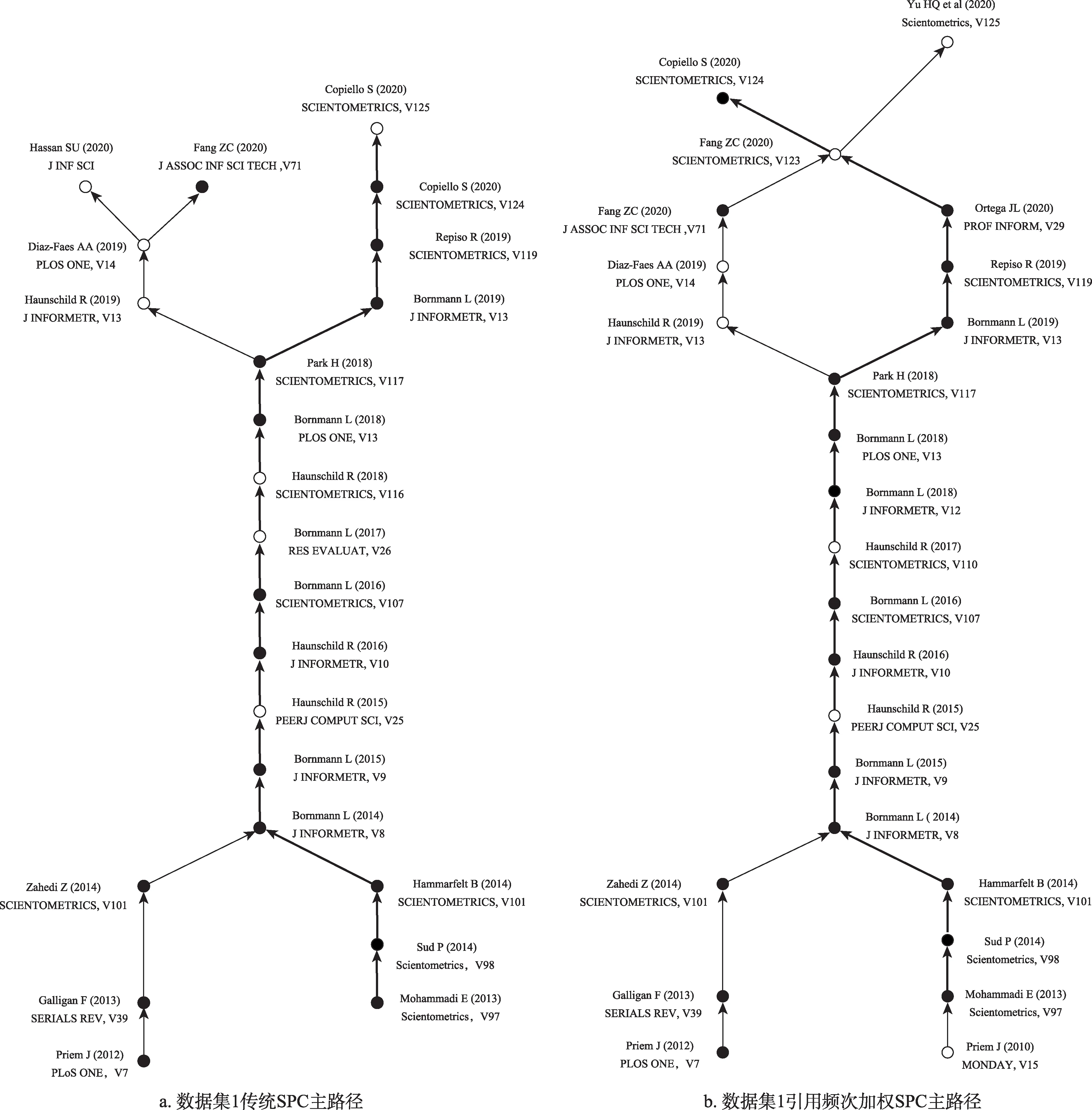
图4 数据集1不同SPC值调节后的主路径
假设主路径分析的目的是从能代表特定领域研究发展关键节点的目标文献数据集中检索相关文献,那么可以使用3个指标来检查主路径分析的性能:精确度(Precision)、召回率(Recall)和F1值(F1-Score)。在本研究中,检索到的相关文献是指同时存在于主要路径和目标文献数据集中的文献,因此精确度是检索到的相关文献数量除以主路径上的文献总数,召回率是检索到的相关文献数除以目标文献数据集中的文献数。本研究筛选了一个包含98篇文献的核心文献数据集,其中512篇文献集中包含98篇核心文献,262篇文献集中包含70篇核心文献。在图4和图5中,空心圆节点代表该文献不在核心文献数据集中,不是重要的发展节点,实心圆节点代表该文献在核心文献数据集中。
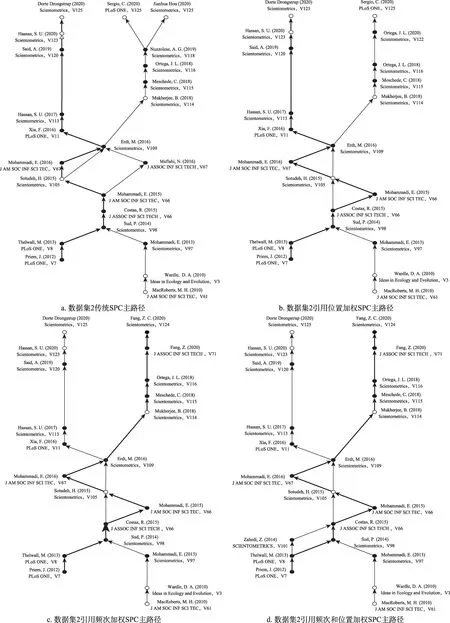
图5 数据集2不同SPC值调节后的主路径
通过图4a与图4b,以及图5a与图5d的对比可以发现,经过引文重要性加权调节后构造的主路径与原始主路径知识流动的路径和节点基本一致。通常只在源点、汇点和关键的分叉路径处有差别,而路径的主干相对稳定;而且样本数据量越大,路径越稳定。我们进一步对各种引文重要度指标加权调节构成的关键主路径和全局主路进行分析,比较它们的精确度、召回率和F1值(表3),结果显示,不同调整方法的主要路径包含不同数量的核心文献以及不同总量的节点文献。通过分析表3可知,数据集1和数据集2的主路径在经过引用频次加权调节后其精确度、召回率都有明显提升,数据集1全局主路径的精度由0.750提升至0.788,F1值由0.210增加至0.242;数据集2的关键主路径精度由0.652提升至0.714,全局主路径精度由0.769升至0.846。数据集2经过引用位置加权调节后,虽然全局主路径的精确度和召回率均不变,但在关键主路径的精确度有所提升;而数据集2经过综合相关度加权调节后的关键主路径和全局主路径F1值均为本实验的最佳值,分别为0.348和0.265。实验结果表明,考虑引文重要性可以提升主路径分析方法的性能。

表3 不同加权调节主路径分析效果
5 总 结
5.1 引文重要性对主路径的影响
传统主路径分析不考虑被引文献对施引文献的相对价值,将所有引文一视同仁,本文试图通过计算引文重要度来解决这个问题。通过分析发现,基于引文重要度的加权确实会对主路径产生影响,但不会改变整个主要路径。图4b与图4a相比,在节点(Copiello S(2020)SCIENTOMETRICS,V124)与节点(Repiso R(2019)SCIENTOMETRICS,V119)之间增加了两个2020年的文献节点;而对比于图5a,图5c在2020年至2016年之间虽然丢失了一个2017年的文献节点,但增加了3个2018年的文献节点,这表明考虑引文重要度会增加主路径节点与节点之间在时间上的连续性。通过引文重要度的加权调节能提升主路径分析方法找到关键节点的能力,增加主路径节点链接间的相关性。在全局主路径上,图4b比图4a多两个核心文献节点,图5d比图5a多一个核心文献节点;在关键主路径上,图4b比图4a多两个核心文献节点,图5d比图5a多两个核心文献节点。同时,通过引文重要度的加权调节也能增加主路径分析的链接溯源能力,加权调节后图4b的源点修正为(Priem J(2010)MONDAY,V15),正是在2010年,Priem J提出“Altmetrics”这一概念。
5.2 引文位置和引用频次对主路径分析的影响
通过图5b、图5c与图5d的两两对比可以发现,引文重要度加权调节与引用频次加权调节的全局主路径结果完全一致,关键主路径只多一个文献节点,关键主路径的F1值差值仅为0.19,区别不大。这表明在本研究中,基于引用频次的加权调节在主路径的构成中起决定性作用,即基于全文引用频次的加权方法比基于全文位置对加权方法更能区分引文对施引文献的相对价值。
通过分析引用频次与引文网络中的链接关系发现(表4),在数据集1和数据集2中分别有4321和2276条引文对在数据集全文中的引用频次≤0.33。删除这些引文对后,数据集1和数据集2的引文网络分别减少4181和1956条链接,即减少这20%的数据量,整体引文网络的链接仅分别减少13%和11.14%。这表明绝大部分在全文中非独立引用1次的文献,不仅在施引文献中的知识贡献低,且在整体的引文网络的链接中也不具有显著性。从这个角度来看,引文对施引文献的价值贡献随着其在全文中提及频率的增加而变得更加清晰,大多数非独立且仅使用一次的参考文献属于敷衍性的引用,删除这些节点并不影响主路径的构造。
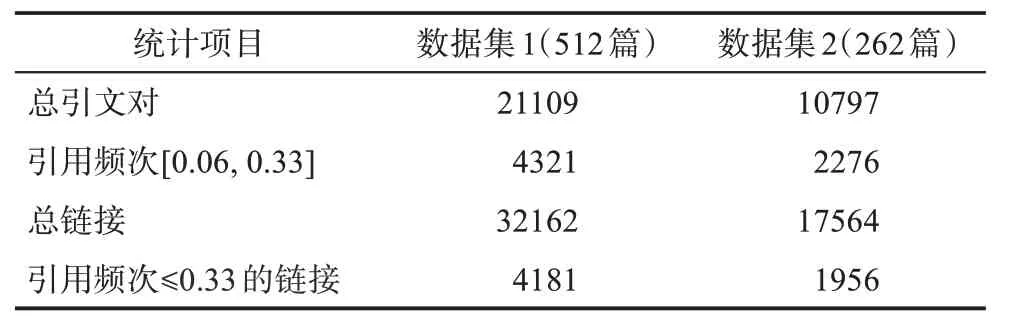
表4 引用频次与引文链接关系
6 结 语
为了克服传统主路径分析不考虑引文对施引文献相对价值的问题,本文构建了参考文献的“引文重要度”指标来衡量引文链接的重要性,对主路径分析方法中的链接遍历计数进行加权调节,改善主路径分析方法在引文网络中进行知识流动路径分析的应用效果。研究结果发现,通过引文重要性的加权调节可以增加主路径链接在时间上的连续性,提高主路径分析方法的链接溯源能力,增加链接节点间的相关性,提升主路径分析方法找到关键节点的能力。本文虽然通过引文重要度指标来表示被引文献对施引文献的重要程度,并进行了探索性研究,但实际学术文献中的引用行为非常复杂,不同的引用动机和引用语境在知识的扩散、传播、利用与创新中承担着不同的作用,后续研究应更加准确地衡量不同引文语境和引文动机对引文重要性的影响,更加客观体现引文网络中知识流的传播、利用与创新等关系。
