融合上下文信息的隐式情感句判别方法
2022-06-07王素格王敏廖健陈鑫
王素格,王敏,廖健*,陈鑫
(1.山西大学 计算机与信息技术学院,山西 太原,030006;2.山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原,030006)
0 引言
文本情感分析[1]是自然语言处理领域最热门的研究方向之一,在产品评价、社会舆情分析、基于内容的推荐等方面具有巨大的应用潜力。由于人们表达情感或观点的方式多种多样,既可以使用明确的显式情感词语表达[2],也可以使用含蓄的陈述性的事实表达。因此,Liu[3]将情感分为主观观点(subjective opinion)和事实蕴含观点(fact-implied opinion),前者是给出情感倾向或意见的主观陈述,而后者则是通过客观陈述隐晦地表达情感。Liao等[4]将隐式情感句定义为“表达主观情感但不包含显式情感词的语言片段”。据统计,汉语中约有15%~20%的句子含有隐式情感[4-5]。与显式情感分析[6-7]相比,隐式情感分析存在句子本身提供的信息不足的问题,需要从上下文中引入新的信息。
现有的隐式情感分析工作主要集中在语料库构建和隐式情感句判别。Chen等[8]收集了不含情感词的中文酒店评论,构建了双隐式语料库。他们发现,隐式情感与其相邻的显式情感在情感极性上往往是一致的。Deng等[9]利用语境中的显式情感线索以及对主观事件的推断来检测隐式情感。Liao等[5]提出了一个面向社交媒体的细粒度的、层次化的情感标注框架,构建了一个包含显式和隐式情感语句的大型语料库。Zhang等[10]构建了一个隐喻语料库,对语料的情绪类别和强度进行了标注。Kauter等[11]提出了一种新的细粒度方法来识别财经新闻和评论中的显式和隐式情绪。Liao等[4]提出了一种基于表示学习的多层次语义融合方法,该方法学习并融合了三个不同层次的特征——单词、句子和文档层次,以识别事实型隐式情感句,但该模型受到了语法结构的限制。BiLSTM(bi-directional long-short term memory)[12]序列学习模型能够有效地捕捉长依赖性序列的语义,并通过引入注意力机制[13-15]自动为句子中的单词分配不同的权重。Wei等[16]提出了一种基于多极化正交注意机制的隐式情感分类模型MPOA,该模型通过有效地模拟词汇和特定的情感极性注意力之间的差异,提升隐式情感分类的性能。上下文信息作为隐式情感句的背景信息[17],可以还原语言环境。Zuo等[18]提出了一种基于上下文的异构化图卷积网络(CsHGCN)框架,该框架将整个文档级别的上下文视作异构图,保持其中的依赖结构,并使用图卷积网络(GCN)获取隐式情感句和上下文的特征,融合两种信息提高了隐式情感句判别的准确性,但并未考虑到隐式情感句的重要特征,不同情感极性和隐式情感句词汇之间的差异。徐昇等[19]提出了一个三层注意力网络模型(TLAN),该模型通过模拟人类双向阅读和重复阅读过程,对中文隐式篇章关系进行识别。潘东行等[20]提出了一种融合上下文语义特征的模型,用于隐式情感句判别,该模型通过引入上下文信息,并重点关注与隐式情感句判别任务相关的上下文,提升了中性隐式情感句的判别效果。赵容梅等[21]提出了一种新型混合神经网络模型,通过卷积神经网络对隐式情感句和上下文提取特征,在词级别和句级别分别加入注意力机制,对隐式情感句更好的表示。然而,这些模型没有在利用隐式情感句和情感极性之间的关系的同时,结合上下文信息对隐式情感句信息进行有效的扩充,尤其是当隐式情感句的上下文信息改变时,其情感倾向有可能随之变化,如表1所示。其中,Target表示隐式情感句,Context表示上下文信息。
表1中的示例E1和E2仅考虑隐式情感句本身,无法判断情感倾向,若引入其上下文信息,可减小判断情感倾向的难度。E1描述了租的房子上班方便,表达了褒义的情感。但对于E2,上下文环境发生了变化,其信息中体现出不完全的无奈,表达了一种贬义的情感。

表1 上下文对隐式情感句影响示例Table 1 Examples of the influence of context on implicit sentiment sentences
根据上述分析,本文提出一个融合上下文信息的多极性正交注意力的隐式情感句判别方法(Context-Based Multi-Polarity Orthogonal Attention mechanism,C-MPOA)。该方法利用不同情感极性和隐式情感句词汇之间的差异,引入上下文信息扩充原有的字面意义,以解决隐式情感自身信息不足的问题。本文的主要贡献如下:
(1)使用多极性正交注意机制对隐式情感句表示,捕获不同情感极性和隐式情感句词汇之间的差异,作为隐式情感句的重要特征。
(2)使用隐式情感句表示作为查询向量,自动关注其上下文,以弥补隐式情感句中信息的不足。
1 融合上下文信息的隐式情感句判别框架
根据引言对隐式情感句判别问题的分析,将上下文信息作为背景信息,建立一种融合上下文信息的多极性正交注意力的C-MPOA模型,丰富隐式情感句的表示。模型框架图如图1所示,其中,虚线箭头表示注意力权重,实线箭头表示数据流操作,虚线框表示一组向量化数据,例如qneu、qpos和qneg为不同极性的查询向量,图中Attention表示多极性注意力机制,Orthogonal Punish表示模型优化部分,使不同极性的查询向量正交。
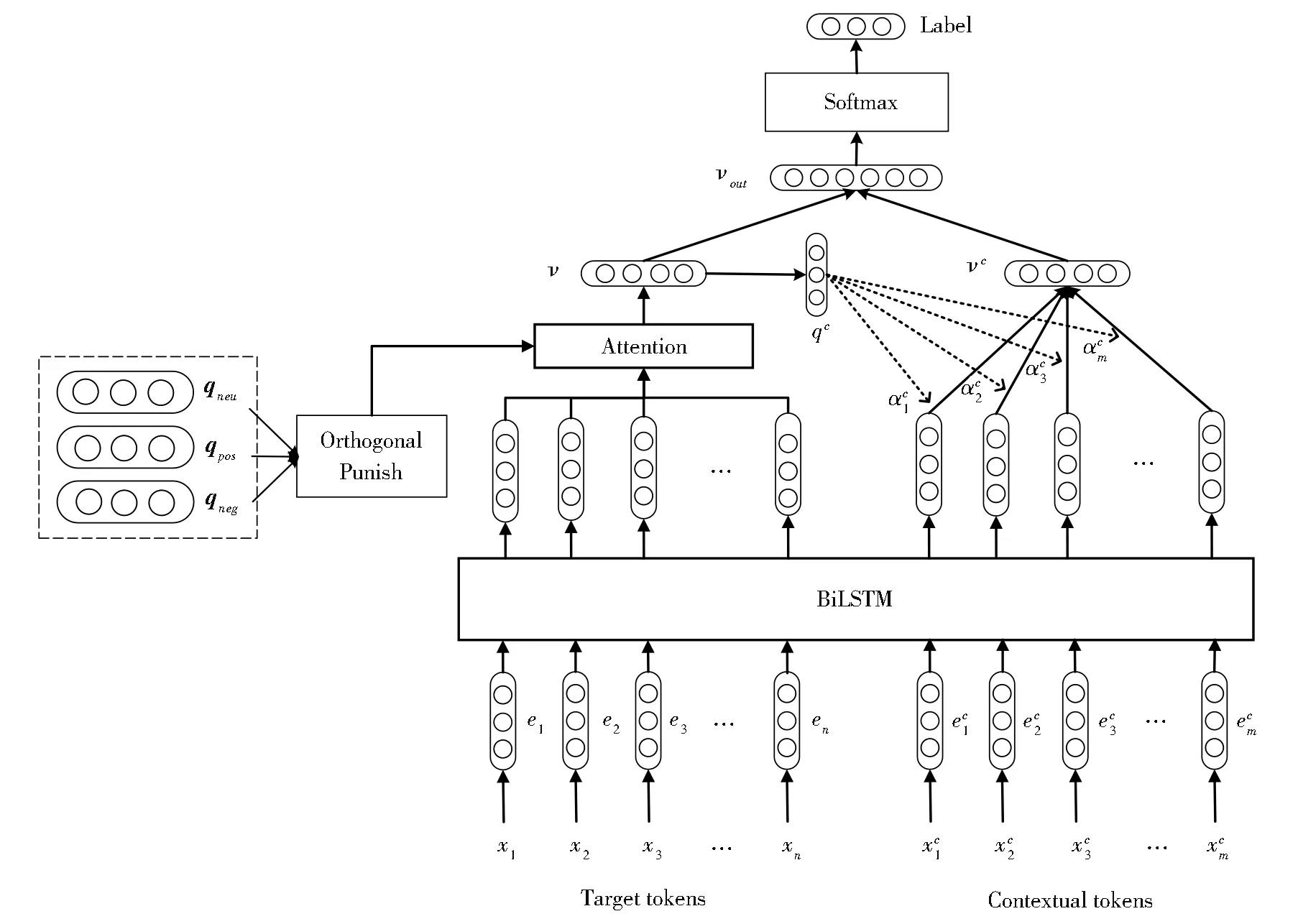
图1 融合上下文的多极性正交注意力模型框架Fig.1 Framework of context-based multi-polarity orthogonal attention model
该模型由3层组成:预训练层、融合上下文的多极性注意力层和输出层,详细描述如下:
(1)预训练层
该层主要对隐式情感句和上下文进行预处理。给定一个隐式情感句(target tokens)S=(x1,x2,…,xn),S的 上 下 文(contextual tokens)为,其中n和m分别为S和C的句子长度。预训练资源中的词向量可以捕获句子中词汇间的动态语义,为模型提供大量的初始语义信息。因此,将S和C分别使用预训练的词向量初始化表示为S=(e1,e2,…,en)和其中,ei,,de是单词表示的维数。
(2)融合上下文的多极性注意力层
该层利用多极性注意力机制将隐式情感句和上下文信息融合建模,强化隐式情感句中的信息。并考虑正向和反向方向序列,以更精确地捕获序列的上下文信息,由此采用BiLSTM对隐式情感句S和上下文C进行隐层表示,得到S和C的隐层表示其中,是第i个词在S中的隐层表示,类似的,是第j个词在C中的隐层表示,为BiLSTM的隐层单元数。
为了将情感极性标签信息融入隐式情感句S表示,使用不同极性的注意力机制,引入特定极性的查询向量,使注意力机制更多的关注不同情感极性间的差异。假设 Q={qpos,qneg,qneu},qpos,qneg,qneu分别对应情感极性为褒义、贬义和中性。q∈Q为特定极性的查询向量,vq是句子在情感极性q下的表示。具体见公式(1)-(3):

对于上下文C的表示,将上下文C视为一个整体,使用经全连接层变换后的隐式情感句表示qc作为查询向量为C中的每一个词汇分配权重,对上下文信息进行词级别的注意,使得模型能自动关注到上下文中与隐式情感句相关的关键信息。上下文的表示vc见公式(5)-(8):
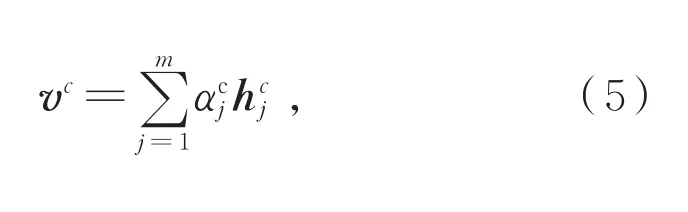
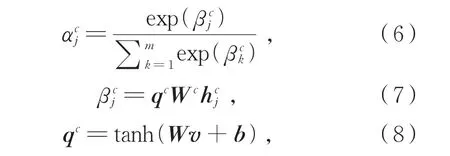
其中,W和Wc为参数矩阵,b为偏置,为上下文的词级别注意力得分,为由计算出的归一化权重,vc为上下文的表示,vc∈R3dm。
将隐式情感句表示v与上下文表示vc拼接,得到融合了上下文信息的隐式情感句表示,见公式(9):

(3)输出层
融合上下文信息的隐式情感句表示vout,映射到情感极性类别空间内,并通过公式(10)将每个类别的分数归一化到一个近似概率值,
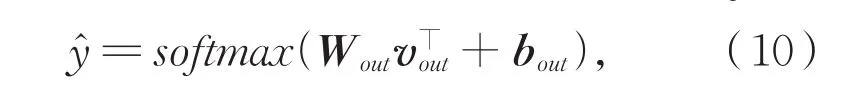
其中,Wout和bout分别为权重矩阵和偏置。
训练阶段采用交叉熵损失函数进行模型优化,见公式(11):
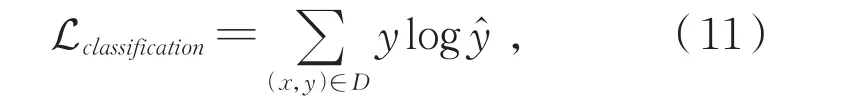
其中,x为目标句,y为句子的真实标签,D为语料库。
在模型优化过程中,通过最小化损失函数(公式(12))保持每个特定情感极性查询向量的正交性,使得模型在优化过程中能够始终保持对各情感极性注意力差异性[16],
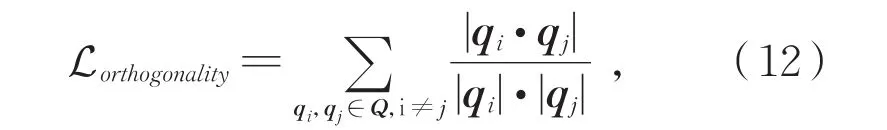
其中,qi,qj∈Q为特定情感极性的查询向量,Lorthogonality对任意一对注意力查询向量间的余弦相似度度量。
在模型训练过程中,将正交注意损失Lorthogonality引入到模型优化Lclassification中,使得查询向量间的余弦相似度最小化。最终损失函数如公式(13)所示:
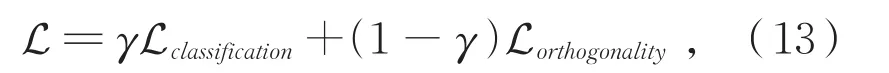
其中,γ为一个参数,用于调整两部分损失间的权重。
2 实验及结果分析
2.1 数据集及评价指标
(1)数据集
本文采用第八届社会媒体处理会议的中文隐式情感分析数据集SMP2019-ECISA①https://www.biendata.xyz/competition/smpecisa2019/作为实验数据集。该数据主要来自微博②https://weibo.com和一些热门论坛,如马蜂窝③https://www.mafengwo.cn/,携程④https://www.ctrip.com/,汽车之家⑤https://www.autohome.com.cn/。微博的数据主要集中在若干社交事件或事件上,论坛的数据主要集中于某些产品或服务上。一些重复的句子已提前删除。数据集概况见表2。
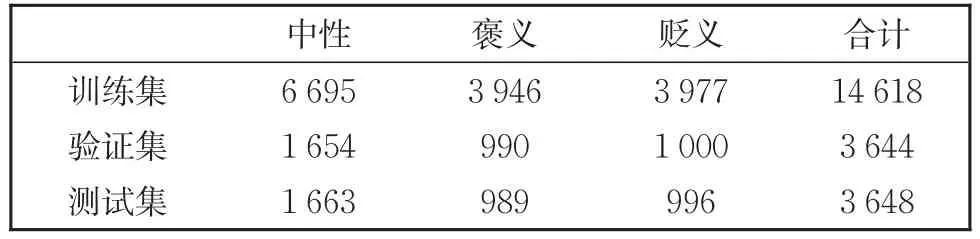
表2 数据集概况Table 2 Overview of dataset
(2)评价指标
本文的实验评价指标采用各情感极性下的F1值和宏平均F1值,以验证C-MPOA模型的有效性,见公式(14)-(15)。
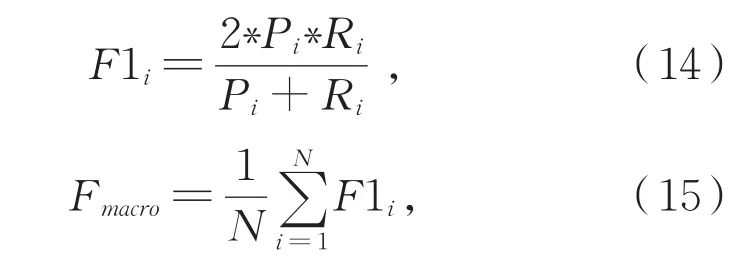
其中,i∈{pos,neg,neu}是一种情感极性,Pi,Ri和F1i分别为情感极性i对应的准确率、召回率和F1值。
2.2 实验设置
(1)模型参数
本文模型C-MPOA的实现基于PyTorch⑥https://pytorch.org/框架,模型超参数设置见表3。
表3中的TENCE、Random和ELMo分别表示预训练层中词汇采用TENCE-AI-LAB⑦https://ai.tencent.com/ailab/nlp/en/embedding.html词向量静态初始化、随机初始化和ELMo预训练模型⑧https://github.com/HIT-SCIR/ELMoForManyLangs动态初始化。
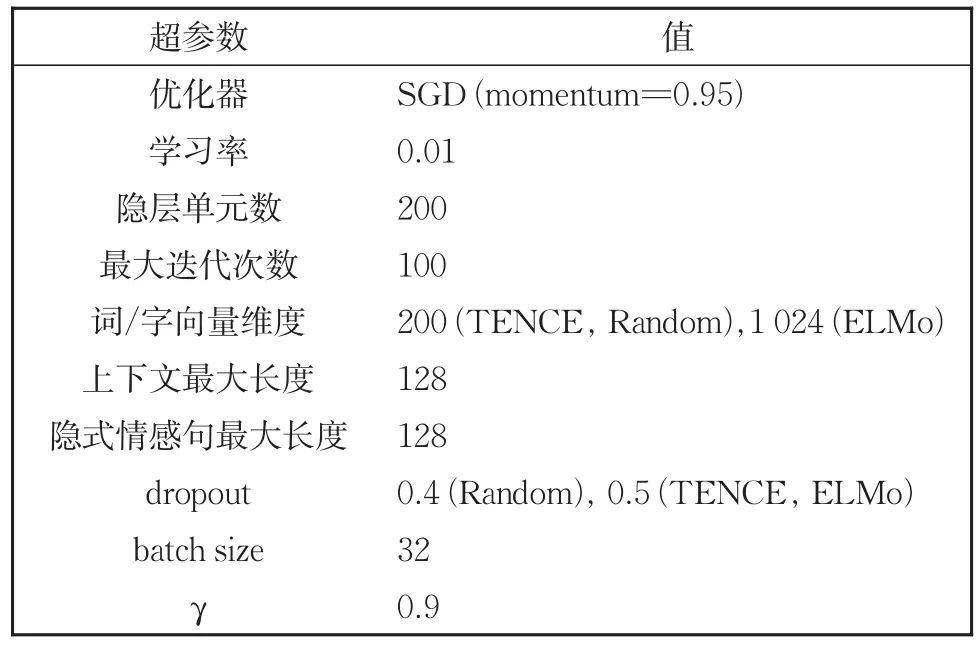
表3 模型超参数设置Table 3 Hyperparameter settings for the model
(2)基线方法
为了验证本文模型C-MPOA的有效性,本实验使用如下的基线方法与C-MPOA模型对比。具体对比方法如下:
MPOA[16]:使用多极性正交注意力机制对隐式情感句表示,以判别隐式情感句。
CsHGCN[18]:使用基于上下文的异构化图卷积网络模型,对隐式情感句及其上下文建模,以判别隐式情感句。
BiLSTM+att+C:与本文所提方法不同之处是,隐式情感句表示部分使用的注意力机制是自注意力机制,其余与本文提出的模型CMPOA相同。
2.3 实验结果及分析
利用本文所提C-MPOA模型与第2.2节的基线方法,在SMP-ECISA数据集上进行隐式情感分析的对比实验,实验结果如表4所示。其中,F-neu、F-pos和F-neg分别对应中性、褒义和贬义情感极性的F1值。F-macro是三种情感极性下的平均得分。括号里的词指的是不同的预训练初始化模式。加粗的结果表明,相应的方法在所有基线中取得的最好的性能。
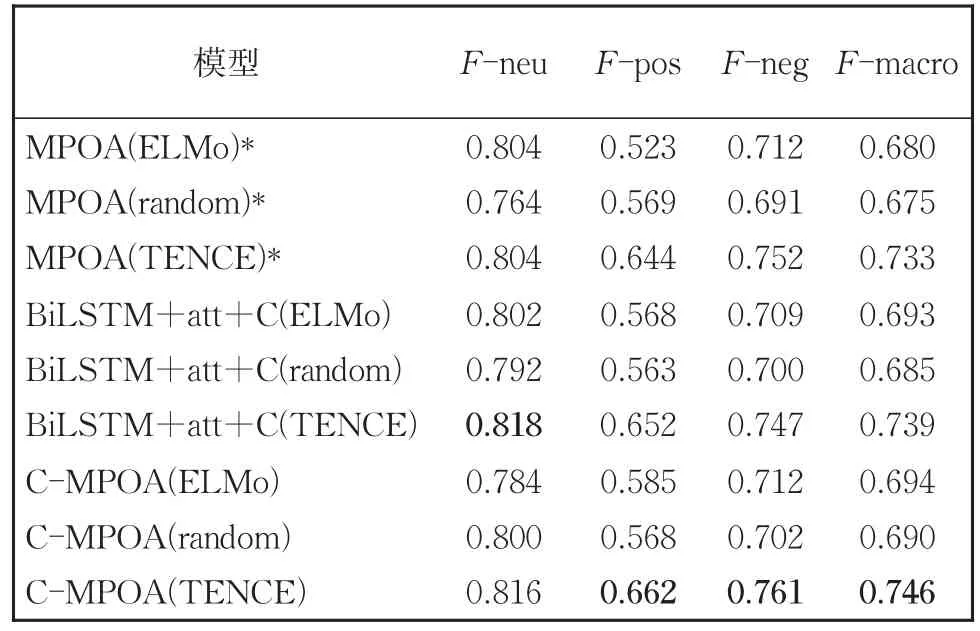
表4 模型C-MPOA与基线方法比较实验结果Table 4 Experimental comparison results between model C-MPOA and baseline methods
由表4的实验结果可以看出:
(1)在相同的预训练模型下,本文的模型C-MPOA与MPOA模型相比F-macro值可提高1.5%,说明了引入上下文信息可以对隐式情感句信息扩充,使其更准确地表示。
(2)在相同的预训练模型下,本文的模型C-MPOA与基线模型BiLSTM+att+C相比,实验结果均有所提高。说明了多极性注意力机制的有效性,它能够捕获情感极性和隐式情感句表示之间的差异,有助于提高隐式情感判别的性能。
(3)预训练方式为ELMo的结果普遍优于random。其原因是,ELMo是一个已在大规模语料库上预训练的模型,为本文模型提供了丰富的初始语义信息,在一定程度上证明了预训练语言模型的有效性。
(4)预训练方式为TENCE的方法与ELMo方法相比,取得了更好的效果。这表明利用大规模语料预训练的静态词向量资源含有更多、更丰富的语义信息,在隐式情感数据规模较小时可以起到良好的信息补充作用。
需要说明的是,CsHGCN模型同样加入了上下文信息,它的实验结果F-neu、F-pos和F-neg分别为 0.883、0.638和 0.786,F-macro为0.769,其性能高于本文的方法。其原因是,Zuo等[18]将 SMP2019-ECISA 数据集中训练、验证集进行融合,并按照8∶1∶1的比例进行划分作为数据集,CsHGCN模型在该数据集上训练、验证以及测试,而本文使用SMP2019-ECISA数据集,训练集和测试集分布存在一定的不一致性,导致实验结果有所差别。
3 结论
针对隐式情感句中信息不足的问题,本文提出了一种融合上下文信息的隐式情感句判别方法C-MPOA。该方法充分利用隐式情感句上下文信息以及注意力机制自动挖掘对隐式情感判别具有重要作用的关键上下文信息。相比于之前在隐式情感分析方面的工作,本文在关注隐式情感句和情感极性之间差异的基础上,利用上下文对隐式情感句的信息进行了扩充,丰富了句子的语义表达,提升了隐式情感句判别的性能。在SMP2019-ECISA隐式情感分析数据集上的实验显示,相比于基线方法本文提出的模型性能得到了提升,验证了该方法的有效性。
下一步的工作我们将聚焦于隐式情感句表示中融入情感常识的表示以及引入语义推理机制,对隐式情感句及其上下文信息更准确地进行建模和深度理解。
