基于DDPG的风电场动态参数智能校核知识学习模型
2022-06-06周庆锋王思淳李德鑫刘佳琪李同
周庆锋,王思淳,李德鑫,刘佳琪,李同
(1. 东北电力大学 电气工程学院,吉林 吉林 132012;2. 国网吉林省电力有限公司电力科学研究院,吉林 长春 130000)
0 引言
随着风电渗透率不断增加,电力系统在线安全分析对电力系统的动态行为有着不容忽视的影响[1-3]。动态行为愈发复杂是多数可再生能源接入电力系统后的必然结果[4-5]。对于传统仿真验证方法而言,其仿真轨迹和实测轨迹往往存在较大偏差,会影响在线安全分析的可信度,对电网安全较为不利[6-7]。
在模型参数校正方面,目前已有较多研究。文献[8]提出基于粒子群的寻优算法(particle swarm optimization, PSO)的发电机参数校正方法,但该方法运算时间较长,精度较低,不适用于多参数的校正。文献[9-10]提出基于轨迹灵敏度理论的发电机参数校正方法,但该方法依赖于发电机模型和参数,不适用于灵敏度相近的系统。
随着社会不断发展,人工智能(artificial intelligence,AI)在电力系统领域的应用愈发广泛[11-13]。文献[14]利用人工智能方法诊断电力系统中的故障,效果显著。文献[15]运用人工智能技术分析电力系统暂态问题出现的新特点。文献[16]将一些人工智能方法用于电力调度场景中,但精确度不足。
综上,已有的发电机参数校正方法存在求解维数受限、需要辨识主导参数等问题,利用人工智能新方法解决复杂高维的参数校正问题的研究还不够深入。本文提出了一种基于深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法的校正方法,精确度较高,适用于结构复杂的模型。
1 双馈风电机组模型
1.1 风力机模型
大型变速风电机组一般采用双馈式异步发电机 (double fed induction generator, DFIG)。本文以双馈式风力发电机组为例进行研究,风力机模型为

式中:Pw为机械功率; ρ为空气密度;Cp为风能利用率;R为叶片长度; λ为叶尖速比; θp为桨距角;vm为风速; λL为中间变量。
1.2 DFIG模型
本文将坐标系转换成与转子同步旋转的两相坐标系,以简化模型,得到磁链方程为

式 中 : ψds、ψqs分别 为 定 子d、q轴 磁 链 ;ids、iqs分别 为 定 子d、q轴 电 流 ; ψdr、 ψqr分 别 为 转 子d、q轴磁链;idr、iqr分别为转子d、q轴电流;Xs、Xr、Xm分别为定子电抗、转子电抗、励磁电抗。
电压方程为

式中:Vds、Vqs分别为定子d、q轴电压;Vdr、Vqr分别为转子d、q轴电压;Rs、Rr分别为定子、转子电阻; ωm为转子转速。
转子运动方程为
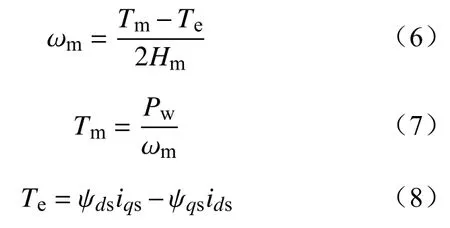
式中:Tm为机械转矩; Te为 电磁转矩; Hm为转子转动惯量。
1.3 转子侧变流器模型
转子侧的变流器输出的有功功率受转子电流控制[17-18]。为了保证风电机组输出功率的波形稳定,对转子q轴的电流进行限流。转子控制系统如图1所示。在图1中,s为转差率;iqrmax、iqrmin分别为转子q轴电流允许的最大值和最小值。变流器q轴方向的电流微分方程为


图1 转子控制系统Fig. 1 Rotor control system
1.4 网侧变流器模型
网侧变流器可用于稳定具有直流性质的母线电压。通过控制转子d轴电流,调整输出无功[19]。电压控制系统如图2所示。在图2中,idrmax、idrmin分别为转子d轴电流允许的最大值、最小值。变流器d轴方向的电流微分方程为


图2 电压控制系统Fig. 2 Voltage control system
2 强化学习方法的一般描述
(1)强化学习可通过某种方法或者某种鼓励的方式,让机器有更大的可能性产生同样的行为[20-22]。强化学习的2个重要特征分别为试错搜索和延迟奖励。
(2)表演者-评论家(actor-critic,AC)算法是强化学习中的一种很经典的框架[23-24]。表演者给出动作,评论家对网络选出的动作进行评价并更新权重,循环执行直到网络收敛。
(3)策略梯度法(policy gradient,PG)算法是强化学习中学习连续行为控制策略的经典方法,其输出是动作或动作出现的概率,而不是各动作的评价值[25]。策略梯度法的目标函数F(θ)为

式中: θ为神经网络的参数;ri为每一步所取得的回报; γ 为折扣系数;n为策略中的动作步数;E为数学期望。
策略梯度法的损失函数为

式中:f(s,a)为智能体在状态s下采取动作a得到的评价指标,若a被认为是好的,则通过最大化这个“好”动作的概率来优化策略,反之亦然;h为策略发生的概率。
(4)DDPG算法是一种基于AC框架的改进算法,其在确定性策略的基础上增加了一个服从高斯分布的噪声,使样本具有多样性。动作a的表达式为

式 中 : θµ为Actor网 络 的 权 重 参 数 ; µ (θµ)为Actor下网络输出值;N为噪声。
均方误差损失函数、采样策略梯度可分别表示为

式中:L为均方误差损失函数;y为目标值函数;Q为状态s下采取动作a得到的目标价值函数;∇J为采样策略梯度值。
3 基于DDPG的风场动态参数校正方法
3.1 主导参数的选择
本文选择10个参数进行校正。具体如下:定子电阻Rs、定子电抗Xs、转子电阻Rr、转子电抗Xr、激磁电抗Xm、惯性时间常数Hm、桨距角控制时间常数Tp、桨距角增益Kp、电压控制增益Kv、功率控制时间常数 T ε。
3.2 状态、动作和奖赏函数的设计
强化学习能够收敛的关键在于回报函数。本文构建的回报函数为
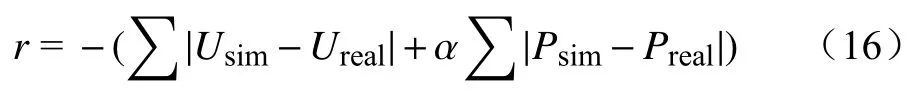
式中:r为回报函数值;Usim、Ureal分别为电压的仿真轨迹、实测值轨迹;Psim、Preal分别为有功的仿真轨迹、实测值轨迹; α为权重因子。
3.3 探索规则的设计
本文使用DDPG网络对状态量进行调整,不断进行“探索”与“利用”直至网络完全收敛。
初始方差 σ =3,记忆池中数据达到上限后,开始学习。 σ 在开始学习后的每个回合都会以一定比例减小,代表“探索”的比例在逐渐减小。最终 σ 将下降至近似于0,代表网络将不再“探索”,进行完全的“利用”。
3.4 DDPG算法流程
DDPG算法的整体流程如下。
(1)初始化仿真环境和网络参数,根据校核参数的上下限给出校核参数初值。
(2)通过策略探索得到调整后的校核参数,并与仿真环境交互得到回报函数值,然后将调整前后的校核参数、动作、回报函数值作为一条经验存入经验池中。通过不断地策略探索,当经验池中的经验足够多时,网络开始学习知识。
(3)网络学习知识的过程包括:①通过反向传递均方误差损失来更新当前Critic网络参数;②使用样本的策略梯度更新当前Actor网络参数;③每隔若干训练回合,将当前网络的参数赋给目标网络。
(4)当网络收敛后,离线学习过程结束,网络参数被当作“知识”保存下来。
4 算例分析
为验证所提方法的有效性,以某省网实际系统为例进行仿真,仿真时间5 s,仿真步长0.01 s,设定故障发生在 0.5 s,在 0.6 s 切除故障。采用8种传统启发式算法与DDPG算法对校核结果进行对比。采用的传统启发式算法如表1所示,其中种群数均为10,最大迭代数除SAA外均为100,精英个数均为2,校核的4个参数对象为Rs、Rr、Xm、Kv。为了使仿真轨迹和实测轨迹接近,算法目标函数f为


表1 启发式算法名称及缩写Table 1 Names and abbreviations of traditional heuristic algorithms
式中: α为权重因子,取1/6。
DDPG算法的网络采用3个全连接层,神经元个数分别为102 4、512、128,最大回合数为500,每回合最大步数为200,表演者网络学习率为0.001,评论家网络学习率为0.002。对4个参数、10个参数分别进行校核,校核对象取值范围见表2。

表2 校核对象上下限Table 2 Upper and lower limits of check objects
4参数的传统方法以及DDPG方法,用时均约为1 h,10参数的DDPG方法用时约为5 h。校核结果如表3~4所示,取传统方法中效果最好的MFO算法与DDPG算法进行电压及有功功率波形的对比,对比结果分别如图3~4所示。电压、有功功率比较结果分别如表5~6所示。

表3 4参数校核结果Table 3 Check results of 4 parameters

表4 10参数DDPG校核结果Table 4 DDPG check results of 10 parameters

图3 电压波形对比Fig. 3 Comparison of voltage waveform

图4 有功功率波形对比Fig. 4 Comparison of active power waveform
综合表5~6、图3~4可以看出,采用10参数的DDPG方法校核效果最佳,其电压值和有功值的平均绝对误差率分别为0.061 6%、1.645 8%,与校核前的0.193 2%、5.432 1%相比,分别提高了68.11%和69.70%。其得到的电压值和有功值的最大偏差分别为 0.004 4、0.085 9,与校核前的 0.010 8、0.548 1相比,分别提高了59.26%和84.33%。这些结果验证了所提出的智能校核方法可以显著减少电压和有功偏差。

表5 电压结果比较Table 5 Comparison of voltage results

表6 有功功率结果比较Table 6 Comparison of active power results
通过对比可以得出如下结果。
(1)同为4参数,DDPG给出的是一个次优解,但对于10参数而言,由于传统启发式算法的维度受限,DDPG算法校核效果明显更优。
(2)对于参数维度高的模型而言,虽然DDPG算法较传统启发式算法不具有时间效率上的优势,但是其具有更佳的校核效果。
(3)DDPG算法训练好的网络可以作为“知识”储存下来,为其他相似模型的训练提供借鉴,而传统方法不具有记忆性。
5 结语
针对发电机参数的复杂模型,本文以深度强化学习的DDPG算法为依托,提出了一种发电机组参数调整的人工智能算法,所提方法精确度较高,适用于结构复杂的模型。智能算法是在试验的基础上积累经验。神经网络从初始化到训练完备需要一定的时间,对于硬件的计算力的要求随着问题维度的升高而更加严格。因此,加快网络收敛速度、减少训练耗时、提高智能算法的运算效率是后续研究的主要方向。
