基于客观组合权-改进集对分析模型的矿井突水水源识别
2022-06-06姜春露查君珍郑刘根谢华东黄文迪陈园平
苏 玮,姜春露,查君珍,郑刘根,谢华东,黄文迪,陈园平
(1.安徽大学 资源与环境工程学院,安徽 合肥 230601;2.兖州煤业股份有限公司 东滩煤矿,山东 邹城 273512;3.安徽科垦工程科技有限公司,安徽 合肥 230601)
0 引 言
煤矿矿井常见的灾害有瓦斯、突水和顶板灾害等,水害是煤矿的第二大灾害,一旦发生突水,将会造成严重的人员伤亡和巨大的经济损失[1-2]。因此,快速准确地识别突水事件所涉及的水源,是解决和预防矿井水灾害的关键手段之一[3]。
针对矿井突水水源识别的方法较多,邓清海[4]、张好等[5]基于Bayes识别准则,结合主成分分析法对不同含水层进行了有效的识别;张淑莹等[6]运用独立性权系数对含水层水质指标进行赋权,再通过灰色关联度理论对水质数据进行水源识别;WANG等[7]将PCA主成分分析和熵权法对水化学数据进行提取和赋权,再采用层次聚类分析法建立了突水水源识别模型;胡伟伟[8]、陈建平等[9]基于矿区的水位地质条件建立了以同位素分析为基础的矿井水源识别模型;闫志刚[10]、王亚等[11]采用极限学习机算法建立计算机水源识别模型,该模型可以快速识别煤矿突水水源;周孟然[12]、闫鹏程等[13]将激光诱导荧光技术结合智能算法建立突水水源识别模型,可以快速地检测出突水水源的类型。这些方法在水源识别中都有良好的应用性,但仍然存在不足。
一方面是各水化学离子的权重不够合理,主观赋权法会因为个人偏好和主观随意性造成权重结果具有一定的偏向性,客观组合权能够从原始数据中提取信息,充分考虑了指标权重的真实重要程度,避免了主观赋权法带来的人为因素的影响。另一方面建立的水源识别模型多是以各个含水层水样数据的平均值为依据,根据突水水样数据与平均值间的关系来识别水源;或是根据不同含水层的水样数据建立数学函数,通过计算函数来确定水源,这些方法容易受到个别极大值或极小值的影响而降低识别效率。改进的集对分析模型通过水化学数据的上下四分位数建立各个突水水源的属区,将水样数据与属区进行计算从而确定各水样与各个含水层的集对势,根据集对势来识别矿井突水水源,降低了极大值或极小值对识别效率的影响。目前,集对分析已经在水质评价[14]、风险评估[15]、旱灾预测[16]和人工智能[17]等领域成功应用,在突水水源识别应用中次邻左值可能会为负值从而导致次邻左区间无法确定,为克服上述不足使用极值法对集对分析模型进行改进。利用客观组合权和集对分析理论相结合,建立客观组合权-改进集对分析模型的突水水源识别模型,能够提高识别模型的准确性,为矿井突水水源识别提供新的思路。
1 矿井突水水源判别研究方法
1.1 集对分析理论与改进
集对分析是处理事物确定与不确定关系的一种数学理论,是以集对与联系度来研究系统中的确定与不确定性及其转化规律的系统分析技术,可以定量处理模糊、随机、不确定性问题[18-19],其核心思想是将事物中客观存在的不确定性,以辩证分析(同、异、反)表示,即以某种联系度来描述事物的不确定性[20]。基本思路为:对集合构成集对M(X,Y),若集对M中有N个特征,其中S个特征为集合X和集合Y共同具有的,P个特征为集合X和集合Y对立的,其余F=N-S-P个特征不属于两者,采用联系度μ来表示集对的辩证关系:
(1)
其中:μ为集对的具体联系度;i和j分别为差异度系数和对立度系数;a=S/N为同一度;b=F/N为差异度;c=P/N为对立度,a+b+c=1并且N=S+F+P,同时a,b,c∈[0,1],a+b+c=1。
在实际问题分析中,仅将研究对象作一分为三的划分不够细化,若将式(1)中的bi进一步展开为bi=b1-i+b1+i,cj=c1-j+c1+j,即可得到五元联系度公式[21]为
(2)
式中:a+b1-+b1++c1-+c1+=1,对于突水水源识别,b1-和b1+为所属水源类型相邻的邻左区和邻右区系数,c1-和c1+为所属水源类型次相邻的次邻左区和次邻右区系数。
由图1所示,将各类水源的各水化学指标按图中分类分为5个区域。

图1 改进集对分析水源识别分区
X
T
2
T
3
X
T
2
T
3
T
1
T
4
a
μ
X
T
2
T
3
μ
[22]
(3)
1.2 客观组合权的确定
确定权重系数的方法有很多种,以主观赋权法和客观赋权法为主,主观赋权法是根据专家或学者的主观认知来判断各个指标的权重大小,例如层次分析法等[23];客观赋权法是利用统计学方法对原始数据的各个指标进行赋权,例如熵权法、基尼系数法等[24]。客观赋权法能够使得权重的分配不受个人偏好,最大程度地减少了主观确定权重带来的人为干扰。
熵权法通过计算某个指标的信息熵,将待评价指标的信息进行量化,可以反映该指标提供的信息量的多少及信息的效用,从而确定该指标在综合评价中的作用大小[25-26]。其确定权重步骤如下:
将每一个评价指标进行标准化,消除不同量纲的影响,公式如下:
(4)
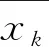
(5)
若式中pk=0时,则Ek=0。其熵值权重λk公式为:
(6)
变异系数法是一种客观计算权重的方法,通过直接各项指标信息得到权重值,能够有效客观地反映各个指标的差距[27-28]。具体计算公式如下:
第k项指标的变异系数Vk为
(7)
其中,S为某项指标数据的标准差;R为某项指标数据的平均值。各指标变异系数权重Mk为
(8)
把变异系数法和熵权法的结果进行组合,组合两种客观赋权法的指标权重ωk为
ωk=(1-a)λk+aMk
(9)
其中,λk为熵权法计算得到的权重;Mk为变异系数法计算得到的权重。a如何合理地取值,有很多专家学者讨论,参照前人研究结果[29]和指标体系的实际情况,本研究取a=0.5。
由式(3)确定联系度μ并组成联系度矩阵A,可与客观组合权矩阵B相乘计算出综合联系度矩阵P,其计算公式为
P=A·B
(10)
P反映出了待判别对象整体的联系度,由l,m,n组成,l为常数项,m为i的系数之和,n为j的系数之和。最后可计算待判别对象的集对势nsp[21],其计算公式为
(11)
2 矿井突水水源识别
2.1 研究区概况
东滩煤矿位于山东省邹城市、曲阜市与兖州区之间,矿区内主要河流为白马河(图2)。
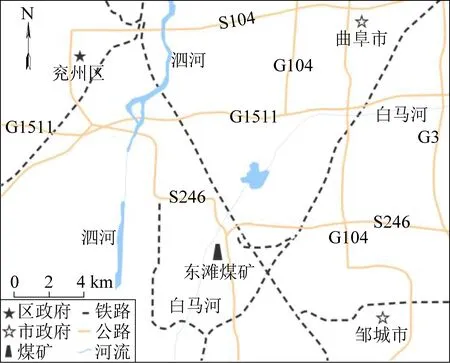
图2 研究区地理位置
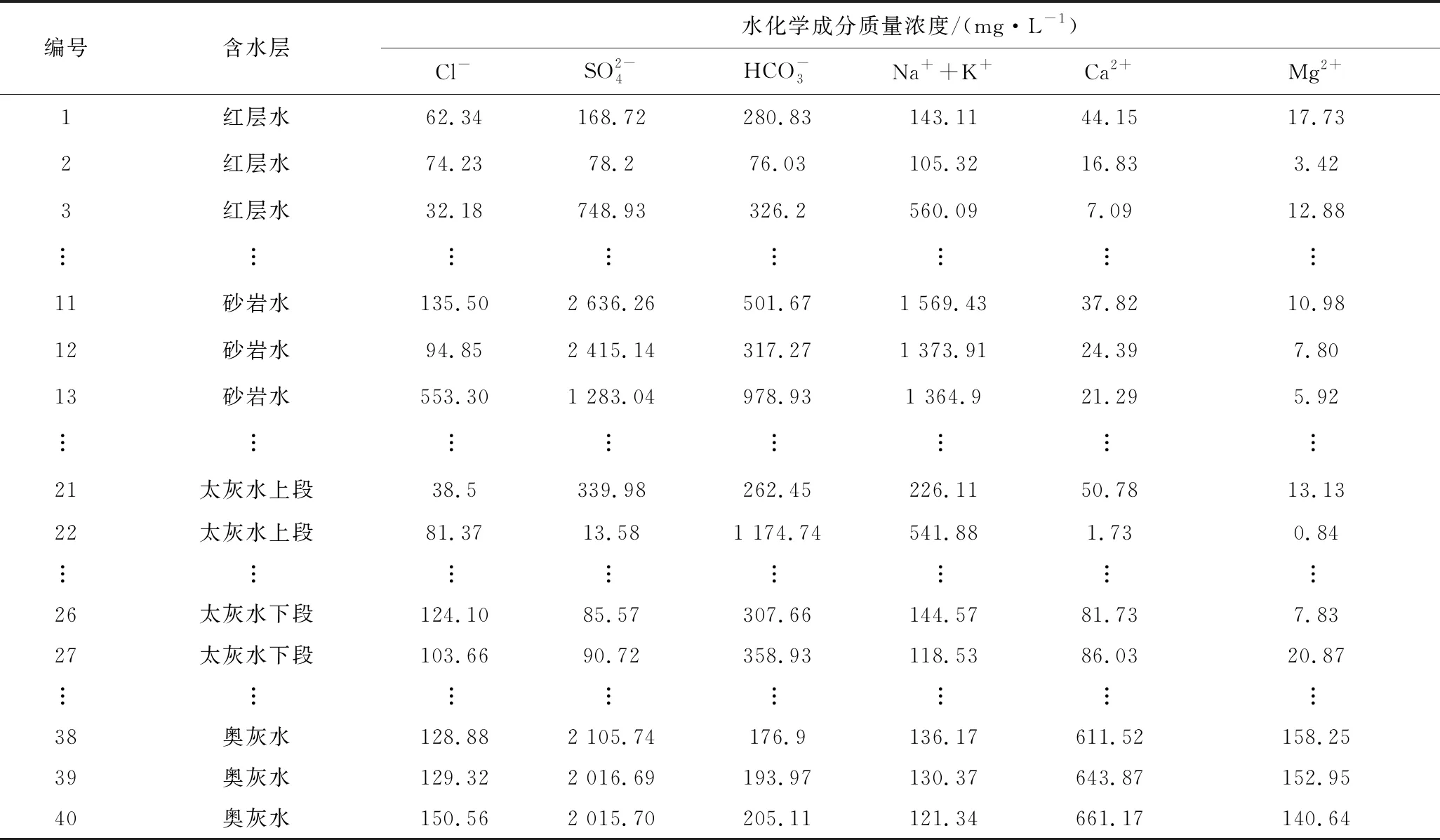
表1 东滩矿区水样主要水化学成分
2.2 突水水源识别模型的建立
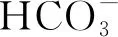
改进集对分析理论是通过不同含水层阴阳离子的上下四分位数来确定各含水层的邻左区、邻右区和属区。根据图1和图3分析可知,邻左区区值T2和邻右区区值T3分别为下四分位数和上四分位数,次邻左区区值T1和次邻右区区值T4分别为最小值和最大值。其中,每行的区间为各水化学指标Cl-、SO42-、HCO3-、Na++K+、Ca2+和Mg2+,每列代表5种主要充水含水层水样:红层水、砂岩水、太灰水上段、太灰水下段和奥灰水,如式(12)—式(13)所示。
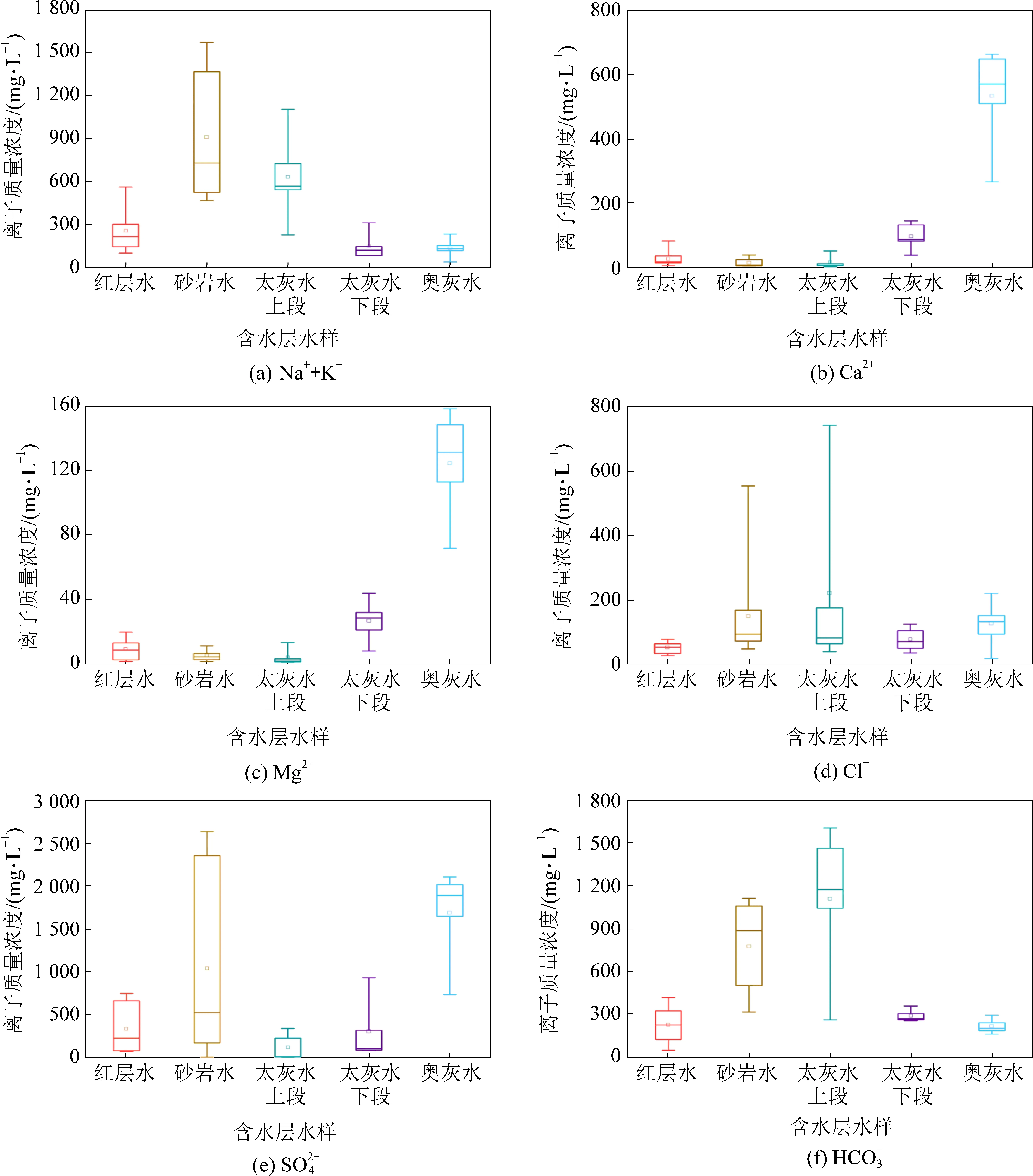
图3 各含水层水化学指标箱形图

(12)
(13)
根据表1建模样本数据、式(4)—式(9)及上述的熵权法和变异系数法,得到各含水层识别指标的客观组合权权重,见表2。若只用某一种方法赋权会有一定的片面性如熵权法中Cl-的权重较小,且使用客观组合权法较单一客观权重法的水源识别效果较好,因此客观组合权更能真实反映出水化学离子的真实权重。Ca2+和Mg2+的客观组合权重明显高于其他离子,分别为0.28、0.25,二者的权重之和占整体权重的53%,结合图3也可以看出Ca2+和Mg2+在不同突水水源中有较好的区分度,因此可以推断出这两项指标在突水水源识别中起主要作用。

表2 识别指标客观组合权权重
2.3 突水水源识别模型验证
取东滩矿区10个已知含水层水样作为水源识别的检验样本,其主要水化学指标见表3,将其代入客观组合权-改进集对分析模型中,对其识别结果进行验证。下面以水样S1为例,详细介绍利用模型进行突水水源的识别。

表3 检验样本主要水化学成分

同理可以计算出各指标与各主要充水含水层的联系度矩阵AS1为
(14)
结合式(10)将联系度矩阵AS1与客观组合权矩阵B相乘,综合计算得出综合联系度矩阵PS1为
(15)
在利用公式(11)计算出各含水层的集对势nsp,分别是nsp1=15.96,nsp2=10.63,nsp3=10.41,nsp4=2.76,nsp5=1.23,将各集对势用百分数进行归一化处理后,依次为38.94%,25.92%,25.40%,6.74%和3.01%。可以从各集对势百分数看出S1水样与红层水的集对势最高,因此将S1水样判定为红层水。
按照上述方法将S2~S10水样分别代入客观组合权-集对分析模型中,其归一化处理后的集对势结果见表4。

表4 检验样本集对势识别结果
由集对势识别结果可以明显看出检验样本的集对势的最大比例,即识别矿井突水水源类型。由表4可知水样S1的红层水集对势比例最大,为38.94%,水样识别为红层水;水样S2、S3和S4的砂岩水集对势比例最大,分别为39.32%、57.40%、60.09%,水样识别为砂岩水;水样S5和S6的太灰水上段集对势比例最大,分别为97.37%和47.94%,水样识别为太灰水上段;水样S7和S8的太灰水下段集对势比例最大,分别为27.54%和40.90%,水样识别为太灰水下段;水样S9和S10的奥灰水集对势比例最大,分别为69.16%和82.56%,识别为奥灰水。
运用客观组合权-集对分析模型对10个检验水样样本进行识别,有9个水样与实际完全相符,仅S2水样被误判为砂岩水。经矿井地质资料对比分析发现,S2红层水取样孔位置位于东滩煤矿一号井东断层附近。该断层为一倾角45°、落差35 m的正断层,切割侏罗系红层水含水层与二叠系砂岩水含水层,是具有一定导水能力的天然通道。由于该通道的存在,导致断层附近红层水和砂岩水发生一定程度的混合,给水源识别带来一定的困难,造成模型误判。因此,应特别重视天然导水构造附近地下水的混合作用对水源识别的影响,结合水化学空间分布特征加强混合水源识别模型的研究。此外,客观组合权-集对分析模型依靠大量实际水样建立识别区间,样本越多识别区间越精确,在后续工作中应持续收集各含水层水样数据,为提高模型的识别准确率提供基础。
3 结 论
1)采用客观组合权不仅克服了主观赋权法的主观随意性的缺点,还弥补了单一客观赋权法带来的片面性较强的不足,能合理地赋值权重。客观组合权确定Ca2+和Mg2+的权重之和占整体权重的53%,说明这2项指标对突水水源的识别影响比较大。
2)对10个检验水样样本进行识别,结果表明,9个水样的识别结果与实际情况完全符合,模型的识别准确率达到90%,说明该模型具有较好的准确性。
3)模型出现误判的原因可能是误判水样取样孔位于断层附近,断层切割侏罗系红层水含水层与二叠系砂岩水含水层,是具有一定导水能力的天然通道,导致水样与砂岩水含水层存在一定的水力联系并发生了混合。
4)建议在后续工作中应收集和监测各种含水层的水样数据,建立丰富的水样数据信息库,为提高模型的识别准确率奠定基础。
