合成孔径成像对低小慢目标的识别技术研究
2022-06-04刘玉雯吴玲玲
刘玉雯,吴玲玲,聂 亮,陈 靖
(西安工业大学 光电工程学院,西安 710021)
1 引言
随着光学技术的飞速发展,在航空航天、卫星遥感、军事侦察等多领域,高分辨率光学成像系统得到了广泛应用与重视。目前,大口径单一光学镜片因受成本、工艺、运输等因素限制和高分辨率的要求,其生产工艺已达到极限。因此,突破传统限制,探索新技术,研制高分辨率合成孔径成为现代光学领域的热点。
2006年洛克希德·马丁先进技术中心建成九望远镜阵列测试床;哈尔滨工业大学进行了分片式多镜面成像系统研究及合成孔径的地面演示系统研制;西安光机所研究了合成孔径的成像理论,并对孔径优化和系统相差等关键问题进行分析;解放军信息工程大学对光瞳优化、活塞误差和图像复原进行了研究。
无人机作为“低小慢”目标的典型代表,是低空安全的重点观测对象。“低小慢”无人机的诞生,使无人机具备更好的灵活性、机动性、易操控等特点,无人机被航拍爱好者使用的同时也被不法分子所利用,严重威胁到社会公共安全和国家安全。
2016年美国国防部加快推进相位高功率微波武器拦截无人机实验,通过蝶形密集天线发射高功率微波,击穿无人机内部电子器件。2017年德国莱茵金属公司将多种探测器与枪炮导弹集成在一套系统上,直接指引枪炮进行打击。2018年北斗实验室发布了全新的反无人机系统,是我国首套采用干扰诱骗方式的反无人机系统。2019年,钮赛赛等首次将深度学习算法引入红外探测无人机目标中,证明深度学习识别效果明显优于传统的模块匹配算法。2020年,刘宜成等提出了一种基于轨迹和形态识别的无人机检测方法,模拟鸟类飞行轨迹实现无人机的检测和识别。徐融借鉴DenseNet思想,采用密集连接的方式将浅层特征网图直接传输到深层同尺度卷积层,并改进YOLOv3的损失函数,在小目标检测上具有更低的漏检率。
将光学合成孔径成像系统应用于识别探测“低小慢”目标,是合成孔径系统在低空领域成像的首次应用。基于YOLOv3的小目标识别方法,大多为在特征提取网络进行卷积层的加深或优化目标识别的损失函数。本文针对光学合成孔径“低小慢”目标的成像特点,提出一种改进YOLOv3主干网络的算法,加强对浅层网络的特征提取能力,并根据数据集的标注信息进行先验框聚类,得到适合本次研究目标的先验框尺度。本文针对“低小慢”目标的底层信息,从轻量化主干网络方面优化YOLOv3网络,得到一种收敛迅速、识别准确率较高的YOLOv3网络模型。
2 光学合成孔径
2.1 光学合成孔径分析
光学合成孔径是将多个小孔径光学系统按照一定的组合规律排列,组成等效的大型综合光学系统。本次研究基于环形七孔结构,分析其光瞳结构及成像规律。环型阵列的子孔径等间隔分布在环带上,相邻子孔径中心的距离与它们到外接圆圆心距离相同。根据计算可得七孔径光瞳相对坐标,分别是(1,0)、(0.62,0.78)、(-0.22,0.975)(-0.9,0.435)、(-0.9,-0.43)、(-0.22,-0.97)、(0.62,-0.78)。根据相对坐标,进行系统光瞳排布及系统MTF仿真,有关情况如图1所示。

图1 环形七孔合成孔径仿真
根据图1可知,系统MTF依规律分布扩展,在中频部分下降较快,这是光学合成孔径图像细节信息丢失、成像模糊的主要原因。
2.2 光学合成孔径成像仿真
根据信息光学的理论,非相干光成像系统具有平移不变性,扩展光源上各点所成的像形态与轴上点一致,该系统对目标的成像过程为:
(,)=(,)*(,)+(,)
(1)
式(1)中:(,)为物方函数;(,)为像方函数;(,)为系统点扩散函数;*表示卷积运算;(,)为噪声函数。
选取光学合成孔径成像规律及光瞳排布等特征因子,模拟经光学合成孔径后的仿真图像,选取鉴别率板为目标图像进行仿真,其结果如图2所示。

图2 合成孔径仿真成像
采用峰值信噪比(PSNR)和结构相似度(SSIM)对仿真图像进行图像质量评价,PSNR值越大,表示图像成像质量越好,失真程度越小;SSIM值越大,表示与原图像越接近。仿真图像评价结果如表1所示。

表1 仿真图像质量评价结果
由表1可知,光学合成孔径成像系统会因中频损失而成像模糊,选取不同填充因子会有不同的系统进光量。同样的光瞳结构,填充因子越小,系统进光量越少,成像质量越差,图像越模糊。根据系统填充因子的计算结果及系统加工余量的要求,应选取填充因子为0.4的环形七孔合成孔径成像系统。
本文实验所使用的光学合成孔径成像系统参数与仿真结果一致,系统仿真结果可应用于后续图像复原处理的相关参数设置。
3 基于YOLOv3的目标识别算法
3.1 YOLOv3目标识别算法
基于深度学习的目标识别算法主要有2类:第1类为以Faster-RCNN为代表的Two-stage目标识别网络,第2类为以YOLOv3为代表的One-stage目标识别网络。Faster-RCNN算法需要生成上千个先验框,并对边界框进行2次筛选,即经过RPN网络,故该网络的推理时间较长、模型参数量大。YOLOv3算法从输入图像到目标识别输出,整体网络属于端到端学习,直接得到目标的类别和位置信息,是运算速度较快的实时检测。
对比YOLOv2所使用的Darknet-19网络,YOLOv3使用Darknet-53作为主干特征提取网络。Darknet-53网络去除池化层,全部由步长为2的卷积层完成下采样操作,主干网络内部使用残差单元堆叠。残差网络能够通过增加模型深度来提高准确率,其内部的残差块使用了跳接法,缓解在神经网络中因增加网络深度而带来的梯度消失问题。YOLOv3从主干网络输出3个分支(即3个特征层),用来进行多尺度预测。3个特征层大小分别为(13×13)、(26×26)、(52×52)。13尺度的特征图对图像的网格划分较大,用于识别尺寸较大的目标;26尺度的特征图对应识别中等尺寸的目标;52尺度的特征图对于图像划分较细,具有较高的细粒度特征,故识别小目标。YOLOv3的网络结构如图3所示。

图3 YOLOv3的网络结构框图
YOLOv3借鉴了FPN的思想,从不同尺度提取特征,不仅在每个特征图上分别做预测,还将小特征图进行上采样,与大的特征图进行拼接,做特征融合处理。经过特征融合的特征图,不仅具有较底层的纹理信息,还包含较高层的抽象信息,能够在不同尺度都具有图像的多层信息,有利于后续的图像识别。
3.2 改进的YOLOv3目标识别算法
光学合成孔径采集的灰度图像中,“低小慢”目标在图像中所占像素较少,目标轮廓较模糊,且与背景的灰度差异较不明显,增加了目标识别的难度。一般的特征提取网络是使用卷积层提取图像特征信息,有的通过增加网络深度来丰富图像特征信息,有的通过增加网络宽度得到图像更多的层次信息,而EfficientNet网络则同时调整网络的宽度、深度及网络的输入分辨率来提升网络性能,故本文选用EfficientNet网络提取图像特征信息。
本文基于EfficientNetv2网络思想,提出一种改进的YOLOv3目标识别算法,具体改进过程如下。
使用EfficientNetv2-S作为YOLOv3主干特征提取网络
本文通过改进主干网络的结构,提升网络的特征提取能力。改进的YOLOv3网络使用EfficientNetv2的部分层结构作为模型的主干特征提取网络,使用Fused-MBConv模块作浅层网络的特征提取,MBConv模块作为后两层网络的特征提取。Fused-MBConv模块结构如图4所示。

图4 Fused-MBConv模块结构框图
Fused-MBConv采用常规的3×3卷积替代MBConv中的3×3卷积和1×1卷积。在EfficientNetv2网络的Stage1-3中,使用Fused_MBConv模块,对这3个模块分别设置了不同的扩展因子(即通道数扩展倍率),当扩展因子不为1时,该模块需经过扩展卷积模块将输入通道数进行扩增。
Fused-MBConv是在MBConv模块基础上作卷积层合并,压缩了模型尺度,提高了浅层网络的运算速度与特征提取能力。
3.2.2 引入渐进式学习策略,加快模型训练速度
当模型网络深度确定时,图像的特征信息会被卷积核进行逐层筛选,模型训练到网络高层时可能会变得低效。随机失活一部分网络层结构,使得网络高层也能接收到更多的底层信息。这样的模型设计可使网络得到更加充分的训练,而模型也会有更好的表达能力。
EfficientNetv2网络的Dropout层采用了随机深度(Stochastic depth)的思想,随机丢弃主分支的某个输出,将整个网络变为随机深度。在模型训练时将网络某层结构进行随机去除,网络的渐进式学习能够提升模型的训练速度,小幅提升模型准确率。Dropout层随机深度结构如图5所示。

图5 Dropout层随机深度结构示意图
3.2.3 使用-means聚类方法更新模型的先验框尺寸
在原YOLOv3模型中,使用COCO数据集进行先验框尺寸的聚类分析,能满足大多数目标识别的先验框尺寸需求,但本文研究的目标是小型无人机,属于“低小慢”目标信息,在图像中所占像素较少,不适合COCO数据集的聚类尺寸。
对合成孔径数据集的标注框信息使用-means算法,根据“低小慢”无人机的不同飞行姿态,得到“低小慢”目标先验框尺寸。保持值为9不变,经聚类算法迭代后选取对应的先验框宽高分别为(44,36)、(45,33)、(48,38)、(48,37)、(50,34)、(53,31)、(55,38)、(55,34)、(58,38)。
经EfficientNetv2输出得到3个不同尺度的特征模块,再经过上采样和深度方向的拼接处理,得到3种尺度的特征图。改进的YOLOv3网络结构如图6所示。

图6 改进的YOLOv3网络结构框图
3.3 目标识别算法评价指标
mAP值越高,代表模型识别效果越好。单独计算各个类别的AP(average precision),取平均值得到最终的mAP,所以mAP是每个类别的平均值。
准确率是真正的正样本数除以检测的总数,即:

(2)
召回率是预测为正例的样本中预测正确的数量除以真正的正样本数量,即:

(3)
IOU表示系统预测框(Detection Result)与原图像标记框(Ground Truth)的重合程度,即:

(4)
4 实验分析
4.1 实验搭建及数据集预处理
本次网络构建基于Python3.7和Tensorflow 2.3框架搭建,在Tesla K80显卡和NVIDIA GeForce GTX 1080Ti GPU的配置环境下完成训练和测试。
本次识别的“低小慢”目标是DJI精灵2四旋翼无人机,使用光学合成孔径成像系统采集目标的视频数据,并根据视频数据,逐帧构建识别数据集。
由光学合成孔径分析可知,光学合成孔径成像固有的中低频损失使得图像轮廓信息模糊,本文在数据集预处理阶段使用SRGAN算法对光学合成孔径数据集进行图像复原处理,SRGAN的迭代效果如图7所示。
经过100次迭代,复原图像与原图对比后的峰值信噪比可达35 dB,结构相似度为0.96。经过SRGAN算法处理的光学合成孔径图像轮廓模糊的现象有所改善,但目标与背景的灰度较接近。使用数据增强处理,改变图像的亮度,使得网络在模型训练阶段能够学习到不同灰度差异的图像特征。

图7 SRGAN的迭代效果图
4.2 目标识别损失值对比
YOLOv3模型将目标识别任务看作目标区域预测和类别预测的回归问题,其损失函数包含置信度损失、分类损失和定位损失,即:
(,,,,,) =(,) +(,) +(,)=
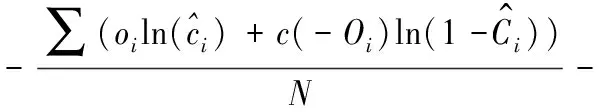


(5)

置信度损失是让模型学习分辨图像的前景和背景,当某预测框与真实框的IOU都小于某阈值,那么判定它为背景,否则为前景;分类损失采用二值交叉熵损失,将所有类别的分类问题看作是否属于该类别的问题,减少了类别间的互斥性;边界框损失采用平方和损失,该损失函数会朝着预测框与真实框重叠较高的方向优化。
采用批梯度下降的方式,对原YOLOv3是算法、主干网络是EfficientNetv1的YOLOv3算法和本文改进算法分别进行训练,加载特征网络的预训练权重。样本进行1 000次迭代,其中批量大小设置为64,初始学习率为10,当有5次迭代的损失值保持一致时,学习率衰减0.9倍。对整体样本进行比例为8:2的随机划分,分别为训练集和测试集,再取训练集的10%用于训练完成后的验证。取3种算法前50次测试迭代效果的损失值作图,如图8所示。
由图8可知,3种不同的YOLOv3算法在10个epochs内均收敛,主干网络为EfficientNet网络的收敛速度快于Darknet-53网络,EfficientNetv1算法和本文改进算法的收敛速度相近。

图8 3种算法损失值曲线
4.3 目标识别实验结果分析
本文的改进算法采用EfficientNetv2对光学合成孔径图像的底层特征进行提取。EfficientNetv2网络的设计是使用搜索算法设计网络结构,在各层网络进行有效提取,能够在压缩模型尺度的同时,提升网络的特征提取能力。本文将根据实验结果从模型参数大小和目标识别效果2个方面,对3种不同算法进行对比分析。
本次实验对比的3种算法分别为:原YOLOv3模型;主干网络为EfficientNetv1,模块为B5的YOLOv3模型,表示为EfficientNetv1(B5)-YOLOv3;本文改进算法即主干网络为EfficientNetv2,模块为S的YOLOv3模型,表示为EfficientNetv2(S)-YOLOv3。
经过数据集的采集与预处理后,分别对3种算法进行相同迭代次数的训练,3种算法的训练参数如表2所示。
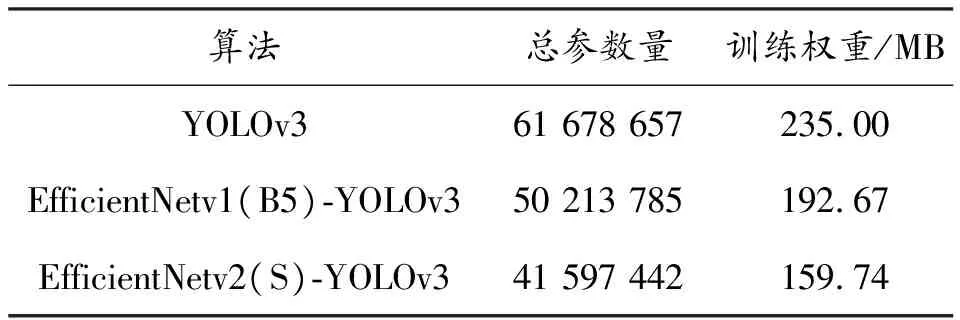
表2 训练参数
由表2可知,在相同参数设置下,本文的改进算法运算参数量最少,模型最为简洁。EfficientNetv2对于浅层网络的改进能使运算参数减少32MB,是一种改进的轻量化网络模型。
将主干网络变换为EfficientNet系列模型,是一种轻量化网络的改进方式,针对光学合成孔径的成像特点,需要对“低小慢”目标的底层信息进行有效提取,而本文算法所使用的卷积模块正是对浅层网络进行改进,本文算法的目标识别结果如图9所示。
将3种算法的IOU阈值均设置为0.5,使用目标识别评价指标对3种算法的目标识别效果列表,如表3所示。

图9 改进算法的目标识别结果图

表3 目标识别效果
根据表3可知,3种算法均能对“低小慢”目标进行有效识别。原YOLOv3中的Darknet-53网络只在深度上堆叠卷积层,对于“低小慢”目标的识别效果相对较差。根据3种算法的时间复杂度计算可知,EfficientNet系列算法的运行速度相比YOLOv3有明显提升,满足实时性要求,其中本文所采用的EfficientNetv2(s)网络对“低小慢”目标的底层特征学习效果较好,本文算法的识别准确率可达96.67%,将准确率和召回率3种评价指标结合,绘制了本文算法的PR曲线如图10。

图10 本文算法PR曲线
5 结论
1) 系统的光瞳排布及填充因子等参数是造成系统MTF中频损失的主要原因。
2) 使用基于深度学习的SRGAN算法对合成孔径图像进行复原处理可增强图像对比度,缓解图像轮廓模糊问题。
3) 针对“低小慢”目标的识别问题,改进的YOLOv3算法使用EfficientNetv2网络的部分层结构作为YOLOv3的主干特征提取网络。
4) 通过对3种YOLOv3算法的实验对比,本文算法的模型参数量最少,对目标的底层特征学习效果较好。与原YOLOv3网络相比,本文算法的识别准确率可达96.67%,是一种有效的轻量化目标识别网络。
