基于Mosaic数据增强方法的标签检测算法研究
2022-05-31吴诚远苏辉跃许又匀邵燕陈宇恒
吴诚远 苏辉跃 许又匀 邵燕 陈宇恒


摘 要:标签检测对现代智能图书馆的建设十分重要,但在实际应用的精度上仍然有待提高。本研究提出一种改进的YOLOv5图书检测方法。该方法利用Mosaic数据增强方法,在数据预处理方面,通过批处理将图片的大小限定在一定范围内,减少拟合,丰富数据的多样性,以此提高实际训练的效果。同时利用了DIOUS_nms替换了原有的传统nms方法,来提高实际的识别效果。相较于原YOLOv5模型而言,推理时间降低了17%,平均准确率提高了2.7%。可见该方法模型小,准确度高,具有部署到移动端设备上的潜力。
关键词:Mosaic;DIOUS_nms;YOLOv5;数据增强;标签目标检测
智能图书馆是指读者可以自主利用图书馆适配软件,能够方便、快捷的搜寻到书籍并且能够精准定位到书籍的位置,如同地图一样,可以大大减少读者往返寻找的时间。目前图书馆已经普遍配备搜寻书籍的设备,但是搜寻的结果仅仅包括了书籍的馆藏位置、馆藏标签号等有限信息,对于书籍的具体位置,仍然需要读者自己去寻找。此外,由于书籍的馆藏信息更新不及时,也会常常造成读者花费长时间却无法找到的问题。目前这些任务主要依靠人工来进行完成,时间成本高,位置不准确。本文基于图像识别的智能识别定位技术是未来图书馆的发展方向,这些任务主要依靠标签检测技术来完成。因此,书籍的标签检测算法是其中的关键。
为此,国内外学者针对标签检测算法进行了广泛的研究。王钰深[1]等提出了利用改进的概率霍夫线算法将书籍依據书脊来进行分割,再通过特征匹配来识别出书签的信息。崔晨[2]等提出了利用文本检测来进行书脊的定位,基于序贯分割来有效的降低光照对实际结果的影响,并且保证了字符不漏检。曾文[3]等基于改进Mask R-CNN的方法来对书籍的特征点进行提取,从而实现提取书籍信息的功能。以上方式的基本思路是根据书籍的特点来设计特定算法来进行进行识别,这种单一算法检测效率较高,但是需要大量的手动特征点提取和调整,过程繁琐,工程量较大,鲁棒性较差。
针对该问题,本文提出在原有的YOLOv5网络结构基础之上进行改进,进而使用了基于Mosaic数据增强的标签检测算法和DIOU_nms的检测框识别策略。该方法利用了改进的Mosaic-9算法来增广数据量,提升数据集数据的多样化,进而达到了模型在不同光照、环境下较高的检测能力,使得其能够较为适合一般的检测环境,进而提高了模型的鲁棒性。DIOU_nms能够有效提升检测的精度,减少错检、漏检的情况。
1 标签检测算法
1.1目标检测算法
书籍的标签检测是一个目标检测任务,由于本场景仅仅存在标签这一个类别,主要的难点在于多目标的位置定位和识别。目前基于深度学习的目标检测算法主要分为两类:一类是基于区域提取的两阶段目标检测模型,如R-CNN[4] Fast R-CN、 Faster R-CNN等,将目标检测分为特征提取和特征分类两步;另一类是直接进行位置回归的单阶段目标检测模型,如SSD、YOLO系列等,将目标检测转换成回归问题,本文主要使用的是基于候选区域的两阶段检测算法。在特征提取和特征融合方面,主要采用了AF-FPN来解决模型大小和识别精度不兼容的问题,使得目标模型在移动设备也能够进行网络部署。AF-FPN主要利用自适应注意力模块(AAM)和特征增强模块(FEM)来降低特征图生成时的数据损失并且增强其特征信息,可以有效的处理标签的多尺度信息的检测性能。此外,本文采用了Mosaic数据增强(Data Enhancement)和DIOU_nms的方式来丰富数据集并提升其鲁棒性,使其更加适合特定场景下的目标检测任务。
1.2 Mosaic数据增强
数据增强目前已经广泛应用于网络优化之中,可以有效提高CNN的性能,防止过拟合的发生。目前常见的单样本数据增强的方法大致分为两种:颜色变换(亮度、对比度等)和几何变换(如缩放,翻转、平移和缩放等等)。Mosaic数据增强综合了颜色变换、几何变换的优点,通过此方法可以丰富数据集。(如图1)
具体的做法是从数据集中随机选取四张像素一致的图像,然后将图像进行随机大小的裁剪,将第一张裁剪的图像固定在新生成的图像的左上角,第二张裁剪的图像固定在左下角,第三张裁剪的图像固定在右下角,第四张裁剪的图像固定在右上角。不仅丰富了图片的背景,而且使得目标更加多样。在本文场景下,目标单一且标签处的特征变化较小,适当使用Mosaic数据增强能够有效增大数据集的实际利用率,提高实际的识别精度。
1.3 YOLOv5s模型
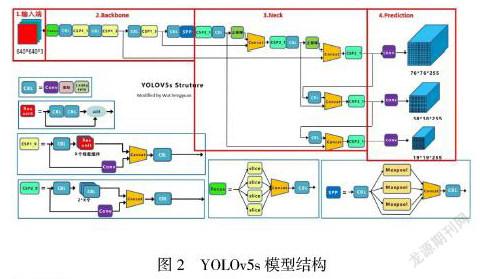
作为图像识别领域比较热门的算法,YOLOv5s因为其轻量化的模型大小,在低压环境下不逊于v4版本的精度和速度,自适应图片处理,使得其对数据集的要求被进一步降低,容易部署工程化实现等优势而更适合用于实际的场景应用。目前YOLOv5的框架由输入端(Input)、主干特征提取网络(Backbone)、Neck和输出层(Prediction)4个部分组成。
其主要的Backbone部分采用了Focus结构和CSP结构,不同于YOLOv4仅仅在主干网络使用了CSP结构,在YOLOv5s网络中,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构应用于Neck中。此外,YOLOv5网络在Neck部分采用了FPN+PAN结构,通过借鉴CSPnet设计的CSP2结构来有效加强网络特征融合的能力。(结构如图2)
1.4 DIOU_nms
对于目标检测输出处理的过程之中,YOLOv5对于目标框的筛选主要采用的是nms操作,传统的nms是对同一类别的候选框进行筛选,检测到置信度最大的检测框,然后遍历最大框附近的框并且计算IOU,IOU大的框将会被删除(这里的IOU是表示高度重叠)。而在本数据集训练的过程中,对于一些薄且摆放不齐的书籍,训练的模型出现了识别框重叠,无法精准确定标签位置,造成漏检、错检的情况。
为了提高YOLOv5对图书馆特定场景的检测效果,本文对目标检测的后处理对目标框的筛选,在nms非极大值抑制的基础上提出一种 DIOU_nms的改进,同传统nms方式相比,DIOU_nms方式针对部分遮挡重叠的目标,在DIOU_Loss的基础之上,考虑了IOU值的同时,也兼顾了两个Box中心点之间的距离,同时添加影响因子,包含了groundtruth标注框的信息,用于在训练时进行回归,而且相较于原本的回归速度更快。因此,采用DIOU_nms方式可以在不增加计算成本的情况下,进一步增加模型识别的准确率。
DIOU_nms公式如下:
其中M表示高置信度候选框,bi就是遍历各个框跟置信度高的重合情况。
此外,针对书籍标签属于小目标识别,本文引入改进的Mosaic数据增强的方法,来解决原模型识别精度不高的问题,在保证高识别率的基础上,进一步提高模型的识别性能,使得数据集数据得到充分利用,提高训练效果。
2 实验结果和分析
为了验证本文中标签检测算法的可行性、有效性,进行了相关的模型训练实验。本节将会从实验环境、数据集来源、实验方法、评估标准来进行阐述。
2.1实验环境
本文实验使用深度学习框架PyTorch训练模型,在训练过程中采用了cuda来进行硬件加速。硬件环境如下:Amd 3700x、Nvidia RTX 2070super,32GB RAM,操作系统为Windows 10,代码环境是Anaconda虚拟python3.8环境。
2.2数据集来源
由于是图书馆的特定环境下来实现工程化,目前没有统一公开的书籍标签数据集,本文采用了自制标签数据集,所有图片均采用COCO2017标注格式。图片数据全部来源于江苏大学图书馆1L的真实书籍标签图片。本文自制数据集共包含205张照片,该数据集共一个类别:标签(label)。
2.3实验方法
模型训练时将数据集205张照片随机分成训练集、验证集、测试集3类,按照8:1:1的比例来进行划分。在训练阶段将YOLOv5和Mosaic数据增强相结合,训练得到2个模型:YOLOv5、YOLOv5+Mosaic,然后采用DIOUS_nms来加强实验结果的对比,最终得到了YOLOv5、YOLOv5+Mosaic、YOLOv5+Mosaic+DIOUS_nms三个模型。将此3个模型进行实验对比。使用了Mircosoft COCO数据集的预训练权重来进行网络参数的预训练,以此提高训练的速度。在输入卷积神经网络之前,数据集的图像分辨率全部调整为416×416。训练过程总共迭代300个epoch,并将初始学习率和Batch_size分别设置为1×10-3和16。Mosai函数的实现参考了YOLOv5的utils文件夹下的datasets.py文件,在原有的load_mosaic9函数上进行改进,使得其更加适合本文书籍标签的应用场景。
2.4 评估指标
本文使用目标检测领域常用的平均精度均值(mean average precision,mAP)来评价算法的实际标签检测效果。其中AP反映了单一类别的检测效果,其计算公式为:
式中:ITP表示正样本被预测正确的数量,IFP表示负样本被预测为正样本的数量,IFN表示正样本被预测为负样本的数量。根据不同的召回率r计算出对应的查准率p,而AP为不同的召回率和查准率围成的曲线面积。平均精度均值mAP为每类AP的平均值,可以反映模型整体的检测性能。
3 结果与分析
模型在204张图像测试集上,采用了2.4部分所提的评估标准,对2.3实验方法所提及的2个模型进行评估,实验结果如表1所示。
综上,YOLOv5+Mosaic+DIOU_nms模型相较于原YOLOv5模型而言,各项指标都有所提升,采用了Mosaic的模型,使得实际检测的区域更加精确,DIOU_nms方式的改进,使得模型的错检率大大下降。模型的检测效果如图3所示,其中测试图像1和2是属于验证集中的,测试图像3和测试图像4是属于未标注数据集中的。
根据以上模型检测结果可知,本文提出的方法错检率低,且验证的准确性高。YOLOv5+Mosaic+DIOUS_nms模型在部分数据集漏标的情况下,依然能够做到不漏检,且检测的区域准确,可以通过crop函数将标签信息部分给完美的分割出来,鲁棒性良好。
4.结论
针对原始YOLOv5算法在小目标的复杂情况下的检测效果欠佳的问题,本文引入数据增强和DIOU_nms的方法,有效提高了数据集的利用率和实际检测结果的精确度,大大降低了实际目标的错检率,使得目标框的回归更加稳定迅速,定位更加准确。本文YOLOv5+Mosaic+DIOU_nms模型提高了YOLOv5算法在特定环境下的检测效果和鲁棒性,也验证了YOLOv5项目工程化的可行性,性能综合优于原版YOLOv5模型。但是在光照较暗的情况下仍然存在着一些漏检情况。因此,下一步需要考虑改进网络特征提取的能力来获得特征近似的标签目标,在保证识别准确度的前提下,提高算法的效率。
参考文献:
[1]王钰深,黄悦恒,黄谦,刘冲.基于霍夫变换的书脊识别研究[J].科技创新与应用,2020(36):7-11.
[2]崔晨,任明武.一种基于文本检测的书脊定位方法[J].计算机与数字工程,2020,48(01):178-182+251.
[3]曾文雯,杨阳,钟小品.基于改進Mask R-CNN的在架图书书脊图像实例分割方法[J].计算机应用研究,2021,38(11):3456-3459+3505.DOI:10.19734/j.issn.1001-3695.2021.01.0069.
[4]洪亮,王芳,蔡克卫,陈鹏宇,林远山.面向海洋牧场智能化建设的海珍品实时检测方法[J].农业工程学报,2021,37(09):304-311.
作者简介:
吴诚远:生于2000年11月,男,汉族,江苏镇江人, 江苏大学本科在读,软件工程方向
项目来源:本文系江苏大学2021年度大学生创新创业训练项目,项目编号:202110299810X
