CPU是如何工作的?
2022-05-30超载
超载

从CPU(图1)的名称中央处理器就可以看出,它是整个电脑的核心,不过这个核心是如何工作的,它们除了频率还有什么差异?这些问题恐怕在很多评测中也少有提及,CPU的运算能力究竟是因何而生。今天,笔者就和大家分享一些关于CPU是如何计算的,它们又是如何工作的知识。
CPU其实是缩写,全称为Central Processing Unit,它的功能作用就是“翻译”电脑的指令

根据这些指令处理计算机中软件生成的数据并输出结果。所谓的电脑可编程性,其实主要就是指CPU的编程能力。在上世纪70年代之前,CPU是由多个独立单元构成的,而不是像今天这样一颗芯片。当集成电路(图2)普及后,元件大幅度“微缩”到一起,成了一块小小的芯片,这也就是所谓的“微处理器”由来。
现代CPU的“核心”
笔者这里提及的“核心”不是现今通常意义上的核心,而是CPU的主要组成部分:控制单元、整数逻辑单元、浮点运算器(图3)。任何一款CPU,实际上都离不开这三个单元,无论CPU的框架设计如何变化,增加多少技术,這三个基本构成是不会改变的。
那么,这三个构成CPU的基本单元究竟都有什么作用呢?控制单元简称CU(图4),是Control Unit的缩写,它的作用其实可以被看做是一个“协调者”,负责协调指令的执行。诸如寄存器、算术逻辑单元、指令寄存器、总线、甚至包括CPU外部的输入输出,都要依靠控制单元的协调管理。
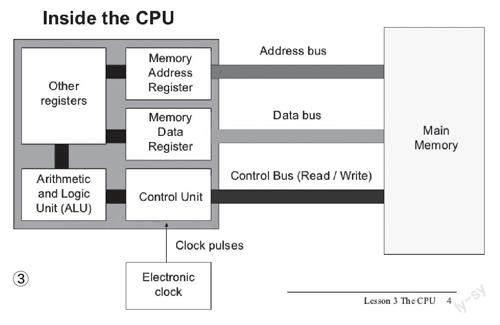
当有需要执行的命令“发送到”CPU,第一个“接收者”就是控制单元,由其分配工作给不同的单元,例如整数逻辑单元、浮点运算器等等。
整数逻辑单元又是做什么的呢?整数逻辑单元简称ALU,是Arithmetic LogicUnit的缩写,一如其名,它的作用就是进行算术、逻辑计算的。简单点理解,例如加法、减法等等计算工作,都是由整数逻辑单元来完成的。到实际的应用层面,例如我们的压缩、解压缩文件、计算机进程的调度,编译器语法分析、游戏的AI处理……诸如此类的计算工作,都是由整数逻辑单元负责。
至于浮点运算器,它的简称为FPU,是Floating Point Unit的缩写,早期曾经是和CPU并立的独立芯片(图5)。浮点运算单元主要影响CPU的科学计算性能,如流体力学、量子力学等,而更贴近我们日常能见到的应用就是多媒体相关的应用,如音视频的编解码、图像处理等操作。
一般针对CPU的评测中,像AIDA 64、Super Pi、wPrime、Fritz Chess Benchmark(图6)、GeekBench、WinRAR、7-zip、CPU Passmark等软件,都是尽力在“挖掘”CPU的浮点、整数运算性能,用它来衡量CPU的性能优劣。

CPU对游戏的影响
我们直接了当一点,游戏是首当其冲考验电脑性能的一个“法宝”,而且不止是显卡,CPU时至今日都对游戏性能高低有着决定性的作用。首先,CPU承担着电脑的任务进程分配,如果游戏的优化不好,会进行频繁的进程调用申请,这样极度消耗CPU的资源。而且,现在的游戏引擎不仅仅要针对画面优化,在AI方面同样是游戏引擎的重要方向。举个例子,游戏中的NPC(Non-Player Character,电脑控制的游戏角色或者事物)要做什么、会做什么,会有什么样的行为(图7),这些,现在都是依靠AI计算获得的。而AI计算的主力,并非是显卡,而是CPU。
此外,可能大家不太了解的事情是,目前游戏的反盗版机制,在游戏的运行过程中,会频繁的加密、验证,这些都会消耗浮点运算性能,也就是CPU的性能。所以这也是为什么较老规格的电脑会在运行游戏时帧率不高的原因,即便它拥有一块性能不错的显卡,也无济于事。
显然,无论是整数运算还是浮点运算,CPU都是必不可少的计算单元,辅以控制器的调度,才能形成一个完整的计算。无论CPU的架构如何变化,这些基本的概念依旧存在,而且,随着应用的发展变化,浮点运算的能力强弱,甚至一度决定了CPU的评价。
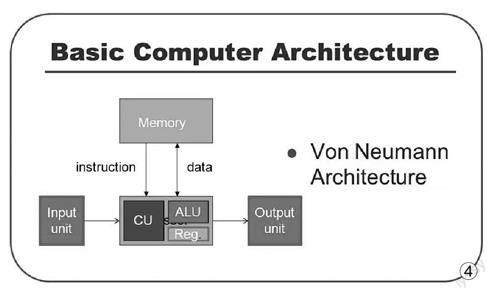
浮点运算的重要性
虽然芯片都是逻辑电路,但是早期的CPU还是很简陋的,前面已经提到,浮点计算单元早期以协处理器的形式存在,一台没有浮点处理能力的电脑性能极差,但是限于当时的技术能力,还做不到一颗CPU就拥有浮点计算能力的程度。例如Intel在生产8086、8088 CPU的同时,还推出了一款8087协处理器产品。这种情况一直持续到487 SX(图8),最终才在80486DX CPU上,第一次将浮点计算单元集成到内部。
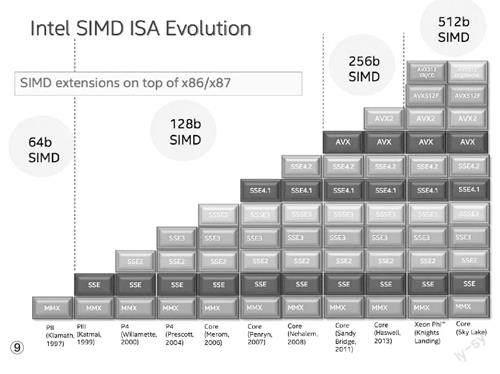
现在的CPU不仅仅是拥有浮点运算单元那么简单,还通过SIMD技术实现了并行计算。所谓SIMD,即SingleInstruction Multiple Data单指令多数据流,单指令流多数据流技术其实是一个控制器控制多个平行的处理微元,例如英特尔的MMX或SSE,以及AMD的3D Now!指令集,都属于S I M D 范畴。当你使用CPU-Z这类软件查看CPU信息时,你会看到很多指令集,例如MMX、3DNow!、S S E ~S S E4 .1、AV X等等(图9),这些都是属于SIMD范畴的。
正是因为浮点运算的存在,让我们的电脑在应用中表现愈发出色,而且不止是CPU,显卡的浮点运算能力更是突出,甚至远超CPU。但是这又引来另一个问题,既然显卡的浮点运算能力这么强大,为何CPU还要保留浮点运算呢?这里就要提到一个失败的例子了。2011年AMD发布了一个全新的CPU架构推土机架构(Bulldozer),它最大的特点是放弃了通常意义上一个核心中,拥有一整套整数逻辑单元+浮点运算单元的组合方式,改成了两个核心共享一个浮点运算单元的方式(图10),然后,将自家优秀的显卡核心集成到CPU中,以期用显卡的强悍浮点性能,最终增强整体的性能表现。然而,这个框架极为失败,也让AMD经历了绝无仅有的“暗淡时光”,CPU整数性能不弱,但综合性能孱弱的令人发指——这和其奇思妙想的两核心共用一套浮点运算单元有离不开的关系。
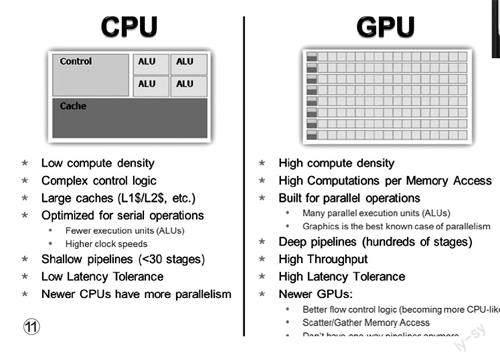
而且,显卡的浮点性能强大是相对的,CPU的浮点运算能力比不过显卡也是有原因的——显卡更擅长大规模并行计算(图11),举个简单的例子,如果说CPU的浮点计算是几个数学家在解高阶方程式,那么显卡的浮点运算就是一群学生在做加减乘除的基础运算,更注重规模效应。
CPU计算还需要这些
计算好或者待计算的数据,究竟如何“输入、输出”呢?这就需要用到寄存器了。
它实际是一个用来存储输出数据的单元,而且它是一个中间数据的“转存站”。它拥有有限存贮容量的高速存贮部件,它们可用来暂存指令、数据和位址。在中央CPU的控制部件中,包含的寄存器有指令寄存器(IR)和程序计数器(PC)。在中央CPU的算术及逻辑部件中,包含的寄存器有累加器(ACC)。

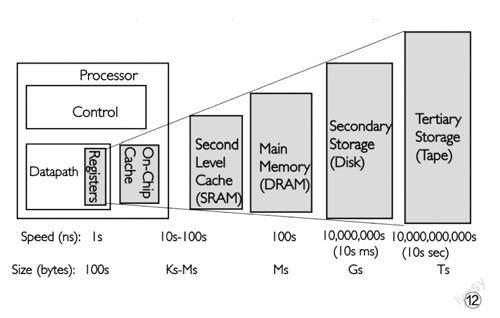
这些数据通过寄存器之后按理应该是输出到内存中的,但实际因为速度之间的差异过大,不得不进一步“缓冲”一下,这便有了缓存的存在。缓存英文为Cache,全称是高速缓冲存储器,它是CPU与主内存间的一种容量较小但速度很高的存储器(图12)。由于CPU的速度远高于主内存,CPU直接从内存中存取数据要等待一定时间周期,緩存中保存着CPU刚用过或循环使用的一部分数据,当CPU再次使用该部分数据时可从缓存中直接调用,这样就减少了CPU的等待时间,提高了系统效率。
当CPU需要调用数据的时候,它会先到缓存(图13)中去寻找,如果数据因之前的操作已经读取而被暂存其中,就不需要再从随机存取存储器中读取数据——由于CPU的运行速度一般比主内存的读取速度快,主存储器周期(访问主存储器所需要的时间)为数个时钟周期。因此若要访问主内存的话,就必须等待数个CPU周期从而造成浪费。
提供“缓存”的目的是为了让数据访问的速度适应CPU的处理速度,其原理是内存中“程序执行与数据访问的局域性行为”,即一定程序执行时间和空间内,被访问的代码集中于一部分。为了充分发挥缓存的作用,不仅依靠“暂存刚刚访问过的数据”,还要使用硬件实现的指令预测与数据预取技术——尽可能把将要使用的数据预先从内存中取到缓存里(图14)。

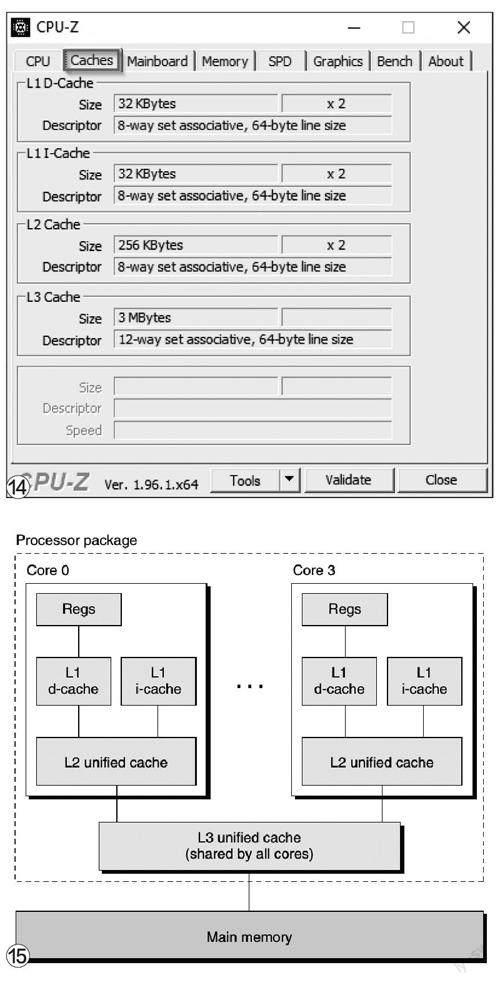
而且,为了进一步提高性能,缓存被分成指令和数据分区两个部分,而且还会分级,即我们常常讲到的CPU一、二、三级缓存。尤其是多核心时代,一级缓存几乎是各个CPU核心的专用缓存,二次级缓存则是多核心共享的结构,用以进一步提高性能(图15)。
时钟频率
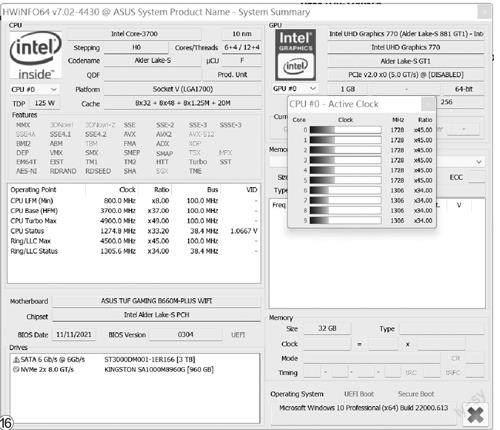
时钟频率,英文Clock Rate,意即同步电路中时钟的基础频率,它以“每秒时钟周期”(Clock Cycles PerSecond)来度量,量度单位采用Hz(图16)。
CPU的时钟频率通常是由晶体振荡器的频率决定的。在一个时钟脉冲后,CPU的信号线需要时间稳定它的新状态。如果上一个脉冲的信号还没有处理完成,而下一个时钟脉冲来的太快(在所有信号线完成从0到1或者从1到0的转换前),就会产生错误的结果。芯片制造商制定了“最高时钟频率”的规范,并且在出售芯片之前对它们进行测试确保它们符合“最高时钟频率”的规范。测试将执行最复杂的指令,处理最复杂的数据模型确定使用的最长处理时间(测试在最合适的电压和稳定保证CPU在最低性能下运行),保证最高时钟频率时不会发生冲突。
因此,早年间时钟频率几乎是唯一评判CPU性能的依据,例如1990年代,大多数电脑的性能如何判断快慢,主要就依靠CPU频率,100MHz就是比90MHz的CPU性能快。时至今日它依然是判断CPU性能的重要标准之一,但不是唯一了。
多核心
让更多的核心参与到计算中来用以提高系统性能,是近年来CPU的“标准配置”,单核心CPU早已走入历史舞台。多核心CPU的开端其实要追溯到2000年,当时IBM发布了Power4CPU,这是世界上第一个双核心CPU产品(图17)。由于多核心CPU具有高主频、设计和验证周期短、控制逻辑简单、扩展性好、易于实现、功耗低和通信延迟低等优点,因此它得以迅速成为CPU“标配”。此外,多核心CPU还能充分利用不同应用的指令级并行和线程级并行,具有较高线程级并行性的应用可以很好地利用这种结构来提高性能。
但是,如何发挥多核心CPU的性能,还需要软件优化,比如有些应用可以最大限度调度所有CPU核心参与到计算中(图18),而部分应用只会调用到4至6个核心,所以,单一核心的绝对性能依旧是当前最重要的。

超线程
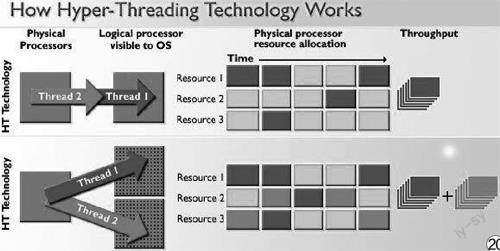
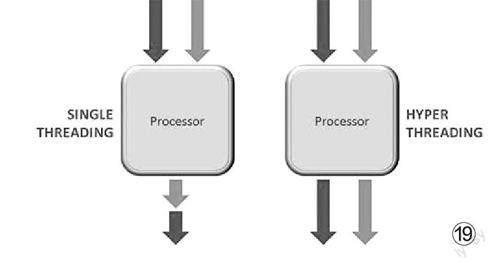
然而这还不够,如何让每一份电力供应都能转换为性能,让CPU的工作尽可能“满坑满谷”,提高执行效率一直是人们的追求。一般来说,单个时间单位内,一个CPU核心一次只能执行一个线程的工作。如果想并行工作,提升效率,似乎只能是使用更多的核心。这样一来效率并不是很高,如何进一步“压榨”CPU呢?那就要使用超线程技术了。超线程技术说简单一些,就是在单位时间内,一个核心可以处理两个线程的工作(图19),单核心模拟双核心执行双线程运作,用以提升执行效率。
英特尔在奔腾CPU上就开始引入超标量、乱序执行、大量的寄存器及寄存器重命名、多指令解码器、预测执行等特性,这些特性的原理是让CPU拥有大量资源,并可以预先执行及平行执行指令,以增加指令执行效率,可是在现实中这些资源经常闲置。为了尽可能的利用CPU资源,于是在现有单核心的基础上,只增加必要的资源,让闲置的CPU核心资源模拟第二个线程(图20),这就是超线程的由来。这个必要的资源其实非常少,只是在一个核心内增加一个逻辑CPU单元,而整数逻辑单元、浮点运算器、缓存依旧共享同一个核心资源。
CPU性能的第一要素
衡量CPU性能究竟是看主频还是看核心?都不是,而是一个计算公式—— CPU性能=IPC×频率。IPC即Instruction PerClock,意为每周期指令(图21)。这个指标是衡量CPU性能最直观的体现,它是指每个时钟周期执行的平均指令数。
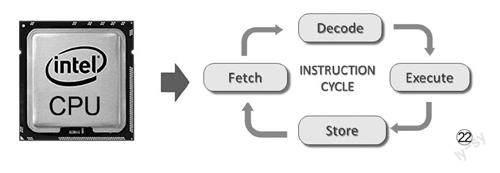
CPU在执行指令的时候,一共分为三个步骤,即“获取指令(Fet ch)”“译码(Decode)”“指令执行(Execute)”(图22)。大致的工作原理是这样的,在获取指令阶段,CPU的寄存器中找到对应的指令地址,然后根据指令地址从内存中把具体的指令加载到寄存器中,并准备未来执行下一条指令;刚刚加载到寄存器中的指令这个时候会由CPU控制单元进行的解析,“翻译”成对应的操作执行,然后确定要操作哪些寄存器、数据或者内存地址,用以后续执行操作;到了指令执行阶段,这些操作会指派给整数逻辑单元操作。这样一个“三部曲”的操作流程,电脑完成運行代码所需的机器级指令的数量,在同一个时钟周期内,能够执行多少次“三部曲”就是IPC的意义所在。此时,CPU的性能判断也就有了依据,用这个IPC数乘以×频率就可以得到CPU的性能。例如,同样是4GHz的两个CPU,其中一个的IPC性能提升了15%,则整体性能要比另一个提升15%。我们都知道CPU的制程工艺很大程度上决定着性能,主要作用就是在尽可能小的体积下容纳更多的积体电路,通过更多的积体电路来提升IPC性能;同时在更先进的制程工艺下,可以控制功耗的同时,稳定CPU的高频运作。所以,CPU的性能实际上要综合来看,而不是单纯的依靠频率、核心数量来确定它的性能。
CPU的异构崛起?
CPU增强性能的方法其实不止提升IPC性能,例如我们之前也提到过的缓存,如果能够增加缓存自然也能提升性能——数据交互能力越强,CPU的处理效率就越高。例如,AMD的锐龙7 5800X3DCPU就是这样来提升性能的。这里就要提到一个名为3DV-Cache堆叠缓存的技术了。
简单说,在原有Zen3架构的基础上,为每个CCD计算芯片上堆叠64MB SRAM作为额外的三级缓存(图23),加上原本就有的32B,合计达96MB。之所以采用这个3DV-Cache堆叠缓存技术,是为了在最小的成本提升情况下,进一步扩展缓存容量,通过垂直堆叠(可以简单理解为在芯片内部堆叠到CPU核心之上,但并不是在CPU核心之中,这样有助于控制成本)这样的方式提升CPU的数据缓存交互能力。

經过这样一个简单的设计,锐龙75800X3D对比锐龙9 5900X在1080P高画质下游戏帧率平均提升15%左右,例如《看门狗》最高达到了40%;《Far Cry 6》、《战争机器5》、《最终幻想14》等则可以提升20%的性能。显然, 扩大缓存带来的性能提升,一点也不亚于提升核心计算单元的能力——其实,电脑经过这么多年的发展,数据瓶颈问题一直存在,这也是制约系统性能的一个重要症结,甚至要比优化CPU的计算能力重要。
除了AMD,英特尔也对CPU的设计上有着另一个思路——异构设计,要注意的是,其设计更偏向于如今ARM架构CPU的特点,与早期GPU+CPU的异构计算架构有区别。例如12代酷睿CPU将核心分为性能核心和能效核心(图24)。那么,它们的结构区别在哪里呢?先说说这个能效核心。能效核心的最显著特点就是后端执行能力增强,尤其是整数逻辑单元的计算能力(浮点运算部分也有一定提升),而功耗也能被控制在一个合理的范围区间,这也是一直以来能效核心的主要特点——这些所谓的能效核心,其实就是由著名的Atom系列CPU发展而来。而在性能核心上,英特尔着重加强了IPC性能,相比于11代酷睿CPU的核心,有多达19%的提升,其中浮点性能刻意加强,当然代价就是功耗增高。不过由于有了大小核心的异构设计,实际的功耗可以得到很好的平衡——在任务调度协调上,控制单元起到了关键性作用。想不到吧,CPU时至今日,无论核心如何变化,大框架实际没有什么改变。


CPU的技术名词越来越多,但是总体的框架设计依旧是“原来的样子”,很长时间内这一点都是无可改变的——如果有变更的那一天,必然是电脑产业界翻天覆地的变化,所有的体系都将改变。而且,随着技术的发展,我们将会看到更多诸如3D V-Cache堆叠缓存、大小核心设计等等“出圈”的CPU设计“思路”——在现有技术条件下,仅仅依靠制程工艺升级来增加晶体管提升性能,则控制功耗会愈加困难,制程工艺正在走向“死胡同”,唯有“挖空心思”在其他方面进行优化设计,尤其在数据传输瓶颈上多下功夫,才有机会进一步提升CPU的计算能力,不过,它们的工作基本原理依旧不会改变,这是CPU“先天基因”决定的。
