从再现到预测:基于BP神经网络的中小学生数字阅读素养评测体系研究
2022-05-30王佑镁李宁宇尹以晴柳晨晨
王佑镁 李宁宇 尹以晴 柳晨晨

[摘 要] 针对现有数字阅读素养评测中存在的概念不清和多采用主观构建评测指标等问题,有必要引入人工智能技术来改进评测方法。首先,使用层级分析法(AHP)确定数字阅读素养各维度及其指标权重,形成面向中小学生的数字阅读素养评测指标体系;其次,利用BP神经网络训练所收集的样本数据,生成能够再现专家评价体系的神经网络模型;最后,根据所开发的数字阅读素养评测系统得到数字阅读素养评测值,利用BP神经网络学习样本中關于专家指标值和评测值的映射关系,验证数字阅读素养评测指标权重的合理性,并存储该BP神经网络用于预测中小学生数字阅读素养评测值,从而形成客观合理的数字阅读素养评测体系,为我国中小学生数字阅读评测提供模型、工具和技术系统,也为相关领域评价体系建构提供一种方法。
[关键词] BP神经网络; 数字阅读素养; 层级分析法; 人工智能
[中图分类号] G434 [文献标志码] A
[作者简介] 王佑镁(1974—),男,江西吉安人。教授,博士,主要从事人工智能教育、数字阅读研究。E-mail:wangyoumei@126.com。
一、问题的提出
迅猛发展的互联网技术和不断普及的移动终端,使得数字阅读成为中小学生语言文字理解和知识建构的重要方式,数字阅读素养已成为个体数字化生存的核心素养[1-2]。数字阅读是近年国内外学术研究的热门议题,但数字阅读素养研究却没有得到应有重视。总体上看,国内研究多倾向于概念分析和经验研究,未能阐明中小学生数字阅读素养的结构内涵与评价指标[3];国外重要评测项目研究多从单一视角开展,缺少多模型的理论视域和技术分析[4],因此,使用新兴研究技术和方法对其评测指标开展研究显得尤为必要。同时,国内中小学生数字阅读素养评测技术工具研究明显滞后,国外数字阅读素养评测嵌入在阅读素养或者学业水平测试系统中,但尚未见独立的、成熟的评测量表与样卷[5],需要建构系统性强、操作性好的评测系统。
由于数字阅读素养上下级指标之间是典型的非线性映射,传统的统计学和结构方程模型(SEM)在解释非因果关系的维度变量中有着较大局限性,而具有自主学习能力、自适应组织能力及强非线性映射能力的BP神经网络[6],能被用于解决上述困境和不足。本研究根据中小学生数字阅读实际情况,建立一套合理的数字阅读素养评测指标体系以及评测系统,根据评价指标体系设计调查问卷,利用层级分析法对指标体系进行权重赋值,采用抽样调查收集数据,并利用中小学生样本对象的评测数据,以数字阅读素养问卷观测指标值为输入、以数字阅读素养系统评测值为输出构成样本集,采用BP神经网络对其进行分析和样本训练,生成输入与输出之间的非线性映射关系,形成基于BP神经网络的数字阅读素养评测体系,为我国中小学生数字阅读素养评测提供支持,也为相关领域评价体系建构提供一种方法。
二、基于BP神经网络的中小学生
数字阅读素养评估模型
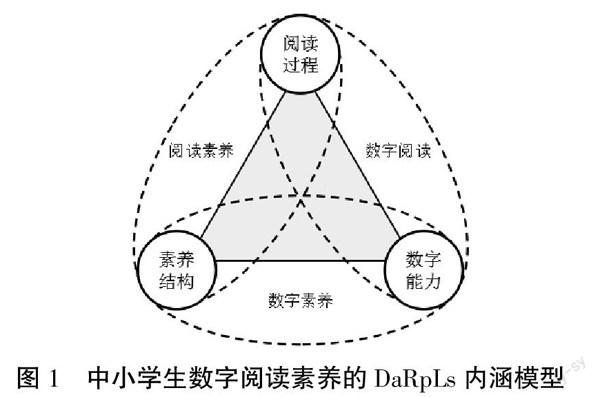
数字阅读素养评测是一项系统性和复杂性的工作,也是一种综合评价过程。其中,建立评价指标体系是最重要的要素之一,是其基础和核心[7]。国内的相关研究分别从数字化视角、阅读视角和混合视角对数字阅读素养的概念内涵进行了初步厘清,也在数字阅读素养能力结构的界定方面形成了三分法[8](数字阅读意识、能力、道德)、四分法[9](数字阅读意识、知识、技能、伦理)、五分法[4](数字阅读意识、知识、能力、方法策略、道德)的内涵结构体系。而国外的有关研究重视传统阅读素养测试中嵌入数字阅读素养评测,比较有影响的包括PISA、ePIRLS、ORCA等。因此,本研究基于素养模型、阅读素养、数字阅读行为、数字素养等理论视角,整合素养结构—阅读过程—数字能力三维结构,建立中小学生数字阅读素养的DaRpLs内涵模型(如图1所示),并以此为理论基础,融合国内有关数字阅读素养的研究,以及PISA、ePIRLS、OCRA等大规模国际评测指标体系中的数字阅读素养体系,进行中小学生数字阅读素养的评价指标开发。聚焦中小学生阅读认知理解、信息素养能力、创新性问题解决和道德伦理素养,建构包括数字阅读意识、数字阅读知识、数字阅读能力、数字阅读道德在内的中小学生数字阅读素养评价维度,映射至意识、元认知、行为、人际四大应用领域,形成从评价维度到观测点的三级评测指标体系,如图2所示。
(一)数字阅读素养评价指标权重的建立
数字阅读素养评测是一项复杂的、综合性的评测活动。因此,只确定中小学生数字阅读评测指标体系是不够的,需要对各评价指标的权重进行设置。层级分析法(Analytic Hierarchy Process,简称AHP)常被用于结合定性分析和定量分析,把复杂的问题分解成层次问题,极大地便于人们解决问题。层级分析法的基本思想是先对复杂的决策问题进行分解,得到具有关联性的有序层次结构。由于同层次的不同指标点进行比较会存在各自不同的相对重要性,因此,便会形成若干个同级指标两两比较下的判断矩阵,依次计算出各层指标元素的相对重要性权值,最后根据各层次之间指标上下级相对权重形成全部指标的权重,并据此对研究问题作出全面评估[10]。
层级分析法中构建指标层次结构需要满足以下条件:(1)同层指标为上层指标的子指标,并对上层指标产生影响;(2)同时该层指标又会影响下层指标,并受到下层指标的反作用;(3)同层指标保持相互独立。这些层次具体可分为目标层、准则层和方案层。虽然不对层次结构中的级别个数进行限制,但也要根据问题的复杂程度谨慎设置层次数,尽量确保各个层次的指标数不超过9个,以免形成过多两两比较而对判断矩阵的构建造成困难。
本研究的专家小组首先通过对数字阅读素养影响因素的深入分析,根据普遍采用的1-9标度法,对各级指标建立起各级判断矩阵。其次,使用MATLAB软件进行软件编程,求解出判断矩阵的最大特征根λ,以及和λ所对应的特征向量;随后对所求解进行一致性检验,得到的检验结果中显示一致性比率小于0.1,则表明检验通过。最后对最大特征根向量归一化处理,就可以得到所求的各个评价指标的权重,部分MATLAB代码如图3所示。
对每一个判断矩阵都进行上述的一致性检验操作后,得到了中小学生数字阅读素养各个评价指标的权重,见表1。
(二)BP神经网络模型的构建
BP神经网络算法本质上是一种具有多层次结构神经网络的学习方法,其特点是信号向前传递,而算法训练的误差向后传递,在比较误差和期望值的过程中,对每一层网络的连接权值以及阈值不断地进行调节,重复多次最终使得神经网络的训练输出尽可能地与期望输出接近,从而完成神经网络训练目的[11]。
1. BP神经网络结构及其描述
BP 神经网络模型如图4所示,主要包含输入层、隐含层和输出层这三个部分。该图展示了一个由l层神经元组成的多层神经网络,第一层与最后一层分别是输入层和输出层,而第2层到第l-1层均被称为隐含层。
令输入向量为:
其中,f(x)是神经元的激活函数,neti(l)则代表l层第i个神经元的输入。
建立BP神经网络模型分为两个步骤[12]:(1)输入信号的正向传播过程,先构建一个给定神经网络,设置好输入、输出以及隐含层的神经元节点数并赋值初始连接权值和阈值,将训练样本作为输入,由输入层传递到隐藏层,在隐藏层中经过数据处理后传递给输出层,由输出层处理后会产生一个输出;(2)误差信号的反向传播过程,神经网络处理后的实际输出会与期望的输出值产生一定的误差,反馈该误差值,将其沿神经网络进行反向传播,修正调整相关的连接权值与阈值用以进行下一次计算。对于每一个输入重复上述两个过程,直到神经网络达到设定的训练次数或输出的误差减小到可以接受的程度。
假定现在有m个用来进行神经网络训练的样本集合{(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))},其中d(i)为对应输入x(i)的期望输出(即实际值),对于给定的m个训练样本,定义误差函数为:
这种神经网络的BP算法就是通过上述的过程,把输入的信号通过正向传播得到输出值,把获得的误差信号反向传播,进而调整连接权值与阈值,采用批量更新的方法对该神经网络的权值和阈值进行不断循环往复的更新,对各层神经元的连接权值以及阈值的最优化计算,让神经网络的样本训练输出值与期望的输出尽可能地接近,直到E小于给定误差值或者达到规定的最大训练次数,以达到训练的目的[13]。
2. BP神经网络的MATLAB软件实现
构建BP神经网络时,需要根据实际情况对该神经网络的隐含层层数、隐含层节点数、输入样本进行神经网络的初始权值和阈值、神经元激活函数、训练参数、训练样本数据的归一化等方面的设定操作。MATLAB軟件中集成了人工神经网络工具箱,可以根据实际需要直接调用,无需再进行复杂的求解过程,极大地方便了BP神经网络的应用[6]。
在MATLAB软件中,newff函数可以用来生成BP神经网络并进行初始化赋值,具体函数语法表现为:net=newff(P,T,S,TF,BTF,BLF,PF,IPF,OPF,DDF),根据函数格式和实际样本情况对神经网络中各个参数进行设置,便可以得到一个未经训练的初始BP神经网络。由于初始生成的神经网络中,连接权值和阈值都是随机赋值的初始值,因而必然会存在着较大误差,接下来需要设置训练参数进行训练,不断修正连接权值和阈值以减小误差。
训练神经网络使用的函数名是train,设定后会根据神经网络的样本输入值与目标期望输出样本[14],对初始随机赋值生成的神经网络进行根据BP算法的计算,不断地通过比对误差来修正神经网络各层的权值连接和阈值,以达到最终的设定要求。而不同训练算法的选择也会影响训练的速度和精度,需要根据实际样本数据不断调试。
三、分析与结果
数字阅读文本具有互动性、多模态性和可扩展性等特点,要求读者具备不同于纸质文本阅读的新的技能与策略。本研究针对数字阅读利用数字化平台或移动终端定位、获取、阅读和传递、反思和评价、管理与创造多种形式阅读资源时所具备的知识、能力和文化的综合素养,设计了数字阅读素养评测量表工具,用于评测数字阅读素养的自我反思与实践体验。量表设计主要采用李克特五点分级,主要用于考查中小学生对数字文本多模态信息获取、使用、评价、反思和创造的能力与素质。
(一)BP神经网络参数设定
在BP神经网络的结构设定中,有关于各隐含层节点数量以及隐含层的层数,虽然在理论上可以设置多个,但若是神经网络的网络结构设定得太过复杂,就意味着要设置很多的训练参数,计算的过程进一步复杂化,这往往会导致模型的精度变差,也会使神经网络训练时间过长[15]。Kolmogorov定理表明,具有一个隐含层的三层BP神经网络,当隐含层的神经元节点数尽可能多,便能实现对任意非线性函数无限逼近[16]。基于此定理,本研究构建了具有一个隐含层的三层 BP 神经网络。
输入项的特征点决定输入层节点数,在本研究中,中小学生数字阅读素养三级评价指标有10个,因此,输入层的神经元节点数为10。中小学生数字阅读素养系统实际测试评价结果作为神经网络的单输出,因而设定输出层的神经元个数为1。而有关隐含层节点数的设置,并无成熟的理论对其进行验证,许多学者曾研究如何来确定一个恰当的隐含层神经元节点个数。节点个数过少,会使得网络难以识别出样本,可能导致训练失败或精度低,但若是隐含层神经元节点个数过多,神经网络的训练时间则会被延长,同时该神经网络的泛化能力会大幅降低[17]。本研究根据具体样本数和实际情况,多次尝试对不同神经元进行训练,发现确定的隐含层节点数为10时效果最好,最终在MATLAB软件中得到如图5所示的三层BP神经网络模型。
该神经网络的训练参数设置如下:输入层和隐含层之间的激活函数设定为tansig;隐含层和输出层之间的激活函数设定为purelin;训练函数则采用有动量和自适应lr的梯度下降法traingdx函数;同时根据样本数据的特点和实际需求,将学习次数阈值设定为10000;目标误差设定为0.0001;学习速率取0.01。
(二)模型对比与验证
1. BP神经网络再现专家评价指标
本研究收集到的有效样本数量为295个,将中小学生数字阅读素养评价指标A1、A2、B1、B2、B3、C1、C2、C3、D1、D2共10个指标作为BP神经网络的输入向量。考虑到每个指标维度具有不同的题目数,因此,学生在各个维度的量表得分需要根据题目数量求加权平均分,将该加权平均分作为该维度下的样本输入,并对每一个维度都进行此操作,最终得到结合专家指标权重评价的样本输入向量。将维度下的加权平均分乘以前文提出的各指标权重,进行求和,最终得到综合数字阅读素养自测值的评价结果矩阵,组成神经网络的输岀向量。
在神经网络中,隐含层所采用的的一般是S型或双极S型激活函数,输入的数值范围需要在1的绝对值内,这就需要对输入和输出数据进行归一化处理。采用的函数为mapminmax,作为一种线性转换函数,它可以很好地保存数据原始意义而不造成数据遗失[18]。先将各个评价指标的分值做归一化处理,以使数据集中在[-1,1]范围内。
然后将处理过的数据中的280项作为训练样木集训练网络,其余的15项数据则作为测试样本集输入完成训练的神经网络中进行误差测试。这15项测试集的数据经由神经网络模型进行仿真处理,并把仿真得到的数据通过反归一化还原为原始的数量级,作为15项测试集的预测值与其真实值进行对比计算误差,计算决定系数R2,验证其回归拟合程度。部分MATLAB代码如图6所示。
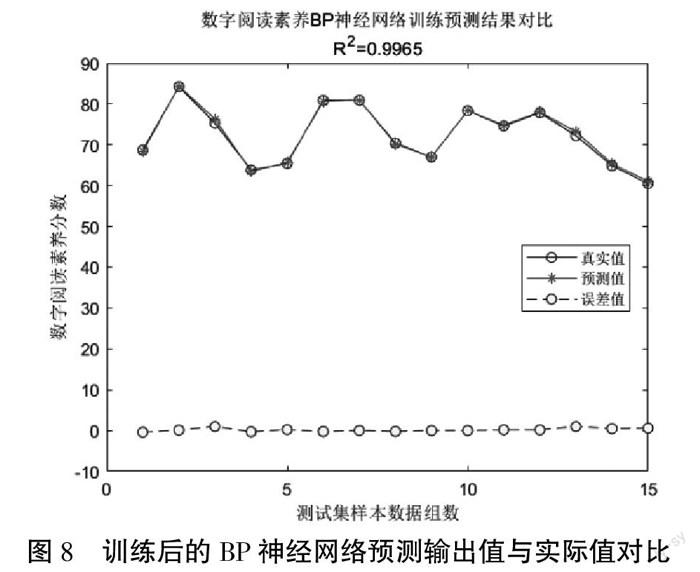
如图7所示,神经网络迭代5406次即完成收敛,达到规定误差精度,回归拟合的效果非常好。将数字阅读素养真实值与神经网络预测值的误差进行比较,如图8所示,训练完成的神经网络模拟数字阅读素养评价输出值,非常接近真实评价数值,即表明经过训练完成的BP神经网络具有非常好的非线性函数逼近效果。
经过神经网络训练不断修正后的连接权值和阈值,此时不再发生改变,神经网络经过自适应学习后,得到了无限迫近先前对各维度评价指标拟定的专家评价指标权重。也就是说,该神经网络学习了专家知识和经验,其输入—输出的映射关系,在某种意义上来讲,就是专家小组利用层级分析法确定的数字阅读素养评价指标权重体系。
训练好的神经网络积累了评价专家的知识和经验,将其进行保存后就能成为有效进行评价的工具。以后当需要对中小学生数字阅读素养进行评价时,可以向已经训练完成的BP神经网络中输入对应的数字阅读素养评价指标的数据矩阵,该神经网络就会对专家的知识和经验进行再现,从而在没有人为干预的情况下,即时做出响应,形成评价结果。这样可以有效避免传统评价中可能出现的人为失误,提高评价的准确度,从而极大地提高工作處理数据的效率[11]。
2. BP神经网络验证指标权重的合理性
虽然已经利用BP神经网络再现专家小组知识和经验,但专家小组确定的评价指标权重体系是否合理,是否能够符合大数据样本的实际情况,还有待商榷。此外,中小学生通过数字阅读素养问卷得到的数字素养自测值,能否代表其真实数字阅读素养水平,也是一个需要回答的问题。同时,学生的数字阅读素养也需要一个基于真实数字阅读环境的评测系统进行测量。
因此,结合前文所提出的目前数字阅读素养评测所存在的困境与不足,在操作层面,本研究开发了一个PC端和Android移动端的中小学生数字阅读素养评测系统(如图9所示),并通过一定规模的中小学场景实证应用,反馈修正评测技术工具并完善系统。该系统设计遵循以非线性方式呈现文本的要求,模拟出一个数字化的阅读环境,数字阅读任务的完成需要基本的数字化素养与传统的阅读理解能力的相互融合。评测系统注重给学生创造情境性的、拟真性的阅读任务环境,注重考查学生在多文本阅读过程中的表现。
基于此中小学生数字阅读素养评测系统,研究中测量得到了学生在数字阅读倾向、数字阅读动机、数字技术知识、数字阅读内容知识、数字阅读策略知识、信息获取与整合能力、阅读认知与理解能力、信息评价与使用能力、隐私与安全、规范与道义10个维度的数字阅读素养实际得分。
该得分并未结合专家小组提出的权重计算,而是对每个维度赋予相同权重,得到的是数字评测环境下中小学生的真实数字素养水平。先前之所以要对量表各个指标进行权重分配,是因为各个指标在评价综合成绩的过程中反映出各自不同的重要程度,是否科学合理地对指标权重进行分配,会直接影响评价结果。而此时对数字阅读素养评测系统得分不进行权重分配,是为了探究在大样本数据量下,能否通过BP神经网络,对考虑权重的各个评价指标值与未考虑权重的综合成绩进行拟合并得到较好的拟合效果。如果将考虑权重的各个评价指标值作为输入向量,将未考虑权重的评测系统数字阅读素养得分作为输出向量,其输入—输出的映射关系反映出较好的拟合水平,则说明专家小组通过层级分析法构建的中小学生数字阅读测评指标权重体系具有合理性,中小学生数字阅读测评量表能够反映大样本数据量下中小学生的真实数字阅读素养水平。
研究过程中收集到45份有效的中小学生数字阅读素养评测系统评分,将这45位学生在各个维度的量表得分根据题目数量求加权平均分,乘以专家小组提出的各指标权重,得到结合专家指标权重评价的样本输入向量;将收集到的这45位学生的中小学生数字阅读素养评测系统评分加以组合,得到综合数字阅读素养系统评测真实值的评价结果矩阵,组成神经网络的输岀向量。然后将处理过的数据中的40项作为训练样木集训练网络,其余的5项数据则作为测试样本集输入完成训练的神经网络中进行误差测试。这5项测试集的数据经过神经网络模型进行仿真处理,把仿真得到的数据通过反归一化还原为原始的数量级,作为5项测试集的预测值与其真实值进行对比计算误差,计算决定系数R2验证其回归拟合程度。MATLAB代码与前文类似,只需要对部分参数进行修改。
如图10所示,神经网络迭代2580次即完成收敛,达到规定误差精度。将数字阅读素养真实值与神经网络预测值的误差进行比较,如图11所示,训练完成的神经网络模拟数字阅读素养评价输出值,非常接近真实评价数值,即表明经过训练完成的BP神经网络具有非常好的非线性函数逼近效果。
不断经过神经网络训练修正后的连接权值和阈值,此时不再发生改变,神经网络经过自适应学习后,得到考虑权重的各个评价指标值与未考虑权重的评测系统数字阅读素养得分之间的输入—输出的映射关系。此时,该神经网络不再是学习了专家知识或经验,而是验证了专家小组评价指标权重体系的合理性。其输入—输出的映射关系说明,即使在大量样本数据下,根据专家小组评价指标权重体系进行问卷调查得到的指标观测值,依然能够反映学生的真实数字阅读素养水平。
3. 存储神经网络预测数字素养评测值
既然该神经网络能够用于验证指标权重合理性,并且本研究所建立的BP神经网络模型拟合精度较高,神经网络的数字阅读素养预测值与实际值较小(见表2),该对比显示,用于检验的样本中,其神经网络模型的预测值和系统评测真实值的相对误差不超过4.33%,表明该神经网络模型适用于中小学生数字阅读素养评价问题,所得到的预测结果可信度较高。因此,该神经网络模型亦可用于对中小学生数字阅读素养系统评测得分进行预测。
也就是说,利用中小学生数字阅读素养评测量表收集到数字阅读素养自测值,结合专家小组提出的指标权重体系,得到的数字阅读素养各维度观测值作为输入向量,神经网络能够根据之前训练好的映射关系输出数字阅读素养预测值。
此时,神经网络实现了对中小学生数字阅读素养的预测,这能极大地扩展数字阅读素养评测场景。考虑到不同地区间的设施差异,并不是所有学生都能够采用完善的数字阅读环境评测数字阅读素养,利用BP神经网络模型和开发的数字阅读素养量表,能够让学生无需再在数字阅读素养评测系统中进行测验,便可以根据量表观测值模拟得出其评测系统得分,该模型的实用价值得到进一步提升。
四、结 语
本文综合使用抽样调查、评价研究、层级分析法(AHP)、BP神经网络模型等方法,探究中小学生数字阅读素养评价指标体系,开发中小学数字阅读素养量表和评测系统进行评测,实现了BP神经网络应用于数字阅读素养评测过程,并通过MATLAB软件对设计好的BP神经网络模型进行训练和测试,获得较为准确可靠的评价结果。本研究实际上探索了一种基于人工智能技术的评测体系建构方法,为中小学生数字阅读评测提供模型、工具和技术系统,也可以为相关领域评价体系建构提供一种方法,尤其是对于建构主观性较强、指标维度之间存在交叉难以判断的测评体系更具参考价值。
存在的问题及改进之处在于:由于生成神经网络的时候,MATLAB软件会赋予随机生成的连接权值和阈值,经由样本输入后的BP算法不断修正误差达到训练要求以得到最终值,神经网络每次训练过程的迭代次数、训练时间以及回归拟合度都是不同的,需要多次训练才能得到较为符合需求的神经网络。此外,训练样本数据也会对神经网络的训练产生较大影响,不仅会影响对神经网络训练的结果,也会影响构造出的网络系统的适用性。因此,在选取数据样本时,需要采用更加科学的选取方法,筛选出的数据样本需要更具代表性,可以扩大神经网络模型的适用范围。本研究过程训练生成并保存了两个可用于后续研究的神经网络,后续将通过不断增加训练样本数,提升神经网络模型的训练精度。
[参考文献]
[1] 樊敏生,武法提,王瑜.数字阅读:电子书对小学生语文阅读能力的影响[J].电化教育研究,2016,37(12):106-110,128.
[2] 赖文华,王佑镁,杨刚.语言图式和内容图式对数字化阅读影响的实证研究[J].电化教育研究,2015,36(7):89-93.
[3] 周惠敏.大学生数字阅读素养现状及提升策略研究[J].大学图书情报学刊,2019,37(01):55-61.
[4] 杨帆.大学生数字阅读素养评价研究[D].临汾:山西师范大学,2017.
[5] 岑佳怿.小学生数字化阅读素养调查研究[D].重庆:西南大学,2020.
[6] 罗成汉.基于MATLAB神经网络工具箱的BP网络实现[J].计算机仿真,2004(05):109-111,115.
[7] 王宗军.综合评价的方法、问题及其研究趋势[J].管理科学学报,1998(1):75-81.
[8] 王健,张立荣.新媒介时代大学生数字化阅读素养的内涵与培养[J].现代远距离教育,2011(6):73-77.
[9] 张传真.大学生数字阅读素养现状调查及提升策略研究[D].曲阜:曲阜师范大学,2018.
[10] 邓雪,李家铭,曾浩健,陈俊羊,赵俊峰.层次分析法权重计算方法分析及其应用研究[J].数学的实践与认识,2012,42(7):93-100.
[11] 蔡会娟.基于AHP和BP神經网络的高校研究生综合素质评价研究[D].新乡:河南师范大学,2014.
[12] 姚裕盛,徐开俊.基于BP神经网络的飞行训练品质评估[J].航空学报,2017,38(S1):24-32.
[13] 乔维德.基于BP神经网络的现代远程教育教学质量评价模型的构建[J].中国远程教育,2006(7):69-71.
[14] 李学锋,钟叔玉.数据挖掘及其在矿业中的应用研究[J].矿业研究与开发,2006(5):51-54.
[15] 沈花玉,王兆霞,高成耀,秦娟,姚福彬,徐巍.BP神经网络隐含层单元数的确定[J].天津理工大学学报,2008(5):13-15.
[16] HECHT-NIELSEN R. Kolmogorov's mapping neural network existence theorem[C]//Proceedings of the International Conference on Neural Networks. New York: IEEE Press, 1987: 11-14.
[17] 宋宇辰,何玮,张璞,韩艳.基于BP神经网络的资源型城市可持续发展指标预测[J].西安财经学院学报,2014,27(6):79-84.
[18] 袁曾任.人工神经元及其应用[M].北京:清华大学出版社,1999.
From Reproduction to Prediction: Research on Digital Reading Literacy Evaluation System for Primary and Secondary School Students Based on
Back-propagation Neural Network
WANG Youmei, LI Ningyu, YIN Yiqing, LIU Chenchen
(Research Center for Big Data and Smart Education, Wenzhou University, Wenzhou Zhejiang 325035)
[Abstract] Given the problems of unclear concepts and subjective construction of evaluation indicators in the existing digital reading literacy evaluation, it is necessary to introduce artificial intelligence technology to improve the evaluation method. Firstly, the analytic hierarchy process(AHP) is used to determine the dimensions of digital reading literacy and their index weights, so as to form a digital reading literacy evaluation index system for primary and secondary school students. Secondly, the sample data collected by BP neural network training is used to generate a neural network model that can reproduce the expert evaluation system. Thirdly, according to the developed digital reading literacy evaluation system, the digital reading literacy evaluation value is obtained, the mapping relationship between expert index value and evaluation value in BP neural network learning sample is used to verify the rationality of the weight of digital reading literacy evaluation index, and the BP neural network is stored to predict the digital reading literacy evaluation value of primary and secondary school students, so as to form an objective and reasonable digital reading literacy evaluation system to provide models, tools and technical systems for digital reading evaluation of primary and secondary school students in China, and also provide a method for the construction of evaluation system in related fields.
[Keywords] Back-propagation Neural Network; Digital Reading Literacy; Analytic Hierarchy Process; Artificial Intelligence
基金項目:国家语委2019年度重点(信息化专项)科研项目“我国中小学生数字阅读素养测评技术研究”(项目编号:ZDI135-113)
