基于深度学习的Spring Cloud负载均衡优化研究
2022-05-30吴岚若







摘要:针对微服务框架Spring Cloud中内置负载均衡算法不能全面反映负载与负载滞后的不足,文章提出一种基于深度学习负载预测的负载均衡算法,以更全面的负载模型衡量微服务节点的负载,并使用GRU神经网络进行负载预测,根据负载预测值动态调整微服务节点的权重,再基于加权轮询算法进行负载均衡,进一步地提升微服务应用系统的响应速度与资源利用率。实验采用Jmeter进行仿真测试,并将本文提出的算法与Spring Cloud的内置算法进行对比。实验结果表明,在线程并发数较多的情况下,该算法能更有效地在使用Spring Cloud搭建的微服务应用系统中实现负载均衡。
关键词:微服务;Spring Cloud;负载均衡;GRU网络;负载预测
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2022)10-0080-04
随着互联网技术与云计算的发展,单体架构已经越来越不适应于日新月异的应用需求。在单体架构中,应用程序通常被构建为一个不可分割的整体[1],随着项目的扩展,单体架构应用的开发、部署、维护会越来越困难[2],因此,微服务架构逐渐兴起。微服务架构是旨在将软件系统分解为一组独立的微小服务的云原生架构[3],这组微小服务可以独立部署在不同平台,也可以使用不同的技术栈。微服务架构可以克服单体架构的缺点,增强系统的可扩展性、高并发性、高可用性[4],因此被越来越多的企业与研究机构使用。
在各种微服务框架中,Spring Cloud是较为流行的一种。据云原生产业联盟发布的《中国云原生用户调研报告(2020年) 》[5]显示,Spring Cloud是微服务架构的用户首选。由于微服务架构将软件系统分解为了粒度较小的微服务,故服务治理技术也更加复杂。在服务治理技术中,负载均衡技术十分关键,通过优化微服務架构中的负载均衡技术可以有效减少请求延迟,提高微服务架构的可靠性和资源利用率[6]。
Spring Cloud Ribbon是Spring Cloud的负载均衡组件,其内置负载均衡算法存在负载衡量不全面与负载滞后的缺点。如果能较为全面地计算负载值,并掌握负载变化的未来趋势,对负载值进行预测,则能更好地提升负载均衡算法的性能。本文针对Spring Cloud Ribbon中存在的问题,提出了一种基于深度学习负载预测的负载均衡算法,该算法提出了一种更全面的模型衡量负载,并对负载进行预测,进一步提升了微服务应用系统的响应速度与资源利用率。
1 负载预测
1.1 微服务节点负载模型
微服务节点的负载能反映微服务节点的处理性能。选取适当的负载评价指标对负载进行计算得到综合负载值,再基于综合负载值进行请求分配,可以进一步提升负载均衡算法的准确性。
本文选取了CPU利用率、内存利用率、网络利用率、IO利用率四个负载评价指标衡量节点的动态负载。由于节点本身的服务器配置也会影响到节点的性能,并且配置信息一般不会改变,因此本文将服务器的配置信息也加入负载的衡量中。
为了更准确地表示微服务节点的负载,引入以下定义:
定义1:静态性能
微服务节点的配置信息可以反映节点的基础性能,本文采用的配置信息有CPU核心数、内存容量与网络带宽。节点[ ⅈ ]的静态性能(Static Capacity)记为[SCi],计算如公式(1) 所示:
通过上述计算得出本文构造的判断矩阵[A]通过一致性检验,故可将归一化特征向量作为权向量。
1.2 GRU神经网络模型
负载具有实时性,而动态负载均衡算法中使用的负载数据往往具有滞后性。在Spring Cloud中,负载信息的采集周期,服务消费者将负载数据更新到注册中心的续约周期,以及服务消费者从服务注册中心拉取服务注册表的周期都导致了负载数据的滞后。如果能掌握负载的变化趋势,对负载进行预测,以负载预测值作为请求分配的依据运用在负载均衡算法中,则能提升系统负载均衡的性能。本文提出了一种基于深度学习的负载预测模型,该模型使用GRU神经网络对负载进行预测,降低负载数据的时延,提升负载均衡算法的准确性。
深度学习的概念源于人工神经网络的研究,主要使用深度神经网络作为工具解决问题。当深度学习用于时序数据预测时,网络结构主要使用循环神经网络(RNN) 。RNN是一类用于处理序列数据的神经网络,包括双向RNN、门控RNN等。其中门控RNN,如LSTM和GRU,有效优化了RNN中梯度爆炸和梯度消失问题。本文使用GRU神经网络进行负载预测,相比LSTM[8],GRU简化了门结构,能有效加快训练速度,提高计算效率[9]。
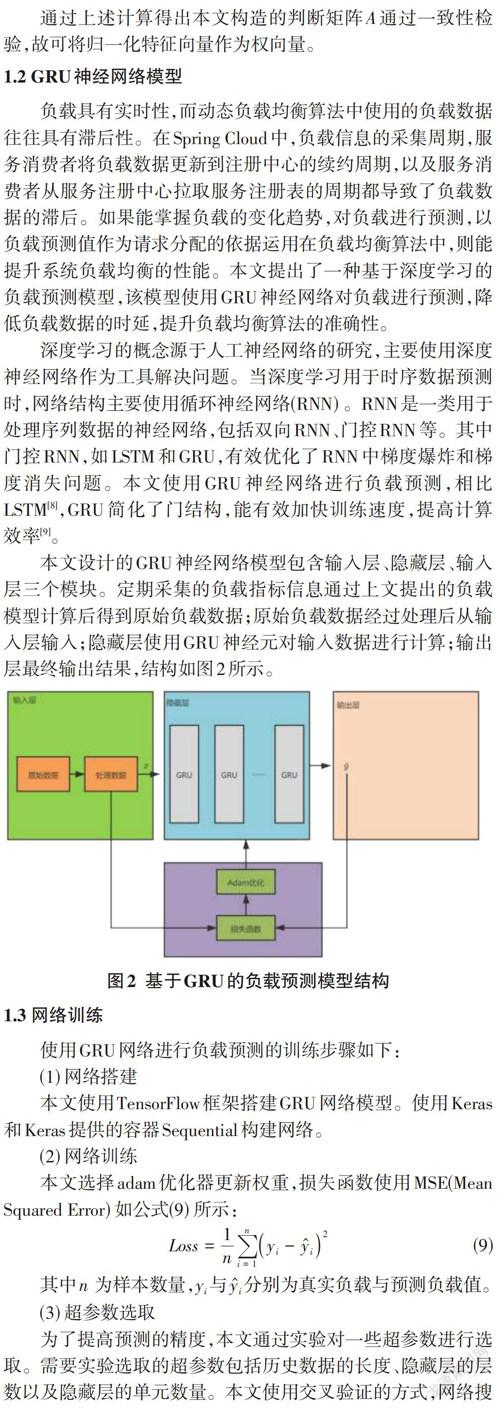
本文设计的GRU神经网络模型包含输入层、隐藏层、输入层三个模块。定期采集的负载指标信息通过上文提出的负载模型计算后得到原始负载数据;原始负载数据经过处理后从输入层输入;隐藏层使用GRU神经元对输入数据进行计算;输出层最终输出结果,结构如图2所示。
1.3 网络训练
使用GRU网络进行负载预测的训练步骤如下:
(1) 网络搭建
本文使用TensorFlow框架搭建GRU网络模型。使用Keras和Keras提供的容器Sequential构建网络。
(2) 网络训练
本文选择adam优化器更新权重,损失函数使用MSE(Mean Squared Error) 如公式(9) 所示:
[Loss=1ni=1nyi-yi2] (9)
其中[n ]为样本数量,[yi]与[yi]分别为真实负载与预测负载值。
(3) 超参数选取
为了提高预测的精度,本文通过实验对一些超参数进行选取。需要实验选取的超参数包括历史数据的长度、隐藏层的层数以及隐藏层的单元数量。本文使用交叉验证的方式,网络搜索进行参数选取。网格搜索定义一个三维方格,每格对应一种超参数组合。
(4) 模型评价
使用MAPE和RMSE对模型进行评价,如公式(10)(11) 所示:
[MAPE=100%ni=1nyi-yiyi] (10)
[RMSE=1ni=1nyi-yi2] (11)
其中[n ]为样本数量,[yi]与[yi]分别为真实负载与预测负载值。
2 基于深度学习负载预测的负载均衡算法
服务提供者的负载预测值将通过Spring Cloud的续约机制更新到服务注册中心,并作为微服务元数据写入服务注册表,最终被服务消费者拉取。Spring Cloud的续约周期与服务消费者拉取服务注册表的周期均会导致负载数据的滞后性。本文根据负载预测值计算各微服务节点权重,基于加权轮询算法进行请求分配,对未来负载变化趋势不同的微服务节点进行动态权重调整,从而有效避免负载滞后问题。
2.1 权重计算
(1) 初始权重:
记微服务节点[ⅈ ]的初始权重为[W'i],计算如公式(12) :
[W'i=CLoadi] (12)
其中[C ]为权重常量调节因子,[Load(i) ]为该节点的负载值。在初始未获取微服务节点的动态负载时,[Load(i)]由微服务节点的静态性能决定。
(2) 权重动态调整
为了更准确地调整微服务节点权重,本文设定了三个阈值[Loadl]、[Loadh]、[Loadm],并根据这三个阈值对微服务健康等级进行分级。当微服务负载值属于[(0,Loadl)]时,其处于低负载状态,健康等级记为[LLoad];当负载值属于[(Loadl,Loadh)]时,其处于正常负载状态,健康等级记为[NLoad];当负载值属于[(Loadh,Loadm)]时,其处于高负载状态,健康等级记为[HLoad];当负载值属于[(Loadm,1)]时,其不可用,健康等级记为[Down]。
引入权重修正因子[β],计算如公式(13) :
[β=LoadiAvgLoadi ] (13)
其中[ AvgLoad(i) ]为该微服务所有实例的负载平均值。当微服务实例健康等级为[LLoad],说明实例较空闲,剩余性能较好,应当增大其权重;健康等级为[NLoad],说明该实例处于正常状态,无需调整权重;健康等级为[HLoad],说明该实例负载较重,应当减少其权重;不可用实例权重为0。权重调整公式如公式(14) 所示。
[Wi=CWi+β,LLoadWi,NLoadWi-β,HLoad0, Down] (14)
根据动态调整后的权重进行请求分配,可以有效优化负载不均的情况,提升系统的资源利用率。
2.2 算法运行流程
考虑到当系统整体负载较小时,采用本文算法造成的资源消耗可能会影响负载均衡效果,故当总平均响应时间低于设定的阈值时,本文采取Spring Cloud Ribbon内置的WeightedResponseTimeRule。WeightedResponseTimeRule会根据响应时间进行权重计算,微服务节点的响应时间越长,被选择的概率就越小。
当请求到达时,服务消费者节点会遍历该请求需调用的微服务对应的所有实例,计算所有实例的平均响应时间[Tavg],若[Tavg]小于阈值[T],则说明目前系统中负载较小,采取Spring Cloud Ribbon内置的WeightedResponseTimeRule进行负载均衡。
若[Tavg]大于阈值[T],则采取基于深度学习负载预测的负载均衡算法。算法设计如算法1所示:
算法1 基于深度学习负载预测的负载均衡算法
输入:需调用微服务对应的所有实例集合[I];
输出:权重最大的微服务实例[ Ik]。
1. for each [ Ii∈ I] do
2. [Load(i)] [← ]getPredictLoad([ Ii)];
3. if [Load(i)] [∈(Loadm,1)] then
4. Weight([ Ii])[ ← ]0
5. else if [Load(i)] [∈(Load0,Loadl)] or [Load(i)] [∈(Loadh,Loadm)] then
6. Weight([ Ii])[ ← ]adjustWeight([ Ii])
7. else
8. continue
9. end if
10. end for
11. return getBiggestWeight([I])
算法1遍歷所有微服务实例,获取各实例的负载预测值,判断其是否需要调整权重,为负载较高或较低的微服务调整权重,不可用的微服务节点权重设置为0。重复上述过程,直到遍历完毕,最终输出权重最大的微服务实例,选择该实例分配请求。
3 算法性能分析
本文使用基于Spring Cloud搭建的微服务应用系统进行测试。选取平均响应时间与吞吐量这两个评价指标,使用Jmeter模拟用户并发请求,验证本文对Spring Cloud负载均衡性能的提升。
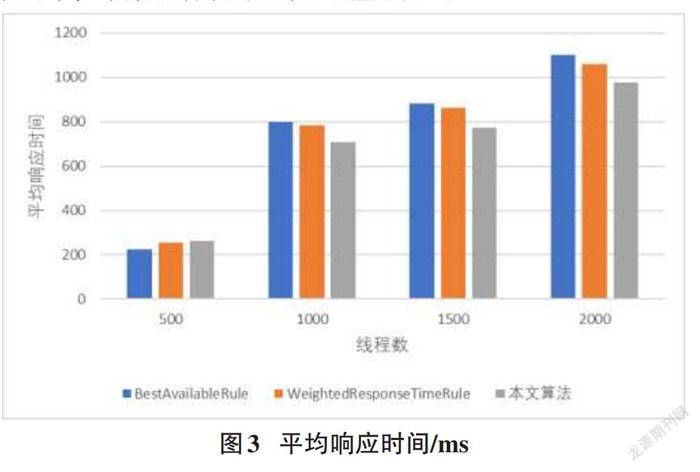
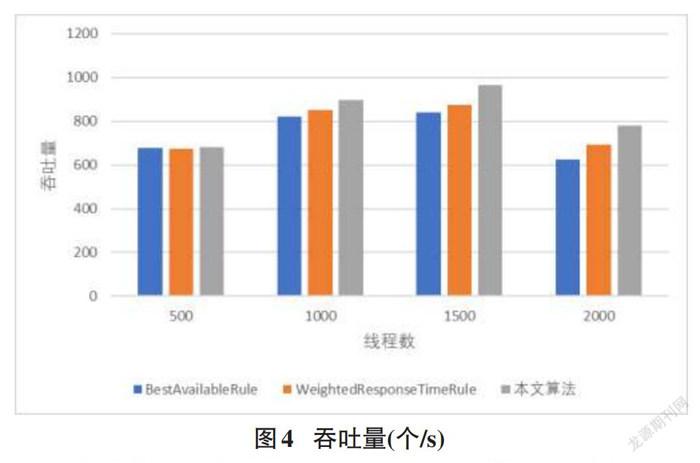
将本文提出的算法与Spring CloudRibbon内置的BestAvailableRule、WeightedResponseTimeRule进行实验对比,测试结果如下,平均响应时间见图3,吞吐量见图4。
从图3与图4的实验结果可以看出,当并发线程数较少时,本文算法与Ribbon内置算法对比没有明显优势。这是由于在并发量较小的情况下,平均响应时间与吞吐量主要取决于算法本身的复杂度,本文在负载较轻时会采取 Ribbon 内置的 WeightedResponseTimeRule。但当并发线程数在1000及以上时,应用本文提出的算法明显增加了系统的吞吐量,减少了平均响应时间,提升了系统的负载均衡效果。因此可以得出本文提出的算法,在并发量比较高的情况下要优于Ribbon的内置算法。
4 结束语
本文针对微服务框架Spring Cloud中内置负载均衡算法负载衡量不全面与负载滞后的缺点,提出了一种基于深度学习负载预测的负载均衡算法。该算法定期采集微服务节点的负载信息,通过一种较全面的负载模型进行负载计算,并使用GRU神经网络对负载值进行预测,根据负载预测结果进行权重计算,微服务节点的权重能根据负载的变化趋势进行动态调整,使客户端请求分配更加合理。实验结果表明,该算法与Spring Cloud Ribbon中的内置算法相比,在并发线程数较多的情况下,有效地优化了负载均衡性能,进一步提升了微服务应用系统的响应速度与资源利用率。
参考文献:
[1] SHABANII,BERISHAB,BIBAT,et al.Designof Modern Distributed Systems based on Microservices Architecture[J].International Journal of Advanced Computer Science and Applications,2021,12(2):153-159.
[2] Villamizar M,Garcés O,Ochoa L,et al.Cost comparison of running web applications in the cloud using monolithic,microservice,and AWS Lambda architectures[J].Service Oriented Computing and Applications,2017,11(2):233-247.
[3] Balalaie A,Heydarnoori A,Jamshidi P.Microservices architecture enables DevOps:migration to a cloud-native architecture[J].IEEE Software,2016,33(3):42-52.
[4] Liu G Z,Huang B,Liang Z H,et al.Microservices:architecture,container,and challenges[C]//2020 IEEE 20th International Conference on Software Quality,Reliability and Security Companion.December 11-14,2020,Macao,China.IEEE,2020:629-635.
[5] 云原生產业联盟.中国云原生用户调研报告(2020年):云原生热点技术使用现状全披露[EB/OL].[2022-2-21].https://www.sohu.com/a/426326675_753085.
[6] Wang H,Wang Y,Liang G Y,et al.Research on load balancing technology for microservice architecture[J].MATEC Web of Conferences,2021,336:8002.
[7] DANNER M,GERBERA.Patient Involvement in Health Technology Assessment[M].Gewerbestrasse:Springer,2017.
[8] Song B B,Yu Y,Zhou Y,et al.Host load prediction with long short-term memory in cloud computing[J].The Journal of Supercomputing,2018,74(12):6554-6568.
[9] Yamak P T,Li Y J,Gadosey P K.A comparison between ARIMA,LSTM,and GRU for time series forecasting[C]//ACAI 2019:Proceedings of the 2019 2nd International Conference on Algorithms,Computing and Artificial Intelligence.2019:49-55.
【通联编辑:唐一东】
收稿日期:2021-12-15
作者简介:吴岚若(1997—) ,女,安徽铜陵人,硕士,研究方向为软件工程。
