大数据在乡村振兴发展水平评价中的应用
——以乡村称号数据为例
2022-05-28巩蓉蓉
□ 刘 瑾 李 振 巩蓉蓉 刘 英
(1.中央民族大学 经济学院, 北京 100081; 2.复旦大学 大数据学院, 上海 200433;3.珠海复旦创新研究院, 广东 珠海 519000; 4.中国人民大学 重阳金融研究院, 北京 100872)
一、引 言
中共十九大提出乡村振兴战略,明确“产业兴旺、生态宜居、乡风文明、治理有效、生活富裕”二十字方针。在此背景下,如何对各地乡村振兴发展水平进行测度和评价,发掘优势,补全短板,进而因势利导推动乡村发展,是实现中国乡村振兴的关键。当前,已有研究通过构建相关指标体系来测度中国乡村振兴发展水平,并使用统计年鉴[1]、农业普查数据[2]、调查数据库[1]以及调研数据[3]进行实证分析。然而,统计数据虽然具有可靠性较高的优点,但滞后期一般为2-3年,调研数据则较少进行追踪调查。由于难以获取更多有效数据,导致政府、学术机构等难以全面、科学评价中国乡村振兴发展水平。
随着国家大数据战略推进,大数据技术更加成熟,正加速成为创造价值、发掘潜力的驱动力,其应用逐渐渗透到经济社会的各个微观单元。在农业农村领域,大数据技术在农产品价格监测[4]、农产品流通[5]、农业灾害预警[6]等领域得到广泛应用,但无论在理论上还是实践上,尚未有文献对大数据在乡村发展评价方面的应用进行系统研究。事实上,大数据在乡村振兴发展水平评价中大有可为,这主要得益于乡村大数据的沉淀。大数据技术不仅可以用于数据采集,同时还可以在分析、处理和展示数据方面发挥独特优势,为全方位、多维度、立体化刻画乡村发展面貌,评价中国乡村振兴发展水平提供技术支撑,也为解决中国农业农村问题提供新的方案。本文以从互联网爬取的乡村称号数据为例,对大数据在中国乡村振兴评价中的应用进行探索,为乡村振兴评价领域中使用新数据、新模型、新技术提供参考,同时也给出大数据在解决经济社会问题时的具体使用方法。
相比已有研究,本文主要在四个方面进行创新。第一,本文创新性地使用非传统数据源,为评价乡村振兴发展水平提供更多维度。第二,本文提出非传统数据的采集和处理方法,为规范使用大数据源提供模板。第三,本文应用非结构化和半结构化数据的量化方法,解决了大数据中数据量化难的问题。第四,本文结合使用传统分析方法和新型分析方法,挖掘出更多有效信息。总体来看,本文在数据源选择、数据处理、数据计算和数据展示的全流程都体现了大数据思维,在实际操作中,使用爬虫技术、分词技术、大数据匹配技术和可视化技术等信息技术手段,具有一定创新性。
二、大数据优化乡村振兴发展水平评价的理论逻辑
(一)大数据技术全生命周期视角下的乡村振兴发展水平评价优化
在农业农村数据量不断增加、大数据技术迅速发展的背景下,本文重新审视如何评价乡村振兴发展水平这一问题。大数据具有“5V”特征,即海量(Volume)、高速(Velocity)、多样(Variety)、真实(Veracity)和低价值密度(Value)。大数据技术是指大数据的应用技术。从大数据的生命周期来看,具体分为大数据采集、大数据预处理、大数据存储和大数据分析等四个阶段。在各个阶段,大数据技术均有助于乡村振兴发展水平评价优化,图1给出了大数据优化乡村振兴发展水平评价的理论逻辑。
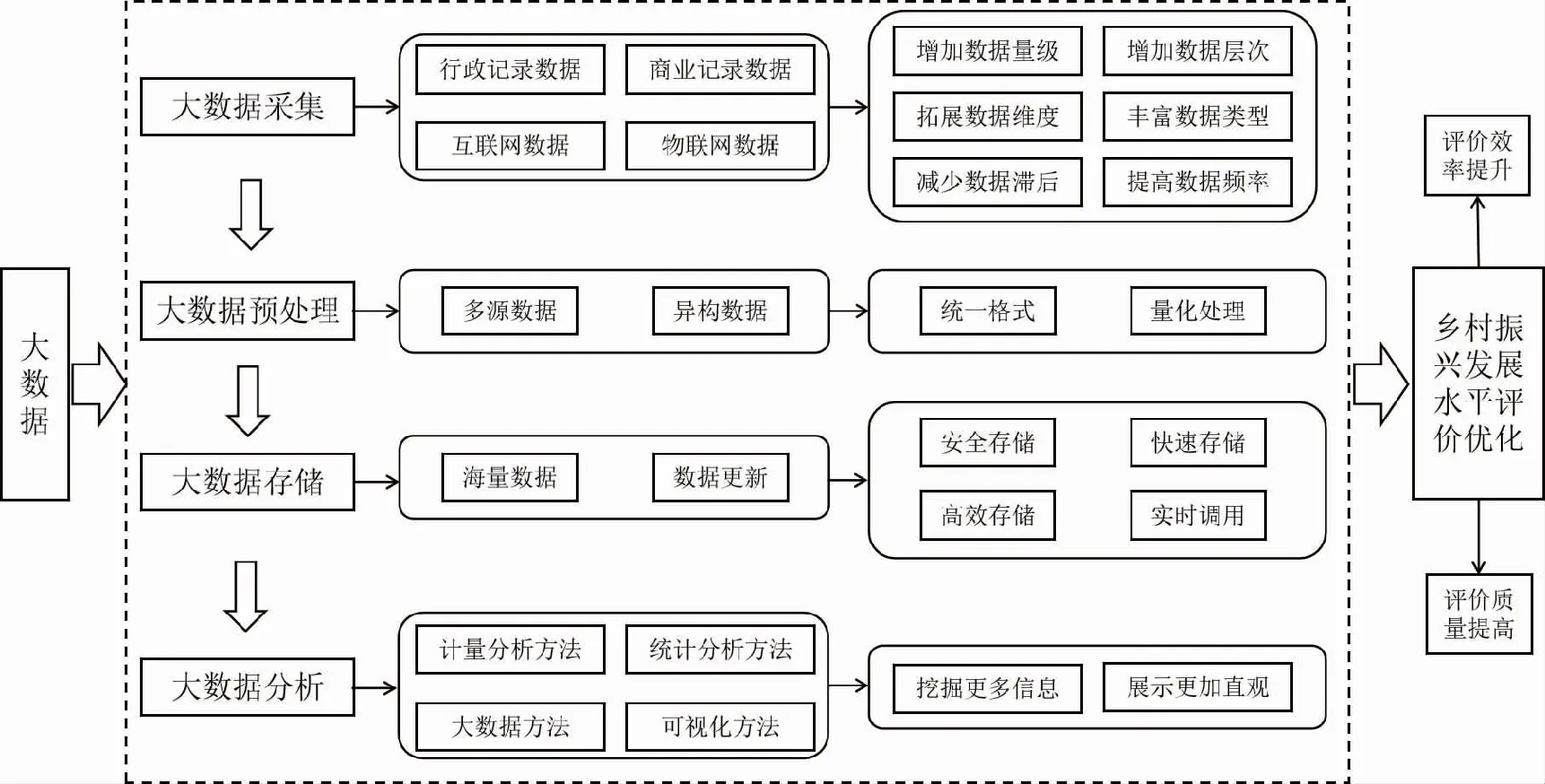
图1 大数据优化乡村振兴发展水平评价的理论逻辑
第一,在大数据采集阶段,大数据技术可以对不同来源的乡村数据进行采集,包括行政记录、商业记录、互联网数据、电子设备传感数据等,这些数据可以统称为非传统数据,不同于统计部门采集的传统数据[7]。使用非传统数据进行分析能够增加数据量级和层次,拓展数据维度,丰富数据类型,减少数据滞后并提高数据频率。第二,在大数据预处理阶段,首先需要对缺失数据、异常数据做处理,将其按照一定方法补全或者剔除。然后,要将多源异构乡村大数据整理成为统一格式数据,并对一些文本型数据做量化处理,将其转换成数值型数据。第三,在大数据存储阶段,要将海量的乡村数据存储在数据库中,且必须保障安全、快速和高效存储。第四,在大数据分析阶段,借助机器学习、深度学习等大数据分析方法对数据进行处理,并使用可视化技术对数据进行展示。
(二)大数据技术助力乡村振兴发展水平评价质量和效率提升
大数据技术通过以上四个阶段,能够优化乡村振兴发展水平评价,主要体现在两个方面。一是质量提升。从本质上看,乡村振兴发展水平评价是一个特征发掘过程,大数据技术优势恰在于此。从广度上看,大数据技术通过对来源广泛的数据进行采集,能够为刻画乡村发展面貌提供更多“原材料”。从深度上看,算法和技术可以为提取数据特征提供更多手段。二是效率优化。大数据技术可以直接采集原始数据,进行快速运算和分析,然后输出结果,能够缩短各个环节所用时间,同时减少人工失误导致的数据偏差,从而提高乡村振兴发展水平评价效率。
三、乡村称号数据概念说明和处理
(一)乡村称号数据概念介绍和数据质量初步评估
在乡村数据采集阶段,要特别关注数据质量问题。在大数据环境下,数据质量问题更加突出,原因来自诸多因素,比如大数据来源多元化、数据总体多变且覆盖不全、数据表现非标准、数据内涵非确定和数据真假难辨等[8]。因此,大数据质量评估要考虑“十性”要求:可得性、相关性、可靠性、有效性、及时性、适用性、准确性、连贯性、可比性和可解释性[7]。
通过梳理文献中涉及的乡村大数据源,本文选定乡村称号数据作为切入点进行研究。乡村称号数据是指由政府部门经过评审并发布的乡村称号名单,如“农业产业强镇”、“中国美丽休闲乡村”等。虽然称号是由政府部门发布,但其具有来源分散、更新速度较快、半结构化或非结构化、文本型数据等特征,因此相关数据属于非传统数据。结合上述数据质量评估标准,本文对称号数据质量进行初步评估,发现其满足有关数据质量的“十性”要求。
(二)乡村称号数据采集和筛选
发布乡村称号的政府部门包括农业部、商务部、生态环境部等。本文分三步对称号数据进行采集和筛选。
第一步,初步搜索称号。首先,在各政府部门网站搜索框中输入“称号”、“试点”、“示范”等关键词,然后对2005—2020年相关目录进行查看,即本文不查询2005年之后没有更新过任何批次的称号(1)这主要是考虑到称号具有时效性,往往随着农业农村政策变化进行更新和调整。在2005年之前发布或更新的称号距离现在太过久远,即使某些村落获得过乡村称号,也很难反映这些村落目前乡村振兴发展情况,因此使用价值较小。。经过人工查找,定位包含称号名单的条目,这些条目的形式一般为“标题+正文+称号名单”。经统计,共获得54个称号。
第二步,筛选有效称号。54个称号并非都适合评价乡村振兴发展水平,需要根据称号政策含义进一步筛选。一是剔除具有扶贫性质的称号。以“农民合作社质量提升整县推进试点”为例,考虑到该称号名单中包含很多仍处于贫困状态的县级行政单位,不能很好地代表乡村振兴发展水平,因此,对这类称号进行剔除处理。二是剔除具有明显地域偏差的称号。地域偏差是指由于不同地域适合发展的农业产业不同,因此不宜将与某类产业相关的称号纳入乡村振兴评价体系。三是剔除对象数量过少的称号。如“农业重大技术协同推广计划试点”仅在2018年公布过8个试点,数量太少,不宜纳入评价体系。在对所有称号进行筛选后,本文得到29个有效称号。此外,在搜索引擎中直接搜索“农村称号”,还得到中国文明网、人民网、中国生态文化协会等官方媒体和协会评选出的3个称号。由于“淘宝村”称号能够体现农村电子商务产业的发展情况,因此本文也将其纳入到有效称号列表中。最终,本文得到33个有效称号共128个批次的名单。
第三步,采集称号数据。在获取33个称号各批次名单的原始链接后,从网站爬取数据,大部分为网页数据,少部分页面提供文件下载链接,文件格式包括WORD、EXCEL、PDF、CEB等多种类型,数据基本上是半结构化数据。本文使用爬虫技术手段获取全部名单数据。
(三)乡村称号数据预处理
在大数据预处理阶段,本文关注多源异构数据的整合问题。33个称号数据的格式和结构不统一,甚至同一称号不同批次的数据格式和结构也不同。由于农村称号对象大部分是行政单位,因此,本文分三步对农村称号数据进行预处理。
第一步,提取称号对象中的行政单位名称。大部分称号格式为“X省X市X县X乡镇X村”,县级称号格式为“X省X市X县”,乡镇级称号格式类似。本文对128个批次名单数据中所有行政单位名称进行提取。
第二步,按照行政级别对原始数据进行处理。对于原始数据中各级行政单位信息都完整的称号,可以直接使用分词技术将“X省X市X县X乡镇X村”中各个行政单位分开,如表1所示,以“全国民主法治示范村”和“淘宝村”两个称号为例,将称号对象按照省、市、县、乡、村五级行政区划进行处理和存储。对于原始数据中各级行政单位信息不完全的称号,首先需要从国家统计局网站的统计用区划和城乡划分代码页面爬取全国所有地区的行政区划层级和代码,然后将称号中所含的行政区划信息与统计局行政区划信息进行大数据匹配,补全缺失信息,补全结果也同表1样例按照五级行政区划存储。对于称号对象为非行政区划的称号,如“全国主食加工示范企业”,本文将企业名单与国家企业信用信息公示系统进行匹配,获得企业注册地址,并按以上步骤重复处理过程。最终获取128个批次名单的47 381个对象。

表1 乡村称号数据处理结果样例
第三步,根据本文需要对数据进行量化处理。经过前两步,本文已经将多种格式、多种类型的数据整理成为统一格式数据,但这类文本型数据无法与指标体系结合,同时,不同称号的对象有差异,称号对象既包含行政区划,又包含企业、园区等,相互之间不可比,因此需要进行量化处理。本文以省级乡村振兴发展水平评价为例,首先分别对各个称号在省级层面进行数量统计。考虑到不同省份的村、乡镇、区县数量差异较大,因此不能直接使用绝对数量,需要将其转换成比例数据,转换过程需要考虑称号对象的行政区划层级。当称号对象行政区划层级十分清晰,为县级或村级时,使用各省份县级或村级行政单位的数量作为除数,对绝对数量结果进行处理;当称号对象包含不同的行政区划时,如“全国一村一品示范村镇”称号对象同时包含村和镇,此时需要选用较高层级的行政区划数量,即各省份镇的数量作为除数;对于基地、企业等只能细分到县级的称号,使用县级行政单位数量作为除数;除以上三种情况外,如果对象为园区、优势区、企业等称号,使用村级行政单位数量作为除数。
四、基于称号数据的乡村振兴发展水平评价
(一)模型构建
目前对乡村振兴进行评价的主要方法是构建指标体系。指标体系是最为经典的一种评价方法,本文也使用指标体系对乡村振兴发展水平进行评价。由于标签模型具有框架设定更为自由、标签数据类型更加多样等优势,本文考虑使用信息领域“数据画像”中的标签技术,将指标体系拓展为标签体系,对乡村振兴发展情况进行可视化展示。
1.指标体系构建
本文选取2020年为评价年度,利用33个称号来构建指标体系。根据乡村振兴战略“二十字”方针要求,将一级指标确定为产业兴旺、生态宜居、乡风文明、治理有效和生活富裕,然后将33个称号作为底层指标,将称号按其含义分配到所属的一级指标中,如表2所示。

表2 基于称号的乡村振兴指标体系
2.标签模型构建
标签体系是一种灵活、多维和适合大数据系统的模型体系。在信息技术领域,标签技术通常被用在“用户画像”领域,即通过为事物打上不同的标签来描述和刻画用户特征。本文创新性地将画像技术的核心——标签技术应用到乡村振兴的评价领域,为评价乡村振兴发展水平提供了更多技术工具和展示方法。
本文将与乡村称号相关的标签分为三类。第一类,事实标签。标签名称与称号名称相同,标签值是经过标准化处理的原始数据。事实标签可以对底层指标数据进行展示。第二类,模型标签。模型标签是指经过模型计算得到具体标签值的标签。本文模型是指标体系,经过指标体系处理,可以计算各省份的总指数值、5个一级指标值和33个二级指标值,然后分别对各省份总指数值、一级指标值和二级指标值进行排名,最后给各省份打上标签。例如,假设山西省“国家农业科技园”二级指标值在各省份中排名第8,可以打上“国家农业科技园排名第八”的标签。第三类,预测标签。预测标签是指基于多年数据进行预测的标签。可以将获取的乡村称号微观数据按照年度进行累计计算,得到连续多年数据,在此基础上进行预测标签值的计算。例如,假设2019年山东省“乡风文明”一级指标值排名第6,2020年排名第4,可以打上“山东省乡风文明2020年上升2位,有上升趋势”的标签。
(二)实证分析
1.指标体系结果分析
熵权法是一种客观赋权方法,能够避免人为因素的干扰。因此,本文选用熵权法计算指标权重。同时,本文使用机器学习中的聚类分析方法,将31个省份(不包括港澳台)聚为3类,如图2所示,纵坐标为乡村振兴总指数值。
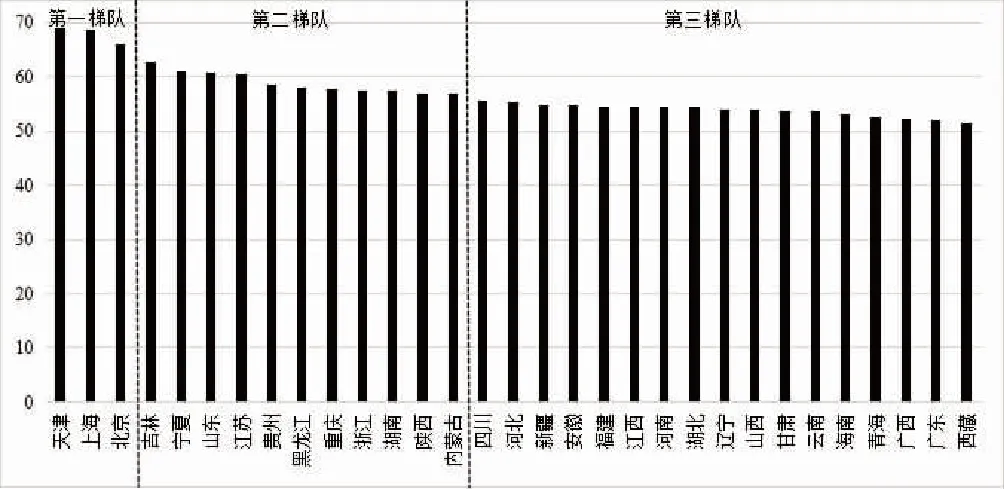
图2 中国省级乡村振兴指数聚类图
天津、上海和北京三地名列前茅,属于第一梯队,吉林、宁夏等11个省份属于第二梯队,四川、河北等17个省份属于第三梯队。可以看出,乡村振兴指数与东中西部地理位置的关联性较弱。虽然东部沿海省份总体发展水平明显高于大部分中部省份和西部省份,但宁夏、贵州、重庆等西部省份的总指数值较高,出现在前十名,这与以往的研究结果差异较大。因此,使用新型数据可以从更多维度对乡村振兴发展水平进行刻画,有助于更加全面地了解乡村发展情况。
2.标签模型展示
各省份都可以使用标签技术对事实标签、模型标签和预测标签进行展示。本文以北京市和四川省为例,使用词云图展示事实标签,如图3所示。
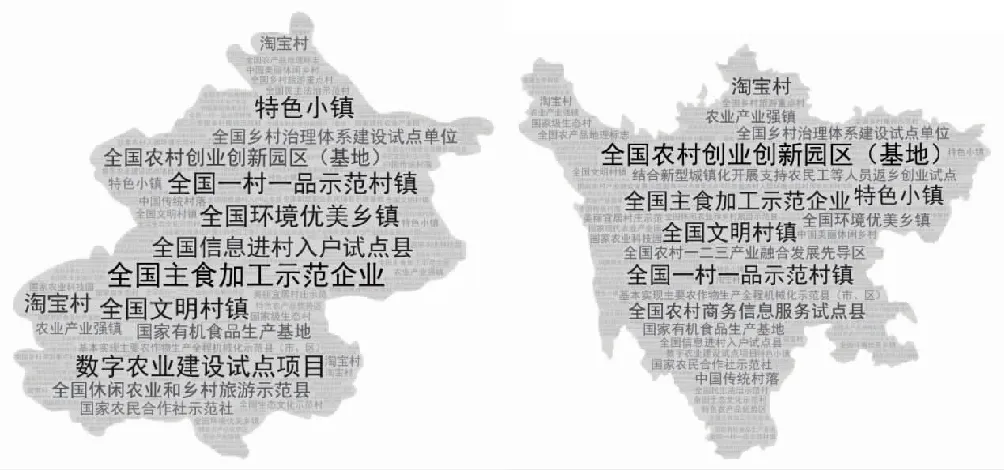
图3 北京市和四川省乡村振兴事实标签词云图
从北京市词云图可以看出,“全国主食加工示范企业”标签最为显著,这与北京市市场经济发达,适合企业发展的大环境相关,此外,“全国文明村镇”、“全国环境优美乡镇”、“数字农业建设项目试点”等多个标签也较为突出,说明北京市在乡村振兴发展的多个方面具有独特优势。四川省的“全国农村创业创新园区(基地)”和“淘宝村”标签比较突出,说明四川省作为西部省份,其农业农村发展出现了新的动向,如推动农业技术创新、发展农村电子商务等,这些变化有助于缩小东西部乡村发展差距。关于模型标签和预测标签,理想状态是使用算法并编写程序,将计算过程和结果输出等步骤标准化、流程化,本文在此不做展示。
五、进一步探讨
统计数据和大数据的结合使用是政府统计工作的未来趋势,本文使用称号数据作为切入点进行研究。随着各级政府数据资源共享和开放工作进程的推进,大量乡村数据资源被集合起来,在此基础上,政府部门可以对统计数据和大数据进行拼接,基于多维数据进行数据分析。使用大数据要注意四点事项:一是警惕“数据陷阱”,防止出现由于过度挖掘导致的过度拟合现象。二是警惕有偏的大数据,即数据量够大,但代表性不足的大数据,使用这类数据进行分析的结果往往远离事实。在实际工作中,需要先对相关大数据源进行人工筛查,确保其代表性、相关性和可靠性。三是要重视对“小数据”研究。根据数据含义、数据类型等将“大数据”拆解为“小数据”,对各个“小数据”内部情况进行详细研究,解决好每个“小数据”内部数据质量问题。四是利用统计思维处理大数据。大数据应用不是将大数据扔进一个“黑盒子”中等待结果输出,而是需要结合统计方法的人工全程参与。大数据方法与传统统计方法并不冲突。未来,随着大数据技术的进一步发展,大数据分析和预测结果将成为政府部门作出决策的重要参考和依据,积极运用大数据技术和提高工作人员大数据素养将成为影响政府治理水平和服务能力的重要因素。□
