Capturing semantic features to improve Chinese event detection
2022-05-28XiaoboMaYongbinLiuChunpingOuyang
Xiaobo Ma|Yongbin Liu|Chunping Ouyang,2
1School of Computing,University of South China,Hengyang,China
2Hunan provincial base for scientific and technological innovation cooperation,Hunan,China
Abstract Current Chinese event detection methods commonly use word embedding to capture semantic representation,but these methods find it difficult to capture the dependence relationship between the trigger words and other words in the same sentence.Based on the simple evaluation,it is known that a dependency parser can effectively capture dependency relationships and improve the accuracy of event categorisation.This study proposes a novel architecture that models a hybrid representation to summarise semantic and structural information from both characters and words.This model can capture rich semantic features for the event detection task by incorporating the semantic representation generated from the dependency parser.The authors evaluate different models on kbp 2017 corpus.The experimental results show that the proposed method can significantly improve performance in Chinese event detection.
KEYWORDS dependency parser,event detection,hybrid representation learning,semantic feature
1|INTRODUCTION
Event Detection (ED) is a key step in event extraction which aims to recognise event instances of a particular type in plain text.Specifically,given a sentence,ED is required to decide whether the sentence contains event triggers,and if so,it needs to identify the specificeventtype.For example,in the sentence‘He boughta plane ticket and arrived in Sydney on November 17th’,an event detection system will detect a ‘transaction’ event triggered by‘bought’,and a‘movement’event triggered by‘arrived’.
Chinese event extraction has had progress recently.To date,many methods [1-3] have been proposed and have obtained state-of-the-art performance.However,the existing event extraction methods find it challenging to capture sufficient semantic information from plain text,because a word may have different meanings in different sentences.For example,in Table 1 S1 is a sentence in which the word‘下课’is equivalent to resign,but in S2,the same word‘下课’is used to express the meaning that the class is over.Also,the wordtrigger mismatch problem still exists,because triggers do not exactly match with a word.In Table 1 in S3,the event should be triggered by ‘落入法网’ which is a cross-word trigger.Because the word segmentation tool divides ‘落入法网’ into‘落入’and ‘法网’ that makes it impossible to extract the complete trigger.In S4,there is more than one trigger in the word ‘击毙’ (shoot and kill).A ‘shoot’ event triggered by ‘击’and a ‘kill’ event triggered by ‘毙’.These triggers are called inside-word triggers.
To improve event detection quality,previous methods often captured additional information,such as syntactic features.The dependency parser is an effective way to capture syntactic features.Using the dependency parser,a sentence can be labelled with structured information that contains a dependency relation.An arc represents a dependency relation that connects a dependency word to a headword in a sentence.For example,in Figure 1,an arc represents a dependency relation (dobj) that connects the dependency word‘合并’(merger)to the headword‘公司’ (company).The dependency relation provides rich semantic features for models and performs reasonably well.For example,in Figure 1,‘合并’(merger)is a trigger word.From thedependency relation between ‘合并’ (merger) and its entities‘公司’(company)we can exploit its entities to assist the classification of the trigger and discern the event type of‘Merge-Org’.These related entities called cue words can provide available information to assist the trigger classification.However,with traditional word embedding it is difficult to take full advantage of these cue words because they are scattered in a sentence.Therefore,we connect cue words to trigger comments by adding dependency relations.In most cases,these additional features can provide helpful information.

TABLE 1 Examples of word polysemy and word-trigger mismatch

FIGURE 1 Example of a Merge‐Org event triggered by ‘合并’ (merger)
With this objective,we propose a hybrid representation method to learn information from words,chars,and dependency relations.More concretely,we first learn two separate characterlevel and word-level representations using token-level neural networks.Then,we obtain the dependency information from the dependency parser and generate its representation by One-Hot Encoding.Our analysis proves that the feature generated from the dependency parser are beneficial for event detection.Finally,we design appropriate hybrid paradigms to capture the hybrid representation.Our model achieved the micro-averaged F1 scores of 59.86 and 53.44,respectively,for trigger identification and trigger classification.
2|METHODOLOGY
Our model can be divided into two stages which process hybrid representation via dynamic multi-pooling convolutional neural networks.The first stage is trigger identification,where we use a neural network to capture the potential trigger nuggets containing the concerning character by exploiting the triggers' character compositional structures.The second stage is used to determine the event's specific type,given the potential trigger nuggets.This is called trigger type classification.We use the dependency information extract from a dependency parser to generate a feature representation via tokenlevel neural networks in these two stages.Then,we combine it with the word feature representation and obtain a hybrid representation.
Figure 2 depicts the architecture of our event detection approach,which involves the following four components:(a)representation of the input sequence;(b)feature representation based on the dependency parser;(c)hybrid representation;and(d) dynamic multi-polling convolutional neural network.
2.1|Representation of the input sequence
To better capture information on different levels,we propose using two levels of embedding,namely,word level embedding and character level embedding.To further enhance performance,we use pre-trained weights to initialise the embedding.Then,a two token-level neural network is used to obtain features from characters and words.The network architecture is similar to NPNs [4].LetT=t1,t2,…,tnbe tokens in the sentence wheretiis theith token.Then,letxibe the concatenation of the embedding (word or character) oftiand theti’s relative position totc,a convolutional layer with the window size assis introduced to capture compositional semantics as follows:
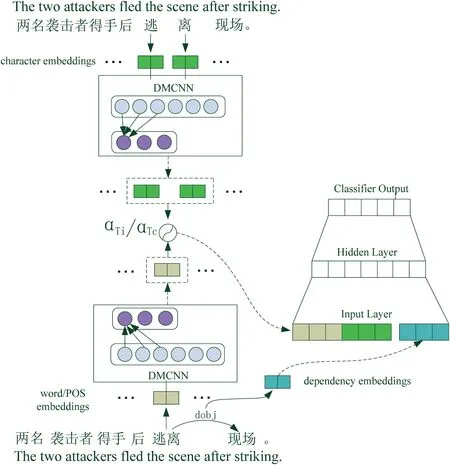
FIGURE 2 Architecture of event detection,where αTi and αTc are the gates described in Section 2.3
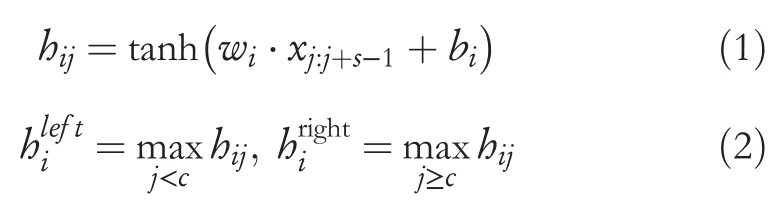
Equation(1)shows the convolutional process,wherewiis theith filter of the convolutional layer,xi:i+jis the concatenation of embeddings fromxjtohj+s-1,andbiis a bias.Equation (2) gives the important signals of different parts of the sentence by using dynamic multi-pooling whererefers to the pooling result of the left oftc,andrefers to the pooling result of the right oftc.Then,we concatenateandto obtain the word-level representationfwordoftc.By using the same procedure on character-level sequences,we can also obtain the character-level representationfchar.
2.2|Feature representation based on the dependency parser
The dependency parser is the focus on most works in dependency grammar that are based on the dependency relation.Syntactic dependencies can be used to obtain deep semantic information.Syntactic dependencies are used in the neural network model by directly incorporating them into embedding.In this work,we use three different feature abstraction layers to represent three features:
· POS:part of speech
· DR:dependency relation
· DIS:distance from the HEAD
These three features are based on the results of the dependency parser.Dependency parsing for training was done with the Stanford Neutral Network dependency parser [5].
POS is a generalisation of the word which plays an important role in natural languages processing tasks such as named syntactic analysis,entity recognition and event extraction.A noun or pronoun can act as a subject in a sentence,but an interjection cannot.This is because the grammatical component has a restriction on the speech component.Therefore,POS is applicable as an abstract feature to express different characteristics of text semantic information.We take POS as a feature to reinforce word-based features.There are 28 parts of speech in Chinese,we use a 28-dimensional one hot vector to represent the parts of speech.It means that the POS of each word in a sentence can be represented as a 28-dimensional feature vector.Each dimension of the 28-dimensional vector represents a part of speech.The POS of a word is expressed if one of the values is 1,and the remaining 27-dimensional values are 0.
Dependency relation expresses the semantic relationships between the components of the sentence.For the event extraction task,trigger words usually are the predicate verbs.We find that,in the KBP corpus,the most popular dependent grammatical role of the trigger words is HEAD that accounts for 56%,and the role of the verb object accounts for 19%.Therefore,we consider that a dependency relation is available to improve trigger detection.On the feature layer of the dependency relation,the vector dimension is 18 (17 relationship types and one ‘other’ type).We find that 17 kinds of the dependency relation are frequently used in syntactic dependencies,and in order to reduce the complexity of feature representation,we classify the other dependency relation as the‘other’type.
The distance from the HEAD is the length of the dependency path.Concretely,if a word and HEAD are directly related,we say that the distance of the HEAD is 1.If the path includes one intermediate dependency,the distance of the HEAD is 2.For example,in the sentence of Figure 1,‘宣布’(announced)is the HEAD,and the dependency path of‘公司’(company) are as follows:
宣布c→comp合并→dobj公司
Here,‘宣布’ (announced) is the HEAD in this sentence,‘合并’ (merger) creates an intermediate dependency between the HEAD and ‘公司’ (company).Therefore,for the word‘公司’(company),its distance from the HEAD is 2.HEAD is the root node in syntactic dependencies that usually represent the core word in a sentence.Triggers represent the important content in events.Based on the analysis of the trigger in the KBP corpus,we find that HEAD and trigger words are similar.It means that the distance from the HEAD can be used to measure whether a word is a trigger in a certain sense.On the feature layer of DIS,we use a seven-dimensional vector to represent the distance from 0 to 6.In addition,if it is greater than 6,we still identify its value as 6.
2.3|Hybrid representation learning
For Chinese event detection,only employing word-level representation or character-level representation cannot obtain sufficient information.Because characters reveal the inner compositional structure of event triggers [6],while words can provide more accurate and less ambiguous semantics than characters [7].For example,if we understand the word ‘逃离’(flee) in a character-level representation,it is a trigger consisting of ‘逃’ (escape) and ‘离’ (leave).While in a word-level representation,the word-level sequences can provide more explicit information to distinguish the semantics of‘离’(leave)in this context with the character in other words like ‘离婚’(divorce).
After the embedding layer,we can obtain a word-level feature representationfword,a character-level representationfcharand a feature representationIn this work,we exploit a paradigm of Task-specific Hybrid [4] to combine these representations.Specifically,we first learn two gates to model the information flow for the trigger identification and event type classifier:sis the sigmoid function,andare the weight matrices,andbis the bias term.

Based on the three feature layers in 2.2,we obtain three features representation.Then,we construct a 53-dimensional vectorby concatenating these three feature representations.Finally,we obtain the concatenation of the feature and word as a new representation:
According to the gates which are introduced to trigger the nugget generator and the event type classifier,we can obtain the final vector as the input:
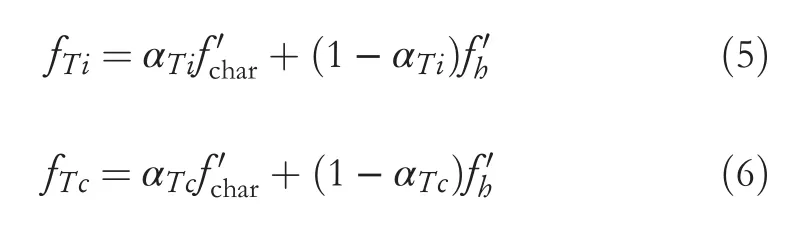
wherefTiis the hybrid feature for the trigger identification andfTcis the hybrid feature for the event type classifier.αTiand (1 -αTi),respectively,represent the importance ofandin trigger identification.αTcplays a similar role in event type classifiers.
2.4|Dynamic multi‐pooling convolutional neural networks
Traditional convolutional neural networks use only one pooling layer,which implements a max operation.It means that traditional convolutional neural networks only capture the most important information in the representation of a sentence.In event extraction,one sentence may contain two or more events,and an argument may play a different role with a different trigger.However,traditional convolutional neural networks capture the most useful information of an entire sentence and will lose other important information in the same sentence.To address this problem,Chen et al.[8] propose a dynamic multi-pooling convolutional neural network(DMCNN)that can obtain more valuable information without losing the max-pooling value.
In this study,the neural network that we used is similar to the DMCNN.We now describe the neural network for this study.Figure 3 describes the architecture of trigger identification.
First,the concatenation of the embedding and the relative positionxiis obtained.We concatenatexito the feature vector,which we have explained in Section 2.2,resulting in the lexicallevel features.
Next,the lexical-level features are given as input to the convolution layer to capture the compositional semantics and obtain feature maps.Concretely,a convolution operation produces a new feature by exploiting a filter(also called kernel)to scan a window ofhwords.Letxi:i+jrefer to the concatenation of wordsxi,xi+1,…,xi+j.Filters are applied to a window ofhwords in the sentencex1:h,x2:h+1,…,xn-h+1:nto produce a feature mapciwhere the indexiranges from 1 ton‐h+1.In our case,one filter produces one feature for one positioni:cij=σ(wj·xi:i+h-1+bias)whereσis a nonlinearity (tanh in our case),jranges from 1 tom,m is the number of filters.
Then,the feature map outputcjis divided intoisections according to the number of triggers in a sentence.For example,if one sentence has one trigger then the sentence will be divided into two sections,and when this sentence has two triggers,these two triggers will divide the sentence into three sections.Through dynamic multi-pooling,the final output of one filter is given bypji=max(cji)to obtainpjifor each feature map and allpjiare concatenated to form a vector P.
We concatenate the feature vectors above and the lexical feature into a single vectorFword.We adopt a similar method to obtain the char-level feature vectorFchar.Finally,we use hybrid representation learning which is expressed in Section 2.3 to produce two hybrid representations for the dense layer of trigger identification and trigger type classification.
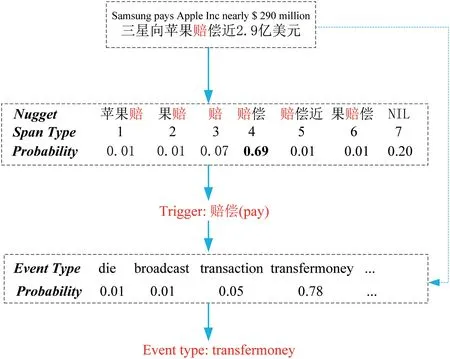
FIGURE 3 Example of trigger identification and trigger type classification.‘NIL’ means this character is not in any trigger
2.5|Training and classification
Following previous works,we consider event identification as a multi-class classification problem.The hybrid representationfN,which is learned from the architecture described in Section 2.3,is the input of convolutional neural networks.The input is a tokenised sentence.We also use the dropout layer[9]to prevent over-fitting.
Then,convolution layers are used to capture semantics and generate feature maps by filters.Traditional convolutional neural networks usually get one max value for a feature map by taking one feature map as a pool.In our case,we use dynamic multi-pooling to get a multi max value by splitting each feature map into multiple parts.By concatenating the sentence-level and lexical feature,we get a single vector F and it is fed into a classifier.The process of getting the final output can be expressed as follows:
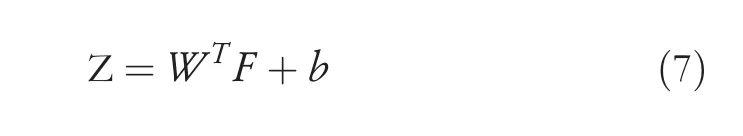
WTis the transformation matrix,bis a bias term andZis the final output of the network.
Finally,we use the softmax activation function to predict each type's probabilistic score,then pick the highest probability as the final result.We use two different classifiers to predict the span type in trigger detection and the event type in trigger type classification.In Figure 3,we give an example to show how classifiers get a trigger word and predict the event type.When the classifiers took a character as the potential trigger or potential trigger,one classifier extracts the best match in different possible trigger words containing this character.Then,another classifier will predict the event type triggered by this trigger.
3|EXPERIMENTS
3.1|Dataset and evaluation metric
We evaluate the networks in this study using the TAC KBP 2017 Event Nugget Detection Evaluation dataset [10] that is widely used for ED.In the evaluation corpora,there are 693 documents in which half of the documents are newswire and the other half of the documents are texts from the discussion forum.Table 2 shows the number of each event type in the corpora.We used the Stanford CoreNLP toolkit [11] to preprocess all documents for sentence splitting and word segmentation.The grammar analysis tools adopted the Stanford Neutral Network dependency parser.
Similar to[1,4,12,13],we used the same training set with 506 documents,the same development set with 20 documents and the rest 167 documents were used for testing.
We follow standard evaluation procedures:A trigger is correct if its event subtype and offsets match those of a reference trigger.Finally,we used precision (P),recall (R) and the F-measure (F) to evaluate the results.

TABLE 2 Number of nugget per event type
3.2|Experimental setting
For training the classifier,we divide the train set into positive instances and negative instances.A character included in trigger words is considered a positive instance,otherwise the character is considered a negative instance.In our case,we set the ratio of positive instances to negative instances to 1:20.In order to efficiently train neural networks,we limit the maximum sentence length of 220 in the character-level representation,and also limit the maximum sentence length of 130 in the word-level representation.The word embedding dimension and char embedding dimension are 100.For the activation function of the convolutional neural network,we use the same sigmoid function as the DMCNN[8].For evaluation,we limit the length of the triggers of 3.Because most of the triggers in the labelled corpus are not longer than 3.Besides,we set the batch size as 128.The dropout rate was set to 0.5.The parameters were initialised with a uniform distribution between-0.1 and 0.1.
3.3|Experiments and results
For our method,we use the pre-trained word embedding,respectively,learned by Skip-Gram and BERT.We select five state-of-the-art methods for comparison:
FBRNN:Ghaeimi et al.[1] used forward-backward recurrent neural networks to detect events that can be either words or phrases.This method is one of the first efforts to handle multi-word events and also the first attempt to use RNNs for event detection.
DMCNN:Chen et al.[8] proposed a dynamic multipooling convolutional neural network that uses a dynamic multi-pooling layer according to event triggers and arguments.This event extraction method aims to automatically extract lexical-level and sentence-level features without using complicated NLP tools.
CLIZH (KBP2017 Best):Makarov and Clematide [13]incorporated many heuristic features into the LSTM encoder,which achieved the best performance in TAC KBP2017 evaluation.
NPN (Task-specific):Lin et al.[4] proposed Nugget Proposal Networks for Chinese event detection which using hybrid representation to capture features,and designed three kinds of hybrid paradigms(Concat,General and Task-specific)to obtain the hybrid representation.In our study,we use the result of Taskspecific as a baseline to compare with our method.
JMCEE:Xu et al.[14]proposed a Chinese multiple events extraction framework that adopts a pre-trained BERT encoder and utilises multiple sets of binary classifiers to determine the spans to complete event extraction.
As we can see in Table 3,our method has a competitive precision and recall in the task of trigger identification,resulting in the highest micro-averaged F1.Compared with the best result,our model achieves 0.49%and 1.1%improvements in terms of micro-averaged F1,respectively.In the task of trigger identification,our method achieves the best performance in both precision and micro-averaged F1.Specific to the recall value,our model performs worse than JMCEE,but we achieve a great improvement on precision than the baseline and get a higher micro-averaged F1.This shows that our model does not improve the precision by sacrificing the recall.
The result shown in Table 3 also shows that employing the dependency parser can achieve better precision.We believe this is because the dependency parser can capture rich relational information and different complementary information to assist trigger detection.What's more,the performance is better when BERT is used as the pre-training model of our model to initialise the parameters.This is due to the effective architecture and the large-scale pre-training information of BERT.
3.4|Ablation study
In order to illustrate the effectiveness of various parts of our model,we conduct ablation experiments on the kbp2017 Corpus.We first compared with the model removing dependency features (Char and Word Emb).Then,on the basis of removing the dependency features,we separately remove the word-level feature(Char Emb)and character-level features(Word Emb).

TABLE 3 Experiment results on TAC KBP 2017 dataset
According to the results presented in Table 4,we can see that neither the character-level model (Char Emb) nor the word-level model(Word Emb)can achieve competitive results.It is possible to incorporate character-level features and wordlevel features,which is beneficial to capture the trigger's integrity.Furthermore,it can be observed that dependency features,which could take advantage of event information scattered in the sentence,help trigger identification and trigger classification.
3.5|Influence of mismatch triggers and polysemous triggers
In order to explore the influence of mismatch triggers and polysemous triggers,we counted the mismatch triggers and polysemous triggers on the KBP2017 dataset.First,we split triggers into two parts:match and mismatch.Then,based on the polysemy of triggers,we split triggers into two parts:polysemy and univocal.Table 5 shows the statistics of the mismatch trigger and polysemous trigger on the KBP2017 dataset.
Based on the ablation study,we further analysed the influence of our model on trigger mismatch and polysemy.Table 6 shows the F1 score of different types of word-trigger match on the trigger identification task.Compared with the model that only considers the word feature or character feature,our method achieves better performance regardless of whether the triggers are mismatched or not.The word-based model only gets 22.77% F1 score because mismatch triggers are difficult to be separated as a specific word in the preprocessing stage.
To further explore the effect of the character,word and dependency feature,we split the KBP2017 test set into two parts:polysemy and univocal.The F1 score of each part is shown in Table 6,in which our method achieves the best results on both the polysemy part and the univocal part.Without the dependency feature,the performance of the method drops by 2.55% in the polysemy part.The results indicate that theseadditional information can alleviate some of the misclassification of the triggers caused by polysemy.In contrast,wordbased or char-based model does not get enough semantic information,thus has a low result.
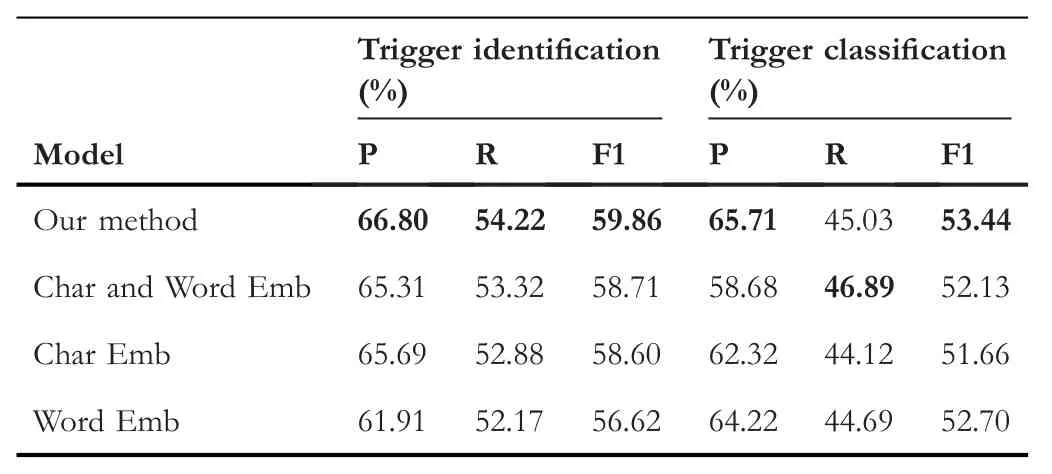
TABLE 4 Ablation study for our method

TABLE 5 Proportion of the mismatch triggers and polysemous triggers on KBP 2017
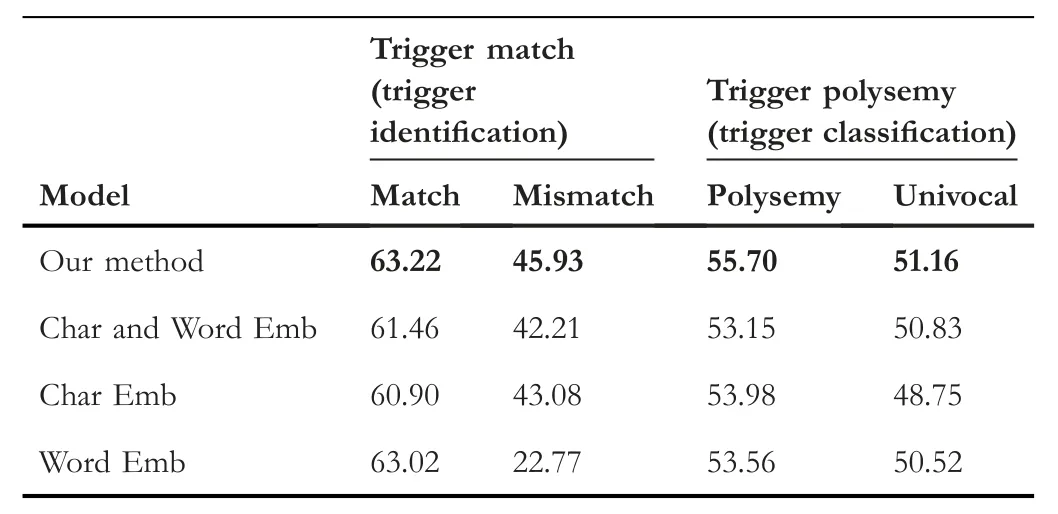
TABLE 6 F1 score of mismatch trigger on trigger identification task.And F1 score of polysemous trigger on trigger classification
4|RELATED WORK
4.1|Feature engineering method
Event detection is a supervised multi-class classification task that can be divided into two steps:feature selection and classification model.For event detection tasks,traditional classification models are mostly maximum entropy models or support vector machines.Chieu and Ng [15] first presented a maximum entropy approach to extract information on a dataset with better performance than the past work that used pattern-learning methods.Ahn [16] used a modular approach based on lexical features,syntactic features,and external knowledge features to complete an event extraction task on an ACE English corpus.
In follow-up studies,the researchers proposed more advanced features for event detection.Ji and Grishman [17]proposed a cross-document feature that extracts multiple results from a set of related documents.This approach achieves the propagation of event arguments in sentences and documents.Inspired by the hypothesis of ‘early-update’,a joint framework to extract events is proposed in [18,19].Although these approaches have a high performance,the traditional classification model suffers as it is heavily dependent on feature selection.
These methods are based on feature engineering.The feature extraction is usually a pre-order module of the prediction model in the ways.Principal component analysis or linear discriminant analysis is generally used for feature extraction.The prediction model performs the classification task on the feature extraction results.
4.2|Deep learning method
In recent years,deep learning is widely used in event detection tasks based on structured prediction.We report studies on event extraction with neural networks.Nguyen and Grishman [20] exploit convolutional neural networks to achieve the modelling of non-continuous skip-grams [21]and overcome the problem of complicated feature engineering.These methods achieve high performance in event detection.But the issue of data scarcity limits their improvement and performance.Chen et al.[22] propose an automatic label method for event extraction by detecting triggers and arguments for each event type.Liu et al.[2]leverage supervised attention mechanisms to model argument information for event detection.
Recently,the researcher proposed some novel models to solve a different problem in event extraction related to our work.Zhang et al.[23] transformed the event recognition problem into semantic feature classification and proposed a deep belief network model to identify the triggers.Chen et al.[8] proposed a dynamic multi-pool convolutional neural network to capture the sentence-level information for event extraction.Lin et al.[4] proposed a hybrid representation model to solve the problem of word-trigger mismatch.Tong et al.[24,25] proposed a novel Enrichment Knowledge Distillation (EKD) model to solve the problem of the long tail.
These methods,based on the neural network,are essentially representation learning methods.The difficulty of these methods is the evaluation of the contribution or influence of representation learning on the final output of the system.With these methods,it is difficult to capture the dependence relationship between trigger words and other words in the same sentence.This study used the dependency parser that effectively captures dependency relationships and improves the accuracy of event categorisation.
5|CONCLUSION
This study proposes an effective Chinese event detection model.Due to the Chinese language's nature,the Chinese tokens usually contain more internal structures,and every single character in the token may convey helpful semantic information.Our method uses the hybrid representation to capture features both in the word-level and character-level and concatenates token features with semantic features generated from the dependency parser.Besides,we use a dynamic multi-pooling convolutional neural network to store more useful information in the same sentence.The experimental results prove that the dependency parser can capture more valuable features,which improves our method's performance in event detection tasks.
ACKNOWLEDGEMENTS
This work is supported by 973 Program(No.2014CB340504),the State Key Program of National Natural Science of China(No.61533018),National Natural Science Foundation of China (No.61402220),the Philosophy and Social Science Foundation of Hunan Province (No.16YBA323),Natural Science Foundation of Hunan Province (No.2020JJ4525) and the Scientific Research Fund of Hunan Provincial Education Department (Nos.18B279 and 19A439).
CONFLICT OF INTERESTS
The authors declare no conflict of interests.
DATA AVAILABILITY STATEMENT
Data available on request from the authors.
ORCID
Yongbin Liuhttps://orcid.org/0000-0002-3369-3101
猜你喜欢
杂志排行

CAAI Transactions on Intelligence Technology的其它文章
- Matrix‐based method for solving decision domains of neighbourhood multigranulation decision‐theoretic rough sets
- Feature extraction of partial discharge in low‐temperature composite insulation based on VMD‐MSE‐IF
- Wavelet method optimised by ant colony algorithm used for extracting stable and unstable signals in intelligent substations
- Efficient computation of Hash Hirschberg protein alignment utilizing hyper threading multi‐core sharing technology
- Improving sentence simplification model with ordered neurons network
- Demand side management for solving environment constrained economic dispatch of a microgrid system using hybrid MGWOSCACSA algorithm