基于无监督深度学习的电子健康档案数据挖掘技术研究进展*
2022-05-27顾耀文
顾耀文 李 姣
(中国医学科学院/北京协和医学院医学信息研究所 北京 100020)
1 引言
电子健康档案(Electronic Health Record, EHR)是一种用于收集、存储和提供个体健康记录的纵向医疗保健电子数据。通常包括人口统计、检查结果、疾病诊断、临床护理、用药管理、付款和保险等信息[1]。近年来各国加大对EHR建设工作的投入[2-3],EHR开始替代传统就医过程中的纸质病历,作为主要信息源贯穿医疗工作中,实现个人健康整合和资源共享[4],为优化就医流程、节约医疗支出起到重要作用。EHR数据不仅限于帮助医疗计费及患者管理,还能够助力生物医学研究,有较大研究潜力[1,5]。随着人工智能技术发展,利用深度学习等数据驱动方法对EHR进行2次利用,在临床决策支持[6]、疾病亚型发现[7]、药物警戒[8]、医学概念提取[9]、临床结局预测[10]等领域具有重要应用价值。然而EHR数据存在非结构化文本较多、数据隐私性要求较高、标注样本昂贵稀缺的问题,难以进行数据挖掘。以自编码器(Autoencoder, AE),生成式对抗网络(Generative Adversarial Network, GAN)和基于Transformer的双向编码器表征(Bidirectional Encoder Representations from Transformers, BERT)为代表的无监督深度学习技术能从富含噪声、无标注的原始数据中提取关键信息并直接对数据进行建模,实现特征提取、数据生成、结构化表示等功能,在解决EHR数据挖掘难点方面具有潜力。基于无监督深度学习的技术框架协助EHR数据挖掘具有广阔发展前景,成为当前研究热点。本文综述常用无监督深度学习技术及其应用于EHR的最新研究进展并对无监督学习技术进行总结与展望。
2 无监督深度学习技术
2.1 定义
无监督深度学习是指使用深度学习技术在没有额外信息情况下直接从原始数据中学习潜在的模式,以发现隐藏在原始数据中有价值的信息,例如有效特征、类别、结构、概率分布等。无监督深度学习可以用来作为通用数据预处理过程并在其后嵌入多种算法模型以完成具体下游任务。
2.2 常用无监督深度学习算法
主要包括自编码器、生成式对抗网络、BERT等。无监督深度学习模型使用卷积神经网络(Convolution Neural Network, CNN),循环神经网络(Recurrent Neural Network, RNN)等作为每个网络层的基础结构,利用随机梯度下降算法(Stochastic Gradient Descent,SGD),Adam,RMSprop等优化方法训练深度神经网络以完成模型学习。因模型结构和计算过程的差异性,不同无监督深度学习方法在EHR数据挖掘主要应用方向不同,见图1。本文对自编码器、生成式对抗网络、BERT原理及其在EHR数据挖掘中的具体应用进行介绍。
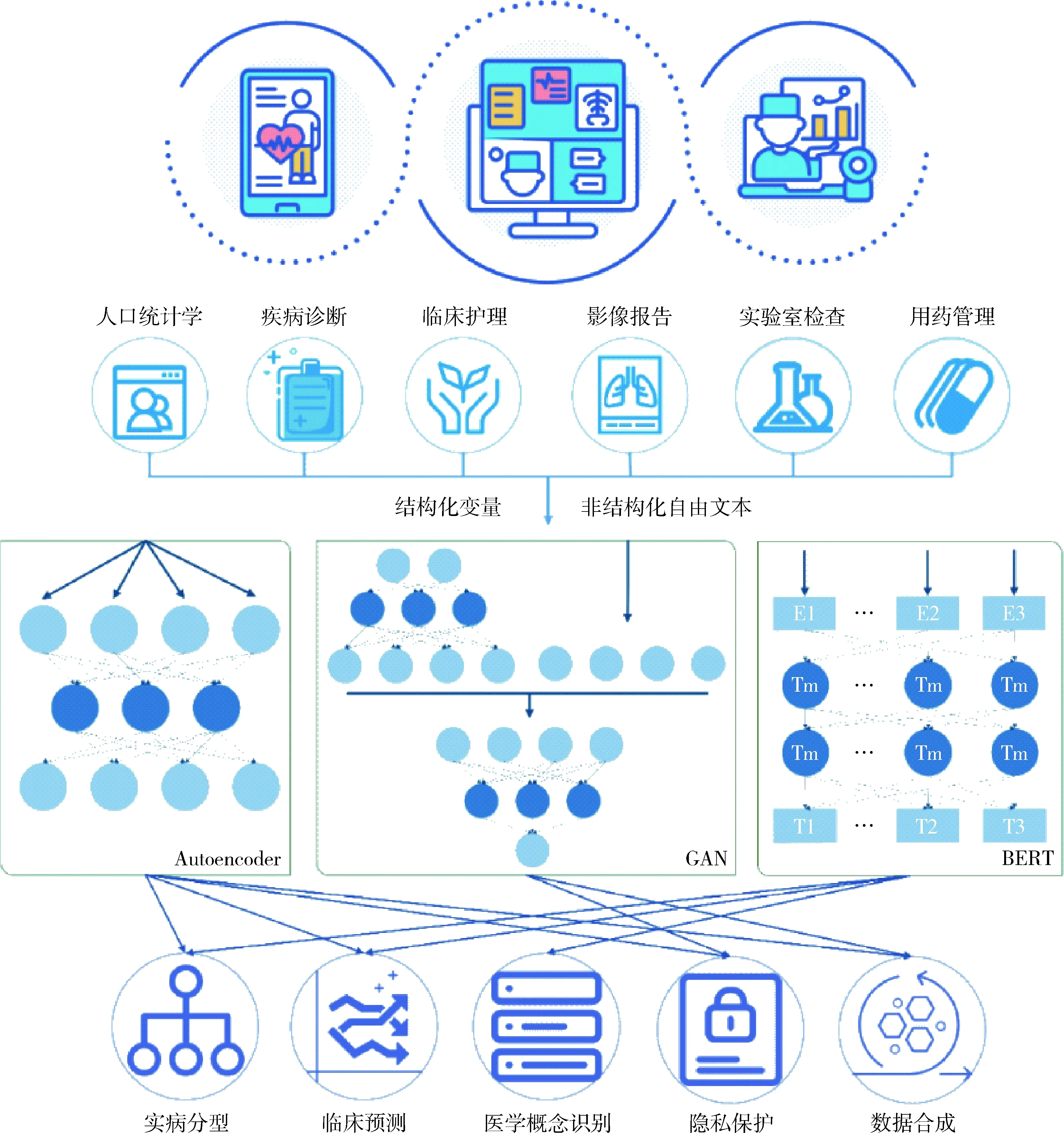
图1 基于无监督深度学习的EHR数据挖掘
3 无监督深度学习技术原理及在EHR数据挖掘中的应用
3.1 自编码器
3.1.1 基本概念 一种使用反向传播算法使模型期望预测输出值等于输入值的神经网络。其将高维输入压缩为低维的隐层表征并用以重构输出值。自编码器由编码器(Encoder)和解码器(Decoder)构成。对于任一给定输入向量x,首先在表示为h=f(x)的编码器中编码为低维隐层向量,再通过表示为y=g(h)的解码器进行输出,其中x与y的维度相同。因此自编码器计算过程可以用y=g(f(x))表示,而模型训练目标为最小化输入向量与输出向量之间的差异,可以表示为minLoss(x,g(f(x)))。
3.1.2 特点 相较主成分分析(Principal Component Analysis,PCA)等线性无监督学习方法,自编码器使用神经网络作为基础结构,通过不同激活函数实现非线性推广;同时自编码器可以通过叠加神经网络层数使编码器和解码器更加复杂,从而学习得到更有效的表示;更为重要的是自编码器作为一种通用数据驱动型计算模型,可以使用从另一相关数据中预先训练得到的模型或部分层,通过迁移学习和微调的方式增强当前任务自编码器表征性能以及降低训练耗时,大幅扩展自编码器应用范围,使其在小样本任务中具有良好表现。
3.1.3 特定用途自编码器 为尽可能提高自编码器表征能力及其在去噪、降维等特定用途的性能,研究者以传统自编码器为基础开发降噪自编码器(Denoising Autoencoder,DAE),稀疏自编码器,卷积自编码器,变分自编码器(Variational Autoencoder,VAE)等模型结构。
3.1.4 基于自编码器的EHR数据挖掘 目前自编码器在数据去噪以及数据降维、可视化等领域具有广泛应用,同时可用于特征提取、分类及异常值检测等任务。对于基于自编码器的EHR数据挖掘研究,由于自编码器能够以无监督方式自动学习有效特征且不同EHR数据的特征类别具有较高一致性,因此自编码器具有在大规模EHR数据中进行无监督学习的潜力,其编码器输出的低维稠密向量可在降维、聚类后用于患者分层,也可嵌入线性分类层或与随机森林等分类模型用于临床结局预测;而其解码器输出的向量与模型的输入信息相似,可被设计以实现隐私保护、数据合成等,见图2。

图2 基于自编码器的EHR数据挖掘流程
3.1.5 相关研究 Deep Patient[10]使用3层去噪自编码器自动学习EHR数据中的分层规律和依存关系,将自编码器学习到的深层表征作为随机森林分类器的输入,用于预测患者未来患病可能。结果表明基于自编码器模型的预测性能优于PCA、K-Means等传统无监督学习算法;ConvAE[7]使用词嵌入、卷积神经网络和自编码器提取电子病历深度表征并在复杂疾病的临床亚型分型任务中取得最优性能;SDAE[11]使用规范化的堆叠式去噪自编码器,根据大量急性冠状动脉综合征EHR数据完成患者分层和临床风险预测任务并取得具有竞争优势的预测性能。
3.1.6 应用价值 自编码器可作为自动学习EHR深层表示的通用框架,这种无监督深度学习方式不仅消除了昂贵费时的手工特征工程步骤,还能以数据驱动的方式学习真实世界样本中的潜在表示,具有广阔的临床应用前景。
3.2 生成式对抗网络
3.2.1 基本概念 生成式对抗网络是Goodfellow I、Pouget-Abadie J和 Mirza M等[12]于2014年提出的一种基于深度学习的无监督生成模型,用于根据模型的自我对抗过程以实现生成足够逼真的数据的目的。生成式对抗网络主要包括生成器和判别器两个部分,其中生成器用于根据给定的输入信息生成一个尽可能“以假乱真”的新数据,而判别器用于判断生成器所生成数据是否为真实样本。在最初训练过程中生成器仅能生成充满噪声的数据,而判别器可以很准确地进行辨别;随着模型不断迭代,当生成器可以生成与真实数据分布相同的数据时,判别器无法准确判断数据来源,便认为模型已完成训练并能够用于相关数据的生成任务中。目前生成式对抗网络已经成功应用于图像生成[13]、风格迁移[14]、信息补全[15]等领域中并达到目前最先进技术(State-Of-The-Art,SOTA)效果;同时在文本生成[16]、结构化数据生成[17]等方面也有大量应用。
3.2.2 在EHR数据挖掘中的应用场景 对于部分特殊疾病和罕见病来说,EHR数据是稀缺的;同时受医疗数据法律、隐私和安全问题等因素影响,完整EHR数据的获取难度较大。为了规避这些问题可以考虑通过自动生成逼真的合成数据进行EHR数据挖掘;对于EHR数据扩增方面,相较于基于概率统计和临床实践指南的传统方法,基于生成式对抗网络的无监督方法通用性更广,并且可以自动从数据中学习到真实样本分布而不是依靠先验知识。基于生成式对抗网络的EHR数据挖掘流程较为简单,研究者可以直接通过将随机噪声向量输入训练后的生成式对抗网络以得到与训练EHR数据分布相似的合成数据,以解决EHR数据合成和隐私保护问题,见图3。

图3 基于生成式对抗网络的EHR数据挖掘流程
3.2.3 相关研究 DAAE[18]将递归自编码器与生成对抗网络结合,在生成时间序列EHR数据时取得了最优的似真性评分;MedGAN[19]结合自编码器和生成式对抗网络以合成高质量的EHR离散数据,在数据分布统计和预测建模等任务中实现了与真实数据相当的性能;而MedWGAN、MedBGAN[20]为对MedGAN进行改进,提高了关联规则挖掘和疾病预测方面的性能。在隐私保护方面,生成式对抗网络生成的合成数据与真实样本没有显式映射,而针对MedGAN、DAAE等生成式对抗网络的隐私实验结果表明,基于生成式对抗网络产生的不同EHR合成样本的潜在隐私暴露风险较低。
3.3 BERT
3.3.1 基本概念 BERT[21]是谷歌于2018年提出的一种大规模预训练语言模型,其在11个自然语言处理任务中取得了先进结果。BERT的模型结构由一种基于Self-Attention的Transformer[22]结构组成,相较于自然语言处理中较为常用的循环神经网络Transformer计算速度更快并能进行深层堆叠。此外BERT还构建了两种无监督预训练(Pre-training)过程。(1)MLM(Mask Language Model)。对部分输入句子中的字进行随机掩盖并通过训练BERT模型以预测被掩盖的字来学习句子内部关系。(2)NSP(Next Sentence Prediction)。1次输入两个句子并训练BERT模型以预测两个句子相邻的概率来学习句子之间的关系。通过构建MLM和NSP训练目标,BERT能够以无监督的方式从无标注文本中进行预训练,在完成预训练过程后,BERT模型可以通过在模型后端嵌入不同结构以应用到不同自然语言处理任务中,例如文本分类、命名实体识别、语义提取等。
3.3.2 基于BERT的EHR数据挖掘 BERT被广泛应用于不同语种、专业领域的自然语言处理问题中。在相关领域或语种的大规模文本上完成预训练后,BERT使用特定任务相关数据集进行微调,即可取得先进性能。在EHR数据挖掘领域,由于BERT模型的参数量较庞大、训练时间较慢,研究者常在开源BERT预训练模型的基础上使用EHR自由文本进行微调。在下游任务方面,研究者可使用微调后的BERT模型输出临床文本的表示向量以用于语义相似性计算,或嵌入线性分类层以进行临床预测任务研究,见图4。医学概念识别也属于针对每个医学概念词语的多分类任务,可根据每个词语经过BERT编码后的输出类别值识别对应的医学概念。

图4 基于BERT的EHR数据挖掘
3.3.3 应用情况 医学概念识别方面,EHRBERT[23]从EHR中识别药物、诊断、不良事件等医学临床实体并将其规范化。识别医学临床实体可以将非结构化文本转化为结构化数据,这对临床决策支持、医学知识发现等基于EHR的数据挖掘研究具有重要作用;临床预测方面,TAPER[24]利用BERT模型将EHR中的非结构化文本嵌入到统一向量表示空间中,有效地将患者信息编码为可用于下游任务的形式,增加了EHR有效信息量并将其应用于存活、重复入院等临床结局事件预测中;语义相似性方面,由于基于模板和临床笔记生成的EHR数据存在较多冗余信息,需要对EHR数据进行压缩,而计算临床文本片段的语义相似性是一种解决方法。Mahajan D、Poddar A和 Liang J J等[25]将多任务学习方法应用于ClinicalBERT模型中,在临床语义文本相似性任务中取得了最优预测性能。
3.4 无监督深度学习技术研究情况
目前无监督深度学习技术研究在疾病亚型分析、临床结局预测等多个细分医学研究领域已取得较大成果,但其在EHR数据挖掘中的通用性应用尚未成熟,具体主要体现在大多研究的建模数据来源不具备普适性和代表性。例如ConvAE、EHRBERT等研究使用数据规模较大,但均为医院未公开EHR数据。虽然保证了数据一致性,但将其迁移至不同来源的EHR数据会存在数据分布差异问题;TAPER、DAAE等使用MIMIC-III等公共EHR数据库数据进行建模,但缺乏实际应用场景下的外部验证集评估。因此如何有效地将无监督深度学习技术应用于EHR数据并指导临床实践仍然有待进一步研究。EHR数据挖掘的无监督深度学习模型及其主体模型结构和应用场景,见表1。
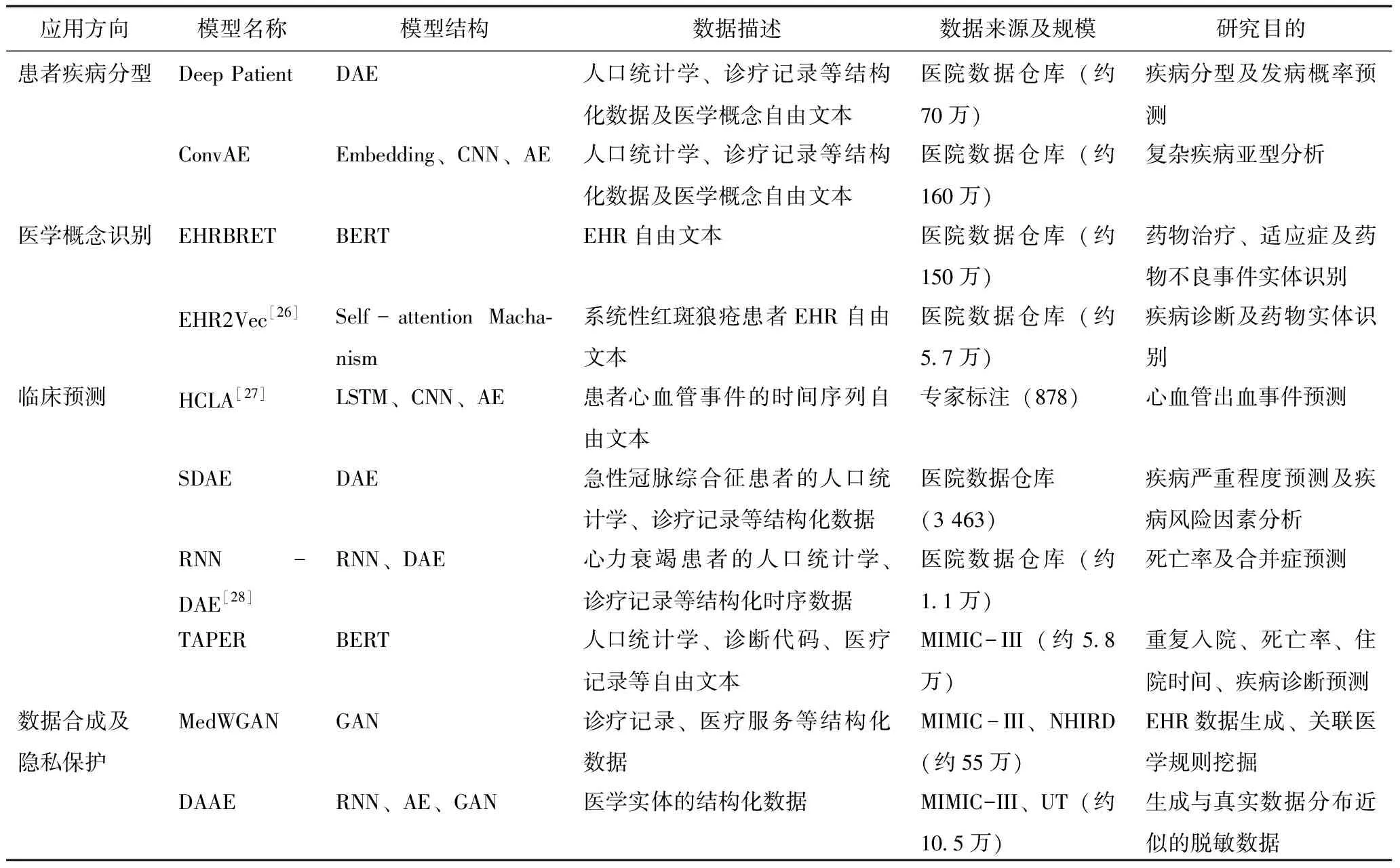
表1 基于无监督深度学习的EHR数据挖掘应用研究

续表1
4 无监督深度学习的局限性
4.1 缺乏可解释性
由于深度学习是一种“黑盒”模型,研究者尚未能揭示深度学习模型在训练过程中所学习参数矩阵的具体意义,EHR数据使用自编码器、BERT等无监督学习方法得到的潜在表示无法被合理解释,而临床决策支持、患病风险预测等临床具体应用需要预测工具的计算方法具有可转化为临床知识的能力,这使得无监督深度学习在临床实践中应用较为受限。
4.2 异构数据处理困难
EHR中存储有包括人口统计学、疾病诊断、实验室检查、影像报告、用药情况等多源异构数据,从数据结构上来说包括非结构化文本、图像、类别特征、实值特征等,单一无监督学习技术无法有效处理全部EHR信息。开发基于无监督学习的通用异构信息处理框架是最大程度利用EHR数据、促进临床应用的重点研究方向。
4.3 缺乏通用基准测试
大多用于EHR数据挖掘的无监督深度学习模型多采用私有数据集,并且受患者数据敏感性限制EHR数据共享较难推进;有研究声称该模型具有最先进性能却较少有充足外部验证过程。因此缺乏通用基准测试数据集和算法是目前开发适合于EHR数据的无监督深度学习模型的障碍。
5 结语
无监督深度学习与人类学习方式相仿,能够自动从大规模无标注数据中学习相关概念和关系的表示,并且可以作为预训练模型用于其他任务之中,具有发展为通用人工智能技术的前景,因而被卷积神经网络发明人Yann LeCun誉为“深度学习的未来”。在EHR数据挖掘领域,使用海量EHR数据训练的无监督深度学习模型可用于生成模拟数据、处理冗余文本信息和特征提取,是患者隐私保护、结构化表示和临床预测等关键问题的重要解决方法。随着信息化技术的发展和人力成本的增加,急剧扩增的EHR数据中无标注样本的占比逐渐增大;虽然EHR数据共享不断加深,但数据隐私保护及多源异构问题阻碍了监督学习在EHR数据挖掘中的广泛应用。而无监督深度学习相比于监督学习和统计分析等方法具有数据驱动、通用性强等优点,能够从大规模EHR数据中挖掘、提取、发现有效信息,助力临床医学研究。
