基于大规模图谱分析的移动流量数据识别算法研究
2022-05-26易灿
易灿
(湖南大众传媒职业技术学院,湖南长沙,410100)
0 引言
网络中每天都会有大量的用户数据信息产生,例如,移动互联网网页数据、用户交互数据、设备产生活动数据等等。传统的流量分析技术无法做到对如此大规模、复杂数据的分析和识别,网络运营商为满足用户使用需求、提升数据挖掘能力,需要采用分布式并行算法对海量网络数据进行处理与分析。图谱分析是数据分析过程中较为常见的分析方法,不仅能够直观展现分析过程与结果,还能挖掘事物间深层次的关系。文章基于图谱分析,设计了三种识别算法,对移动网络流量数据进行识别与分析。
1 网络流量监测方法与意义
■1.1 移动流量数据监测方法
对互联网流量数据进行监测是了解互联网特性、挖掘有效数据信息的重要方式。通常采用两类方式进行流量监测,第一种为主动流量监测。此方式通过在监测点利用网络探针对网络流量进行主动监测。其优点为能够直接测量网络,测量过程可控性较高,测量方式相对灵活,但也存在一定缺点,主动测量并直接分析的方式,会有新的网络流量产生,这些新出现的流量,一定程度上会改变原本网络情况,降低测量结果精准性,且会使得被监测网络的荷载负担加大,反而不利于对如此大规模数据流量的主动测量。
另一种方式为被动流量监测,此监测方式需要设置监测点,然后按指定的时间间隔或者长时间对流经该监测点的数据流量进行收集,并将监测点收集的流量信息存储,便于之后进行数据分析、特征提取等,也可依据监测信息对网络性能进行分析。该监测方式理论上不会产生新的网络流量,不会增加网络运行负担。但其缺点也较为明显,此方式只能对某一监测点的流量数据进行监测,且使得监测点数据存储与分析等问题增多[1]。
■1.2 网络流量监测意义
对网络流量数据进行监测,可以实现互联网的科学规划和扩容。网络运营过程中,运营商经常会面临资源不足问题,导致无法满足较高的网络需求,需要对网络进行扩容。但是如果没有针对性地扩容,首先资金投入是一方面的问题,关键也往往并不能有效解决问题,网络容量没有得到显著扩充。如果在扩容之前对网络流量数据进行了科学监测,可结合网络历史数据,对流量进行控制,减少一些低附加值的流量,从根本上避免流量过载问题的发生,因此能够减少对网络的扩容需求,也能降低运营商维护资本。以往的流量监测数据,可对未来流量变化预测提供参考,以及时采取有效措施提前应对。
通常情况下,每天的网络流量时间流量曲线都较为相似。假如某个节点出现了故障,那么其相对应的网络流量也会呈现出异常现象。因此,网络流量监测环节,可帮助网络运维人员进行网络故障分析和运行维护。对网络流量的监测,有助于发现信息流量的不合理流动情况,例如,一些非常繁忙的链路或者经常闲置的链路,然后进行人工调整,以提高网络资源的利用率,同时避免流量拥堵。网络监测在网络安全防护方面也有着重要作用。网络上不可避免地存在一些大大小小的不合规合法现象,例如,恶意攻击、垃圾邮件以及恶意病毒等,影响网络的安全使用。这些行为通常较为隐蔽,需要专门的设备来检查。而长期的网络流量监测下,正常流量的基线已经建立,对一些异常流量进行监测可发现这些违法行为,维护网络安全[2]。对网络流量监测数据进行挖掘和分析,也有助于了解用户的真正需求,然后利用网络资源,实现精准市场营销,增加用户对网络的依赖性,提升用户使用满意度。
2 基于图谱分析的网络流量数据分析与识别算法
依据图谱分析,可对网络中大规模移动流量数据进行处理与分析,对互联网的现状进行更加直观、深入的掌握。基于图谱分析方法,对海量网络流量数据进行了三方面的分析,分别为点击识别分析、实体连接结构分析以及网页级精细化流量分析,并针对每一种分析都设计了相应的识别算法[3]。
■2.1 基于依赖图的用户点击识别算法
智能终端的应用软件几乎都采用HTTP 协议实现,为了更加高效地从海量数据流量中分析出用户的真实网络浏览行为和兴趣,要对Web 数据进行预处理,准确识别出用户的网页点击请求[4]。其点击识别流程算法如图1 所示。

图1 点击识别算法流程图
第一步骤为数据预处理。网络中存在大规模的用户点击记录,一些是错误的或者无用的请求记录,为提升用户点击快速识别过程,首先要对捕获的海量HTTP 请求记录进行预处理,将无效记录清除,减少数据量。一个正常、完整的HTTP 请求记录具有多个属性值,例如,用户号码标识、流开始时间、流结束时间等。其中属性值不完整的请求记录都视为要从记录集中去除的目标。然后依据用户号码将网络中同一用户的请求按照流开始时间排序并聚合到一起,生成用户请求序列。
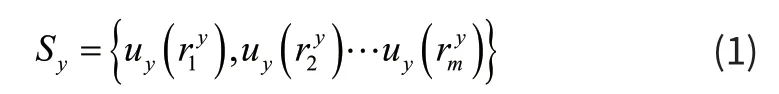
第二个步骤为建立请求依赖图。依赖图中的每个点都有两种可能,分别是主请求和内嵌请求。主请求是向网页服务器发出的第一个请求,也就是用户点击请求。初始页面会有多种内嵌实体超链接,用户对这些内嵌超链接发出的请求即为内嵌请求。设定一个向前间隔时间τ,与用户请求间隔作对比。如果该用户的请求ri的起始时间和ri-1的起始时间差值大于τ,将其认定为候选主请求,如果ri与下一个请求ri+1起始时间差值小于τ,则在请求依赖图中由ri代表的点向ri+1代表的点建立一条边。依次类推,直到发现一个新的候选主请求为止,再计算用户在新主请求中的内嵌请求[5]。依赖图中用户请求的点或两个请求之间的边的出现次数,当做其在请求依赖图中的权重。
第三个步骤为识别点击请求。计算一个节点作为主请求的概率,来判定此用户请求节点是否为主请求。计算方式如下。
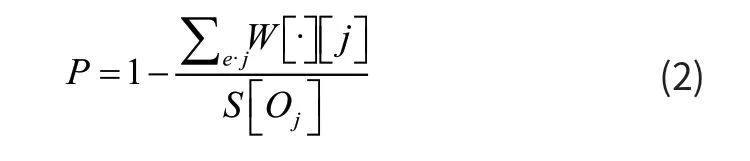
计算出该节点是主请求的概率P 之后和门限值ρ 对比,如果P 大于门限值,则可认定其为用户点击主请求,如果P小于门限值,则认定该节点为内嵌请求,即用户在主请求页面触发内嵌实体链接的请求。
■2.2 并行tNMF 算法
随着结构化的网页越来越复杂,对于网站设计或者管理员来说,对网页实体间的关系进行分析也越来越重要。在采用用户点击识别算法以后,请求依赖图中的每个节点被标上了点击请求和内嵌请求的分类标签,构成了一个二部请求依赖图。对此设计一个并行的tNMF算法对二部请求依赖图进行图形分解。通过分析图形分解结果,探究网页实体间的依赖模式[6]。
用邻接矩阵表示二部请求依赖图模型,对邻接矩阵分别进行行向量和列向量的聚类,得到具有相似特征的行向量和列向量,组成一系列子集。设计的并行tNMF 算法是对二部请求依赖图进行分解的一种联合聚类算法。邻接矩阵Dm×n中m 代表主请求,n 代表内嵌请求,将m 个主请求聚类为p 个主请求组,表示为矩阵Rm×p,对应的,将n 个内嵌请求聚类为q 个内嵌请求组,表示为Cn×q,因此最终可得p×q 个聚类子图,表示为矩阵Hp×q。所有的矩阵都为非负矩阵,并行tNMF 算法流程如图2 所示。

图2 tNMF 算法流程
初始输入阶段。向算法中输入一个邻接矩阵Dm×n,然后依据矩阵阶数和p、q 参数,将上述矩阵R、C、H 随机初始化。
迭代优化阶段。计算相对平方误差RSE,其计算公式为:
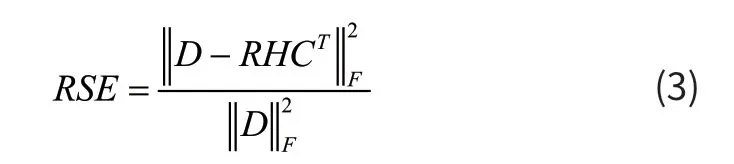
当相对平方误差大于门限值θ 时,对R、C、H 三个矩阵进行迭代更新,直到其小于门限值θ,停止迭代更新进入下一步。矩阵R 中的元素表示第i 个元素属于第s 组的似然度。迭代更新算法为:

输出阶段。经迭代优化以后,最终生成三个矩阵,分别为R、H、C,然后再生成聚类子图。完成并行tNMF 算法。得到p×q 个联合聚类,其中每一个分组都代表一个子图结构,用小的邻接矩阵L 表示每个子图结构,矩阵L 的行向量表示为k,列向量为h,分别表示子图中的主请求和内嵌请求个数。根据矩阵Lk×h的阶数,对子图的结构模型进行判断。判断方法为:如果子图中主请求个数k 为1,同时内嵌请求个数h 大于1,则这种子图结构模式为“点击星形”;如果主请求个数k 大于1,同时内嵌请求个数h 等于1,此时子图结构模式为“内嵌星形”;如果k 和h 都大于1,则这种子图结构模式为“网状”;如果k 和h 都等于1,将此子图结构模式定义为“其他”类型。
■2.3 并行流式算法
用户的点击请求能够反映出用户的真实网络使用意愿,为对大规模网络数据进行精细化分析,基于Spark 计算框架设计了并行流式算法。选用Spark Streaming 并行开源框架,相对于其他流式处理框架,其对流式大规模数据处理优势显著,能够从多种数据源获得数据,也能将数据输出到不同数据平台。接收到数据流以后,将其分为一个个小批次数据流(Batch),供后续处理。DStream 是Spark Streaming 中特有的基础数据类型,代表了一系列连续的RDD,每个RDD 都对应一个小批次数据流Batche,使得用户能够通过处理RDD 来对流式数据进行处理[7]。设计的并行流式算法流程图如图3 所示。

图3 并行流式算法流程图
由图3 可知,首先开源流处理平台Kafka 将捕获的网络流量数据以数据流形式输送给SparkStreaming,SparkStreaming 将整个数据流切分为多个小段数据流,转换为DStream 数据。以5 分钟为一个时间段,将数据流分别依次存在Batchs 中。将数据流切分,可能会引起用户访问同一网页的所有请求,分在不同批次Batche 中。在此需要用到SparkStreaming 的窗口函数,将窗口大小定为10分钟,而滑动更新时间间隔为5 分钟,这样当用户的网页请求被分到不同Batch 中时,窗口进行一次滑动后,下一个Batch 内依然有上一个Batch 内网页的所有请求,数据完整性得到保障,每个RDD 都输入到Spark 引擎中,先对用户在同一网页内的所有请求构建referrer 图,然后将RDD经Content-Type 过滤和其他转换操作,识别出用户的点击请求,输出到HDFS 内[8]。
3 结语
综上所述,网络数据监测对于网络的科学规划与扩容、网络安全运维与防护、网络资源合理利用等都有着重要意义。设计了用户点击识别算法以更深入探究用户的使用需求和兴趣;设计了并行tNMF 算法,以揭示网页实体间的依赖模式;基于Spark 技术框架设计了并行流式算法,对流量数据进行精细化分析。分布式并行算法在网络数据的挖掘和分析中将会发挥更重要的作用。
