可变时长的短时广播语音多语种识别
2022-05-25邵玉斌杜庆治
王 瑶,龙 华,邵玉斌,杜庆治
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
语种识别是指计算机根据不同语种之间的差异来判别语音样本中所用语言的种类.在语种识别中,短时语音片段被用于多种场景,例如军事监听、短语翻译和紧急救援等,但短时语音存在一些不足:①随着语音时长的减少,语段特征中有效信息也随之减少[1],无法充分表达语种信息;②由于训练语音的数量是有限的,无法覆盖到任意时长,而当待测语音与训练语音时长不等时,语种识别的准确率会急速下降.文献[2]针对短时语音的语种识别问题提出了一种时长扩展方法,该方法通过对短时语音进行语速变速和时长拼接,将原有的短时语音片段转换成时长较长的语音,有效提高了短时语音的语种识别准确率.但在语段拼接过程中,语音的条数和语速的快慢对语种识别结果影响较大.为了解决训练语音与测试语音时长不等而导致语种识别率下降的问题,文献[3]采用语种特征补偿方法对不同时长语音的特征进行补偿,将不同长度的语音特征映射到了固定长度上,较好地解决了长度失配和音素失配不平衡的问题,但在短时语音的语种识别中,其准确率还不够理想.文献[4]和文献[5]通过在深度神经网络中引用时间平均池化层(Temporal Average Pooling layer,TAP layer),将不同时长语音处理成相同维度的特征,虽然解决了训练语音和测试语音时长不匹配的问题,但也丢失了语音信号中的部分时域信息.近些年来,长短时记忆网络(Long Short-term Memory Network,LSTM)[6]在处理可变时长语音的问题上取得了一定的成果,但还是存在两个缺点:①当输入序列较长时,由于时间的迭代乘法,训练速度可能非常缓慢[7];②训练过程中可能会出现梯度消失和梯度爆炸的问题[7].就目前而言,在可变时长的短时广播语音信号语种识别实验中,采用卷积神经网络(Convolutional Neural Network,CNN)[8]作为后端分类器是较为少见的.同时,Abdel-Hamid 等[9]认为CNN 用于语音识别有3 个重要的优势:①局部感受野可增强对非白噪声的鲁棒性;②权值共享可以进一步增强模型的鲁棒性;③池化操作可以抵抗频带带来的扰动.
针对上述可变时长的短时语音在语种识别中存在的问题,本文在训练阶段,提取短时广播语音对数功率谱包络图(Logarithmic Power Spectrum Envelope Map,LPSEM)作为特征输入,并以CNN中的Resnet 网络[10]作为分类模型.在测试阶段,当待测语音的时长不等时,本文基于文献[10]中的深度残差网络Resnet34,在其前端引入时长规整层(Regular Duration layer,RD layer)构建出一个可以识别可变时长语音的语种识别模型(Variable Duration-Language Identifi-cation,VD-LID).在时长为1 s 的短时语音语种识别任务中,准确率达到了82.4%;此外,相比于没有引入时长规整层的Resnet34网络,VD-LID 分别将测试语音时长为5 s 和10 s的语种识别准确率提升了27.9%和37.7%.
1 特征提取
1.1 语种特征分析语谱图[11]、对数Mel 尺度滤波器组能量(log Mel-scale filter bank energies,Fbank)[12]、梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)[13]是进行语音识别的重要特征.这些特征在说话人识别和语种识别中都取得了一定的成果,但在语种识别中还存在一些不足,语谱图、Fbank、MFCC 包含了大量的说话人信息,这些信息会对语种识别产生较大影响.并且对于Fbank 而言,由于在提取过程中经过了梅尔滤波器组,使其具有了较高的相关性,这将会产生大量冗余信息.相比于Fbank,MFCC 在其基础上进行了离散余弦变换(Discrete Co-sine Transform,DCT),虽然降低了Fbank 的相关性,但在一定程度上减少了语音中的原始信息量.目前还没有文献明确何种特征会对语种识别起到关键作用,因此对特征提取的课题还有待研究.针对上述问题,本文提出使用LPSEM 作为特征输入.
语音信号可以看作是由声门激励信号与声道冲激响应共同作用的结果,其中声门激励信号主要反映语音的说话人信息,将其滤除可以有效减少语音信号中的说话人信息[14].本文中声道冲激响应就是对数功率谱包络(Logarithmic Power Spectrum Envelope,LPSE).LPSE 不仅与语义有关,还反映了语音信号的声道特性[15],声道特性是指人类发声时舌体、牙齿等器官的形状.而不同语种在发音时,舌体、牙齿等器官的形状具有一定差异.从语音的音素角度分析,不同的语种都有一套不同的音素来加以描述,并且不同音素的共振峰标度有所不同,而共振峰标度可以很好的在LPSE 中显现出来,故选择LPSEM 作为语种识别的特征.
1.2 LPSE 提取提取LPSE 实 际上就是将语音中的声门激励信号与对数功率谱包络分离的过程,具体流程如图1 所示.

图1 对数功率谱包络特征提取流程图Fig.1 The features extraction of logarithmic power spectrum envelope
一帧语音信号x(n) 可以表示为:

式中,x1(n) 和x2(n) 分别表示对数功率谱包络和声门激励信号,∗ 表示卷积运算.
步骤 1分帧、加窗:对语音信号进行分帧,然后加上窗函数,取一帧语音信号x(n) 进行分析.
步骤 2DFT:通过离散傅里叶变换(Discrete Fourier Transform,DFT),将时域信号变换成为频域信号.

式中,fdtc() 为离散傅里叶变换,N为序列长度,n为时域上的第n个采样点,k为频域上第k个采样点,j 为虚部单位,X(k) 为变换后的频域信号.
步骤 3取模、取对数:对式(2)中X(k) 取模,再求其对数:

步骤 4IDFT:对进行逆离散傅里叶变换(Inverse Discrete Fourier Transform,IDFT)得到语音信号x(n) 的复倒谱:


式中,Y(k) 为语音信号x(n) 的对数功率谱包络.语音信号x(n) 的波形、对数功率谱和对数功率谱包络 如图2 所示.

图2 同一帧语音信号的波形、对数功率谱和对数功率谱包络Fig.2 The waveform,logarithmic power spectrum and logarithmic power spectrum envelope of the same frame speech signal
1.3 绘制LPSEM语音信号作为非平稳信号,其频域随时间变化而变化,为了较好地保留语音信号的时域特性和频域特性,同时使得每一帧语音信号之间具有较强的关联性,在提取完一帧语音信号的LPSE 之后,将同一段语音信号的每一帧LPSE按行拼接起来,形成一个f×w的矩阵M,其中f代表帧数,w代表帧长.其流程图如图3 所示.

图3 生成对数功率谱包络图的流程图Fig.3 Flowchart for generating a logarithmic power spectrum envelope diagram
在LPSEM 中,横轴为频率特性,纵轴为时域特性,每一个色块由矩阵M中的一个数据点扩展得到.同时矩阵M是由每一帧语音的LPSE 按行拼接而成,故M可以表示为:

式中,i代表第i帧,j代表每一帧的第j个点.
将一个数据点扩展形成一个色块,即Yi(j) 扩展得到色块Zi(j),矩阵M扩展为矩阵Z,因此,LPSEM 可以表示为:
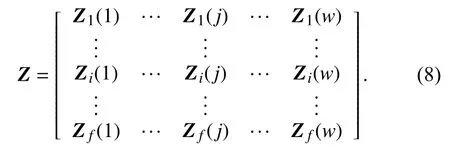
2 语种识别模型VD-LID
对于一般的神经网络,尤其是全连接神经网络,其输入需要固定长度[16-17],然而在语种识别和说话人识别中使用的语音时长往往不是固定的.为了让语种识别系统输入语音时长可变,并且不丢失语种信息,同时语种识别准确率保持在较高水平,本文在Resnet34 网络前端引入一个时长规整层.如图4所 示.
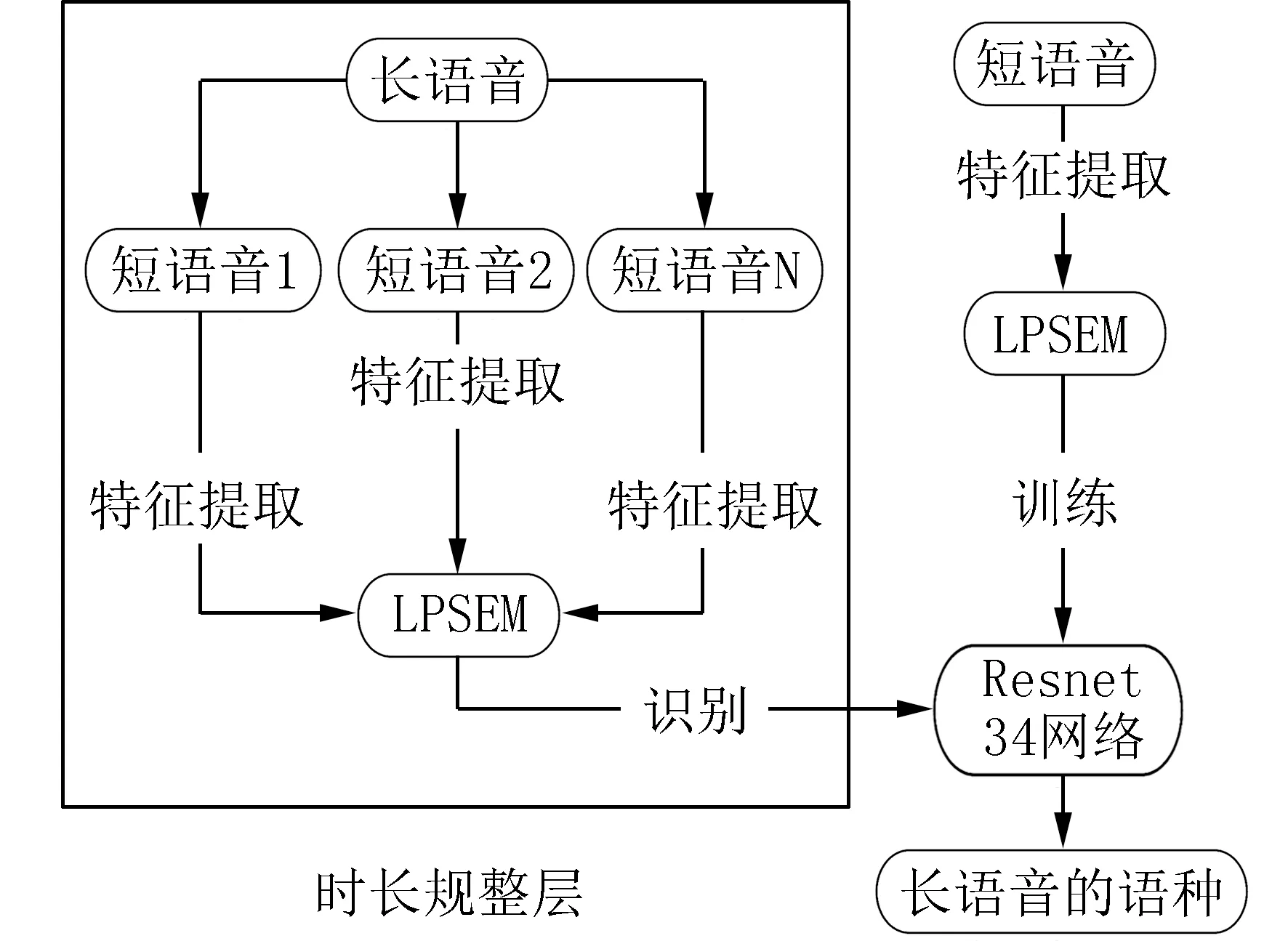
图4 引入时长规整层的VD-LID 模型Fig.4 VD-LID model with regular duration layer
2.1 时长规整层本文根据语音的时长不同,将长语音分割为若干时长为1 s 的短时语音,从而保证测试语音的特征能够映射到训练语音的输入特征上.已知时长为1 s 的短时语音片段生成LPSEM特征矩阵M的维度是f×w.当语音片段时长大于1 s 时,设其生成的LPSEM 特征矩阵为M′,其维度为F×w,此时F≥f,故需要引入时长规整层对长语音进行时长规整,具体操作如下:将长语音切割成多条时长为1 s 的短时语音,其结果表示如下:
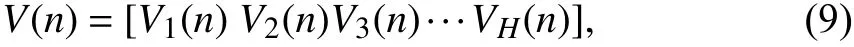
式中,V1(n),V2(n),V3(n)···VH(n) 分别为时长为1 s的短时语音,V(n) 为时长大于1 s的语音,n代表第n个采样点.在进行语音分割时,首先要确定语音信号的时长T,再确定所分时长为1 s 的短时语音的个数H.L为长语音分割时相邻两段短时语音的重叠时长或间隔时长,其计算公式如下:

当L大于0 时,|L| 表示相邻两段短时语音的重叠时长,当L小于0 时,|L| 表示相邻两段短时语音的间隔时长.
2.2 CNN 网络目前在语音识别领域比较流行的CNN 网络主要是Resnet 网络和VGG 网络.在VGG 网络内部使用多个 3×3 的卷积核代替其他大尺度的卷积核,其优点在于,保证相同感知野的条件下,不仅可提升网络的深度,在一定程度上也提升可神经网络的效果.然而VGG 网络拥有3 个全连接层,这意味着会使用大量的参数,因此它的计算会消耗大量的资源.同时随着网络层数的增加,梯度消失导致其后端网络层无法对前端网络层进行调整,也会影响神经网络的性能.
相比于VGG 网络,Resnet 网络引入残差单元来解决网络的退化问题.残差单元可以表示为:

式中,x和y分别表示所在网络层的输入和输出结果,F(x,Wi) 表示要学习的残差映射,F(x) 代表残差函数.W1和W2代表图5 中第一个网络层和第二个网络层的权重向量,σ 代表ReLU 激活函数.最后残差单元的输出为 σ(F(x)+x).
当残差函数F(x)=0 时,此时堆积层做了恒等映射,网络的性能不会随着网络层数的增加而下降,事实上残差函数不会为0,因此堆积层在输入特征基础上还可以学习到新的特征,从而拥有更好的性能.图5 为残差单元结构示意图.
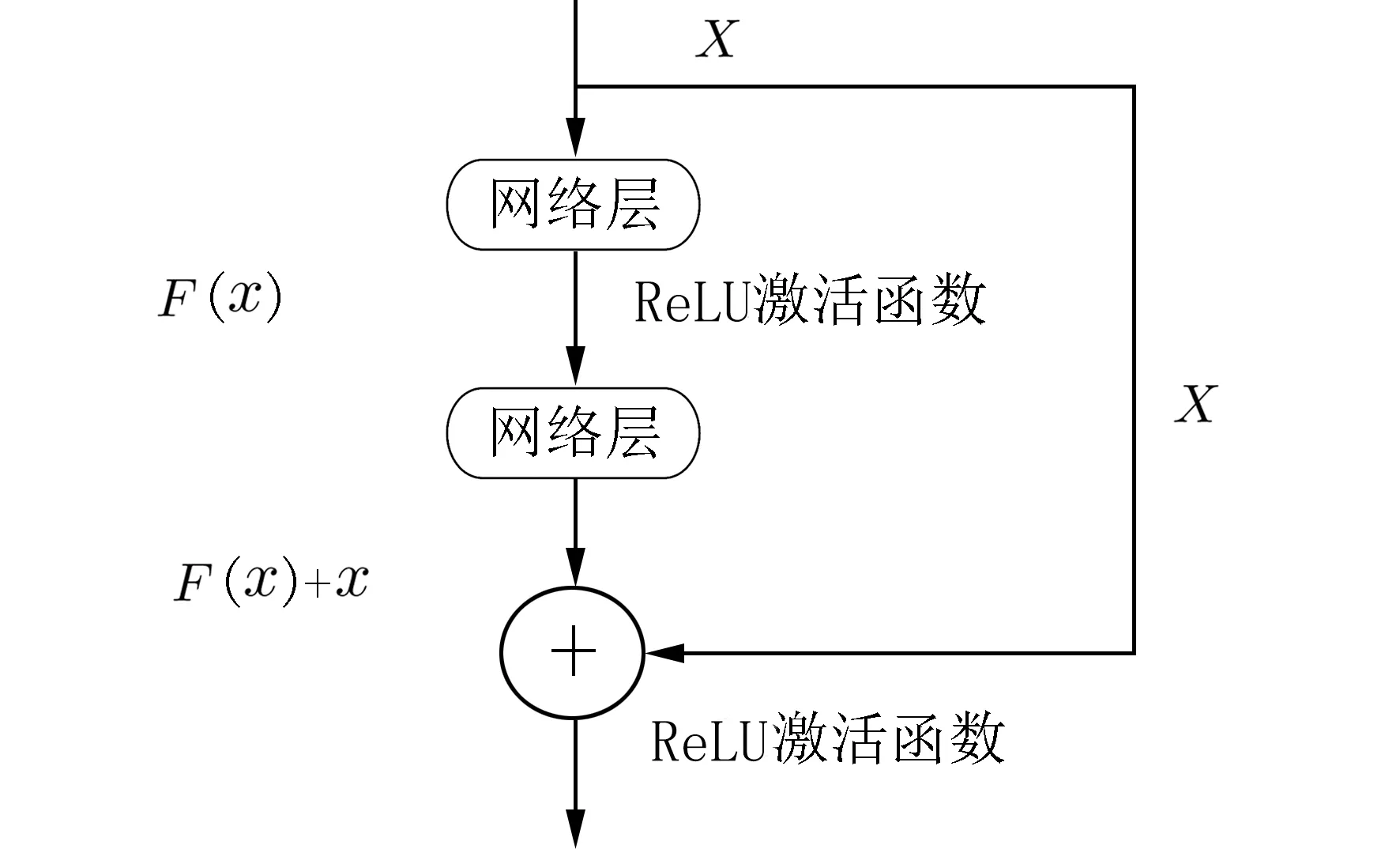
图5 残差单元结构图Fig.5 Unit structure diagram of the residual neural network
在VD-LID 后端我们采用softmax 函数来计算语音分属每一语种的概率.

式中,pJ表示判别为第J类语种的概率,G代表语种个数,cI、cg分别代表第I个节点和第g个节点的输出值.
一段时长为T的长语音,经过分割之后得到H段时长为1 s 的短时语音,将H个短时语音的特征输入CNN 网络得到H×G个节点的输出值,然后把这些节点的输出值映射到softmax 函数中,得到各个短时语音识别为某种语种的概率pJ.

式中,QJ代表待测长语音被判别为第J类语种的概率,eJ表示第J类语种片段的个数,pJ,r代表被识别为第J类语种的第r条短语音的概率,pr表示当识别为第J类语种时,第r条短语音的概率.
因此,当输入一段长语音时,首先经过时长规整层分割为若干条时长为1 s 的短时语音,通过公式(13)计算得出每条短时语音识别为某种语种的概率pJ,再将pJ带入公式(14)计算这些短时语音的概率,最后计算得出长语音识别为某种语种的概率QJ.
3 实验分析
3.1 实验设置实验数据集从国际广播电台中录制,共8 种语言,分别是普通话、缅甸语、越南语、柬埔寨语、老挝语、韩语、藏语、维吾尔语.采样率为16 kHz,精度为16 bit,声道为单声道,每种语言4 800 段,其中3 000 段为时长为1 s 的训练集,剩下的1 800 段为测试集.测试集包含3 种时长,分别为1、5 s 和10 s,每种时长600 段.
本文中语种识别的测试标准采用识别准确率(Recognition Accuracy,AR)来评价.

式中,G代表语种个数,ag是第g个语种识别正确的语音个数,bg代表第g个语种总的语音数,AR代表识别准确率.
语种识别系统分为前端声学特征和后端语种分类模型,前端声学特征采用Fbank、MFCC、LPSEM 和语谱图.其中LPSEM 作为实验特征,Fbank、MFCC 和语谱图作为对比特征.后端训练模型为Resnet 网络和VGG 网络.网络采用交叉熵准则(cross entropy)进行训练.
实验主要分为3 个部分:第1 部分分别将语音的Fbank、MFCC、LPSEM 和语谱图特征拟合到Resnet 网络和VGG 网络中,研究各个特征在不同网络中的语种识别情况;第2 部分分别对语音的Fbank、MFCC、LPSE 的特征向量和Fbank、MFCC、LPSEM 的特征图谱进行训练,研究特征数据扩展对短时语种识别效果的影响;第3 部分在Resnet34网络前端引入一个时长规整层,同时与不加时长规整层的Resnet34 网络进行对比,来研究时长规整层对不同时长语音输入的影响.
3.2 实验结果
3.2.1 实验1 在实验1 中,语音时长为1 s,输入特征为Fbank、MFCC、LPSEM 和语谱图,训练网络根据种类和层数的不同分为Resnet18、Resnet34、Resnet50、VGG11 和VGG16.从 表1 中可以看出Resnet 网络的语种识别效果普遍高于VGG 网络,这主要是由于VGG 网络随着卷积层数的增加,梯度消失导致后端的网络层无法对前端的网络层进行调整.而Resnet 网络提出了shortcut 捷径连接,很好地解决了梯度消失的问题.同时在Resnet34 中,当输入特征为LPSEM 时,语种识别率最高,达到了82.4%,同比输入特征为语谱图增加了6%,比输入特征为Fbank 增加了7.2%,比输入特征为MFCC 增加了7.9%.同样当输入特征为LPSEM 时,各个网络的识别率相比于其他特征也是最高的,但在Resnet 网络中随着网络层数的增加,语种识别率并不是随着层数增加而增加的,例如Resnet50 相比Resnet34 下降了2.3%,这可能是网络层数过高,使得网络在训练时出现了局部最优而造成的.
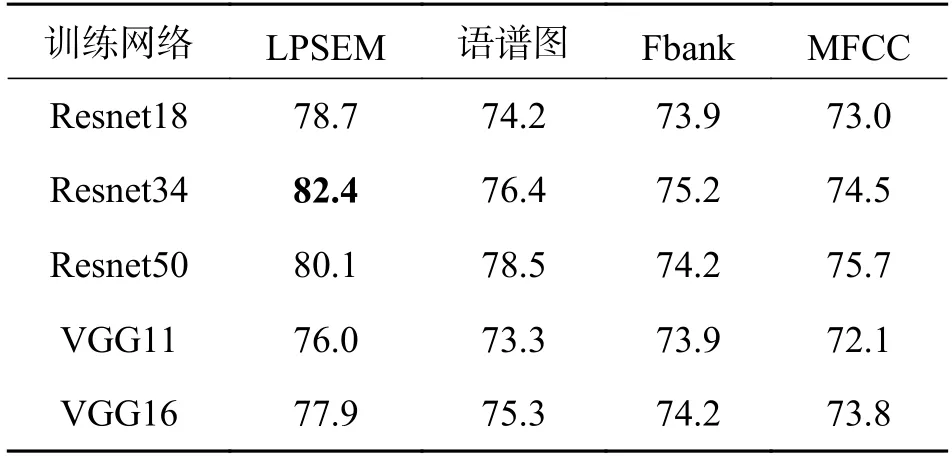
表1 不同网络及特征的语种识别率Tab.1 Language recognition rate of different networks and characteristics %
3.2.2 实验2 在实验2 中,输入分别为1 s 短时语音的Fbank、MFCC、LPSE 的特征向量和Fbank、MFCC、LPSEM 的特征图谱,从表2 可以看出各个特征的原始特征向量的短时语种识别效果普遍低于经过特征数据扩展后的特征图谱,因此在本文中将短时语音的特征向量扩展成为特征图谱有利于短时语音的语种识别.

表2 特征数据扩展对短时语音语种识别率的影响Tab.2 The impact of feature data expansion on short-term speech language recognition rate %
3.2.3 实验3 在实验3 中,输入特征为LPSEM,语音时长为1、5 s 和10 s.训练模型为没有引入时长规整层的Resnet34 网络和引入时长规整层的VD-LID 模型.实验结果如表3 所示.在没有引入时长规整层的Resnet34 网络中,输入时长为5 s和10 s 的广播语音语种识别率分别只有58.7%和56.3%,在VD-LID 模型中,输入时长为5 s 和10 s的广播语音的语种识别准确率为86.6%和94.0%,相比于没有引入时长规整层的Resnet34 网络,两种输入时长的语音分别提高了27.9%和37.7%,并且输入时长为5 s 的广播语音比输入时长为1 s 的广播语音识别率提高了4.2%;输入时长为10 s 的广播语音比输入时长为5 s的广播语音语种识别率提高了7.4%.实验结果表明:当没有引入时长规整层时,由于训练语音与测试语音时长不匹配,会造成识别率大幅度下降;而在引入时长规整层之后,时长规整层将输入长语音分割为若干时长为1 s 的短时语音,从而使得测试特征能够与训练特征相映射,在识别过程中,VD-LID 模型后端又通过计算每段时长为1 s 的短时语音语种识别情况来判别长语音的语种,而时长为1 s 的短时语音语种识别准确率已经达到了82.4%,因此随着语音时长的增加,长语音的语种识别准确率也会随之提高.
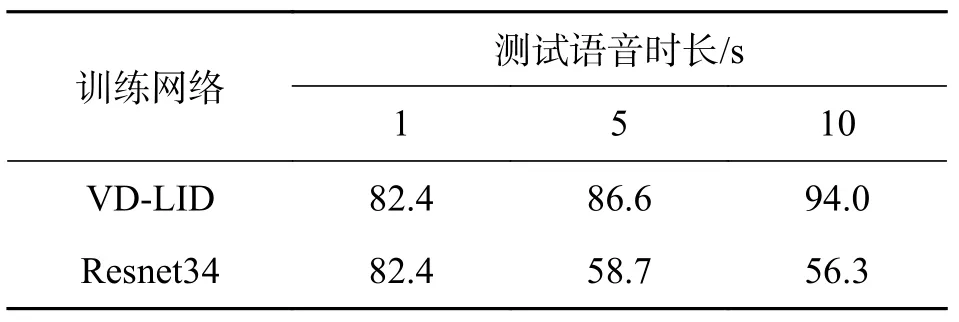
表3 时长规整层对语种识别准确率的影响Tab.3 The impact of the time-length regulation layer on the ac-curacy of language recognition %
4 总结
在语种识别中,针对短时语音信息量较少,语种识别率较低的问题,本文使用了LPSEM 作为特征输入,Resnet34 网络作为分类模型,对时长为1 s的短时语音进行语种识别,其识别率达到了82.4%;针对训练语音与测试语音时长不匹配导致语种识别率急剧下降的问题,本文采用Resnet34 网络结合时长规整层的方法,构建了可以识别不同时长语音语种的可变时长语种模型VD-LID,对比没有结合时长规整层的 Resnet34 网络,VD-LID 将时长为5 s 和10 s 的广播语音的语种识别率分别提升了27.9%和37.7%.但考虑到短时语音的语种识别极易受到噪声的影响,因此,在后续的工作中还需对语音的降噪展开研究.
