基于ERNIE 和双重注意力机制的微博情感分析
2022-05-25周丽华徐广义刘艳超
沈 彬,严 馨**,周丽华,徐广义,刘艳超
(1.昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2.昆明理工大学 云南省人工智能重点实验室,云南 昆明 650500;3.云南大学 信息学院,云南 昆明 650500;4.云南南天电子信息产业股份有限公司,云南 昆明 650040;5.湖北工程学院 信息技术中心,湖北 孝感 432000)
随着微博、知乎、Twitter 等社交平台的快速发展和普及,越来越多的用户可以在这些社交平台上发表自己对某个话题的观点、态度和情感,由此产生了大量带有情感色彩的评论文本数据.微博评论文本属于短文本的范畴,具有口语化、噪声大、网络新词多以及上下文信息有限等特点,因此给微博情感分析带来了巨大的挑战[1].如何针对微博评论文本的这些特点进行情感分析,挖掘其中蕴含的有价值的信息,对于政府决策、产品营销和网络舆情监控等具有重要的意义[2].
情感分析方法主要包括基于情感词典的方法、基于传统机器学习的方法和基于深度学习的方法.基于情感词典的方法实质上是一种“词典+规则”的方法,该方法需要构建一个领域情感词典,并结合人工设计的一些规则来判断评论文本的情感倾向性.例如,赵妍妍等[3]通过构建副词、否定词、情感表情等相关词典来扩充情感词典,在微博情感分类的性能上相比基线方法提高了1.13%.Zhang 等[4]使用扩展情感词典来计算微博文本情感分类的权重,相比基本情感词典提高了近10%.Xu 等[5]构造了一个包含基本情感词、领域情感词和多义情感词的扩展情感词典,并利用扩展情感词典和设计的评分规则进行文本情感分类.然而,基于情感词典的方法严重依赖于情感词典的构建和人工设计的规则,人工干预大,效果较差.
基于传统机器学习的方法通过人工设计特征,并将这些特征映射为多维特征向量来训练一个分类器,性能上较基于情感词典的方法有了很大的提升,常用的分类器有支持向量机(Support Vector Machine,SVM)、朴素贝叶斯(Naive Bayes,NB)和最大熵(Maximum Entropy,ME)等.例如,杨爽等[6]提出一种基于SVM 多特征融合的微博多级情感分类方法,通过融合语义、情感、词性等特征实现了情感的五级分类.Naz 等[7]提出了一种利用SVM分类器和n-gram 特征进行Twitter 情感分析的方法.然而,基于传统机器学习的方法依赖于情感特征的提取和分类器的组合选择,而且不能充分利用文本的上下文语境信息,影响了分类的准确性.
近年来,随着深度学习技术的发展,越来越多的研究者将以卷积神经网络(Convolution Neural Networks,CNN)和循环神经网络(Recurrent Neural Network,RNN)为代表的深度学习模型应用于文本情感分析领域中.Kim 等[8]使用卷积神经网络对电影评论进行情感分类,验证了其性能优于递归神经网络.刘龙飞等[9]使用字级别和词级别两个不同粒度的文本表示作为卷积神经网络的输入,以此来学习句子的特征信息,实验结果表明字级别的原始特征好于词级别的原始特征.Song 等[10]提出了一种新的位置敏感CNN,它可以通过捕获3 种不同语言级别(单词级别、短语级别和句子级别)的位置特征来提高特征提取的能力.滕磊等[11]提出基于胶囊网络的模型(Model based on Asp-Routing and Doc-Routing Capsule,MADC),用来预测评论文本的方面级情感.Abdi 等[12]提出了一种基于长短时记忆网络(Long short-term memory,LSTM)的模型,该模型通过多特征融合的方法将评论情感分类的准确率提高了5%以上.为了充分考虑CNN 和RNN的优点,杜永萍等[13]提出一种基于CNN-LSTM 的情感分类方法,在对含有隐含语义信息的短文本评论情感倾向性识别中取得了不错的效果.Madasu等[14]提出了一种顺序卷积注意递归网络(Sequential Convolutional Attentive Recurrent Network,SCARN),取得了比传统的CNN 和LSTM 更好的性能.由于注意力机制在视觉图像领域中的成功应用,一些研究者也将注意力机制应用到文本情感分析领域中.例如,吴小华等[15]提出了基于字向量表示方法并结合Self-attention 和BiLSTM 的中文短文本情感分析算法.Lei 等[16]提出一种多情感资源注意力模型,该模型可以从三种情感资源(情感词典、否定词、程度副词)中捕获更全面的情感信息,并在电影评论数据集(Movie Reviews,MR)和斯坦福情感树库(Stanford Sentiment Treebank,SST)上提高1%以上的准确率.
在深度学习中,一个关键的步骤是对文本进行向量化[17].Word2vec[18]作为自然语言处理(Natural Language Processing,NLP)领域的词向量工具,通过无监督上下文无关的训练方式,将词映射为低维、稠密的分布式特征向量,使得训练好的词向量中携带着潜在的语义信息.但是Word2vec 无法表示词的多义性.针对这个问题,研究人员提出了各种预训练模型,通过对预训练模型微调,可以提高多项NLP 任务的性能.曾诚等[19]提出一种结合ALBERT预训练模型与卷积循环神经网络(Convolutional Recurrent Neural Network,CRNN)的弹幕文本情感分析方法ALBERT_CRNN,实验结果均优于传统方法.2018 年,Peters 等[20]提出了语言模型嵌入(Embeddings from Language Models,ELMo)算法,该算法采用双向LSTM 语言模型来学习具有上下文信息的词嵌入表示,但是该方法只是将两个方向的语言模型进行拼接,并不是真正意义上的双向建模.同年,Google 的Devlin 等[21]提出了基于Transformer 的双向编码器表示(Bidirectional Encoder Representation from Transformers,BERT)模型,使用具有强大特征提取能力的双向Transformer 编码器,通过遮蔽语言模型(Masked Language Model,MLM)和下一句话预测(Next Sentence Prediction,NSP)两个无监督预测任务来获得预训练模型.2019 年,Sun 等[22]提出了基于知识增强语义表示(Enhanced Representation through Knowledge Integration,ERNIE)模型,相较于BERT,ERNIE 使用更大的中文训练语料,并改进了掩码策略.ERNIE 模型在训练过程中通过对字、短语和实体进行掩码,可以让模型隐式地学习到实体之间的先验语义知识和长语义依赖关系,增强了模型的语义表示能力.
尽管目前的神经网络模型在情感分析中已经取得了巨大的成功,但是情感资源在神经网络中的应用仍存在局限.文献[9,15]虽然针对微博评论文本的相关特点验证了字级别特征更适用于微博情感分析,但是并没有解决多义性的问题.受文献[9,16,23-24]的启发,本文在引入情感资源和注意力机制的基础上,结合ERNIE 预训练模型能够根据上下文语境获取字级别的动态特征表示以及具有更丰富的语义表示能力等优点,提出了一种基于ERNIE 和双重注意力机制的微博情感分析模型.实验结果表明,新模型在COAE2014 和weibo_senti_100k 数据集上的分类准确率分别达到了94.50%和98.23%,同时也验证了将情感资源运用到神经网络中的有效性.
1 ERNIE-DAM 情感分析模型
1.1 情感信息提取评论文本中包含着大量的情感信息,如情感词或者修饰词与情感词的搭配组合等,当情感词被修饰词所修饰时,有可能伴随着整句的情感极性发生变化,如极性反转、加强或者减弱等.修饰词词典一般包括连词、否定词、程度副词等.参考文献[16]构建情感资源库的方法,本文主要将情感词、程度副词、否定词加入到情感资源库中,并通过设定的提取规则从文本中提取出包含的情感信息.设定的提取规则如下:
规则1遍历整个文本,若当前词语是情感词,则将当前词语加入到情感信息集合中.
规则2遍历整个文本,若当前词语是程度副词或者否定词,且下一个词语是情感词,则将二者作为一个整体加入到情感信息集合中,并将情感词从情感信息集合中删除.
规则3遍历整个文本,若当前词语是程度副词,且后面紧依次紧跟否定词和情感词,则将三者作为一个整体加入到情感信息集合中,并将否定词与情感词的整体从情感信息集合中删除;类似的,若当前词语是否定词,且后面依次紧跟程度副词和情感词,则将三者作为一个整体加入到情感信息集合中,并将程度副词与情感词的整体从情感信息集合中删除.
1.2 模型构建本文提出的ERNIE-DAM 模型在纵向结构上包含输入层、特征提取层、特征融合层和情感输出层4 个部分,在横向结构上包含2 个处理通道:基于BLSTM 网络和注意力机制的通道负责提取评论文本的上下文关系特征,基于全连接网络和注意力机制的通道则负责提取评论文本中包含的情感信息的情感特征,并且均采用ERNIE 预训练模型获取文本字级别的动态特征表示.模型的整体架构如图1 所示.
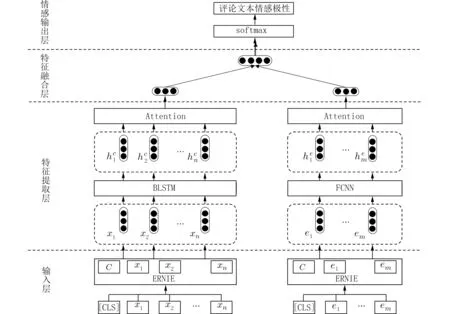
图1 ERNIE-DAM 模型Fig.1 Model of ERNIE-DAM
1.2.1 输入层 输入层包括评论文本及其包含的情感信息.对于一条评论文本,根据1.1 节中情感信息的提取规则,提取出该条评论文本中包含的情感信息.例如,评论文本“我超喜欢三星这款手机”中包含的情感信息为“超喜欢”.将评论文本和情感信息分别按照字粒度进行切分,并在首位置拼接一个分类标志符号[CLS],即X={[CLS],x1,x2,···,xn},E={[CLS],e1,e2,···,em},其中xi和ei分别表示评论文本和情感信息中的第i个字.然后输入到ERNIE预训练模型中,经过ERNIE 前向计算后得到评论文本的特征向量矩阵X和情感信息的特征向量矩阵E:

式中,⊕为拼接操作,n和m分别表示评论文本和情感信息的长度.
1.2.2 特征提取层
1.2.2.1 上下文关系特征 在评论文本中,不仅要考虑序列内部之间的上下文语义依赖关系,还要关注到对于情感分类更加关键的部分,对于重要的部分应该赋予更高的权重.因此采用BLSTM 网络和注意力机制相结合的方法对评论文本的上下文信息进行编码,以获取文本的上下文关系特征.
LSTM 作为循环神经网络RNN 的变体,能够很好地解决RNN 模型在训练过程中存在的梯度消失和梯度爆炸等问题,并且具有较强的长距离语义捕捉能力,在处理序列化文本中得到广泛使用[24].LSTM 神经网络的前向传播计算如下所示:
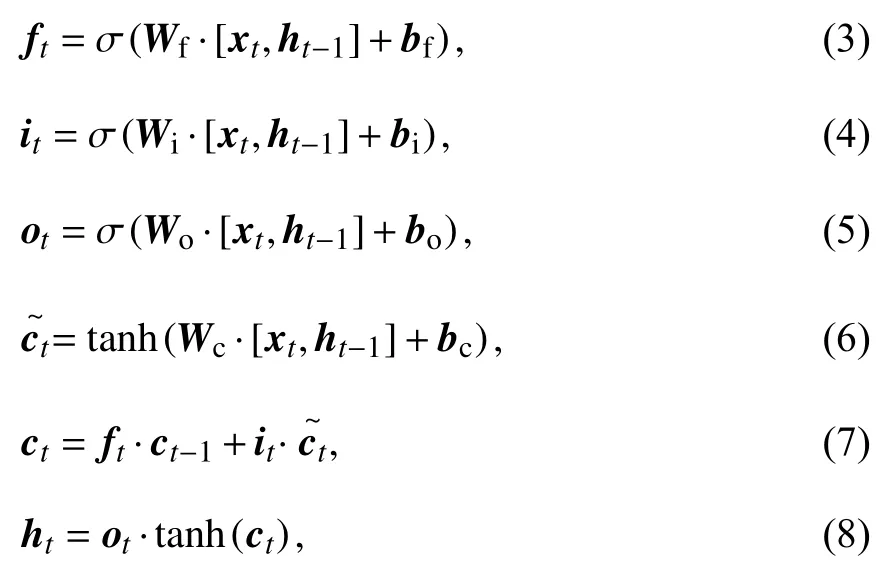
式中,xt为当前时刻的输入,ht−1为上一时刻的外部状态,Wi、Wf、Wo和Wc为权重参数,bi、bf、bo和bc为偏置,σ为sigmoid 激活函数,tanh为双曲正切激活函数,ft表示遗忘门,决定上一时刻的内部状态ct−1中哪些信息应该被抛弃,it为更新门,决定当前时刻的候选状态中哪些信息应该被保留,ot为输出门,决定当前时刻的内部状态ct哪些信息应该输出给外部状态ht.
由于LSTM 只能捕获文本中的正向语义信息,缺乏对逆向语义信息的捕获,因此本文采用BLSTM 来捕获文本中正反两个方向的长距离语义依赖关系.在BLSTM中,某一时刻t的输出状态由正向LSTM的输出和反向LSTM的输出相连接组成:

1.2.2.2 情感特征 在评论文本包含的情感信息中,情感信息之间只是具有情感表示、情感极性的加强和减弱以及反转等功能,不像文本序列中一样存在较强的语义依赖关系[30].同时,评论文本中可能包含多个情感词,不同的情感词对于评论文本的情感倾向性的影响程度也是不一样的.因此采用全连接网络和注意力机制相结合的方法对情感信息进行编码,以获取最显著的情感特征.首先使用两层的全连接网络对情感信息进行编码:
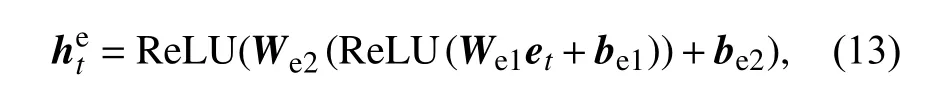
式中,We1、We2和be1、be2为全连接网络的权重参数和偏置.

式中,Ww和bw为权重参数和偏置,uw为softmax函数的权重参数,βt为输入状态的权重.
1.2.3 特征融合层 特征融合层的目的是将上下文关系特征向量和情感特征向量进行融合,从而构造新的特征向量表示.为了简化模型的复杂度和计算量,采用简单的向量拼接方式,将上下文关系特征向量vc和情感特征向量ve沿维度方向拼接,得到最终的特征向量表示v∗,如下所示:

1.2.4 情感输出层 将特征融合层输出的特征向量v∗通过softmax分类器,从而得到模型最终预测该条评论文本属于哪个类别的分类结果,如下式所示:

式中,w为权重参数,b为偏置,为该评论文本属于哪个情感类别的概率分布.
1.2.5 模型训练 在模型训练的过程中,本文使用交叉熵作为损失函数,并通过端到端的反向传播算法(back propagation)来更新网络参数,如下所示:

式中,D为训练数据集,C为情感标签的类别数,y为实际情感类别,为预测的情感类别.
2 实验
2.1 数据集本文选取两个公开的数据集进行实验.数据集1 来自COAE2014 任务2 中文评测数据集,共有7 000 条已标注情感极性的社交评论数据,其中正向评论3 776 条,负向评论3 224 条,本文将数据集随机打乱后按“7∶3”的比例划分为训练集和测试集.数据集2 来自weibo_senti_100k 数据集,共有119 988 条已标注情感极性的社交评论数据,其中正向59 993 条,负向评论59 995 条,本文将数据集随机打乱后按“8∶1∶1”的比例划分为训练集、验证集和测试集.详细的数据信息如表1 所示.

表1 两个数据集的相关信息Tab.1 The relevant information of two data sets
情感资源库包含情感词、程度副词、否定词,如表2 所示.其中,情感词来自大连理工大学情感词汇本体库、知网HowNet 和台湾大学NTUSD,并将三者合并去重;程度副词和否定词来自知网HowNet.在分词过程中,本文将情感资源库作为自定义分词词典,使得文本中的情感信息能够作为一个完整的语言单元存在.

表2 情感资源库Tab.2 The data library of emotion resource
2.2 数据预处理评论文本中存在很多的噪声数据,影响着情感分类模型的性能,因此,在模型输入前需要对这些数据进行清洗,以提高数据的质量.本文采用正则表达式匹配的方法对数据进行清洗,从评论文本中删除URL、@+用户名、转发微博等无意义的数据,只保留中文、大小写字母和阿拉伯数字.由于话题标签hashtag 中一般包含被评论的话题或者对象,于是本文对这部分数据进行了保留.
2.3 参数设置本文使用PyTorch 深度学习框架,所有实验均采用Adam[25]优化器,在训练阶段采用“Early Stopping”法,并选择在测试集上表现最佳的结果作为最终的实验结果.文本最大长度设置为140,情感信息集合最大长度设置为40.数据集1 和数据集2 的batch_size 分别设置为32 和128.在使用传统词向量构建的神经网络模型中,Word2Vec 采用Li 等[26]使用中文微博语料训练好的Chinese-Word-Vectors,词向量维度为300 维,随机初始化
2.4 评测指标文本分类中通用的评测指标有精确率P(Precision)、召回率R(Recall)、F1 值(F1-measure)和准确率A(Accuracy).由于本文使用的两个数据集都比较平衡,所以使用测试集上的F1值和准确率A作为实验结果的评测指标.评测指标定义如下:
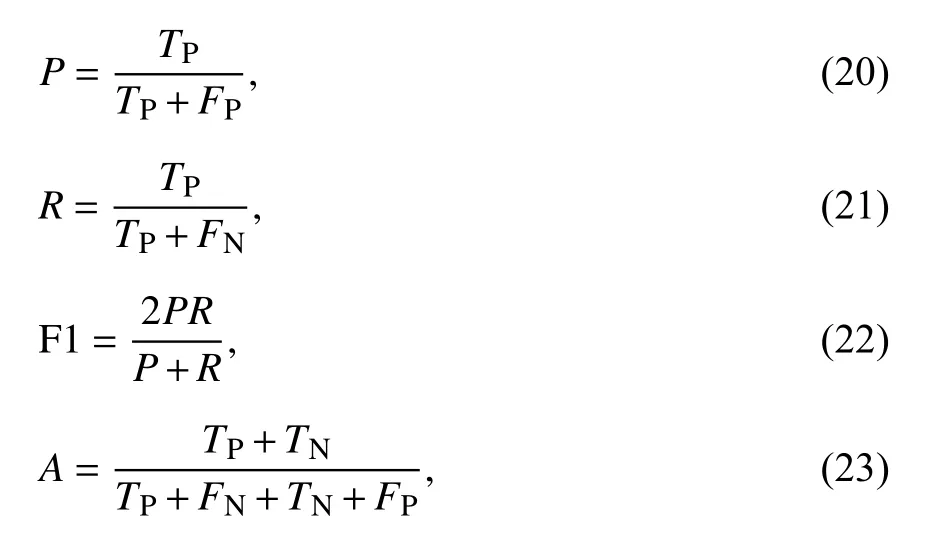
式中,TP表示实际为正向且预测为正向的数量,FP表示实际为负向但预测为正向的数量,TN表示实际为负向且预测为负向的数量,FN表示实际为正向但预测为负向的数量.TP、FP、TN、FN的混淆矩阵如表3 所示.

表3 混淆矩阵Tab.3 Confusion matrix
2.5 实验结果与分析为了验证本文提出的方法的有效性,本文设置了3 组实验.第1 组实验比较不同模型的情感分类性能,其中ERNIE、ERNIEDAM 采用百度发布的中文预训练模型ERNIE1.0来进行文本向量化表示,其余模型均采用Li 等[31]提出的Chinese-Word-Vectors 构建词向量,并在训练阶段进行微调.第2 组实验比较不同词向量工具对本文模型情感分类性能的影响.第3 组实验验证不同情感信息的组合对于情感分类性能的影响.
2.5.1 分类模 型对比实验 FastText:文献[27]提出的文本分类模型,其模型结构类似于Word2Vec中的CBOW 模型,通过对整个句子的词向量和Ngram 向量取平均池化后得到句子表示.
TextCNN:文献[8]提出的卷积神经网络,通过卷积和池化操作得到句子表示.
LSTM:文献[28]提出的长短时记忆网络,取最后时刻的隐层输出作为句子表示.
BGRU/BLSTM:文献[28]和文献[29]提出的门控循环单元和长短时记忆网络的双向变体,拼接最后时刻正反两个方向的隐层输出作为句子表示.
RCNN:文献[30]提出循环卷积神经网络,将BLSTM 模型各时刻的输入和输出拼接之后取最大池化得到句子表示.
BLSTM-Att:文献[31]提出的基于Attention 机制的双向长短时记忆网络,采用注意力机制对BLSTM 各时刻的隐层输出加权求和得到句子表示.
CNN-LSTM:分别采用CNN 提取局部特征和LSTM 提取全局特征后进行拼接,得到句子表示.
ERNIE:取ERNIE 模型[CLS]位置对应的特征向量作为句子表示.
ERNIE-DAM:本文提出的基于ERNIE 和双重注意力机制的情感分析模型.
不同模型的分类对比结果如表4 所示.从表4可以看出,本文提出的ERNIE-DAM 模型在COAE2014 和weibo_senti_100k 数据集上,所有指标都取得了最好的结果.相比FastText、TextCNN、BLSTM、RCNN、BLSTM-Att、Word2Vec-DAM 和ERNIE 模型,ERNIE-DAM 模型在COAE2014 数据集上的F1 值分别提高了8.16%、6.94%、7.28%、6.41%、6.26%、5.28%和1.08%,在weibo_senti_100k 数据集上的F1 值分别提高了3.23%、1.50%、1.33%、1.03%、1.14%、1.01%和0.51%.由此可以看出,相比于其他基于传统词向量构建的神经网络模型,ERNIE、ERNIE-DAM 模型在微博评论文本情感分析任务上具有较明显的优势,也充分说明了预训练模型能够根据文本序列中的上下文语境对同一个词的不同含义进行区分,从而提高情感分类的性能.而基于知识增强的ERNIE 预训练模型由于采用了具有强大特征提取能力的双向Transformer 编码器,并通过对海量数据中的实体概念等先验语义知识进行建模,增强了字的语义表示能力,所以仅仅通过微调的方式就能取得比其他基于传统词向量构建的神经网络模型更好的效果.另外,将基于Word2Vec 构建的DAM 模型与BLSMT-Att 模型进行比较,在两个数据集上的F1 值分别提高了0.98%和0.13%,说明将评论文本中的情感词、程度副词、否定词等情感信息提取出来,通过全连接网络和注意力机制挖掘文本中深层次的情感特征,对于文本的特征向量表示起到情感增强的作用,验证了将情感资源运用到神经网络中的有效性.
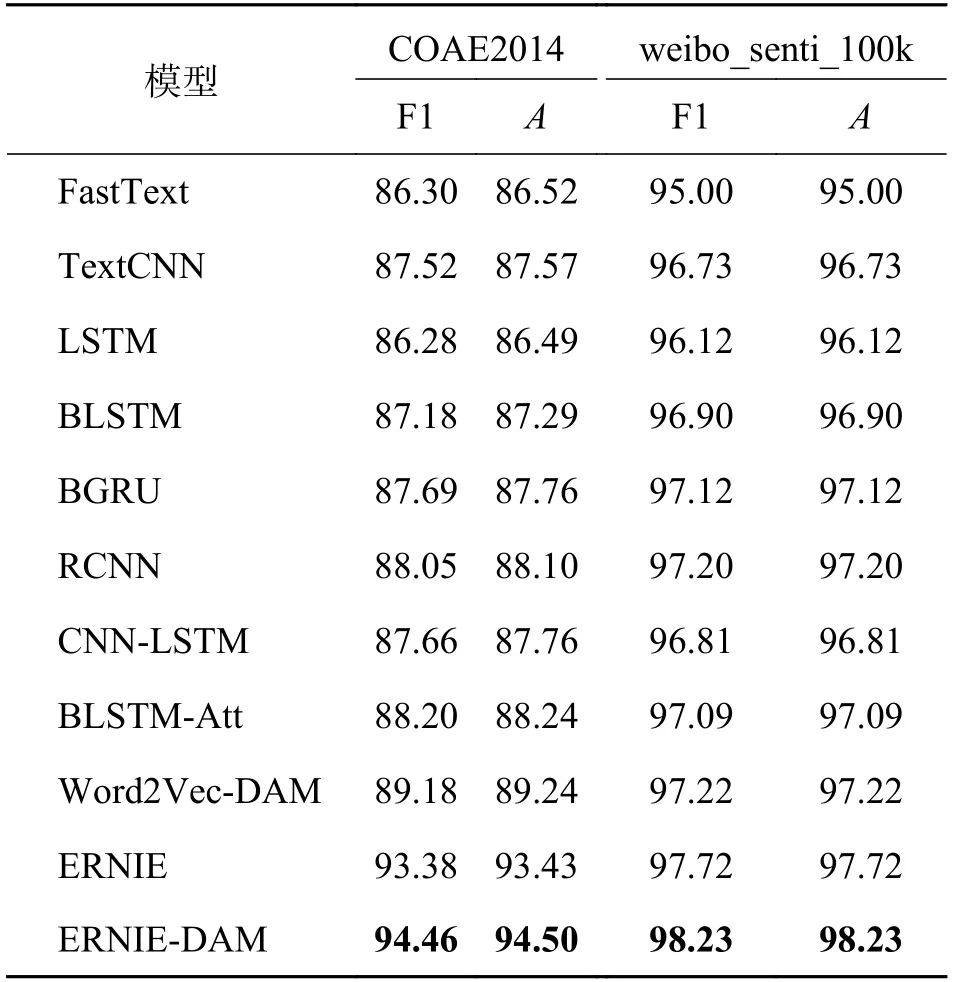
表4 不同分类模型的对比结果Tab.4 Comparison results of different classification models%
另外,本文还将其他基于传统词向量构建的神经网络模型进行了实验对比.BGRU 相较BLSTM在减少一个门函数的基础上,不仅减少了训练时间,而且效果也更佳.相比LSTM、TextCNN 模型,CNN-LSTM 模型结合了CNN 提取文本局部特征和LSTM 提取文本上下文全局特征的优势,性能有进一步的提升.相比BLSTM 模型,BLSTM-Att 模型在BLSTM 神经网络基础上增加了注意力机制,有助于提取出文本中更重要的信息.此外,ERNIEDAM 模型相比ERNIE 模型在微博情感分析中具有更好的表现,证明了DAM 模型能够充分考虑评论文本中的上下文信息以及情感信息中更显著的情感特征,进一步提升模型的性能.
2.5.2 词向量工具对比实验 Word2Vec-DAM:将词使用Cinese-Word-Vectors 词向量进行初始化后,输入到DAM 模型中进行训练.
ELMo-DAM:将词使用ELMoForManyLangs预训练模型转换为词向量以后,输入到DAM 模型中进行训练.
BERT-DAM:采用中文预训练模型BERT 将文本向量化表示后,输入到DAM 模型中进行训练.
ERNIE-DAM:采用中文预训练模型ERNIE 将文本向量化表示后,输入到DAM 模型中进行训练.
基于不同词向量模型的分类对比结果如表5所示.从表5 可以看出,ELMo、BERT、ERNIE 预训练模型相比传统的静态词向量,可以根据上下文语境对文本中同一个词的不同语义表征进行动态调整,解决了传统词向量中存在的一词多义问题,因而各项评价指标均有明显的提升.相比ELMo 采用双向LSTM 语言模型来提取词向量特征,BERT 和ERNIE 采用更强大的双向Transformer 编码器,因此进一步提高了模型的特征提取能力.ERNIE 与BERT 相比,由于对先验语义知识建模,实验结果有明显提升.
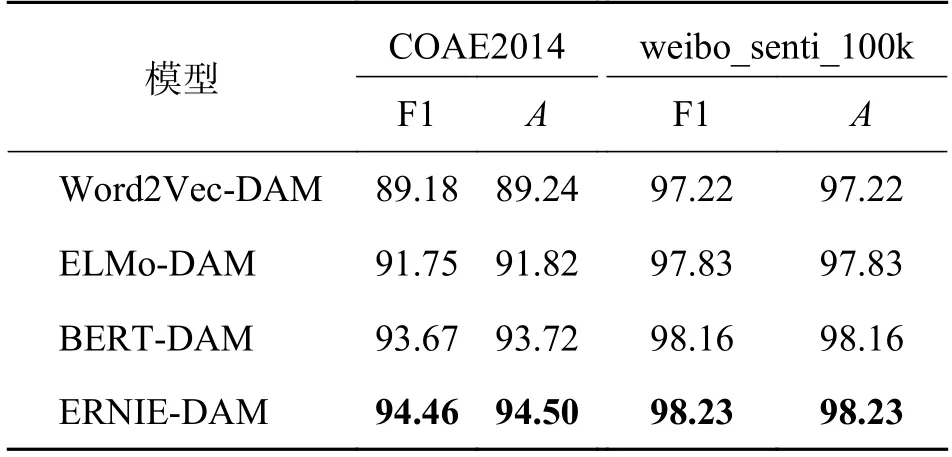
表5 基于不同词向量模型的对比结果Tab.5 Comparison results based on different word vector models %
2.5.3 消融实验 为了验证不同情感信息的组合对于情感分类模型性能的影响,本文进行了消融实验,并选择在COAE2014 测试集上的结果进行对比分析.当不包含情感信息时,本文模型退化为ERNIE-BLSTM-Att 模型,在ERNIE-BLSTM-Att 模型的基础上设置了5 组对照实验,分别是ERNIEBLSTM-Att(不包含情感信息)、EBA+S(ERNIEBLSTM-Att+情感词)、EBA+SN(ERNIE-BLSTMAtt+情感词+否定词)、EBA+SI(ERNIE-BLSTMAtt+情感词+程度副词)、ERNIE-DAM(本文模型,ERNIE-BLSTM-Att+情感词+否定词+程度副词).实验结果如图2 所示.

图2 不同情感信息组合的对比结果Fig.2 Comparison results of different combinations of emotion information
从图2 可以看出,在ERNIE-BLSTM-Att 模型的基础上单独添加情感词时,模型的性能有了提升;当在情感词的基础上单独添加否定词和程度副词时,模型的性能有了进一步的提升,但是程度副词的提升不如否定词的明显.这说明了情感词、否定词和程度副词等先验情感资源的引入可以提高情感分类模型的性能,同时,否定词对于文本情感极性的表现能力要强于程度副词.
3 结语
本文提出一种基于ERNIE 和双重注意力机制的微博情感分析模型ERNIE-DAM.该模型利用不同的注意力机制对评论文本和文本中包含的情感信息进行特征提取,以获取文本最终的特征向量表示.通过ERNIE 预训练模型强大的语义表示能力对文本进行动态特征表示,解决了传统词向量中同一个词在不同上下文语境中表示不同含义的问题.同时,将情感资源和注意力机制相结合的方法能够有效地提高模型捕获文本情感语义的能力,进而提高文本情感分析模型的性能.实验结果表明,本文提出的模型在COAE2014 和weibo_senti_100k 两个数据集上都取得了较好的分类效果.本文下一步的研究工作中,将进一步结合微博评论文本本身的语言学特征,融入表情符号、浅层语义信息和语义角色信息等特征,探究其对模型性能的影响.
