智慧校园可视化平台系统设计
2022-05-21颜杰森
颜杰森
(泉州工艺美术职业学院 党政办信息中心,福建 泉州 362500)
在“互联网+”时代下,以物联网为基础的智慧校园开始逐步进入校园,智慧校园是将智慧教学的环境、资源、服务以及管理进行充分的融合,是对以往的数字化校园进行升级,在教育领域中加入云技术、大数据等物联网技术[1]。目前,各大高校也逐渐开始挖掘校园网内大数据下的隐藏信息,以对校园网内的用户行为进行识别,从而进一步提升学校在教学管理、资源分配、科研、人才培养上的工作水平[2]。校园网与其他网络不同,通常结构复杂且规模较大,其用户主要为学生群体,所以网络的管理就显得更为复杂。通过物联网数据挖掘技术进行该类学生群体的网络行为分析,以更进一步了解学生的生活习惯,使学校能够更好的服务于师生[3]。研究旨在对校园网用户的数据进行挖掘,构建出基于物联网的智慧校园可视化平台。
1 智慧校园可视化平台系统及算法设计
1.1 智慧校园可视化平台系统总体设计
由于校园网数据规模大、维度多,且数据分析的范围较大,为有效提升用户的响应及系统分析的速度,研究应用Hadoop大数据核心框架及开源框架Sqoop与Hive,从四个层次对用户行为分析系统进行平台搭建,如图1所示。

图1 智慧校园可视化平台系统整体架构Fig.1 Overall architecture of smart campus visualization platform system
如图1所示,采集层的工作是对不同数据源进行数据采集,再将数据进行预处理后,由MySQL数据库构建出系统所需的数据仓库;存储层的工作是应用Sqoop在Hadoop的HDFS中导入MySQL中的数据,用于Hadoop进行数据的分析处理;分析层的工作是通过协调分配系统资源来提升MapReduce的计算能力,并在MapReduce执行引擎的基础上进行数据的搜索、计算等操作,以实现对数据的分析;应用层用于展示可视化功能与分析结果,包含数据查询、行为分析、基于数据及分析结果的画像应用[4]。根据校园基础平台的数据、用户行为分析、画像模型及应用等方面,构建智慧校园可视化平台系统的功能模块,如图2所示。
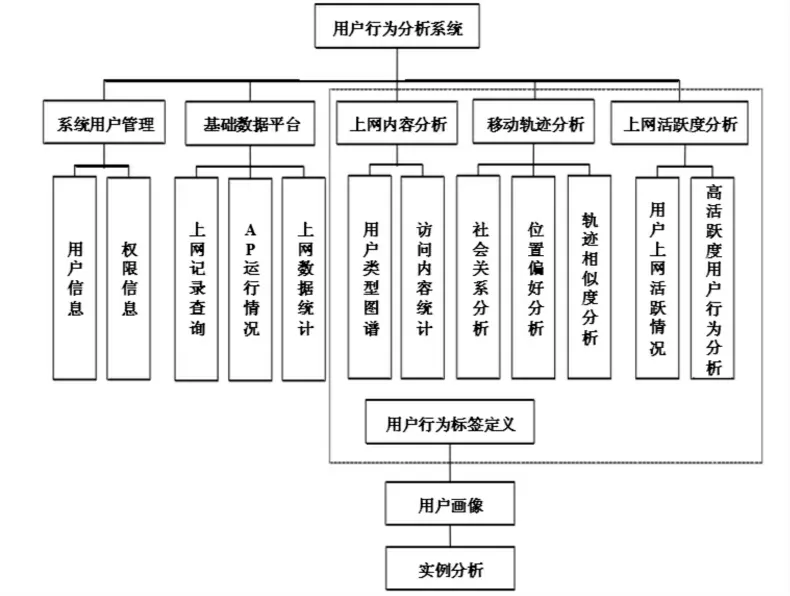
图2 智慧校园可视化平台系统的功能模块Fig.2 Function modules of intelligent campus visualization platform system
在智慧校园可视化平台的构建中,需要同时实现有线网络与无线WLAN的覆盖,包括生活区、教学区等区域。在管理过程中,详细记录校内网络的各项数据,以记录校内网络用户的上网与网络活动情况。此次研究通过对2020年6月15日—6月22日的Dr.Com与NAT日志,以及计费与网管系统的历史数据进行采集,同时将数据存储于MySQL关系型数据库中,最后对这些采集的数据进行分析处理工作,将预处理后的数据存入数据仓库,以备实验与行为分析。由于智慧校园可视化平台需要对大量图表统计进行可视化显示,还要直观展示出AP楼宇的位置与用户的轨迹,研究应用Highcharts与Echarts来展示数据分析界面,如图3所示。

图3 Highcharts与Echarts可视化图例Fig.3 Visualization legend of highcharts and ecarts
由于可视化分为统计与聚类结果可视化。其中,统计可视化包括了曲线图、直方图以及表格的对比,以增强用户对数据的了解程度;聚类结果可视化包括直方堆叠图、环形图以及饼图等方式,以展示出聚类分布的统计结果。其中,直方堆叠图最为符合聚类的结果要求,主要是由于该图为多维度用户上网特征中挖掘出来的,并且在二维展示中还增添堆叠顺序与大小,以及不同的颜色,在可视化研究中具有很大的优势。
1.2 用户活跃度和轨迹相似度算法分析
评价用户上网的活跃度可以从上网的流量、时长以及次数来判断,也就是从用户网络访问情况、上网持续时间和频率来进行活跃度的分析,且三者存在着一定的联系[5]。由于上网次数越多,持续时间也就越长,那么上网流量也就越多,因此可以综合考虑对用户平均上网流速进行分析。在进行用户活跃度分析前,需要对活跃度低的用户进行过滤,以提升分析的准确度。首先对用户上网活跃度公式进行设计,主要是对预处理后的数据进行统计,包括上网流速、次数以及时长,并应用k-means聚类算法评价分类个数在k∈[2,10]时的得分,如图4(a)所示。同时统计两类用户群的上网访问内容,以找出两类用户的上网特征,如图4(b)所示。

图4 校园网用户上网数据聚类与访问内容统计结果Fig.4 The data clustering and access content statistics of campus network users
由图4可知,校园网内两类用户群的主要特征为上网流速与时长,其中分类1主要集中在社交与游戏中,虽然在线时间段,但是期间不断访问网络,使得流量较大;分类2集中在新闻类与社交中,在线时间长,但产生流量小。这也较好的体现聚类结果的正确性。因此,上网活跃度不但要考虑上网频率和时长,还需要对上网流速进行综合考虑,而通常上网频率较高的用户,上网时长也会较长,因此将上网流速与时长作为活跃度的度量因素。
构建用户活跃度公式时,需要保证上网流速与时长在公式中的权重相当,其次只要流速与时长中有一个值异常,则活跃度极小。用户u在时间段T内的活跃度Act(u),如式(1)所示
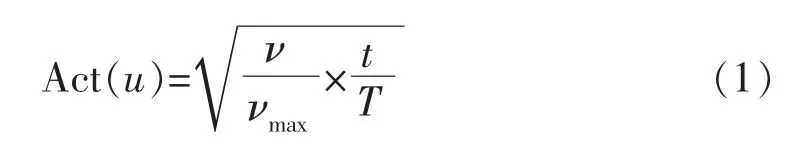
式中:T为用户u活跃时间段,t为u在T内上网的总时长,ν为u在t内上网的平均流速,νmax为网内流速的最大值。
对于用户轨迹相似度的计算,研究应用LCSS优化算法,主要是由于该算法可以较好的表现出轨迹间非连续的最长公共子序列的长度,即轨迹相似程度,因此可以通过该方法判断用户间移动位置序列的相似度,以及位置间停留时长的相似度。位置停留时长序列相似系数c的计算方式

式中:LCSS(u,ν)表示用户u与ν的公共子轨迹序列长度,s为用户u与ν的公共子轨迹序列中的点序列,ti(u)和ti(ν)为用户u与ν在点i上关联AP站点的停留时长。接着将LCSS算法得出的公共子序列长度与c进行综合,得出轨迹相似的有效值。设定m,n分别为用户u与ν的移动轨迹长度,那么公共子序列长度的相似度可以表示为和,且值为0时越不相似,值为1时越相似,再对二者取平均值得出移动位置序列的相似度。
由于在移动位置序列相似度的基础上可以得出位置逗留时长序列相似度,那么为经过LCSS计算后的公共子轨迹序列中的点序列,所以对两个相似度进行相乘,能够得出用户移动轨迹的相似度。LCSS优化算法的用户轨迹相似度计算,如式(3)所示
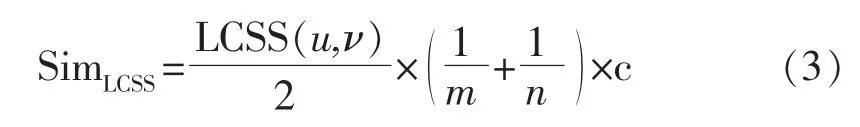
式中:SimLCSS值在区间[0,1]内,相似度越高则值越接近1。在用户逗留时长中引入LCSS算法,不但可以增加算法的优越性,还能够有效提升轨迹相似度计算的准确率。
1.3 校园用户画像模型构建
用户画像的精确构建能够为用户的有效管理及行为预测提供数据基础,而用户画像中标签系统的构建非常关键[6]。标签库为用户标签集合,对用户标签进行集中管理,并采用多维度模式管理标签[7]。通过Dr.Com日志、网管及计费系统获取用户数据,获取数据包括用户访问外网(上网情况)、无线联网(上网轨迹)、访问链接(访问兴趣)等情况。所以将通过这三个方面来对数据源进行分析,再进行用户行为标签的设计,并将网络内用户的基本信息作为用户属性标签。再采用离散化方法对用户数据各个维度进行处理,以得到用户的行为特征与基本属性,并综合多个特征选择方法,通过各种方法对特征进行得分计算,并根据得分排序权重,得出分数最高的n个属性特征。该种优化算法综合多种算法的优势,能够有效提升特征选择的准确率。特征选择的权重设置方法分为5步,一是根据得分排序n个特征;二是根据排序设置特征权重为n,n-1,n-2,…,1;三是应用xgboost模型对该选择方法进行模型训练与测试,并得出F1-score值;四是将特征权重与F1-score值进行相乘,得出特征权重;五是按照特征累加各个选择方法的特征权重,得出各特征的最终权重。
构建用户画像主要包括数据挖掘与用户画像两个阶段,前一阶段主要从多维度挖掘用户数据,并构建标签体系,后一阶段则通过构建标签体系将用户画像分为用户属性与行为画像两个方面,构建用户画像模型,同时输出属性与行为画像,最后通过标签权重来对用户画像进行绘制,模型框架如图5所示。

图5 用户画像模型框架Fig.5 User portrait model framework
引入机器学习算法来构建用户画像模型。由于个体学习器具有一定的缺陷,将学习算法与若干学习器结合,得到一种强学习器。其中,Xgboost算法为优化效果较好的一种提升树模型,其通用性高且计算速度快,所以选择应用该模型来构建二级融合模型,如图6所示。

图6 二级融合模型框架Fig.6 Framework of secondary fusion model
在提出的模型框架中,Stacking应用交叉验证来构建训练集与测试集,使得训练后的模型更稳定,并与多个模型相结合训练元模型,以得到更优的效果。Bagging模型采用了投票法,最终分类结果以得票最多的类别为准,并通过随机采样方法对模型进行训练,所以具有很强的泛化性能。二级融合模型的元分类器为xgboost(XGB),应用多种算法作为Stacking的弱分类器,在训练Stacking后得到XGBTree模型,并将其所有特征作为第二层的输入,同时与Bagging算法结合,进一步提升分类的泛化力与准确率。
2 智慧校园可视化平台算法测试分析
2.1 用户活跃度和轨迹相似度算法测试
对校园网内用户的上网数据进行采集,并对用户的平均上网流速与总在线时长进行统计,通过式(1)计算出用户上网活跃度,如图7所示。图7中散点的颜色深浅度表示活跃程度,颜色越深表明活跃度越高。
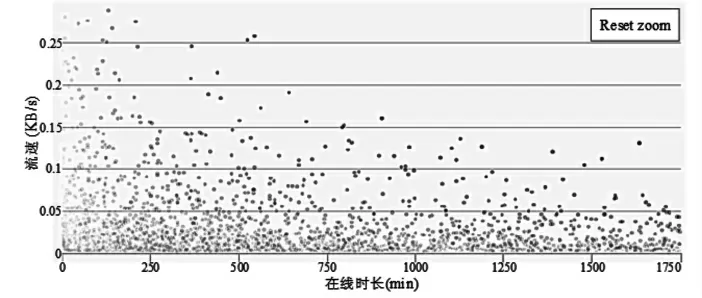
图7 计算后用户上网活跃度分布状况Fig.7 Distribution of users'online activity after calculation
由图7可知,时长与流速越远离坐标值0的点颜色越深,越接近则颜色越浅。通常流速与时长都比较高的用户上网活跃度较高,二者一高一低时,均在中等的用户才具有较高的活跃度,这也符合上网活跃度的概念。
为了验证基于LCSS的相似度算法聚类的结果是否有效,应用相似度聚类分析方法对2020年6月15日校园网用户上网轨迹序列进行分析。由于优化前簇内最多有12个成员,并且有72个簇类的成员只有2个;而优化后的聚类算法簇内最多有5个成员,并且有123个簇类的成员只有1个,反映出用户轨迹行为具有一定的复杂性。以实际用户为例,比较用户间的聚类结果,如图8所示。其中横、纵坐标分别表示不同类别的用户名、逗留总时长,不同颜色代表不同连网的地点,从下到上为用户移动轨迹的先后地点。

图8 基于优化后算法的用户聚类结果Fig.8 User clustering results based on the optimized algorithm
用户05010的轨迹为“图书馆(80.9)→教学楼1(100.1)→体育馆(62.8)”;用户03553的轨迹为“体育馆(113.7)→图书馆(2.7)→体育场(54.1)→体育馆(123.7)”,用户20170906的轨迹为“图书馆(714.4)→体育场(3.1)→体育馆(38.8)”。05010从图书馆到体育馆,在图书馆与教学楼1中的逗留时间较长,说明了教学楼1是其主要目的地之一,因此可以看作与用户03413、jhw106为相同类别;而03553在图书馆停留不到3分钟,反映出该用户可能只是路过该地,因此可以看作与用户01555为相同类别;其他用户也分别找到了属于自己的类别。因此,优化后的用户相似度算法更能为精确,能够较好的度量移动轨迹相似性。
2.2 校园网用户画像模型测试分析
实验数据集采用 sklearn.datasets.base下的load_breast_cancer,包括569条数据记录与30个特征,将前400条作为实验训练集,其余169条作为测试集,并选取600个用户的上网数据,其中用户特征属性包含位置偏好、社会属性、活跃度、访问频率和兴趣,以及上网的次数、流量、时长,同时将60%的数据作为训练集,剩下的平均分为验证集与测试集。本次研究将应用混淆矩阵来获取分类评价的结果,评价标准为准确率、精准率、召回率、F1-score。
首先验证特征选择算法,分别应用基于决策树特征选择模型、方差以及卡方检验来进行特征选择对比,再通过xgboost算法来分类数据,通过F1-score得分来判定算法对分类的有效性。
如表1所示,对比不同特征选择算法的实验结果后,可以看出特征选择算法的分类结果准确度较高。再应用特征选择算法对画像模型的有效性进行验证,主要预测用户角色(教职工与学生)与性别这两个标签,预测结果如图9所示。

表1 对比不同特征选择算法的实验结果Tab.1 Comparison of the experimental results of different feature selection algorithms
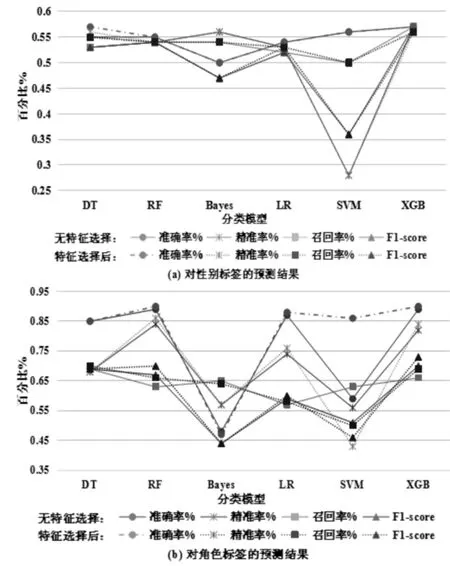
图9 对性别、角色标签的预测结果Fig.9 Prediction results of gender and role tags
由图9可知,性别、角色标签在进行特征选择后的预测效果明显优于无特征选择,反映出训练模型在训练前进行特征选择,能够有效提升最终分类预测的准确性。其中,XGB算法的分类效果优于其他算法,因此将xgboost算法融入用户画像模型中,以作为Stacking的元分类器,并将XGBTree作为Bagging模型的基树。再比较Stacking融合后的模型与单个模型的F1-score值,结果如表2所示。

表2 比较两种集成模型预测的准确率Tab.2 Compares the prediction accuracy of the two integrated models
由表2可知,对于标签预测的准确率而言,集成模型明显优于简单分类器,同时二级融合模型的准确率在一级Stacking的基础上又提升了3%,因此研究提出的融合模型能够增强用户标签的预测准确率,使用户画像的准确率进一步提升。
3 结论
此次研究应用物联网技术,在智慧校园建设领域设计可视化平台系统及优化算法,并对提出的算法进行了测试分析。结果显示,优化后的用户相似度算法更能为精确,能够较好的度量移动轨迹相似性;提出的特征选择算法的分类结果准确度较高,优于其他算法;集成模型的标签预测准确率明显优于简单分类器;训练模型在训练前进行特征选择,能够有效提升最终分类预测的准确性;二级融合模型的准确率在一级Stacking的基础上又提升了3%。因此本次研究提出的融合模型能够增强用户标签的预测准确率,使用户画像的准确率进一步提升。
