基于改进YOLOv3的遥感图像目标检测算法
2022-05-18梁明辉尹衍伟李小兵和圆圆秦兰瑶
雷 亮 梁明辉 尹衍伟 李小兵 和圆圆 秦兰瑶
(重庆科技学院 智能技术与工程学院,重庆 401331)
0 前 言
近年来随着人工智能技术的不断发展,基于计算机视觉的目标检测方法在无人驾驶、工业制造、智慧医疗等领域得到了广泛应用,并产生了巨大的商业价值。无人机(UAV)是一种用无线电遥控的小型不载人飞机,具有灵活、快速、经济等特点,常用于安防、交通、农业等领域[1]。无人机搭载目标检测技术成为当前国内外学者的研究重点,但无人机拍摄的角度和高度不固定以及机体姿态变化大,这给无人机图像的目标检测造成了极大的挑战。
目前学术界已出现许多成熟的目标检测算法,如 YOLO[2]、SSD[3]等。但基于遥感图像的目标检测起步较晚,早期的算法主要基于先验知识进行特定目标检测。Lowe、Sirmacek等人通过采用SIFT特征提取建筑物模板来进行城市建筑物检测[4-5]。Niu等人使用几何形变模型提取高速公路轮廓并进行车辆检测,但只针对特定目标设计算法,在无人机遥感图像的目标检测中存在明显的局限性[6]。近年来随着机器学习技术的发展,出现了基于传统机器学习的检测方法。Tao等人通过提取图像的 SIFT 特征来进行遥感飞机检测[7]。Freund、Aytekin等人采用AdaBoost算法识别机场跑道,并根据跑道位置定位机场位置,但通常无法达到很好的效果[8-9]。如今,基于卷积网络的检测方法成为应用最广泛的方式。Tang等人将R-CNN算法引入遥感领域并取得了不错的效果[10]。Yang等人将One-Stage算法应用于遥感目标检测,但其对微小目标的检测能力较差[11]。
为了提升算法对遥感图像中微小目标的检测能力,本次研究基于YOLOv3算法,将公开数据集VisDrone2019[12]中的行人和车辆作为训练和检测的目标,调整训练策略,进行针对性训练。针对遥感图像中小目标数量多、正负样本比例失衡等问题,通过修改损失函数的权重来平衡正负样本的数量;针对遥感图像中目标尺度变化大等问题,通过加入多尺度训练来提高对同一目标尺度变化的检测能力;针对标签之间的相关性,通过引入标签平滑策略来提高模型的泛化能力。在VisDrone2019公开数据集中进行的实验结果表明,该算法具备较好的检测性能,基本能够对遥感图像进行实时准确的目标检测。
1 基本理论
1.1 YOLOv3网络
YOLOv3是经典的One-Stage目标检测模型,采用Darknet53作为主干网络(见图1)。

图1 YOLOv3网络结构
Darknet53网络由5个残差模块构成,每个残差模块由数量不等的残差单元组成,2个 DBL 单元进行残差连接构成基本的残差单元(见图2a)。其中,每个 DBL 单元由1个1×1或3×3的卷积层、归一化层和 Leaky ReLU激活函数组成(见图2b)。使用残差模块能够在加深神经网络深度的同时有效防止信息丢失和梯度消失。Darknet53网络使用5个步长为2的卷积层来缩小特征图尺寸,并输出最后 3个不同尺寸的特征图进行检测。
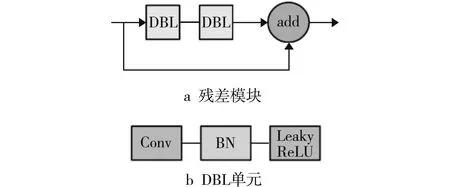
图2 Darknet53网络结构
1.2 训练策略
设计并训练模型后,需要通过验证集来衡量模型的效果。模型的准确率除了与其自身有关外,还与训练过程中的参数密切相关。好的训练策略会大大提高模型的检测精度。
常见的训练策略包括:(1)训练过程中的梯度优化,如梯度裁剪[13]、正则化等;(2)模型学习率的优化,如热启动、学习率衰减策略等;(3)模型输入数据的优化,如标签平滑、多尺度训练等[14]。
不同的模型需要不同的训练策略,不合适的训练策略不仅会使模型变得臃肿进而影响推理速度,而且会降低模型的检测精度。因此,不同应用场景的模型需要不同的训练策略[15]。
针对数据集中的小框与大框数量差距大等问题,修改YOLOv3损失函数中的坐标损失权重,以减少正负样本不平衡带来的影响。修改后的损失函数包括3个部分:坐标损失Lbox、置信度损失Lconf和分类损失Lcls。
损失函数L的计算公式如式(1)所示:
L=1.5(2.0-twth)Lbox+Lconf+Lcls
(1)
式中:tw——真实边框的宽度;
th——真实边框的高度。
坐标损失Lbox的计算公式如式(2)所示:
Lbox=Lxy+Lwh
(2)
式中:Lxy——中心坐标损失;
Lwh——宽高坐标损失。
中心坐标损失Lxy的计算公式如式(3)所示:
(3)
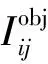

宽高坐标损失Lwh的计算公式如式(4)所示:
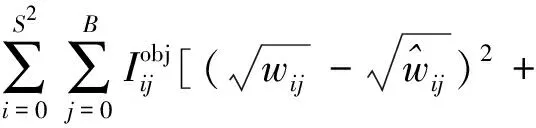
(4)

置信度损失Lconf的计算公式如式(5)所示:
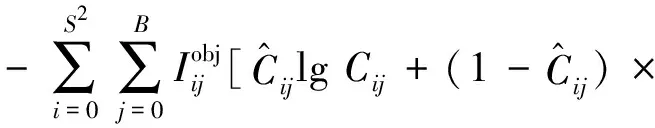
(5)
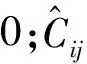
分类损失Lcls的计算公式如式(6)所示:

(6)
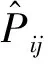
2.2 标签平滑
通常情况下,机器学习的数据集中存在一些错误的标签,而这些标签会直接影响预测结果。本次研究加入标签平滑策略,使神经网络不会“过于相信”某个标签。标签平滑是一种对分类器层进行正则化的机制,称为标签平滑正则化(LSR)。加入标签平滑机制后,标签取0~1的一个概率。
对于标签yk,标签平滑计算公式如式(7)所示:
(7)

c——权重;
μk——均匀分布变量。
2.3 多尺度训练
在VISDrone2019数据集中,有95%是中小目标,且由于无人机拍摄位置不固定,同一目标在不同图像中的尺度也不尽相同,这对模型检测物体大小的鲁棒性提出了更高的要求。当基础网络生成的特征图比原图小数十倍时,会严重损失小目标的特征信息,使其不易被检测到;而当输入图像的尺寸变大时,特征信息保留的更多,但也会影响模型的推理速度。因此,可以引入多尺度训练来平衡两者之间的关系。多尺度训练是提升精度最有效的方法之一。
多尺度训练流程如图3所示。本次研究在训练过程中设定了{512,608,640,672,704,736,768,800}等8种尺度的图像。在每个Batch的所有图像进行训练之前,随机选择1个尺度的图像输入模型。
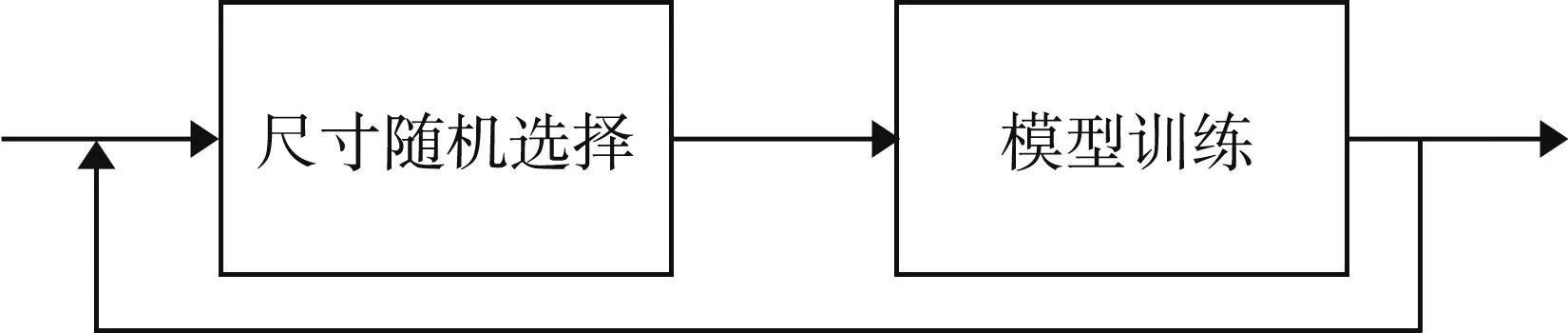
图3 多尺度训练流程
3 模型训练
操作系统为Ubuntu 18.04,深度学习框架为PaddlePaddle 2.1.2,CPU为4核,内存为32 GiB,GPU为NVIDIA Tesla V100。
3.1 数据集制作
VISDrone2019是2019年ICCV研讨会目标检测挑战赛提供的一个大型无人机捕获数据集,包括10 209张图像(7 019张用于训练,1 610张用于验证,1 580张用于测试),其中包含了大量的注释信息。以训练集为例,共包含349 163条注释信息,平均每张图片包含50条注释信息。无人机拍摄的数据集中,行人和车辆等物体的标注框非常小,其中,小目标物体占61%,中目标物体占34%,大目标物体仅占5%。该数据集在多种场景下,跨越多个城市,包括晴天、阴天、白天、灯光条件不同的夜晚等情况。数据集主要检测9个类别(见表1),不同情况下的样本图像如图4所示。

表1 数据集主要检测类别信息

图4 数据集中不同环境下的样本图像
3.2 训练过程
本次研究主要针对中小目标进行检测,YOLOv3算法的锚框并不适用。因此,采用K-means聚类方法预先设定输入网络图像大小为800×800,生成9个适用于VISDrone2019数据集的锚框:[7,14]、[11,30]、[21,20]、[19,50]、[37,34]、[36,81]、[64,55]、[79,115]、[146,168]。
分别对原YOLOv3算法和改进YOLOv3算法进行训练,均使用Momentum优化器,设定动量因子为0.9,加入L2权重衰减正则化,以防止过拟合,正则化系数为0.000 5。训练阶段,初始学习率为2×10-4,训练轮数为300 epoch,每5个epoch评估 1次,学习率衰减系数为0.1,在第240 epoch和270 epoch时将学习率衰减为2×10-5和2×10-6;设置梯度裁剪策略,系数为0.1。训练开始时设置Warm Up,在第4 000 steps时使学习率上升为2×10-4;随机使用随机裁剪、图像翻转、归一化、随机填充等操作对每幅图像进行处理;原YOLOv3算法的输入图像尺寸为608,改进YOLOv3算法采用多尺度训练,尺寸为{512,608,640,672,704,736,768,800}。
4 结果分析
4.1 评价指标
准确率(p)是指预测出的所有目标中正确的比例,计算公式如式(8)所示:
(8)
式中:NT——正确检测出的目标数量;
NF——错误检测出的目标数量。
本次研究主要涉及p、p50、p75等3个指标。其中,p是指在IoU为0.50~0.95、步长为0.05设置下的平均准确率;p50是指在IoU为0.50设置下的平均准确率;p75是指严格模式下的平均准确率。
召回率(r)是指被正确识别的目标占总目标数的比例,计算公式如式(9)所示:
(9)
式中:N0——没有检测出的目标数量;
r——IoU为0.50~0.95、步长为0.05下进行测试的召回率。
4.2 结果分析
准确率变化曲线如图5所示,模型在第50 epoch时开始逐渐收敛,准确率为19.9%。
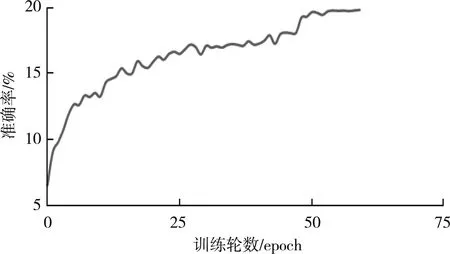
图5 准确率变化曲线
改进YOLOv3算法测试结果如图6所示。由图6 可知,改进YOLOv3算法在晴天、阴天及逆光条件下的傍晚和光照不充足的夜晚都可以达到较好的检测效果,除一些极小目标和姿态严重变形的行人未能检测到。

图6 改进YOLOv3算法测试结果
原YOLOv3算法与改进YOLOv3算法结果对比如表2所示。由表2可知,改进算法的p、p50、p75分别为19.9%、37.8%、19.0%,相较于原算法分别提高了7.2%、13.5%、6.6%。另外,改进算法对中小目标检测的准确率也有所提高,说明修改损失函数和加入训练策略有效。

表2 算法结果对比 %
5 结 语
本次研究在深入了解YOLOv3算法的基础上,对于遥感图像中的目标检测问题提出了具有针对性的优化策略,通过加入多尺度训练和标签平滑策略来提高模型的特征提取能力和泛化能力,修改损失函数来平衡遥感图像中的小目标数量过多等问题。训练结果表明,改进YOLOv3算法的准确率和召回率都有显著提高;同时,能够基本实现多种复杂天气环境下遥感图像中的微小目标检测。但该算法对极小目标和形变较大目标的检测能力仍然不足,存在漏检、误检等现象,还需针对网络特征提取结果作进一步优化。
