煤的发热量预测方法优缺点分析及展望
2022-05-16陆婷婷杨小民霍国锋
陆婷婷 杨小民 霍国锋
(华电国际电力股份有限公司奉节发电厂,重庆 404600)
目前,大部分电厂煤的发热量测定是借助氧弹筒量热仪测量反应物与生成物的焓差计算,这种实验测定方法具有很高的精度。但实际测定的煤样需要经采样、制样及化验等处理流程,测定过程复杂,结果耗时较长,不能很好地满足煤炭生产、利用等环节的需求。为了解决上述问题,越来越多的学者通过建立煤的发热量模型,简单、快速地得到发热量数据,但是精度和通用性还存在一定局限性。本文综述了目前常用的煤的发热量预测方法,并就目前存在的问题进行了分析。
1 发热量预测线性模型
1.1 线性回归分析
回归分析是一种数量统计方法,通过对大量数据进行分析处理,评估各个变量之间关系的强度,从而估计因变量与一个或多个自变量之间的关系,建立回归方程。线性回归分析方法大致步骤如下:
(1)确定变量。对变量x1,x2,x3…xp作n次检测,得到检测值为xi1,xi2,xi3…xip,yi,i=1,2,3 …n。
(2)建立数学模型。线性回归的数学模型可建立为:
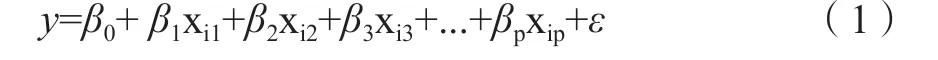
式中:i=1,2,3 … n;β0,β1,β2,β3…βp是相关线性回归系数;ε是均值为0、方差为σ2(σ> 0)的随机误差。
(3)相关分析。求线性回归模型可以利用Excel、MATLAB 及SPSS 等软件快速准确计算回归系数β0,β1,β2,β3...βp的数值,建立所需的回归方程。
陆新科[1]依据所用的煤的特点,忽略挥发分、硫分对发热量的影响,建立了发热量关于灰分、全水分的二元线性回归方程。唐成亮[2]考虑了多种影响因素,建立了燃煤低位发热量与工业分析、元素分析的多元线性回归方程。该模型的最大偏差为2.8%,平均偏差为0.97%,较传统经验公式预测准确度较高、误差较小。
1.2 其他线性方法
除了最常用的线性回归法,还有其他建模方法:闵凡飞等[3]利用灰色系统理论对数据信息容忍性强等特点,仅使用煤灰分、水分两种数据建立了GM(0, H)灰色预测模型。结果证明GM(0, H)模型对煤的发热量预测具有很高的拟合精度。申国民[4]利用统计方法提出了查表计算法。这种方法省略了计算过程,只需通过灰分、全水分结果便可查到煤样的收到基低位发热量。
2 发热量预测的非线性模型
2.1 多元非线性回归法
非线性回归建模类似于线性回归建模,两者都是研究自变量和因变量之间的关系。但是非线性模型的建立比线性模型更复杂,因为函数是通过一系列的反复试验的近似(迭代)创建的。二次回归的步骤如下:
(1)建立二次回归方程。设y为因变量,x1,x2…xn为自变量,a0,a1…an;a0,a12,a23…an-1,n;a11,a22…an,n为未知参数,建立二次回归方程:

(3)求出未知参数。以最小化目标函数为优化目标,利用MATLAB 与SPSS 等软件可以快速求出未知参数值,从而建立所需的二次回归方程。
王江荣等[5]通过引入三角模糊数来弥补工业指标之间分类界限不明显的缺点,提出了一种基于三角模糊数非线性回归模型。最终模型预测的非线性拟合优度值为0.983 8,均方误差为0.447 3,平均相对误差为0.020 3。
2.2 基于机器学习非线性模型
2.2.1 随机森林算法
随机森林算法是一种包含集成学习的机器学习方法,其中包含多棵决策树,这些决策树共同组合解出复杂问题,实现高精度的预测输出。由于整个预测处理流程和数据处理方式比较简单,随机森林算法拥有训练时间少、对数据依赖性小等优点。随机森林算法的算法流程可分为以下几步(如图1):

图1 随机森林算法
(1)从训练集中随机选择n个数据点,即n个数据子集;
(2)构建与所选数据点(子集)相关联的决策树;
(3)通过测试集对每棵决策树预测结果进行投票,去掉票少的决策树;
(4)重复上述步骤,直至有足够多可用的决策树;
(5)取平均值作为预测结果。
韩学义[6]使用随机森林算法拟合出的模型中各个元素权重值得出了对煤发热量影响最重要的参数为固定碳含量和灰分,并且证明了固定碳含量对发热量的影响具有较强的非线性。为了进一步提高算法实用性,作者还利用随机森林算法预测了煤中的碳含量,预测结果的误差达到了2.3%以下。
2.2.2 人工神经网络
人工神经网络是一种模拟生物神经网络的建模技术,被广泛地使用在了各种建模困难的场景中。人工神经网络在经过训练后能够从代表性的数据中构建出复杂的非线性映射结构,与回归分析相比,人工神经网络具有更强的非线性分析和预测能力。
(1)BP 神经网络
BP神经网络是指反向传播神经网络,由输入层、隐含层、输出层三层组成。其中输入层用于接收训练数据,隐含层用于执行计算以确定数据关系,输出层用于得到最终输出结果。BP 神经网络能够不断调整隐含层权值来逼近最小误差,具有强大的自适应、非线性映射能力。构建BP 神经网络的流程可分为以下几步(如图2):

图2 BP 神经网络算法
① 输入层通过预设协议接收数据x;
② 信息前向传递传入隐含层处理;
③ 隐含层依据权值将数据处理后传给输出层;
④ 输出层计算误差,误差反向传递修改隐含层权值;
⑤ 重复以上步骤,直至输出误差在允许范围内。
曹建波等[7]利用七个工业分析参数作为输入,建立了发热量的BP 神经网络预测模型,预测的相对误差最小能够到达0.039%。
(2)RBF 神经网络
RBF 神经网络是指径向基神经网络,其结构与BP 神经网络相似,但RBF 神经网络隐含层只有一层,没有反向传递调整权值过程。RBF 神经网络隐含层采用输入与中心向量的距离作为基函数,拥有更好的模型泛化能力,网络收敛速度更快。如图3。
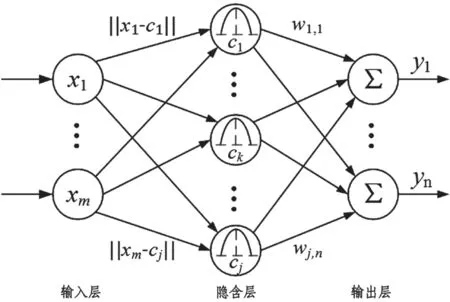
图3 RBF 神经网络算法
于海华等[8]利用挥发分、灰分、分析水为输入,以格林函数为激活函数建立了RBF 神经网络预测模型,最终结果证明训练后的RBF 神经网络模型发热量预测精度最高能够达到98%。雷萌等[9]为进一步提高RBF 神经网络预测精度,引入了模糊聚类对输入样本分类,并根据分类结果分别建立RBF 神经网络模型。这种预处理手段减少了预测的误差,相对误差能够控制在0.5%~2.5%之间。
2.2.3 支持向量机
支持向量机是一种用于分类、回归的机器学习算法。与神经网络相比,支持向量机收敛速度更快,易于获得全局最优解。为了提升工业分析数据对煤发热量的预测精度,谭鹏等[10]建立了基于支持向量机的煤质发热量预测模型。其所建立的模型可以快速、可靠地预测出煤的发热量,平均相对误差最低可达到2.16%。为了减少参数对训练集的依赖,江文豪等[11]在支持向量机中加入遗传算法进行参数寻优,用这些参数进行训练的向量机相比常规的向量机模型拥有更高的预测精度。
3 讨论
3.1 现状分析
从前文及表1、表2 可以总结出,良好的预测算法应该满足以下3 个要求:

表1 预测算法总结

表2 各文献对比总结
(1)精确。能够在可允许误差范围内准确预测出煤的发热量。
(2)快速。预测速度快,能满足生产使用要求。
(3)简单。预测算法简单、收敛快。
3.2 目前存在问题
(1)预测精度不足。由于煤的发热量与工业分析组分之间是非线性关系,使用线性模型预测的精度普遍不高,并且需要经常预测结果中出现的处理异常值。非线性模型能够较好拟合发热量预测中的非线性性质,但容易陷入局部最优,并且为了保证预测精度,过程中还需要大量的维护。
(2)煤种间差距较大,标准不统一。由于煤种、矿区等的不同,煤的发热量并不能简单的用统一因变量表示。
3.3 可能的解决方法
(1)基于大数据的算法改进。无论是因变量的选取还是机器学习的模型训练,都需要大量的数据作为参考。建立煤发热量数据库,使用大数据分析方法来确定预测自变量选取标准,排除对发热量影响较小的自变量,进而统一预测标准,降低预测算法复杂程度。利用数据库还可以对机器学习模型进行不断的训练,使预测精度不断提高。
(2)深度学习算法。基于深度学习的数据驱动算法正在逐渐兴起,并且展现出强大的模式识别和预测能力。足够数量的样品测试和训练可以使一个深度学习模型掌握不同种类煤的特点,预测出不同种类的煤发热量。深度学习模型能自动在不同的预测模式之间切换,而不需要像常规预测建模方法考虑泛化和收敛能力,在精度和通用性上拥有独特的优势。
4 结论及展望
(1)非线性的预测方法越来越多,非线性预测模型正逐渐取代传统的线性模型。一方面是因为随着生产要求提高,线性模型的预测精度已经不能满足实际需要;另一方面随着非线性建模理论的完善,非线性模型预测的精度普遍高于线性模型。
(2)机器学习能够很好地建立非线性模型,还拥有一定泛化能力,能够自适应不同的样本数据。
