基于邻域感知图神经网络的会话推荐
2022-05-15何倩倩孙静宇曾亚竹
何倩倩,孙静宇,曾亚竹
太原理工大学 软件学院,山西 晋中030600
互联网的发展和普及给人们生活、工作带来了极大的便利,但与此同时人们不得不面对数据量激增导致的信息过载现象。推荐系统能够根据用户的历史交互和兴趣偏好设置等信息推荐合适的内容,有效缓解了信息过载问题。然而在实际应用中,用户资料往往是不可知的,因此出现了基于会话(session-based)的推荐[1-2]。
会话(session)指的是用户在一段时间内与项目交互的记录,例如用户30 min内连续点击的物品。会话推荐根据匿名行为序列预测用户下一个可能感兴趣的项目,从而产生有效的推荐。推荐的关键是根据会话序列评估项目或产品之间的关系,而序列中可利用的信息是有限的:(1)会话中的用户通常是匿名的。由于信息保护和新用户等影响,用户身份和偏好设置几乎不可用;(2)序列中仅包含用户的点击和购买行为。这些交互数据不等价于用户的主观意见(如用户评价和评分等),根据客观的交互行为间接推测用户兴趣是有难度的。因此仅通过当前会话信息不足以准确预测用户真实的兴趣偏好,如何发现和利用更多会话信息捕获用户隐含兴趣是推荐的难点。
用来做序列推荐任务的方法中表现较好的一类是图神经网络(graph neural network,GNN)模型[3]。GNN模型当前的研究主要是利用会话内项目之间交互和转移关系捕获用户兴趣,进而实现推荐任务。但仅利用当前会话不仅缺乏对物品间全局关系的捕获和利用,无法捕获有效的协同信息,还忽略了会话之间用户兴趣的相关性,难以表现出良好的性能。实际上会话之间不是独立存在的,邻域信息往往是有价值的补充信息,引入不同会话中的邻域信息可以辅助预测用户的下一个行为。因此,本文提出基于邻域感知图神经网络的会话推荐(neighborhood awareness graph neural networks for session-based recommendation,NA-GNN)。模型从会话和邻域两个角度建模捕获项目特征,然后通过注意力机制聚合节点信息并得到会话表示,预测下一个交互项目。模型组成部分如下:
(1)构建图结构:根据当前会话和全局会话构建会话图和邻域图。
(2)生成节点表示:会话图通过融合自注意力的GNN网络生成会话层的节点表示,邻域图利用邻域感知的注意力递归地合并全局层每个项目的邻域节点特征。
(3)表示聚合:通过注意力机制聚合会话层和邻域层的节点表示,全面训练项目表征。
(4)预测模块:根据聚合得到的序列表示和节点的初始表征预测下一个交互项目。
本文的主要任务如下:
(1)提出了会话图和邻域图相结合的模型,充分利用邻域信息辅助下一次点击预测,提高推荐性能。
(2)提出融合自注意力的GNN 模块和邻域感知的注意力机制,在会话层和邻域层项目表示时对项目给予不同程度的关注。
(3)在真实数据集上进行实验,证明了NA-GNN 模型的有效性和合理性。
1 相关工作
会话推荐作为推荐系统的新分支,在电子商务、社交网络等多个领域体现出很高的实用价值,会话推荐的研究因此得到越来越多学者的关注。本章概述了几种会话推荐模型。
1.1 传统推荐方法
传统的推荐方法凭借可解释性强和轻量的训练部署等优势,在推荐领域中占有一席之地。其中CF[4]算法是驱动个性化推荐机制的基本算法。早期的CF模型如基于用户的CF[5]和基于项目的CF[6],将用户/项目相似矩阵的行或列向量作为用户和项目向量表示,并根据相似度函数计算推荐用户或推荐项目之间的相似度。为了从矩阵中提取潜在的语义,研究人员从潜在因子模型[7-9]中探索了学习的用户和项目向量表示。不过CF模型通常具有很高的计算复杂度,因此在推荐中往往优先考虑用户最近一段时间的兴趣偏好而忽略之前的行为,不能很好地分析出用户真正喜欢哪些类别的商品。马尔可夫过程改进了CF方法。Rendle等人[10]将推荐任务视为一个序列优化问题,分解用户的个性化偏好矩阵,并与马尔可夫链相结合,对相邻点击之间的顺序行为建模来捕获长期用户偏好。模型单纯地从序列前后捕获用户的兴趣偏好进行预测,过分地依赖数据独立性,忽略了序列数据中蕴含的项目间的转移关系。近两年的研究较好地改善了这个问题。文献[11]通过序列信息和马尔可夫链因子对一般表示和序列表示建模,将一般相似性和两个连续项之间的序列关系统一起来进行序列表示学习。从全序列的角度建模更好地捕获用户的长期兴趣,避免对局部序列信息的依赖。文献[12]则改变了从数据中学习的模式,利用因果关系建模。在观察客观数据的同时获取用户个性化信息,更好地建立用户模型。但是模型不可避免的对用户的历史行为和兴趣偏好产生依赖,因此在匿名的会话推荐中不能发挥出最优的推荐性能。
1.2 深度学习推荐方法
不同于传统的推荐方法,基于深度学习的推荐算法通过神经网络模型训练用户的偏好表示,以此进行下一次的点击预测。
RNN 模型在神经网络基础上增加了横向联系,将上一个时间序列的神经单元的值传递至当前的神经单元,从而使神经网络具有记忆能力,在自然语言领域和时间序列训练的任务中有很好的应用性。Hidasi等人[13]提出基于门控循环单元的GRU4Rec(gated recurrent unit for recommendation)模型,在训练项目特征时结合了项目的排名损失(ranking loss),使模型对用户可能感兴趣的项目获得更高的贡献值,推荐效果有了明显的改进。但是同样较多地忽略了序列中蕴含的用户偏好,对信息利用不够充分。之后RNN模型与注意力机制结合,模型预测的准确性进一步提高。NARM(neural attentive recommendation machine)模型[14]融合RNN 模型与注意力机制,同时关注用户的行为和兴趣偏好,突出了注意力机制在捕获节点特征时的重要作用。之后文献[15]提出STAMP(short-term attention/memory priority)模型,从会话上下文的长期记忆中获取用户的一般兴趣,同时通过最后一次点击的短期记忆获取用户的当前兴趣,有效地捕获了用户偏好信息,但该方法舍弃了会话序列行为信息。文献[16]假设历史会话中包含的信息能提高当前会话的推荐性能,提出将协作邻域信息应用于基于会话推荐的框架CSRM(collaborative session-based recommendation machine),将RNN 网络和注意力机制结合,同时利用协作信息预测用户偏好。近两年提出了循环卷积结构,文献[17-18]利用卷积运算提取复杂的局部特征,然后通过迭代的RNN 网络从会话序列中训练用户长期偏好。在建立用户当前兴趣时将循环运算和卷积运算的输出串联起来产生推荐,提高了模型的性能。但由于模型本身的限制,上述算法只能对项目之间的连续单向转移关系进行建模,而忽略了会话中其他项目之间的转移关系,使得预测难以取得更好的性能。
图神经网络的表示最早由Gori等人[19]提出,2009年Scarselli 等人[20]定义了GNN 的概念并由Gallicchio 等人[21]进一步阐述。2013 年Bruna 等人[22]提出了谱域卷积,首次将图像处理中的卷积操作简单地用到图结构数据处理中来。研究人员受到启发,在图卷积的基础上不断改进,GNN 网络[23-24]在会话推荐研究中大放异彩。SR-GNN(session-based recommendation with graph neural network)模型[25]将会话序列建模为图结构,保留了项目之间的关系结构,充分利用交互和转移信息,同时通过注意力机制区分用户的长短期偏好。之后GC-SAN(graph contextual self-attention model based on graph neural network)模型[26]在此基础上融合自注意力机制的优势,捕捉相邻项的交互信息和全局依赖关系,将训练的局部和全局兴趣偏好线性加权来预测。文献[27]发现目前的方法无法捕获用户更细粒度的偏好,提出多分量的协同过滤算法分析用户行为动机,首先分解用户行为的潜在分量,之后对分量重新组合,获得统一的用户/物品表示;文献[28]从重复推荐的重要性入手,提出重复探索机制,结合图神经网络,对用户的重复探索行为模式建模;文献[29]提出需求感知的图神经网络,从用户行为角度发掘用户潜在需求,构建会话需求图训练需求感知以提高项目表征的质量。但是以上GNN 模型都只关注会话的内部信息,忽略了邻域相关信息对当前会话预测任务的辅助作用。为此,本文提出基于邻域感知图神经网络的会话推荐NA-GNN 模型,对当前会话建模的同时将邻域信息作为补充信息,提高推荐任务的性能。
2 模型结构
2.1 GNN工作原理
GNN的网络结构设置为三层:分别是输入层、隐藏层和输出层。早期的GNN 网络[19-21]以迭代的方式传播邻近节点的信息来学习目标节点的表示,直到得到稳定的固定点,因此基于循环结构的GNN 网络以不动点(the fixed point)理论为依据。之后研究人员基于图信号处理领域[22](谱域)取得的一系列成果推导出了图神经网络的基本思路:首先输入图形结构和节点内容信息,在节点之间进行信息的传播、聚合以及变换,最终根据输出的新的节点表示进行图形分析任务,其中:
(1)输入层:以图形结构和节点内容信息作为网络的输入,即网络的拓扑结构和节点的初始表征。
(2)隐藏层:通过聚合当前节点的邻居特征信息进行节点的隐式表示。然后对所有节点的隐式表示结果进行一个非线性转换。堆叠多层最终得到节点表示能够获得更深层的特征。
(3)输出层:得到最终的节点表征,然后进行图形分析任务。
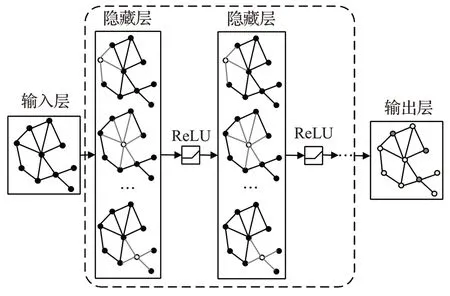
图1 GNN网络结构Fig.1 Network structure of GNN
GNN 网络能非常好地利用图的结构,以一种自然而灵活的方法获取图上邻居节点的特征。这样得到的节点表征刻画了节点的低频信息,也就是当前节点与临近节点之间一些共性和相似的信息,这些信息适用于大多数的推荐任务,如电商平台、社交网络等。
2.2 问题描述及符号表示
NA-GNN 模型的目标是从会话和邻域两个角度来建模获取用户偏好,以此预测用户行为。
预测流程如图2所示,用户与项目的历史交互过程被记录下来,模型对输入的当前会话和全局会话序列分别建图,利用图结构捕获会话层次和全局层次特征。表示聚合模块汇聚两张图中学习到的节点和邻域节点表征,得到当前会话的序列表示。预测模块根据项目的概率预测下一次交互行为。通过对模型预测流程分析,得到图3的NA-GNN模型结构框架组成。
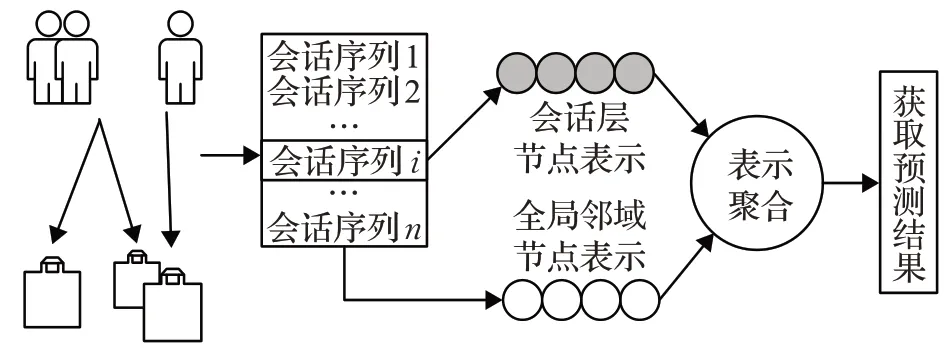
图2 模型预测流程Fig.2 Forecasting process of model
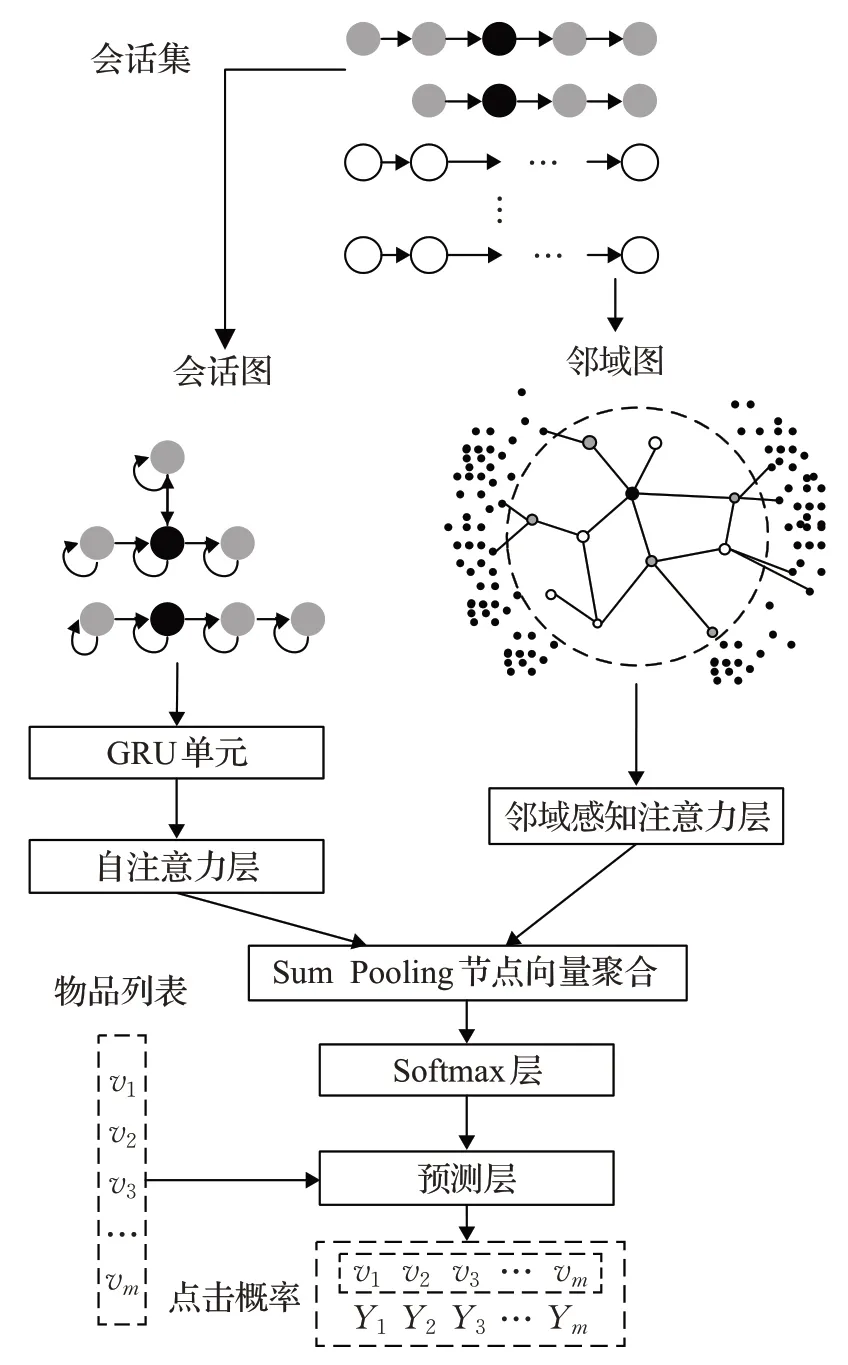
图3 NA-GNN模型结构框架Fig.3 Model framework of NA-GNN
现对文中用到的符号进行如下定义。集合V={v1,v2,…,vm}表示所有会话中出现过的项目集合,m表示项目数量。序列表示一个会话序列,其中表示在会话序列S中,用户与项目发生了交互,并按交互的时间戳进行顺序排列,i表示交互顺序,l表示会话长度。NA-GNN 模型的任务是给定会话,从所有项目集合V中预测用户第t+1 时刻将要点击的项目。模型会输出所有可能物品的概率,用得分Y={Y1,Y2,…,Ym}表示,其中Yi表示第t+1 时刻物品vi被点击的可能性,Y值越高,被点击的可能性越大,在候选物品中的位置越靠前,模型最终选择得分最高的N(1≤N≤m)个物品构成推荐列表。
2.3 构图模块
本节构建会话图和邻域图,分别从会话层次和邻域层次捕获项目交互信息,充分利用当前会话中项目转移关系和邻域信息进行表示。
会话图为带权有向图,表示为Gs=(Vs,Es),目的是基于当前会话中项目的交互信息,学习会话层次的项目表示。其中节点集Vs(Vs⊆V)表示在会话S中出现过的所有项目的集合,边集Es是会话S中出现的所有项目Vs转移关系的表示,边∈Es表示会话S中,用户点击物品vi-1后的下一时刻点击了物品vi。边集Es的权值按如下规则生成:(1)重新定义节点出度和入度。设出(入)度为当前节点的出(入)度值+1(1是节点到自身的边,即自环);(2)计算权重。每条边的权重为边的出现次数除以度值。图4 的示例展示了会话图的构造及权重生成过程。由于当前节点是距离前后交互最近的节点,因此蕴含更多有效的信息,更能代表项目转移关系。
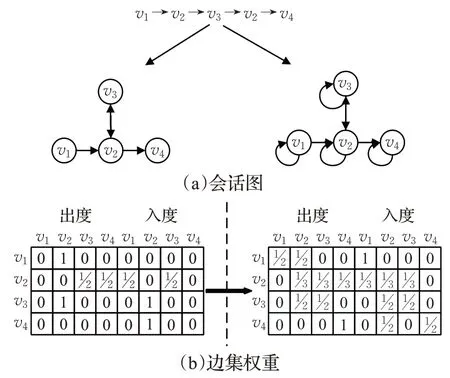
图4 会话图Fig.4 Session graph
邻域图构建为带权无向图,目的是捕获邻域节点表示。首先利用邻域的概念建立全局序列的项目转移关系,邻域是集合上的一种拓扑结构,直观理解就是邻近的区域,通过定义一段“距离”表示靠近“目标”的程度。本文定义邻域集Nα(v) 为邻域节点集合。邻域图构建规则如下:设有会话序列表示为,会话上任一物品∈Vp(会话Sp的点集),α为邻域的阶数,选取Sp上序号为[i-α,i+α]的序列段构造子集Sq,则邻域集为序列Sq上所有节点的集合。
邻域集生成示例如图5 所示。基于此将邻域图构建为Gg=(Vg,Eg),Vg是所有会话上项目构成的节点集合,,vi∈V,vj∈Nα(vi)}表示当前会话的节点与其他会话中项目之间的转化关系构成的边集。图中边集Eg权重wij的生成规则如下,对每个节点,其相临边的权重由两部分组成:(1)每条边在所有会话中出现的频率。(2)邻域感知系数γ。在邻域图中,将物品类别属性是否相同表示为节点间的关联关系,邻域感知系数则强化并量化了这种关系。当两个节点类别相同时,邻居节点对目标节点的预测产生积极的辅助作用,因此赋予正向的(γ>1)系数值强化邻居节点的影响。对边来说,每次连接都是关联关系的强化,因此γ对边的作用是累加的,最终边的权重wij为频率与感知系数的乘积。邻域图的边集综合考虑了节点间信息的相关性和对应边出现的频次,将全局序列项目交互过程的有效信息得到最大化的利用。
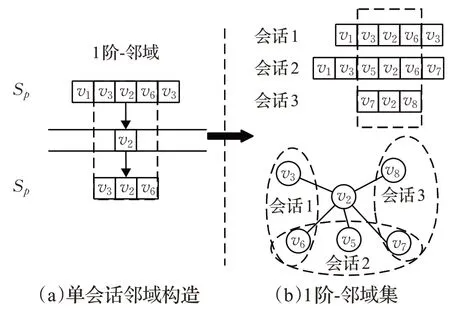
图5 构造邻域集Fig.5 Construct neighborhood set
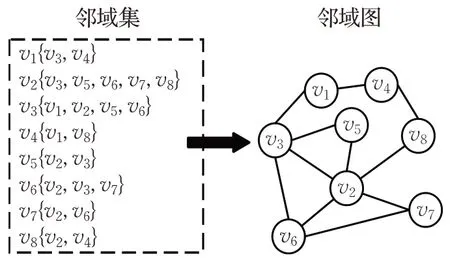
图6 邻域图Fig.6 Neighborhood graph
2.4 表示学习模块
本节对上述两种图进行节点表示训练。通过融合自注意力机制的GNN模块捕获并更新会话图上节点的表示,邻域图则设计邻域感知模块进行学习。
在会话图中,节点向量的学习过程如下:
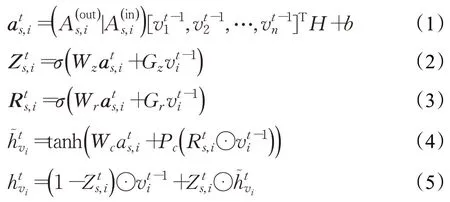
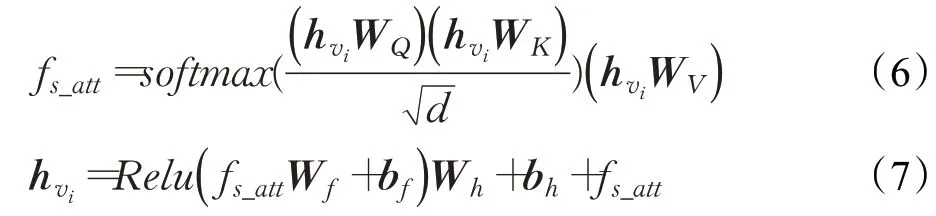
公式(6)是自注意层,其中WQ,WK,WV∈R2d×d是可训练的参数,是当前会话节点vi的向量表示,d表示维度。首先计算K(Keys)和Q(Querys)的相关性,然后对所得的相关度值通过softmax 函数归一化,得到每个节点向量的权重系数,也就是每个节点在当前会话中的重要程度。节点向量与相应的权重相乘得到自注意的节点向量。之后通过一个改进的前馈神经层将节点信息向下层传输。公式(7)中Wf,Wh∈Rd×d,bf,bh∈Rd是可训练的参数,利用ReLU 激活函数捕获有效信息,考虑到前向传输过程会产生信息损失,因此在前馈网络之后对ReLU函数未激活的信息连接,充分利用会话中所有节点的有效信息。重复以上公式可以捕获会话层更复杂的节点转移关系,但是多次提取可能导致节点向量“过度平滑”。
构建邻域图的最终目的是既要从全局序列中选择有用信息,又不能引入噪声。邻域感知的注意力模块通过计算邻域图上当前节点与邻域节点的相关度ω(vi,vj)衡量邻域集节点对节点预测的影响。计算规则如下:
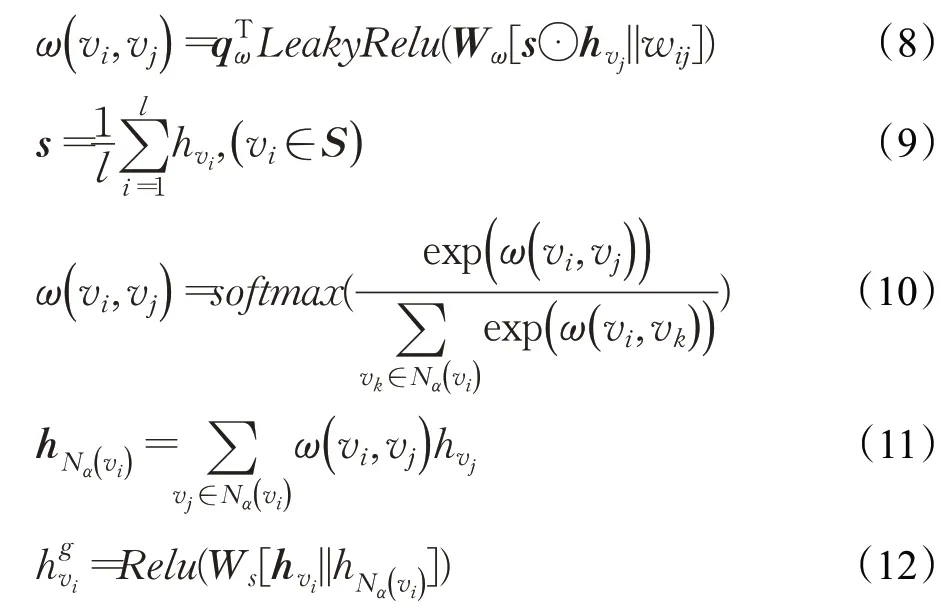
公式(8)中,ω(vi,vj)表示当前节点与邻域节点的相关度,也即相似程度,ω值越高,表示两者对应的用户偏好和行为越相似,则该邻域节点对预测结果影响越大。qω和Wω是可训练的参数;wij是边的权重。公式考虑权重的同时,也考虑了会话S和邻域集节点vj的相关程度,使注意力在两者之间作一个衡量,最终得到更全面的节点信息。式(8)中s表示当前会话S的特征向量,是对会话S中所有节点进行均值池化的结果,即公式(9)。公式(10)对相关度归一化,利用softmax函数得到当前节点的所有邻域节点概率。公式(11)将节点的邻域集Nα(vi) 的每个邻域节点的概率值线性组合得到邻域节点的向量表示。公式(12)对当前节点向量hv和邻域向量表示进行向量聚合,其中Ws∈Rd×2d是聚合权重,全局层节点向量表示为当前节点和邻域节点的向量融合。多次聚合可以把相关的全局信息更多地汇聚到中以提高预测性能。
2.5 表示聚合模块
本节聚合会话图和邻域图的向量表征得到节点的最终表达,最终得到序列表征。
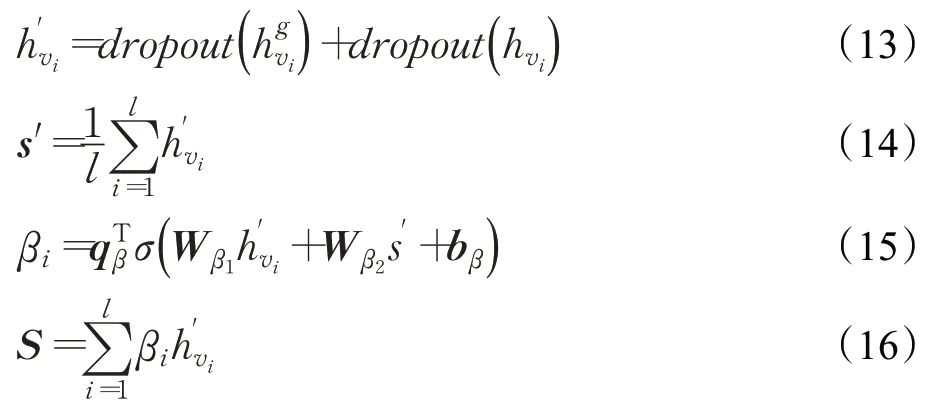
公式(13)对两个层次的节点向量做最大值池化,将更多有效信息整合到节点的表征,从而形成序列表征。过程中对节点向量增加dropout 层,防止提取高阶节点信息可能带来的“过拟合”问题。公式(14)对S中所有节点采用均值池化方法初步得到各种有效信息融合后的序列表示。公式(15)根据节点的贡献值分配不同的关注度:公式中用序列信息s′作为注意力机制的触发信息,利用注意力机制获得节点相应的关注权值。其中qβ,bβ∈Rd,是可训练的函数。最后通过公式(16)将节点表示线性加权得到序列向量表示。
由上述过程得到的会话表示S融合了不同层次的节点信息,充分挖掘了会话层次和全局层次可用的转移关系,更有效地预测用户的兴趣偏好。
2.6 预测模块
本节基于序列向量和节点初始向量,获得下一个节点的推荐列表。
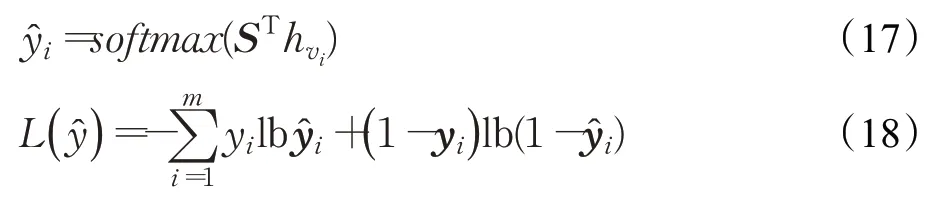
公式(17)对序列向量和节点初始向量做点积运算,通过softmax 函数得到该物品是下一次交互节点的概率,其中表示所有物品的概率分布。模型训练使用交叉熵损失计算,定义为公式(18),其中yi为one-hot向量。
3 实验与分析
3.1 数据集和预处理
实验中用到两个公开的数据集:Diginetica 和Yoochoose。Yoochoose 是RecSys 2015 挑战赛的数据,通过http://2015.recsyschallenge.com/challenge.html 获取。这些数据是实验中收集的,反映了欧洲某在线零售平台上用户的会话点击和购买行为,其中若会话中出现用户的购买活动,表示会话结束。Diginetica 来源于https://competitions.codalab.org/competitions/11161,由CIKM 2016 支持,是从搜索引擎日志中提取的用户会话,记录了查询词、产品描述、用户点击和购买行为等。对两个数据集的预处理工作参考了文献[25],首先过滤掉长度为1 的会话、出现次数少于5 的物品以及仅在测试集中交互的物品,然后将最新一周的会话设置为测试集,其余会话设置为训练集。之后对会话序列进行拆分预处理生成序列和相应的标签。由于预处理后的Yoochoose 数据量巨大且时间间隔相对较长,因此选用离测试集时间最近的1/64 会话序列作为训练集。经过预处理后的数据集统计数据如表1所示。
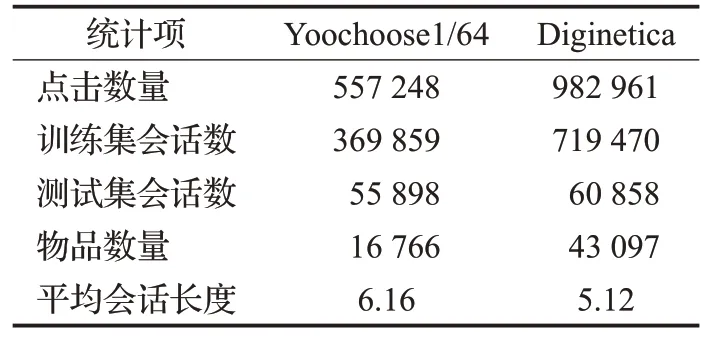
表1 预处理数据统计Table 1 Preprocessed data statistics
3.2 评价指标
实验采用了精确率P@N(Precision)和平均倒数排名MRR@N(mean reciprocal rank,MRR)作为结果度量指标。P@N广泛应用在基于会话的推荐领域,是对预测准确度的度量,指的是前N项中预测正确的物品所占百分率。MRR@N将预测正确物品的排序的倒数作为预测准确度,然后对所有预测的准确度取平均值。当预测列表中推荐正确的物品位置越靠前时,预测的准确性越高。实验中设置N值为20。
3.3 对比模型
为了验证NA-GNN 模型的性能,实验用以下几种推荐模型作为对比模型:
(1)POP(popularity):根据物品在会话中的流行度进行推荐。
(2)Item-KNN(item based K-nearest neighbor)[30]:基于物品相似度进行推荐。模型通过计算目标物品与相邻物品的相似度,推荐与当前物品属性相同或相似的物品。
(3)FPMC(factorizing personalized Markov chains)[10]:是一种融合了矩阵分解和马尔科夫链的混合模型,在捕获用户长期偏好的同时考虑了序列的时间信息。
(4)GRU4Rec[13]:设计了GRU单元对小批量的序列组进行训练,并引入了基于排名的损失函数,利用了整个序列中物品交互信息。
(5)NARM[14]:在GRU4Rec 上引入注意力机制,合理分配模型注意力,捕获用户的主要兴趣。
(6)STAMP[15]:同样是引入了注意力机制的推荐模型,该模型从会话上下文的长期记忆中捕获用户的一般兴趣,根据最后点击的短期记忆来捕获用户的当前兴趣。
(7)CSRM[16]:假设历史会话中包含与目标会话相似的用户偏好并将这种协作信息应用于推荐任务。
(8)SR-GNN[25]:首次提出将会话序列建模为图结构,通过门控GNN模型提取物品间的转移关系。
(9)GC-SAN[26]:将普适的注意力机制替换为自注意力机制,通过注意力机制自适应地捕获物品的交互和转移关系。
3.4 参数设置
为保证实验可信性,实验设置与对比模型相同的维度和批处理大小:隐向量的维度d固定为100,批处理大小为100。由于学习率、训练迭代次数等模型参数的初始化方式对模型收敛速率以及最后的准确率都有影响,因此需要通过辅助实验找到最优的超参数组合。本模型对超参数的设置参考了文献[25]、[26]的方法:使用均值为0,标准差为0.1 的高斯分布初始化。学习率为0.001,每3 个训练周期学习率衰减0.1,正则化系数λ=10-5,设置训练周期为30并在训练集上随机选取10%的子集进行验证。根据经验并结合不同优化器优缺点,本实验选择计算高效且能自动调整学习率的Adam 算法优化模型参数。此外,关于邻域图参数采用网格参数寻优法选择:邻居数Nα∈{10,11,12,13,14}、阶数α∈{1,2,3}、邻域感知系数γ∈{0.95,1.0,1.01,1.05,1.2}。在验证集上取最优的参数组合:Nα=12,α=2,γ=1.05。
3.5 结果分析
首先将提出的模型与基准模型在两个数据集上进行对比实验,结果如表2。由此可以总结出:
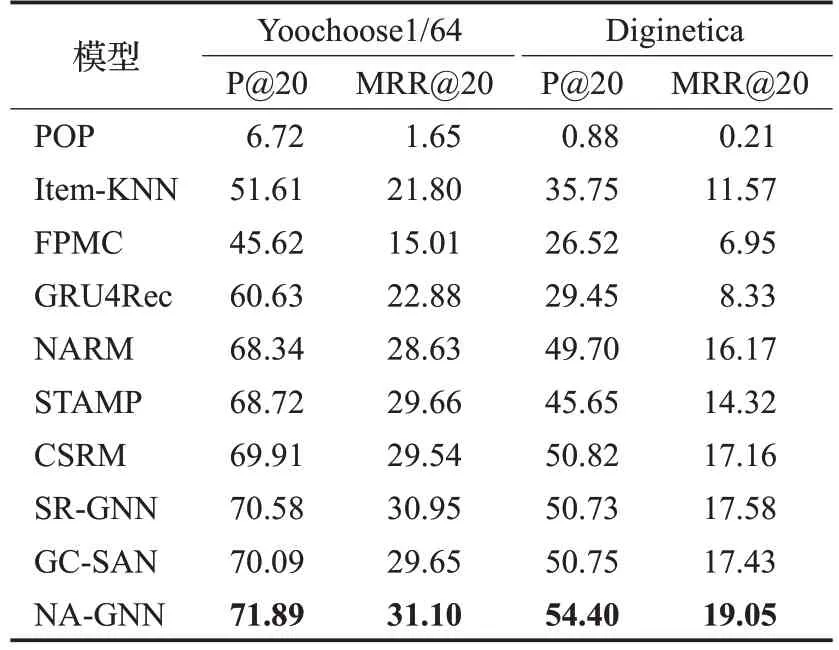
表2 不同模型在公开数据集上性能对比Table 2 Performance comparison of different models on two datasets %
(1)在所有的推荐模型中,POP 只考虑物品的流行度,推荐性能是最差的。与POP 相比,FPMC 和Item-KNN 在准确率上有了极大的提升。FPMC 通过一阶马尔可夫链和矩阵分解捕获用户偏好来提升预测准确性,Item-KNN 利用物品之间的相似度进行推荐,结果显示出很好的性能。但是没有综合会话中项目的时间信息,因此无法捕获项目之间的复杂交互关系。
(2)GRU4Rec 在性能上再次提升。这表明深度学习方法能挖掘有效的高阶信息,生成更符合用户兴趣的推荐列表。与GRU4Rec相比,NARM、STAMP和CSRM的性能明显提高。说明注意力机制能有效关注用户真正的兴趣偏好,同时证明会话中项目的时间顺序和邻域节点信息蕴含用户的长短期兴趣,用户的近期物品交互信息和相似行为对提取当前兴趣十分重要。
(3)实验证明了SR-GNN和GC-SAN的有效性。它们将会话序列建模为图结构,并结合注意力机制训练用户偏好,体现了GNN 强大的节点表示能力。本文模型与GC-SAN 相比:在Yoochoose 上P@20 提高了1.85%,MRR@20 提高了0.48%;评价指标在Diginetica 上分别提升了7.19%和8.36%。证明邻域节点信息对预测下一次交互任务有很好的辅助作用。
3.6 消融实验
消融实验从以下几个方面入手:
(1)NA-GNN-1:只有会话图的NA-GNN模型,即只对当前会话节点建模。
(2)NA-GNN-2:只有邻域图的NA-GNN模型,即只对邻域节点信息建模。
(3)NA-GNN-3:采用SR-GNN 模型方法构建会话图的NA-GNN模型。
(4)NA-GNN-4:构造邻域图边集权重时不考虑节点属性的NA-GNN模型。
由表3 结果可知,NA-GNN-1 模型通过构造自注意力节点表征获得了较好的性能,NA-GNN-2模型中基于邻域感知的注意力对全局邻域信息的学习和训练起到了一定的辅助作用,协助会话层节点向量提取复杂的节点交互和转移关系,有助于提高模型的预测性能。对比NA-GNN-3、NA-GNN-4 和NA-GNN 的实验结果,可以观察到会话图增加节点到自身的边,充分考虑节点本身对当前会话的影响,同时引入注意力机制更有效地捕获节点信息;邻域图中增加项目属性信息,可以更准确地挖掘节点间蕴含的隐含转移关系。通过上述分析,表明NA-GNN模型中的各个模块的设计都是合理有效的。
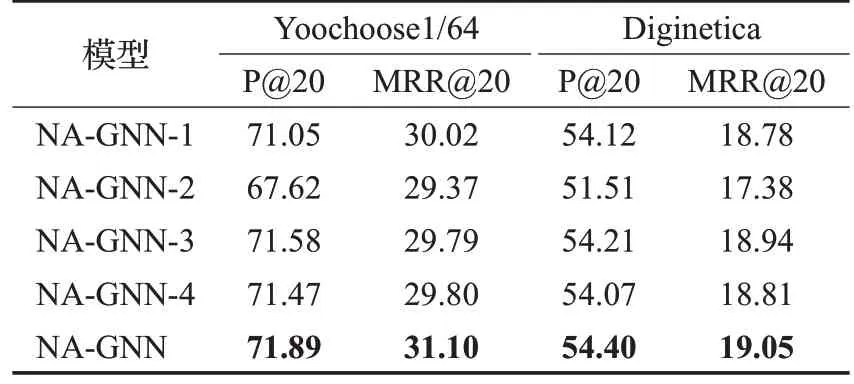
表3 NA-GNN模型消融实验性能对比Table 3 Performance comparison about ablation experiment results of NA-GNN model %
另外针对NA-GNN 模型中构造邻域图的参数,节点邻居数和邻域阶数设计了对比实验,结果如图7 所示。结果表明合理利用邻居节点的数量和阶数可以从全局层次提取更有效的节点转换信息,提高模型的预测能力,但是高阶的邻域图信息也可能会引入噪音,以Yoochoose1/64数据集为例,随着邻居数量增多,模型的性能在达到峰值之后逐渐下降,而一阶的邻域比高阶的邻域图表现出更好的效果。由此可知邻域图在构建时需反复实验,确定合理的参数值,避免聚合无关的邻居节点特征。
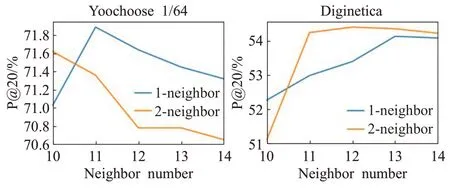
图7 不同邻域参数下NA-GNN模型性能对比Fig.7 Performance comparison under different neighborhood of NA-GNN
3.7 复杂度分析
本文中模型的复杂度[31]从两个指标度量:
计算量(floating point operations,FLOPs):对单个样本,模型进行一次完整的前向传播所发生的的浮点运算个数,用来衡量模型的时间复杂度。计算公式为:
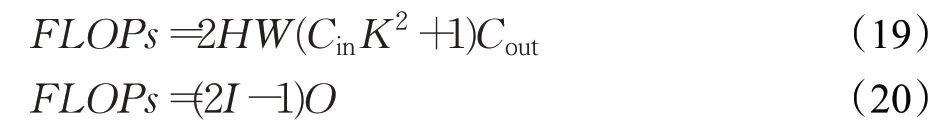
公式(19)描述了卷积层浮点运算数量。其中:H、W和Cout表示输出特征表示的高度、宽度和通道数,K、Cin表示卷积核宽度和输入特征通道数。式(20)是全连接层上计算过程。I、O分别表示输入维度和输出维度。
访存量(Params):是指对于单个样本,模型一次前向传播过程中所发生的的内存交换总量,也即模型的空间复杂度。
在离线方式下对模型复杂度进行评估,包括模型的计算量、访存量和训练时间。实验中得出计算量为每秒53.64 GB,访存量为3.97 MB,在表4中的软硬件环境下训练Yoochoose1/64 的单个周期为2 640 s,因此不会占用太多服务器和内存资源,且没有通过服务器频繁导入导出数据,是轻便可靠的模型。
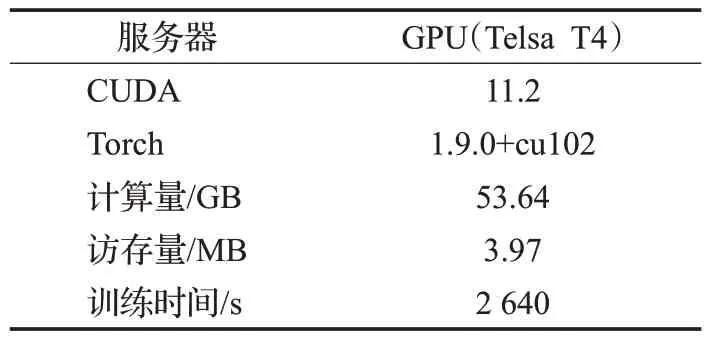
表4 NA-GNN模型复杂度Table 4 Complexity of NA-GNN model
由于模型最终的训练速度,不仅和计算量和访存量有关,与其他因素如内存带宽、优化程度、运算器算力等因素也有很大的关系,因此对模型的复杂度进行了如下理论分析。
分析结果如表5所示,本模型的计算量主要集中在GCN部分。设会话长度为n,隐向量维度为d,层数为K,则通过出入度矩阵初始节点表示的时间复杂度为O(n2d),通过GRU单元为O(nd2),整个图卷积过程的时间复杂度为O(Kn2d+Knd2)。若物品数量V比较大时模型的参数主要体现在物品的嵌入矩阵,此时参数量为O(KVd+Kd2)。与新算法的对比分析发现:模型在空间复杂度上的差别不大。对于长会话进行推荐时,由于CSRM 模型基于RNN 迭代地训练项目特征,空间上需要更多的内存。时间复杂度上SR-GNN 更优,说明GNN 模型是更适合会话推荐的算法。ReGNN 重复探索机制不能与训练同步进行,时间花费更高。整体上,本文提出的模型从复杂度分析是简便高效的模型,具有一定的实用性。

表5 不同模型复杂度对比Table 5 Complexity comparison about different models
4 结束语
为解决基于匿名用户的会话推荐问题,本文提出了基于邻域感知图神经网络的会话推荐模型NA-GNN。模型构造了会话图,利用自注意机制提取节点信息;并设计了邻域图,融合邻域感知的注意力捕获邻域节点的复杂交互作为辅助信息。生成的序列表示则包含了会话层次和全局层次的节点信息,在此基础上进行预测任务。通过实验表明,模型在各项指标上均表现出好的推荐性能。NA-GNN 考虑了物品类别给提取邻域信息带来的影响,然而邻域信息是否有效需要从多个角度考量,通过节点的单一属性无法准确捕获有效信息。除节点的类别属性外,时间信息同样是一个重要因素,一般来说用户在自己感兴趣的物品上往往花费更多的时间,因此图上节点的时间信息对用户偏好有一定体现。在下一步的工作中,需要在NA-GNN 模型的基础上综合考虑节点交互的时间间隔等信息对推荐的影响,研究融合用户交互的时间信息捕获用户偏好的方法,进一步提升推荐准确性。
