网络评论文本数据监管处理的优化研究*
——以茶产品为例
2022-05-12王书博程贞敏
王书博 程贞敏 苏 渝
(1.贵州大学数学与统计学院 贵阳 550025;2.贵州大学管理学院 贵阳 550025)
0 引 言
伴随着Internet的发展,网络购物开始逐渐走进人们的视野,并在不断发展的态势中开始成为人们生活中必不可少的东西,也由于网络购物的及时性和物流中心的遍布性为人们的生活提供了极大的便利,使得人们足不出户就可以买到自己心仪的产品,也促使产品的销售者能够将产品的销售领地不断拓展,也在不断改变着管理人员的行为。其中,影响消费者和管理者行为的主要因素就是产品的网络评论。对于消费者来说,由于现实情况中的网络评论并不是每一条都与产品息息相关,而是存在着大量的无效评论、评分与评论内容严重不符合、重复评论、产品与内容严重不符合等情况,使得消费者不敢轻易相信欲购买产品的网络评论,从而大幅降低了产品的成交率,但如果产品的评论足够有效,能够为消费者提供真实且可靠的信息,那么就会促使消费者产生进一步的消费行为。对于管理人员来说,网络评论中有很多关于产品属性的评价内容,是最早反映消费者对于产品态度的源头,更是直接知晓产品问题所在的重要信息来源,能够帮助管理人员及时对产品做出相应的修改与调整,以此避免产生更大的负面影响。
但是在现实的网络评论中,网购平台生成的短文本信息是由产品的消费者产生的非结构化的文本,其中包含了大量的网络化语言及特殊性符号等,导致文本在处理过程中存在一定的障碍。此外,在对中文进行分词、内涵识别以及同义词提取时还存在一定的难度,用于数据处理的情感词典或者标注语料等必备工具也存在一定的缺失[1],因此,对于中文文本的数据处理及情感度的有效分析还具有很长的路要走,但无可置否,提高对网络评论的提取效率及提取正确率又具有十分重要的现实意义和迫切性。因此,本文在当前研究成果的基础上,以茶产品的网络评论文本数据为例,提出了Bert+Transformer模型和Bert+XGB模型对网络评论文本进行处理,并通过实证分析,证明上述两种模型相较于之前的网络评论文本数据的处理手段而言极大地降低了文本处理的错误率和缺漏率,提高了文本处理的正确性和有效性,从而为消费者和管理人员提供了采取何种消费和管理行为的数据支撑。
1 文献综述
在已有的研究成果与实践中,对于网络评论的文本数据运用主要集中在形象感知分析[2]和及情感分类分析[3-5]两个方面,其中,对于情感分类的分析是最常运用的领域,尤其是对微博评论文本的情感分类分析[1,3],而对于茶产品网络评论文本的情感分类研究至今仍旧是空白,但不可否认,分析出人们对茶产品的情感偏好是进一步制定和修改相应的销售、种植等策略的关键所在,因此,对茶产品的网络评论文本数据进行情感分类分析具有十分重要的意义,也在一定程度上弥补了网络评论文本数据分析和研究领域的空白。
在对文本数据进行处理的基本模型运用方面,最常用的单一模型是Bert模型和XGB模型。针对于Bert模型而言,其主要应用的领域则集中在生成式文本内容摘要[6]、金融文本情感分析[5]、法律文本内容推荐[7]等,注重于内容的分析和提取。针对于XGB模型,其主要的应用领域是各行业的预测,例如超短期光伏功率预测[8]、电信客户流失预测[9]等,注重于行业趋势的探索。两个模型都在各自的应用领域中具有一定的优势,但是也存在一定的短板,例如在顾及了速率的时候就不能兼顾正确率,在顾及了内容的时候就不能兼顾效率,因此单一模型在运用上存在一定的局限性,从而催生了多模型的结合运用,例如BERT-SUMOPN[6]、Wide & Deep-XGB2LSTM[8]、XGB-BFS[9]等应用模型,都做到了两者兼顾,但是都不曾广泛应用到其他的行业中,仅仅集中在单一分析领域,更是不曾应用到茶产品的网络评论文本处理领域。由此可见,当前已经存在的模型成果不仅存在一定的数据处理精度和效度的缺陷,在领域应用方面也存在一定的欠缺。
从当前的研究成果中可以看出,在文本处理的分析内容及使用模型等方面都较为成熟,但是并没有过多涉及其他的行业和领域,尤其是茶产品的网络评论的文本数据处理内容。此外,在模型的混合应用中,主要是应用到行业预测中,而没有着重提高整个网络评论文本处理的速率和正确率。但是,茶产品是中国蕴含传统文化的产业,也是极具经济效益的行业,拥有极高的文化价值和经济价值,并且提高整个网络评论文本数据处理的正确率和效率本身就是一件刻不容缓的事情,在网购盛行的时代对网络评论文本数据进行分类和深入分析具有十分重要的现实意义和实践内涵。
2 文本数据基本情况及预处理
2.1 茶叶消费者评分数据基本情况 为了全面挖掘茶产品现阶段的优势和劣势,本文在某电商平台查找销量较高的绿茶、乌龙茶、红茶、黄茶、黑茶、白茶六个类别7七种茶叶,并爬取每种茶叶离当前时间最近的前1 000条评论及其商品评分,不足1 000条则全部爬取。共爬取商品评论及评分12 305条,在删除重复、字数过少和不相关的评论后,得到有效评论9 644条,如表1所示。

表1 不同茶叶种类的消费者评分
2.2数据预处理由于网络评论数据中夹杂着诸多的英文、错字、繁体字等不利于分词的元素。因此在分词之前使用百度翻译接口和python中繁化简包与汉字纠错包对文本做初步处理。之后,本文采用jieba分词对全部商品评论进行分词,并去掉停用词。对文本不合规数据预处理的具体步骤如图1所示。
3 茶叶消费者评价综合分析
通过爬取某电商平台的茶叶商品评论数据进行文本挖掘,首先将评论进行有效性分析,删除那些复制和简单修改的数据。之后对各种类的茶叶的消费者评论文本进行语义向量分布式处理,采用Bert模型生成消费者评论文本的语义向量,并构建出细粒度情感分析模型,对差评进行分类,实现产品的实时改进。
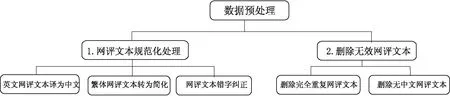
图1 数据预处理方法
3.1基于文本挖掘的茶叶消费者评价分析对茶叶消费者评分高于3分的消费者评论进行近义词分析,采用Word2Vec词嵌入法表示词向量,并对分布较为相近的词语进行聚类。得到好评近义词在消费者在口感方面的评论主要为“甘甜”“香醇”“回味无穷”等;在价格方面的评论主要为“实惠”“不贵”“亲民”“划算”“性价比”“物美价廉”等;在包装方面的评论主要为“精致”“精美”“大气”等;在色泽方面的评论主要为“清澈”“透彻”等;在气味方面的评论主要为“香气”“好闻”等;在养生方面的评论主要为“健康”“养胃”“高血压”“高血脂”“解暑”等。
综上,消费者对于茶叶进行好评主要是由于茶产品口感甘甜、香醇、价格实惠、包装精美、色泽清澈以及有缓解高血压、高血脂、养胃解暑的功效。
本文也对茶产品消费者评分在3分及以下的消费者评论进行了近义词分析,同理得到茶产品消费者差评近义词,茶产品消费者在口感方面的负面评论主要为“陈茶”“苦和涩”等;在价格方面的评论主要为“一分钱一分货”“上当”“变来变去”“不值”等;在包装方面的评论主要为“碎渣”“破损”等;在色泽方面的评论主要为“纯色”“掺杂”“红色”“黑色”等。
综上所述,茶产品缺陷主要集中于商家售卖陈茶、物流导致包装破损、茶叶掺杂异物、价格变动频繁等。
3.2茶产品消费者评论监管为了更加有效地进行产品维护,本文将构建基于消费者评论反馈的分析系统,实时对产品的各个方面进行监管,并做出基于反馈内容的产品改进,进一步提升消费者满意度。
反馈分析系统的构建分为以下两个步骤:一是提取消费者评论中的有效评论,二是对有效评论进行细粒度情感提取,从而获得消费者具体对哪些方面满意,对哪些方面不满意。
3.2.1 消费者评论向量化表示 本文在研究中发现,部分消费者出于获取优惠等心里,对茶产品给出较高的评分,但评论却是差评,不仅如此,部分好评里也含有部分对某些方面的不满意。如果单纯看评分情况并不能准确反映消费者对于茶产品的真实态度。因此,文本将放弃店铺给出的评分指标,提出消费者评分细粒度情感分析模型,期望通过该模型来获取真实的网购产品评价情况。
3.2.2 消费者评论有效性筛选
① 基于有效性的消费者评论排序与筛选模型构建。针对茶产品的消费者评论常常出现内容不相关、简单复制修改和无有效内容等现象,例如“宝贝已收到,是我想要的,手感很好,质量也挺好,有问题客服也很快就解决了,态度非常好,一定好评!物流满分?,包装快递满分?,配送员态度满分?,购物让人开心,吃土使我快乐~?????????一次很好的购物体验,…”这一评论除标点符号外共413个汉字,但是评论内容丝毫没有提及具体的产品,明显是从他处直接复制而来,对消费者和分析人员没有一点帮助。因此,本文通过基于有效性的网络评论文本排序与筛选专利,提出一种更适合茶产品的有效性模型,以期获得更加有效的网络评论,建模流程如下所示。
评论删除简单复制修改模块:
步骤一:采用jieba工具对评论进行分词,对评论做词级的相似度检验;
步骤二:令a=第一条评论和第二条评论合在一起不重复的次数,b = (第一条评论不重复的词数+第二条评论不重复的词数);
步骤三:若 (b-a) / a > 0.9则表示两条评论相似度高,可认为其中一条为简单复制修改后的评论,予以删除;
步骤四:重复上述过程,在任意两条评论均对比完成停止。
评论有效性模块:
步骤一:采用词性标注工具对消费者评论进行标注;
步骤二:对待排序评论集中的名词出现次数进行统计,并按词频从高到低提取出评论数乘以1%之前的高频名词构建评论目标的特征集。并根据具体要求设置辅助特征词;
步骤三:依次对待排序评论集中的每一条评论进行处理,得到每条评论中涉及的特征数;
步骤四:将评论中的每一个词与特征词集进行对照,若评论词既是特征集中的词又是辅助特征词,则将评论词的权重赋值为2,若评论词只是特征集中的词而不是辅助特征词,则将评论词权重赋值为1,若评论词不是特征集中的词,则将评论词权重赋值为0;
步骤五: 依次将待排序评论集中的每一条评论的所有权重求和,若评论中不涉及任何一个辅助特征词则评论的总分值为0,并按照权重之和将评论从高到低进行排序;
步骤六 :将每条评论权重之和作为消费者评论的有效性评分,筛选出有效和无效评论。
② 特征集构建。本文首先采用Hanlp分词器对消费者评论进行分词,在Hanlp自然语言处理类库中封装好的Hanlp类中共有5种分词器,分比为维特比分词器、双数组trie树分词器、条件随机场分词器、感知机分词器、N最短路分词器。本文选择默认的维特比分词器来对网评文本进行分词,并对不同评论分词后相似度超过90%的词汇进行去重,只保留发表时间最早的评论中的词汇。统计出各类茶产品消费者评论的所有名词词频,并按词频从高到低提取出评论数乘以1%(本文为74个)之前的高频名词,并将这些高频名词作为构建特征集的特征。
③ 消费者评论有效性评分统计。由于Word2Vec所得到的好评词和差评词及其近义词(在3.1章节)比一般的特征词更能体现出评论对于产品的描述,因此本文将他们称为辅助特征词,在此说明一点,辅助特征词不一定在特征词集中。
将评论中的每一个词与特征词集进行对照,若评论词既是特征集中的词又是辅助特征词,则将评论词的权重赋值为2,若评论词只是特征集中的词而不是辅助特征词,则将评论词权重赋值为1,若评论词不是特征集中的词,则将评论词权重赋值为0。以此得到评论中每个词的权重,将权重求和得到的值作为这条评论的有效性评分,若评论中不涉及任何一个辅助特征词则有效性评分直接为0。根据有效性评分筛选出有效性评分高、中、低三个层次的评论并做表。其中,表2、表3为高、中层次得分排名前5位的评论,表4为低层次代表评论。
以每个表中的第一条评论为例进行分析,从高层次有效性评分的第一条评论“上班的时候经常带几包去,有些同事也喝过,都说好喝,茶叶肥大厚实,泡出的茶汤清澈明亮,茶香扑面而来,细细品味下回甘十足,说实话,确实比店里便宜得多,而且茶叶也味道好。铁观音茶一直是我喜欢的那一种,一种清香淡雅的香味,独立的包装,干净整洁,适合各种场合饮用。口感不错!茶叶色泽嫩绿,口味纯正,冲泡的汤色金黄清彻,韵味醇厚,喜欢用白瓷泡铁观音,色香味俱全,喝茶就是一种提升气质的生活态度”可以发现,该条评论分层次描述了茶产品和店铺物流的各类信息,能够帮助消费者更加详细了解产品的细节,加深消费者对产品的印象,也给其他消费者提供了很多可以参考的意见。
从中层次有效性评分的第一条评论“茶叶品质不错,很清香,茶汤清透,口感不错,包装精美,性价比高!”中可以发现,该条评论虽然也对茶产品个别特征进行了介绍,但并没有介绍完整,没有提到产品好在哪里或差在什么地方,而是选择产品的部分内容进行描述,但是也对消费者提供了借鉴与参考,对消费者和评论监管有一定的帮助性。
从低层次有效性评分的第一条评论“一直在买这家的茶叶,茶叶真心不错,杠杠的”中可以发现,该条评论在字数上和高层次有效性评论以及中层次有效性评论相比均比较少,并没有指出评论内容的描述对象与产品特色,对消费者的参考意义并不是很大,因此将其归类为有效性较低的评论较为合理。第二条评论则更具典型性,该评论是这一小节开头所举的例子,可以看到,评论被模型判为了0分,模型的优越性进一步展现出来。

表2 部分高层次有效性评分的消费者评论

表3 部分中层次有效性评分的消费者评论

表4 部分低层次有效性评分的消费者评论
通过评论的有效性分析,得分为0的评论对消费者而言没有参考价值,对于监管人员也没有分析的必要,可以将其直接删除,从而节省了时间,降低了成本。经过删除后的样本数量从9 644条减少到了6 822条,具体结果如表5所示。

表5 根据有效性删除样本后不同茶叶种类的消费者评分
3.2.3 消费者评论细粒度情感提取
a. 细粒度情感提取模型简介。由于爬取的网评并没有情感标签因此无法直接带入模型,本文只能通过手工标注的方式构建评论数据集,数据详情如表6和表7所示。该数据集包括每条评论对茶叶口感、价格、包装、色泽和气味5个指标的评价,每个指标包括好、不相关、差三类标签,标签对应取值分别为1、0、-1。将训练好的Bert模型用于茶产品消费者评论的预测,从而提取出消费者对茶产品不同方面的情感观点,为茶产品的改进提供借鉴与参考。

表6 手工标注数据集及其评价指标
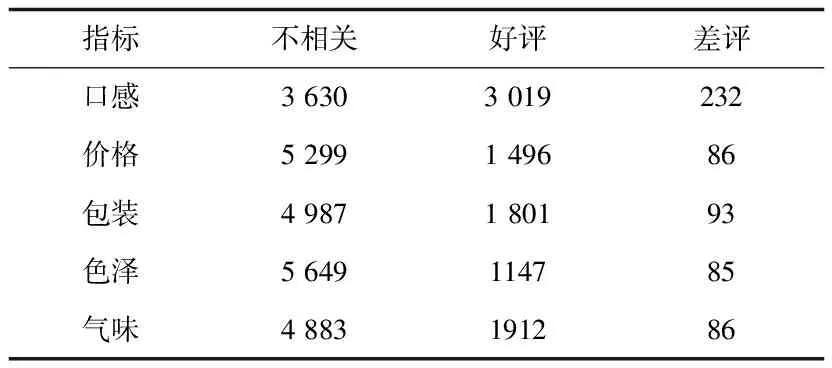
表7 手工标注后各个指标标签的数量
b. 数据增强。对本文所引入的手工标注数据集各项指标进行统计分析[10],发现各指标的不相关标签和评价为好的标签占比很高,该数据集属于不平衡数据集。样本不均衡会严重影响到模型的性能和对少数类样本的捕捉准确度,因此,必须对外部数据集进行数据扩充或者数据删除处理。
在此说明,由于测试集为本文最终评判模型效果的数据,因此不能做以上数据增强,也不能人为改变其分布结构,所以此处的数据增强只针对于开发集[11]。以8∶2的比例划分开发集和测试集(开发集训练模型,测试集判定模型效果),再以8∶2的比例将开发集分为训练集和验证集(训练集让模型学习数据信息,验证集给予模型反馈让模型进行调整)。
a.现有数据扩充。首先对数据进行回译扩充,将一句话依次翻译成多国语言后再翻译回汉语。其次对数据集中-1类标签的评论按逗号进行拆分,并统计评论拆分后的子文本个数。当子文本个数大于3时,将同一评论中的不同子文本打乱顺序[12],并重新进行排列组合,每条评论组合3段,排列6次。假定评论ri包括x1、x2、x3、x4四个子文本,即ri={x1,x2,x3,x4},表明该评论的子文本个数大于3,则将该评论随机组合为{x1}、{x2}、{x3,x4}三段新文本,并以不同顺序排列为新的文本,从而使原有的少数类评论新增5条。
b.构造少数类数据。文本中种类最多的是不相关的数据,这类数据与标签值为-1的样本没有对立的字段,若要将其修改成负评价样本不需要对样本进行修改,只需要加上对应的负面评价即可变成该指标下的负面评论,例如口感这一指标可以根据开发集提炼出口感差评的关键字段:“苦的”“苦和涩”“茶苦”“苦味”“不好喝”“味道差”“难喝”“没有味道”“口感不好”“口感差”“口感太苦”“喝不习惯”“口感一般”“味道一般”“口感苦涩”“没有茶味”“勉强能喝”“只能说能喝”“味道苦涩”“味道太淡”“味道有点淡””等。因此本文使用上述方法尽量做到负面评价样本占总样本数的1/5以上。
例如,在未进行数据增强时,开发集上“口感”这一指标中,好评、不相关和差评数据分别为2 420条、2 896条和188条,可以看出,差评样本远远少于其他两类。经过数据增强后,开发集上三类标签数量分别为2 420条、2 896条和2 118条,可以看出,经过增强后的三类标签的数量相差不大。
c. 模型效果。采用经过预训练的Bert+Transformer模型对茶产品的消费者评论的每一项指标分别进行情感提取,从而得到对评论的情感提取结果。模型评价指标如下:
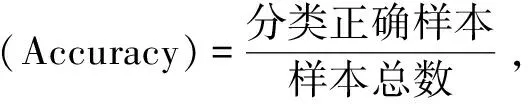

精确率(Precision)=


在进行数据增强前,模型对5个指标负面情绪的识别效果不佳,模型对于-1标签的召回率很低,模型对负面评论的识别效果很差,特别是对于价格、包装和气味的负面评论根本就无法识别(准确率、召回率和F1分数均为0),这是因为在6822条数据中,仅有不到100条评论涉及这三个指标的负面评论,占比太少,导致模型不能有效地进行学习。表8是经过数据增强后,模型对5个指标情绪识别的结果,可以发现,所有-1标签不论是准确率、召回率还是F1分数都要低于另外两类,这是由于负面情绪样本太少,数据集严重不均衡导致的,本文通过数据增强手段将模型的准确率都提升到60%以上,效果显著。除了“价格”和“包装”两个指标的三项评价指标偏低以外(可能是由于价格中“一分钱一分货”等字段正负情绪判别难度较大导致),另外三个指标的所有评价指标值都良好。总体而言,尤其是召回率,所有指标均大于70%,“色泽”和“气味”的召回率甚至达到了90%以上。
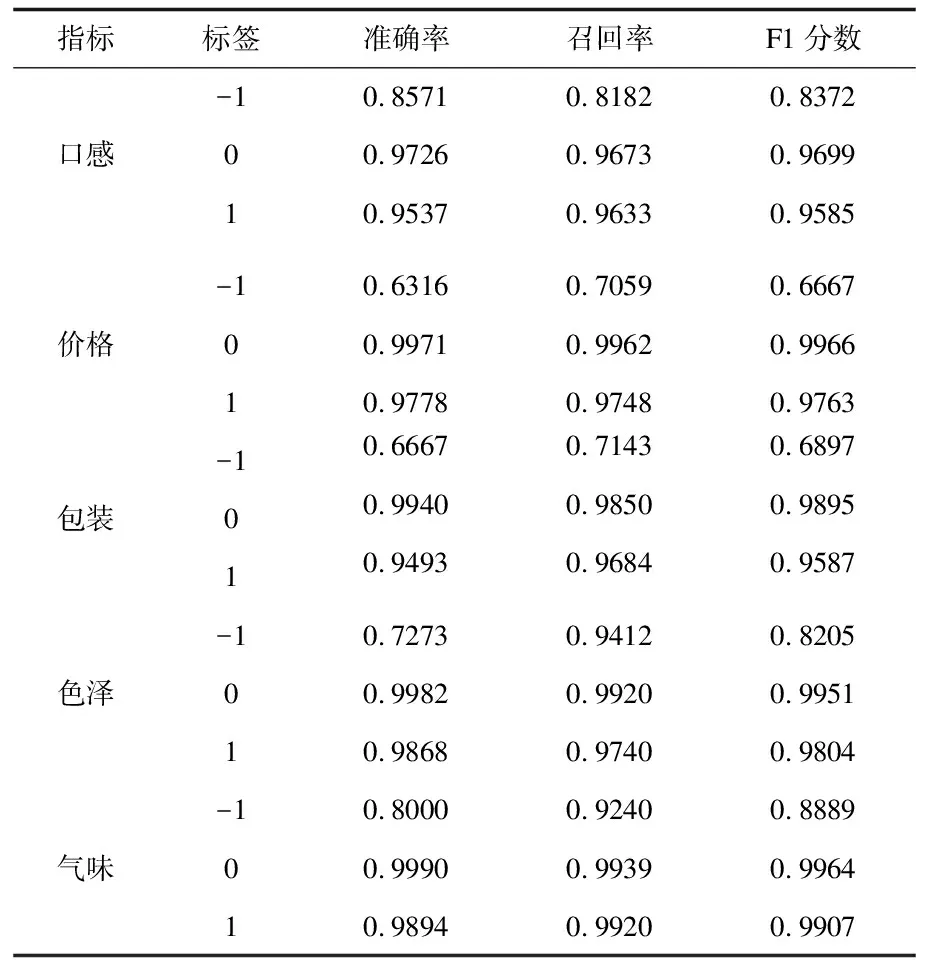
表8 茶产品消费者评论情感提取结果
为更直观地看出模型效果,本文将分析两种模型、利用评分和利用差评关键字段的方式对消费者差评评论的捕捉能力。之所以看差评捕捉能力,是由于相比于好评和不相关评论,差评带给监管者的信息要多得多,同时也对消费者是否产生购买行为的影响更大。由于评分不能反映细粒度问题,本文在此假设评分低的评论都是不喜欢茶叶某个指标的(实际上只利用评分情况也只能这么做,在找到差评后看消费者对哪方面不满意)。
由表9可以看出,对于每一个指标而言,Bert+Transformer模型和Bert+XGB模型这两种混合模型,无论是对负面情绪样本的捕捉能力,还是捕捉精度上面都要远远优于传统手段上仅使用关键字段提取和利用评分选择的方法。针对于本文提出的两种模型而言,基于Bert的深度学习Transformer模型比基于Bert的机器学习XGBoost模型捕捉到的差评数更多,并且基于Bert的XGBoost模型将更多的好评也判定为了差评,但是基于Bert的XGBoost模型的实现速度更快,所以两种混合模型各自有各自的优点,具体选择哪种混合模型可视情况而定。综上,证明了本文提出的模型是更加有效的,具有极强的实践意义。
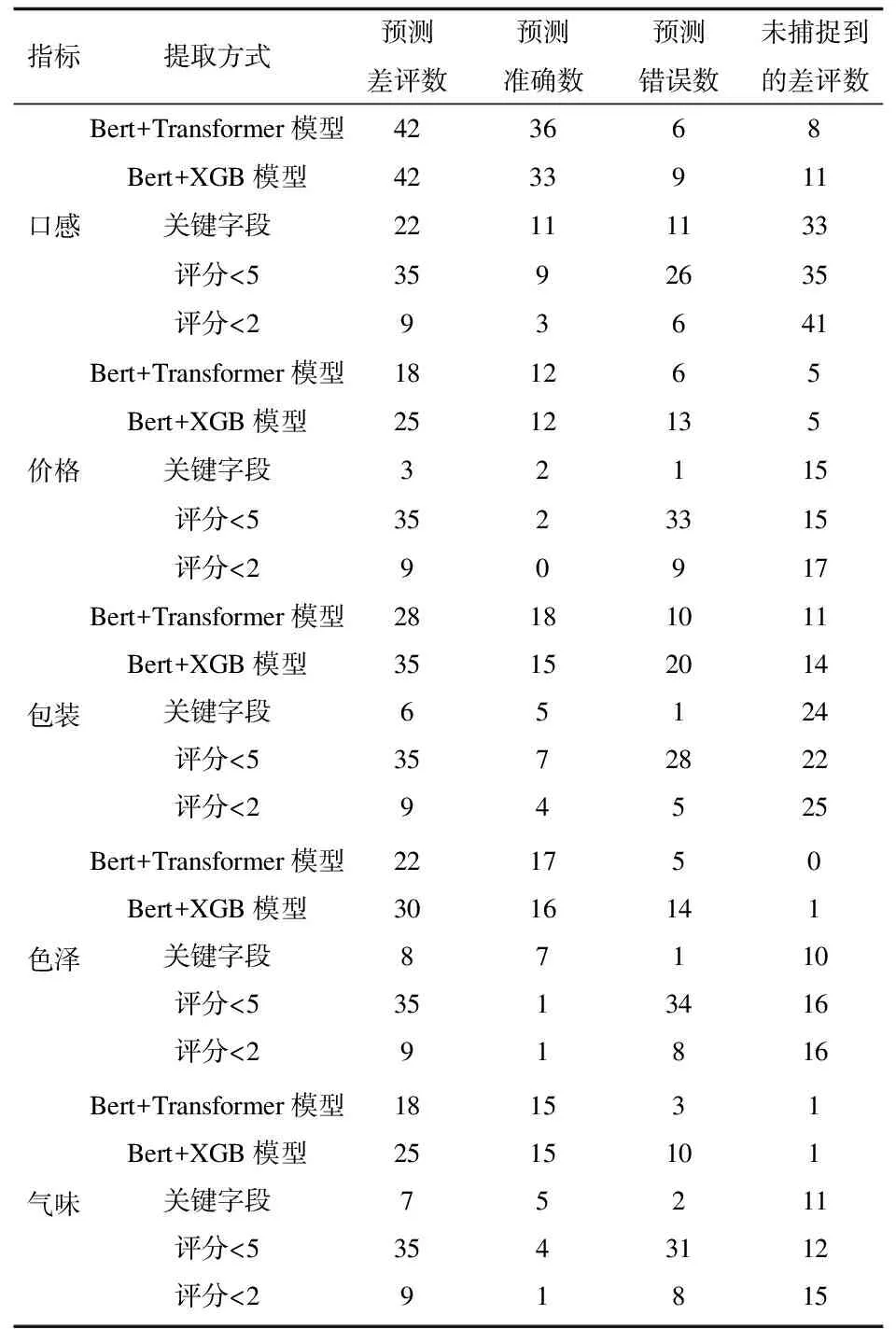
表9 不同模型对各项指标的细粒度负面情感提取结果
4 总 结
本文在前人技术的研究基础上,进行了方法和内容的创新,主要的贡献体现在以下几个方面:
a.弥补了在网络评论文本分析行业中茶产品网络评论文本无人研究的空白,并深度挖掘了茶产品网络评论文本的情感内容分析和内容提取,为茶产品的发展提供了相应的改进和深化的可靠依据,也为其他行业的网络评论文本处理提供了更加高效的方法。
b.从消费者的角度出发,分别构建了评论的有效性模型和细粒度情感分析模型,评论的有效性排序后可以让消费者提高获取产品信息的效率,让消费者能更快速地看到那些对其想要购买的产品有参考价值的评论,从而使消费者能更早地下定决心是否购买产品,也提高了消费者购买行为决策的正确性。
c.从管理者的角度出发,构建的细粒度情感分析模型能够分析出产品的内在特质等问题,从而更加及时和准确地分析出消费者现阶段对产品的哪些地方满意以扩大产品优势,对哪些地方不满意以便于管理者及时做出相应的调整弥补不足。
d.多模型结合运用,打破了当前的模型壁垒,从而提高了模型提取数据的效率和正确率,使得网络评论文本数据处理更加正确和高效,为消费者和管理者都提供了一定的便利,也扩充了模型的多样性和实现了模型多领域的可应用性,具有极强的实践价值。
