新的多任务预测优化模型损失函数及其在蜡油加氢催化剂评价中的应用
2022-05-11李明丰胡元冲梁家林褚小立
田 旺, 秦 康, 李明丰, 胡元冲, 梁家林, 褚小立
(中国石化 石油化工科学研究院,北京 100083)
随着原油逐渐重质化和环保要求日趋严格,重油加氢改质变得越来越重要[1]。蜡油加氢作为重要的加氢改质工艺,可脱除硫、氮等杂质,降低芳烃和烯烃含量,为催化裂化或加氢裂化提供适宜的原料[2]。蜡油加氢工艺的核心是脱硫、脱氮催化剂,所用催化剂不仅决定产品性质,而且影响装置的运行周期。
蜡油加氢催化剂的中试评价主要关注加氢后蜡油的硫、氮质量分数,目前的中试评价模型多为机理模型。机理模型的解释性强,过程较为清晰,但在同时预测加氢蜡油中硫、氮质量分数时,机理模型需要考虑两者之间的相互作用,数学表达较为复杂,动力学模型参数求解困难,实际使用并不方便。
神经网络模型不需要考虑复杂的机理就可以实现相应任务的预测,成为研究热点。周轶峰等[3]利用3层神经网络,根据柴油馏分油性质、工艺条件对加氢柴油中硫质量分数进行预测,得出不同工艺条件对加氢脱硫(HDS)反应深度的影响大小。郭庆洲等[4]根据加氢处理润滑油基础油的几种性质,建立了预测其芳烃质量分数的神经网络模型。相比主成分回归模型,神经网络模型的预测精度更高。胡元冲等[5]基于神经网络框架Keras,针对柴油产物中硫、氮、单环芳烃、多环芳烃质量分数分别建立了预测模型。李诏阳等[6]采用长短期记忆神经网络(Long short-term memory,LSTM),以加氢裂化的操作参数为输入变量,轻质润滑油的4个性质为输出变量,建立了预测模型;通过随机森林(Random forest,RF)算法对输入特征进行重要度排序,得到不同生产目标对应的优化操作方案。田水苗等[7]利用BP神经网络建立数据驱动模型,来预测石脑油、液化气、燃料气、精制蜡油流量以及精制蜡油中硫、氮质量分数;仿真结果表明BP神经网络模型具有较高的预测精度。
尽管神经网络可同时预测多任务,但是,多任务同时预测易出现各任务之间梯度不平衡、预测结果偏向某个任务的问题。为解决多任务同时优化的平衡问题,Chen等[8]曾提出梯度归一化算法,通过动态调整梯度大小,自动平衡深度学习模型的多任务优化;但该方法只在特定的优化器下才能表现出较好结果。Zhou等[9]针对多视图分辨问题,考虑不同任务之间的方差不确定性,提出协同多目标量子粒子群优化算法(Cooperative multi-objective quantum particle swarm optimization, CMOQPSO),该算法即使在小样本场景下也能得到较高的分类准确率。Guo等[10]引入动态任务优先级概念,通过自适应调整各任务损失函数的混合权重,自动对难度较高的任务进行优先级排序;分类模型利用该算法辨别人类游泳姿态的准确率甚至可以媲美单任务学习。Kendall等[11]考虑到视觉场景理解背景下的多任务学习,涉及到不同单位和尺度的各种回归和分类任务,用各任务的同方差不确定性权衡多个损失函数;该方法能够自动从数据中学习相对权重,且不受初始化权重的影响。Yu等[12]确定了3种任务同时优化时各任务梯度相互干扰的客观因素,开发了减轻任务梯度之间相互干扰的简单通用方法。该方法将某个任务的梯度投影到所有与其具有干扰的任务梯度平面,对一系列具有挑战性的多任务监督学习和多任务强化学习问题,显著提高了模型的性能和效率,也明显提高了模型的训练速度和预测效果。Ozan等[13]将多任务学习视为寻找Pareto最优解的多目标优化,在界定出一个多目标损失函数的上界并证明它可以有效地优化之后,进一步证明该上界优化后能得到Pareto最优解;该方法在数字分类、联合语义分割、实例分割、深度估计、多标签分类等场景下能够训练出高效的分类模型。
多任务学习中,对各任务预测的平衡问题研究,目前主要集中在计算机视觉、图像分类和识别、自然语言处理等领域;对算法研究,主要关注算法的改进和统计学的优化;应用对象主要针对分类问题。但是,从影响梯度平衡的本质——不同任务数据分布的固有差异出发,解决不同任务在优化中出现梯度差异的回归问题仍未得到充分的关注。
笔者以非线性多任务回归问题为研究对象,根据加氢蜡油中硫、氮质量分数数据的分布特点,提出了一种构建损失函数的新方法,将其应用于蜡油加氢催化剂中试评价数据模型。针对4种不同的蜡油加氢催化剂,基于深度学习框架,通过硬参数共享,建立了适用于4种催化剂的中试评价数据驱动模型;同时通过全新的损失函数,解决了模型训练过程中各任务梯度的平衡问题。
1 蜡油催化加氢催化剂中试评价实验
1.1 蜡油催化加氢原料和催化剂
选用减压蜡油和焦化蜡油的混合原料为研究对象,用以考察不同催化剂对原料的适用性。原料蜡油(记为样品A、B、C、D)的主要性质如表1所示。实验所用催化剂为中国石化石油化工科学研究院研制的4种催化剂,即2种NiMo剂(RS-2100和RN-410)、CoMo剂(RVS-420)和NiMoW剂(RN-32V)。

表1 蜡油加氢实验所用原料油主要性质Table 1 Properties of raw oil for wax oil hydrogenation
1.2 蜡油催化加氢反应条件
蜡油加氢催化剂中试评价的工艺条件为:反应温度355~390 ℃,反应压力6.4~15 MPa,反应空速0.6~1.6 h-1,氢/油体积比600~1200。其工艺流程如图1所示,其中,加氢反应器中装填直径2~3 mm 的待评价催化剂100~150 mL。原料蜡油经加热炉加热并与H2混合后,进入加氢反应器,加氢反应产物通过热高分罐进行分离,气体产物经洗涤后释放,加氢蜡油进入产品罐,离线分析加氢蜡油的硫、氮含量。
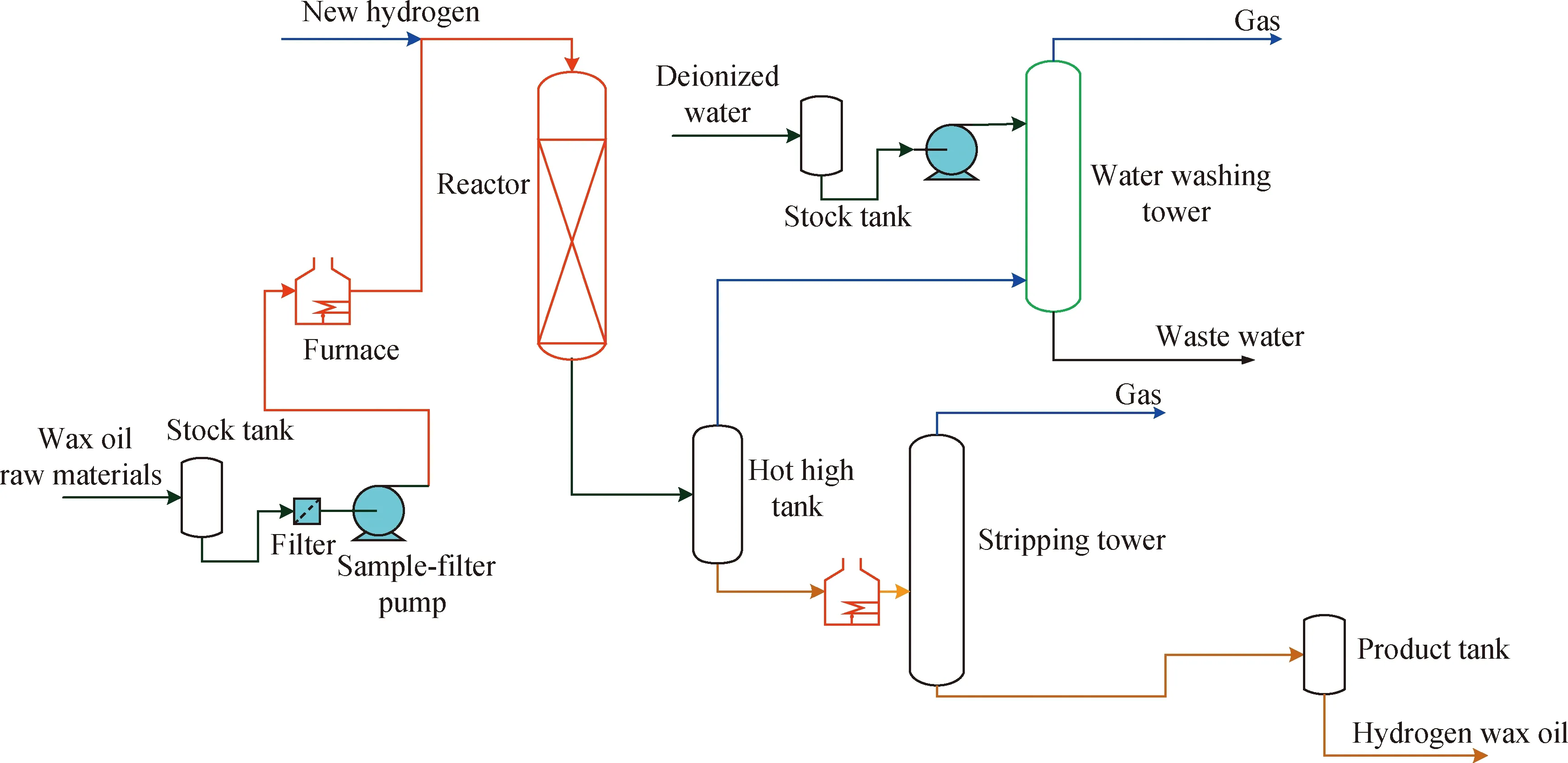
图1 蜡油加氢催化剂中试评价工艺流程图Fig.1 Pilot-scale evaluation flow chart of wax oil hydrogenation catalyst
2 催化剂中试评价数据模型与新的损失函数
2.1 催化剂中试评价数据模型的建立
蜡油加氢催化剂由Co、Mo、Ni、W 4种元素中的2种或3种混合制备而成,不同催化剂的脱硫、脱氮能力有所差异。为此,模型基于深度学习框架Keras,对不同的催化剂使用独热编码,完成不同催化剂中试评价数据的并行训练,构建适用于4种催化剂的数据模型。模型的输入参数包括原料性质、操作参数、催化剂牌号;输出参数为加氢蜡油硫、氮质量分数。建立的模型可以实现加氢蜡油硫、氮质量分数的同时预测。
利用Python编写代码,调用开源的深度学习框架Keras,搭建如图2所示的模型架构。模型设置4层网络结构,分别为输入层、第一隐含层、第二隐含层、输出层。为避免出现过拟合现象,第一和第二隐含层的Dropout均设为0.1。隐含层传递函数分别为线性整流函数(Rectified linear unit,ReLU)和双曲正切函数(Hyperbolic tangent,tanh),输出层传递函数为线性函数linear。损失函数为均方误差(Mean square error,MSE),采用Adam优化器;模型评估指标为平均绝对误差(Mean absolute error,MAE)。为减少模型的随机性,将批量处理规模batch_size设置为5,为保证模型可以复现,固定初始化随机种子。
调用机器学习库Sklearn的数据集划分包,按照70∶15∶15的比例将所有数据随机划分为训练集(Train set)、验证集(Validation set)和测试集(Test set)。为提高模型训练速度,使用Standard Scaler函数对输入数据进行标准化处理,对输出数据取对数。基于Keras进行模型训练的迭代过程如图2所示。
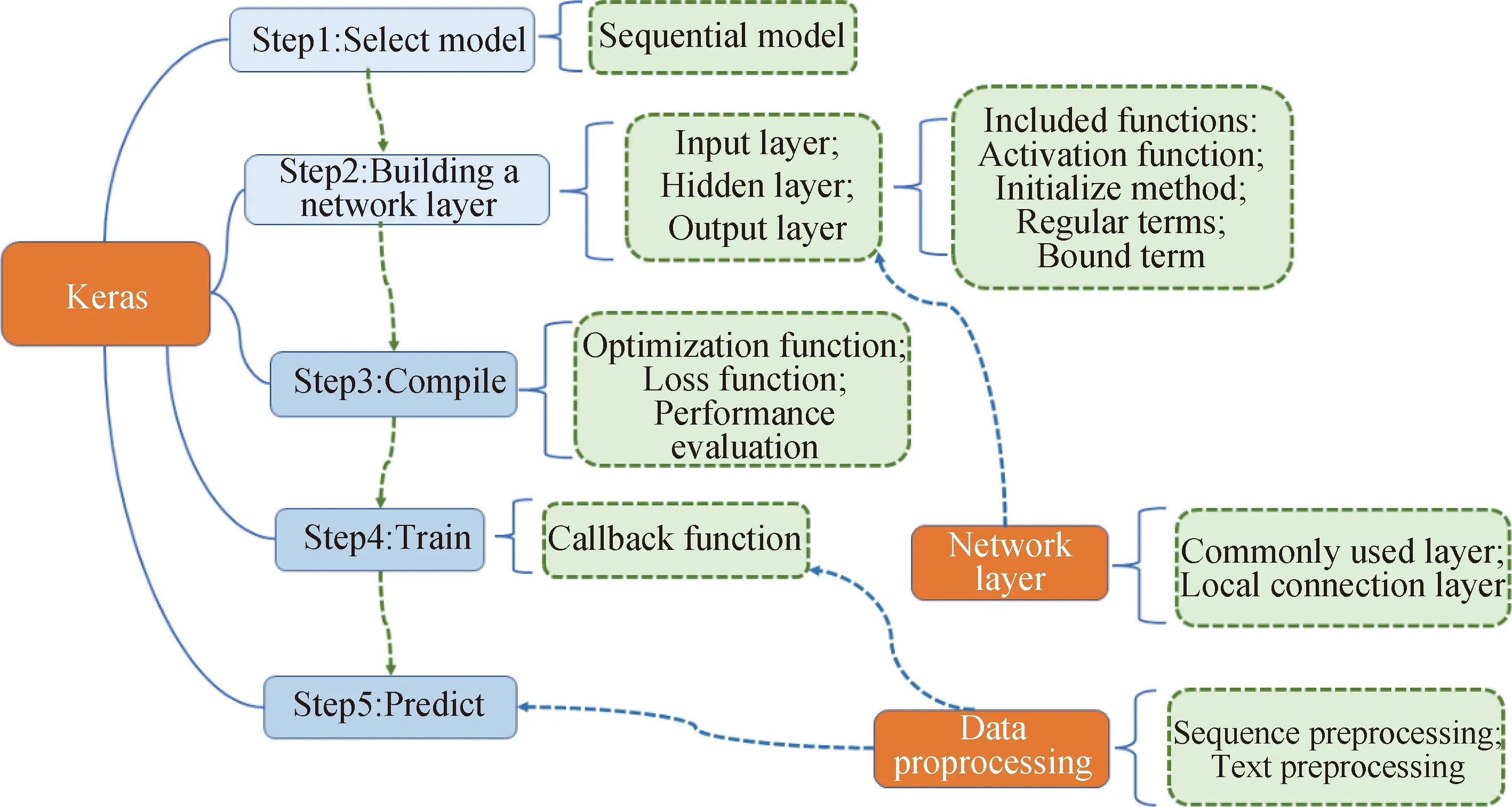
图2 基于Keras的深度学习框架模型Fig.2 Deep learning framework model based on Keras
图3为蜡油加氢中试数据模型训练集和验证集的MSE和MAE变化。由图3(a)可见,随着迭代次数(Epoch)的增加,训练集和验证集的均方误差MSE迅速减小,并逐步逼近稳定值,减小的幅度呈良好一致性,说明模型训练过程合理。将平均绝对误差MAE作为模型训练效果的评价指标,由图3(b)可见,随着Epoch的增加,训练集和验证集的MAE迅速减小,两者之间的差值逐渐缩小并趋于相同。
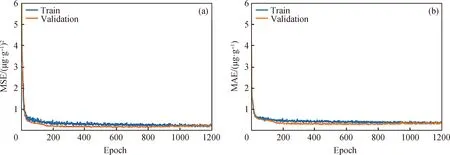
MSE—Mean square error; MAE—Mean absolute error; Epoch—Iterative times图3 蜡油加氢中试数据模型训练集和验证集的MSE和MAE变化Fig.3 MSE and MAE of training set and validation set in training process of pilot test data evaluation model for wax oil hydrogenation(a) MSE vs. Epoch; (b) MAE vs. Epoch
图4为测试集样本中加氢蜡油硫、氮质量分数的实测值和预测值对比。由图4可见:在0~1000 μg/g区间内,模型对硫、氮质量分数的预测值与实测值吻合良好;在高于1000 μg/g区间,硫质量分数预测值与实测值的偏离明显,而氮质量分数无实测数据。
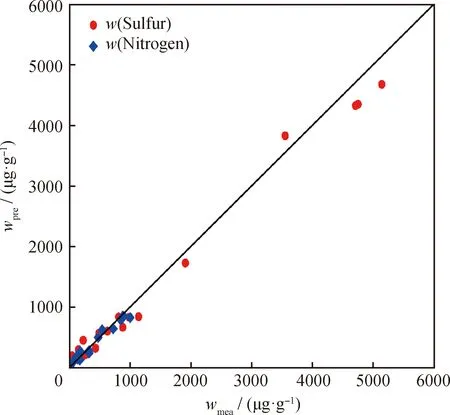
图4 测试集样本中加氢蜡油硫、氮质量分数的实测值(wmea)和预测值(wpre)对比Fig.4 Comparison of the measured (wmea) andpredicted values (wpre) of sulfur and nitrogen massfractions of hydrogenated wax oil in the test set
2.2 新的损失函数
为了进一步定量测试集加氢蜡油中硫、氮质量分数预测效果的差异,笔者对模型的预测效果进行了统计。表2为旧的损失函数模型对测试集中硫、氮质量分数预测效果的评价指标。从表2可以看出,测试集加氢蜡油硫、氮质量分数预测效果的评价指标差异较大。分析原因,主要是模型的损失函数对硫、氮质量分数进行同时优化时,硫、氮质量分数差异大,导致两者梯度更新时产生冲突。
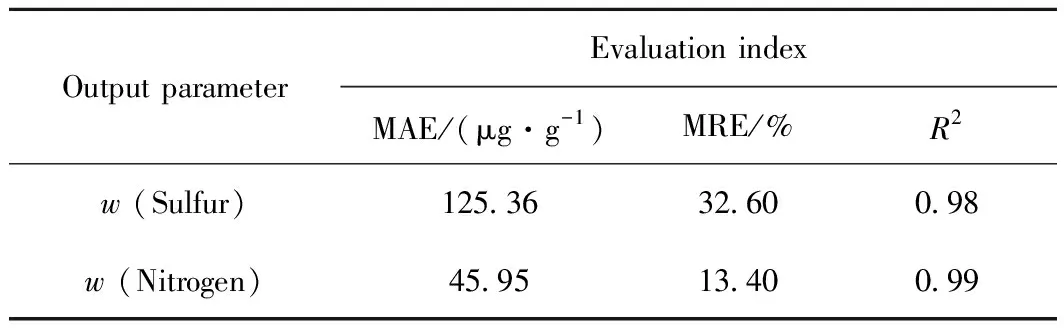
表2 旧的损失函数模型对测试集输出参数的预测效果Table 2 The prediction effect of the old loss function modelon the output parameters of the test set
模型训练过程中,对2个任务进行优化时,如果一个任务的梯度比另一个任务的梯度大得多,那么它将主导平均梯度。此研究中,模型的损失函数表达式为均方误差(MSE),即各任务预测值与实测值误差的平方和再加和求平均,如式(1)所示。
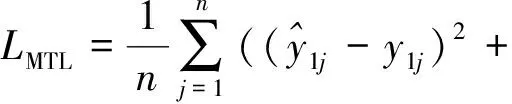
(1)
上述模型数据集中,加氢蜡油的硫质量分数分布在0~6000 μg/g之间,而加氢蜡油的氮质量分数分布在0~1000 μg/g之间。模型在训练时,会优先满足氮质量分数的预测误差,忽略硫质量分数的预测误差,从而出现硫、氮质量分数预测效果差异大的情况。
为解决非线性多任务学习模型预测过程中各任务预测误差不平衡的问题,笔者对所建模型的损失函数进行了重新设计,分别给硫、氮质量分数的误差平方和乘以不同的权重,该权重的作用是平衡模型训练过程中各任务的梯度,使各任务的梯度保持一致,同时达到最优训练效果。假设第i个任务的损失函数(Li)由式(2)计算得到;多任务的损失函数(LMTL)由式(3)计算得到;式(4)中共享参数(Wsh,下标sh是share的缩写)的优化受到所有任务损失函数的影响,并且不同任务损失函数对于共享参数的影响可以使用权重WFi进行调节,其中,Wsh+1为共享参数Wsh的下一步迭代,γ为参数更新过程中的步长。
(2)
(3)
(4)
假设赋予加氢蜡油中氮质量分数的权重为WF1,赋予加氢蜡油中硫质量分数的权重为WF2, 训练模型数据集加氢蜡油的硫质量分数平均值为X,训模模型数据集加氢蜡油氮质量分数的平均值为Y,WF1和WF2与X和Y的关系如式(5)所示。
(5)
将式(5)代入式(3),得到模型的损失函数如式(6)所示。
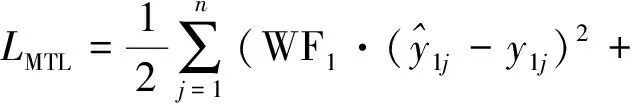
(6)
对模型损失函数的代码进行重新编写,模型训练时,调用新的损失函数,即式(6),模型训练完成后,对测试集加氢蜡油中硫、氮质量分数进行同时预测。
3 结果与讨论
旧、新损失函数模型对测试集加氢蜡油中硫、氮质量分数的预测效果对比,如图5所示。修改损失函数前,旧模型的预测值为Predicted1;修改损失函数后,新模型的预测值为Predicted2。从图5可以看出:相比Predicted1,在硫质量分数高于1000 μg/g区间,Predicted2与实测值的误差明显减小;在硫质量分数低于1000 μg/g区间,Predicted2与实测值的误差略微减小。对于加氢蜡油氮质量分数的预测而言,Predicted2与实测值的误差比Predicted1与实测值的误差略微降低。这说明新模型的损失函数可同时缩小加氢蜡油硫、氮质量分数的预测误差,其中硫质量分数的预测误差缩小尤其显著。
修改损失函数前、后,模型对测试集的预测评估指标,如表3所示。从表3可以看出,构建新的损失函数用于模型训练,加氢蜡油中硫质量分数的平均绝对误差(MAE)、平均相对误差(MRE)明显降低;而加氢蜡油中氮质量分数的MAE、MRE略微降低。这说明新的损失函数可改善模型对不同任务的预测效果。其中,对硫任务的调节作用明显,对比旧、新损失函数模型,加氢蜡油硫质量分数的MAE从125.36 μg/g下降至49.89 μg/g,MRE从32.60%下降至9.98%,R2从0.98提升至0.99,说明为硫任务损失函数设置的权重,对其梯度更新,起到了较好的修饰作用,使得模型在寻优的过程中,逐渐向硫任务的全局最优解靠拢。而模型对氮任务的调节作用较弱,加氢蜡油氮质量分数的MAE、MRE降低幅度较小,R2没有变化,说明为氮任务损失函数设置的权重,对其梯度更新也能起到修饰作用,但这种作用较弱,更多的表现为削弱硫任务梯度更新对氮任务梯度更新的影响。
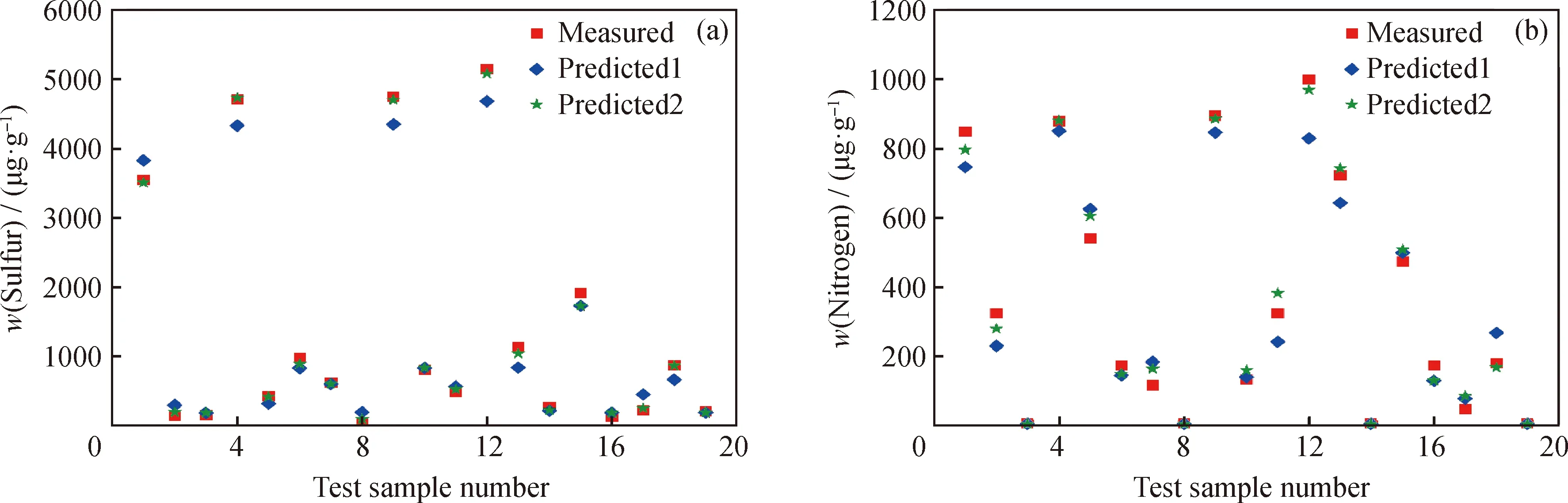
图5 新、旧损失函数模型对测试集输出参数预测效果比较Fig.5 Comparison between old and new loss function models in predicting output parameters of the test set(a) w(Sulfur); (b) w(Nitrogen)

表3 新、旧损失函数模型对测试集预测评估指标统计Table 3 New and old loss function models predict the evaluation index statistics of the test set
综合来看,造成模型同时预测加氢蜡油硫、氮质量分数预测误差差异大的关键原因是硫、氮质量分数分布的固有差异,这种差异导致模型在训练过程中,硫、氮任务梯度更新不一致,进而出现氮任务逼近最优解而硫任务未逼近最优解的情况。因此,笔者基于加氢蜡油中硫、氮质量分数的分布规律,分别为硫、氮任务损失函数构造不同的权重,来平衡两者之间的差异。使用全新的数据进行测试,结果表明新的损失函数基本解决了模型对2个任务同时预测时出现任务之间预测误差不平衡的问题。
4 结 论
(1)基于深度学习框架Keras,利用硬参数共享,建立了适用于4种不同蜡油加氢催化剂中试评价的数据驱动模型,实现了加氢蜡油中硫、氮质量分数的同时预测。
(2)根据加氢蜡油中硫、氮质量分数分布的差异,构建新的损失函数,解决了模型同时预测2个任务时,出现的预测误差不平衡的问题。相比旧的损失函数,新的损失函数模型模拟结果表明,同时预测精制蜡油硫、氮质量分数的平均绝对误差分别从125.36和45.95 μg/g降低至49.89和38.62 μg/g,平均相对误差分别从32.6%和13.4%降低至9.98%和9.59%,基本满足实际应用的要求。
(3)蜡油加氢工艺中的脱硫和脱氮反应是一种相互抑制的反应,传统的机理模型构建时需要考虑两者之间的相互作用,加入一定的假设,参数的求解过程较为复杂。笔者提出的非线性多任务同时预测的方法,为该问题的解决提供了另一种思路。
