基于深度强化学习的四足机器人研究综述
2022-05-10刘伟龙侯兰东徐一明
刘伟龙,李 彬*,侯兰东,徐一明
齐鲁工业大学(山东省科学院) a.数学与统计学院;b.电气工程与自动化学院,山东 济南 250353
1 四足机器人平台介绍
与轮式和履带式机器人相比,腿足式机器人对非结构化复杂地形具有更强的适应性和更小的地形破坏性,尽管控制算法较为复杂,腿足式机器人的研发依旧是机器人研究领域最受欢迎的方向之一。腿足式机器人主要包括双足机器人、四足机器人以及多足爬行机器人等。四足机器人的开发借鉴了猎豹和羚羊等敏捷的四足动物的身体结构。相较于其他腿足式机器人,四足机器人既可以实现静态稳定、高负载和高动态鲁棒性运动,又能在运动控制方面减少开发人员工作难度,所以四足仿生机器人是多年来机器人领域的研究热点。国内外近些年涌现出一批优秀的四足机器人研究团队,主要有美国的波士顿动力公司、麻省理工学院、瑞士苏黎世联邦理工学院、中国杭州宇树科技、杭州云深处科技和山东优宝特智能机器人公司等。
1.1 波士顿动力
最受关注的四足机器人研发团队当数美国的波士顿动力(Boston Dynamics)公司,2005年,波士顿动力公司推出了他们的第一代液压驱动四足机器人BigDog[1-2]。2008年他们又推出了第二代BigDog。2012年,波士顿动力公司发布了一款大型四足机器人LS3,在继续提高负载和续航能力的基础上,搭载了一些传感器,可以实现环境感知和对人员的跟随任务。2015年推出了使用电机和液压机混合驱动方式的机器人Spot,后来过渡到的纯电驱动的Spot mini,并于2019开始出售。波士顿动力公司的部分四足机器人如图1所示。
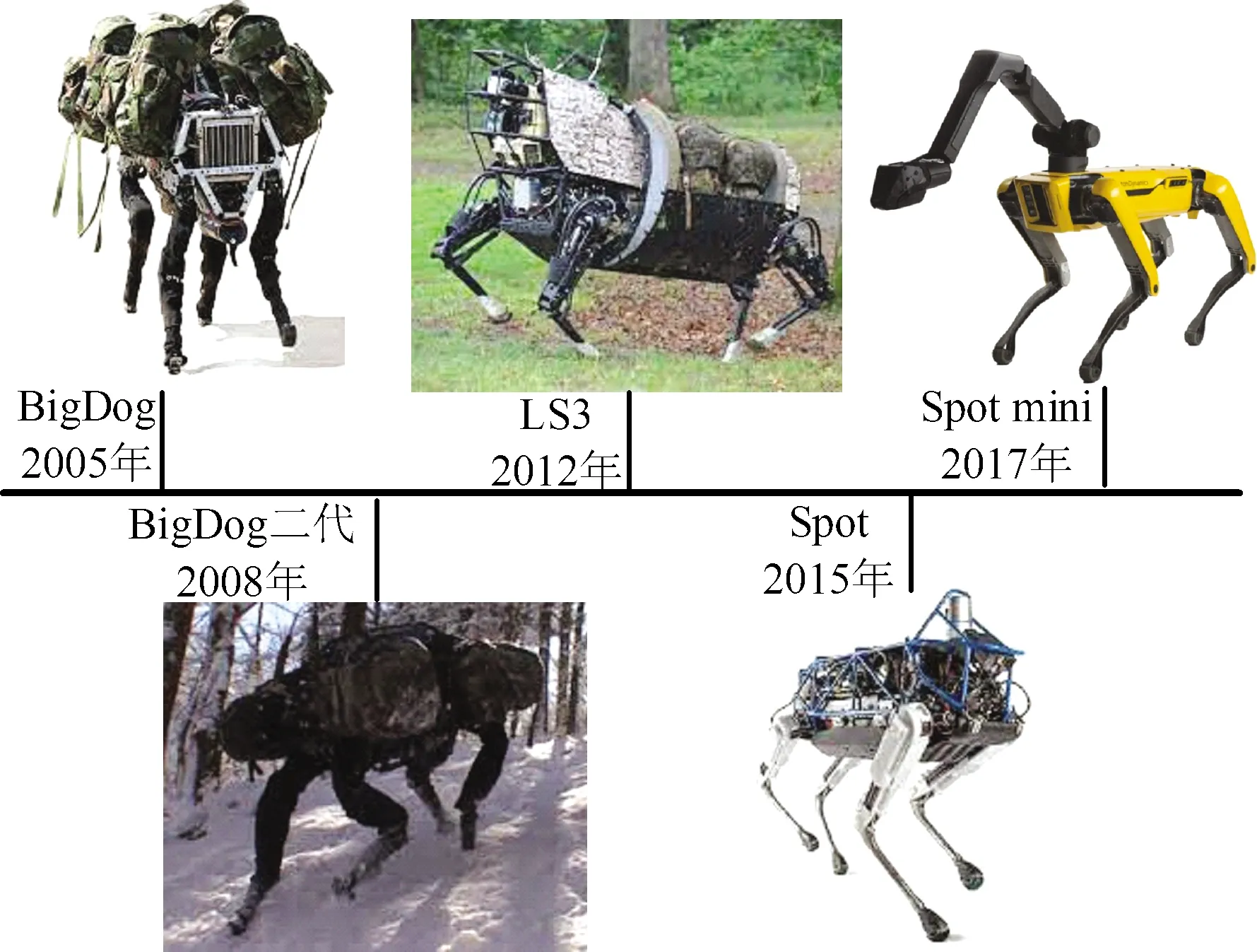
图1 波士顿动力四足机器人
1.2 麻省理工学院
麻省理工学院开发的四足机器人MIT Cheetah系列推动了四足机器人的快速发展,2012年模仿猎豹的腿部构造研发第一款四足机器人Cheetah[3]。同年推出了二代Cheetah2[4-8]机器人。2018年发布了第三代Cheetah3[9-11]进一步提高能量转化效率。2019年,小型四足机器人Mini Cheetah[12]发布,该研究团队也开源了Mini Cheetah机器人的软硬件系统,掀起了四足机器人领域的研究热潮。麻省理工学院的四足机器人如图2。

图2 MIT Cheetah系列四足机器人
1.3 苏黎世联邦理工学院
苏黎世联邦理工学院的ANYbotics团队2017年推出了基于串联弹性致动器的四足机器人ANYmal[13-15],用于复杂环境中实现稳定行走,并搭载特定传感器完成任务,例如工业巡检和泄漏气体检测报警等特定工作。该团队在2019年发布了ANYmal-C,旨在拓展更广泛的应用场景,为基于深度强化学习的四足机器人探索了一些新的研究方向[16-17]。ANYmal系列四足机器人如图3。

图3 ANYmal系列四足机器人
1.4 宇树科技
杭州宇树科技公司2017年推出Laikago四足机器人,该机器人被国内外很多研究团队作为二次开发的实验平台[18]。2019年宇树科技推出了Laikago的改进款Aliengo并在2020年推出了小型四足机器人A1。2021年宇树科技推出了首款伴随型四足机器人Go1,可以实现优异的人员跟随能力。宇树科技公司的部分四足机器人如图4。
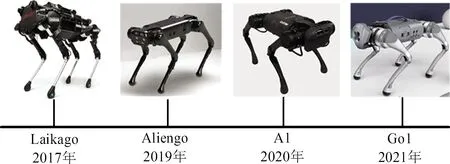
图4 宇树科技四足机器人
1.5 云深处科技
杭州云深处科技公司在2017年推出了“绝影”四足机器人[19]。随后云深处科技推出了“绝影”系列四足机器人的其他型号,分别有“绝影Mini”“绝影Mini Lite”和“绝影X20”,该系列拥有大量外扩平台,支持丰富的传感设备模块化组合搭载,可以胜任多场景的任务。云深处科技的“绝影”系列四足机器人如图5。

图5 云深处科技绝影系列四足机器人
1.6 优宝特智能机器人公司
山东优宝特智能机器人公司2016年推出了一款使用舵机驱动的小型四足机器人e-DOG,主要面向科研和教育行业。2019年,推出了使用高功率密度无刷直流电机驱动的中型四足机器人YoBoGo。该机器人二次开发性较好,可适用于农业、物流、教育和科研等领域应用。优宝特智能机器人公司推出的四足机器人如图6。
齐鲁工业大学数学与统计学院机器人-环境智能交互创新团队参与研制了一台智能感知、避障跟随四足机器人。该四足机器人搭载两部深度相机及一台十六线3D激光雷达组成环境感知的硬件系统,使用超宽带(Ultra Wide Band,UWB)模块作为定位系统。可实现环境地形感知和障碍物躲避,也可以完成对人员的跟随和物资搬运任务。该四足机器人如图7所示。

图7 智能感知避障跟随四足机器人
2 基于深度强化学习的四足机器人平台研究现状
目前,四足机器人的控制方法已经比较成熟,也可以实现低能耗、高动态性和鲁棒性的控制。但传统的机器人控制方法需要对机器人运动学和动力学精确地建模分析,设计四足机器人的敏捷运动需要大量的专业知识和繁琐的手动调参。近年来随着机器学习领域技术的发展,深度强化学习(Deep Reinforcement Learning,DRL)已经在诸多领域取得了令人瞩目的成绩,于是便有一些研究人员开始考虑将学习的方法引入到机器人上,让机器人在尽可能少人工设计和干预的情形下自主学习复杂的控制策略,实现灵活稳定的运动。
2018年,加州大学伯克利分校的Xue Bin Peng等[20]提出了DeepMimic方法,使用强化学习方法模仿示例运动,进而学习稳定的控制策略,使用双足、四足等仿真角色学习了基本的运动和高动态性的杂技动作。该模仿学习方法使用近端策略优化(Proximal Policy Optimization,PPO)算法进行训练。另外还提出在训练过程中对参考状态进行初始化和提前终止错误动作是有必要的,可以避免陷入错误的策略浪费计算资源,显著地提高学习效率和效果。
为了使四足机器人复制四足动物灵活敏捷的运动技能,Xue Bin Peng等[21]提出了一个模仿学习系统。使用动作捕捉技术采集四足动物的运动数据作为参考动作,使用强化学习方法合成控制策略,使机器人能够在现实世界中复现该动作。最后将策略转移到四足机器人Laikago,机器人高效地模仿了trot步态和原地转向等动作。
2018年,Google Brain和Google DeepMind的研究人员Jie Tan等[22]提出了一个利用深度强化学习技术训练四足机器人运动控制器的方法,通过定义一个简单的奖励信号,使四足机器人从零开始学习运动。通过建立精确的关节电机模型、添加延迟和扰动等方法来缩小仿真环境到物理现实世界的差距,提高控制策略的鲁棒性。控制策略在仿真中进行训练,然后部署到Ghost Robotics的Minitaurs四足机器人上。
腿足式机器人的运动控制是一项复杂且具有挑战性的任务,Deepali Jain等[23]引入了一个分层结构控制方法来自动分解复杂的运动任务。使用层次强化学习(Hierarchical Reinforcement Learning,HRL)方法将复杂的任务分解为简单的子任务,将体系结构分为高层和低层策略网络两部分,并对其进行联合训练。使用PyBullet对策略进行仿真训练,将训练得到的控制策略应用于四足机器人Minitaur的路径跟踪任务上。
Sehoon Ha等[24]开发了一个在现实世界中不需要人为干预的腿足式机器人学习运动策略的系统。该系统通过使用软演员-评论家(Soft Actor-Critic,SAC) 算法求解马尔科夫决策过程(Markov Decision Process,MDP),使用PyBullet仿真环境进行大量的训练。在平坦的地面、有弹性的床垫和有凹陷的门垫等地形上测试了他们提出的系统,Minitaur机器人可以在几个小时内学会在这些地形上行走,并为每种地形获得独特和专门的步态。
Jemin Hwangbo等[25]提出了一种在仿真中训练神经网络策略并将其转移到腿足式机器人系统上的方法。首先对机器人的物理参数进行辨识,并估计辨识过程中的不确定性。然后训练一个关节执行器网络,对复杂的执行器动力学建立模型。接下来使用置信域策略优化(Trust Region Policy Optimization,TRPO)算法训练控制策略。最后直接在ANYmal机器人实体系统上部署经过训练的策略,ANYmal能够精确而高效地执行高层的速度指令,并将最快速度提高了25%。
复杂地形下的腿足式机器人运动,是机器人技术的一个重大挑战。Vassilios Tsounis等[16]提出了训练地形感知神经网络策略的DeepGait方法,它结合了基于模型的运动规划和强化学习的方法。该方法由一个地形感知规划器和一个基础运动控制器组成。将该方法应用到ANYmal机器人上,可以顺利规划落足点并通过狭窄的桥梁等地形。
Joonho Lee等[17]提出了一个不依赖视觉信息的四足机器人强化学习控制器。该控制器仅使用来自关节编码器和惯性测量单元的本体感受测量得到的值。仿真中采用强化学习的方法对控制器进行训练,控制器由神经网络策略驱动。该控制器被用于ANYmal和ANYmal-C两代四足机器人上,机器人可以在泥土、沙子、碎石、茂密的植被、雪地、小溪和其他各种自然中的复杂地形中稳定地行走。
针对四足机器人实时在线自适应的问题,Ashish Kumar等[26]提出了快速电机自适应 (Rapid Motor Adaptation,RMA) 算法,该算法由基本策略和适应模块两个组件组成。RMA完全在仿真环境中使用强化学习方法训练,并部署在宇树科技的Al机器人上。在岩石、草地、混凝土、鹅卵石、楼梯等地形中,机器人的通过成功率达到了70%~80%。
3 基于深度强化学习的四足机器人研究思路
随着人工智能和机器学习领域技术的发展,深度强化学习在感知和决策问题中展现出优势。基于学习方法的主要思路就是智能体与环境进行交互试错,在这个过程中鼓励积极正向的行为,惩罚消极负向的行为,经过多次的交互试错训练,根据受到鼓励的程度学习积极正向或期望的行为策略,达到从无到有的学习目的。
将深度强化学习应用到四足机器人的运动控制上,一项重要的工作就是环境的设计,其中包含机器人状态空间、动作空间和奖励函数的设计,这项工作往往需要根据学习的任务目标去制定。四足机器人的状态空间通常会包含机器人在世界坐标系下的三维位置信息、三维的速度信息、三维的姿态角信息、三维的姿态角速度信息、12个关节的位置信息和12个关节的角速度等信息。动作空间通常由12个关节电机输出的位置、力矩和期望运动轨迹参数等组成。奖励函数根据具体的任务目标进行设定,例如把机器人学习稳定的快速行走作为任务目标,通常将机器人前进方向的移动距离和速度设置为正奖励项,将偏航和俯仰角度和角速度设置为负奖励项。
状态作为机器人运动控制策略网络的输入,动作作为策略网络的输出,机器人执行动作与环境交互,机器人的状态发生转移,同时环境会反馈一个奖励函数,策略网络根据新的状态和奖励函数选择下一步的动作。在这个过程中策略网络是不断更新的,更新的过程的也就是深度强化学习算法训练运动控制器的过程。
4 常用算法及仿真平台
4.1 常用的深度强化学习算法
深度强化学习方法可以分为基于值函数的和基于策略梯度的方法。基于值函数的深度强化学习方法适用于解决离散动作空间的问题。而机器人运动控制任务是一个连续动作空间问题,基于策略梯度的深度强化学习方法更加适合[27]。常用的基于策略梯度的方法有深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法[28]、置信域策略优化(Trust Region Policy Optimization,TRPO)算法[29]、异步优势行动家-评论家(Asynchronous Advantage Actor-Critic,A3C)算法[30]和近端策略优化(Proximal Policy Optimization,PPO)算法[31]等。目前,PPO算法是深度强化学习方法处理机器人运动控制任务使用最广泛的算法。
4.2 常用的四足机器人仿真平台
基于深度强化学习方法训练机器人控制器通常需要消耗大量的时间和计算资源,而且训练是从零开始的,机器人控制策略训练的前期往往会做出让人难以预料的错误动作,非常容易造成机器人硬件设备的损坏,因为机器人硬件成本较为昂贵且机载微型计算机的计算性能有限,在实体机器人上进行深度强化学习控制器的训练成本和时间代价较大,所以常用的做法是在仿真中训练深度强化学习控制策略,在实体机器人部署训练后的策略。
目前,比较主流的机器人仿真平台主要有Webots、PyBullet、Gazebo、MuJoCo、V-REP和Isaac Gym等。其中比较适合用于深度强化学习训练机器人控制策略的仿真平台有PyBullet和MuJoCo。PyBullet是一个Python的模块,它基于Bullet物理引擎,系统兼容性较好且支持多种格式的机器人仿真模型,PyBullet可以轻松地调用多数深度强化学习算法库,非常适合机器人进行深度强化学习算法的训练和实验。MuJoCo是基于多关节接触动力学的物理引擎的仿真平台,其中包含了很多强化学习算法的环境和例程,比较适合用于强化学习算法的验证。从物理引擎、开发语言、系统兼容性、适用场景和操作难度等方面考虑,PyBullet较为适合进行四足机器人深度强化学习控制器的训练和实验仿真,也是目前较受欢迎的深度强化学习机器人仿真平台。
如何将仿真环境中训练的策略移植到实体机器人上,并使机器人展现出优异的性能,是四足机器人应用深度强化学习方法进行运动控制面临的一大挑战。由于仿真环境与真实世界环境存在差异,导致仿真到现实之间的控制策略转移存在困难,解决这个问题的思路有两种,一是在仿真环境中建立尽可能接近于现实的精确机器人和环境模型,二是在仿真过程中引入随机的干扰噪声和延迟,提高仿真训练策略的鲁棒性。
5 基于学习方法的四足机器人应用前景展望
四足机器人使用基于学习的方法,可以自主学习运动技能和指定的任务。未来的四足机器人的发展方向是将四足机器人智能感知能力和智能控制能力紧密融合,四足机器人的智能化水平得以提高,就可以在多领域进行部署。未来四足机器人的主要应用场景主要有工业领域和智能家居生态。
5.1 工业领域的应用前景
相较于轮式和履带式移动机器人,四足机器人具有更好的地形适应性和更小的地形破坏性,相较于其他腿足式机器人,具有更好的稳定性和更高的负载能力。四足机器人可以代替人类进入对生命安全造成威胁的场景,并完成一些工作任务。四足机器人背部具有丰富的扩展接口,搭载传感设备、巡检设备和操作终端后,可以完成地下矿井有毒气体检测、工厂设备温度检测、未知环境探测、管道电缆巡检、物资运送等工业场景任务。
5.2 智能家居场景的应用前景
四足机器人拥有近似宠物友好的外形,可以成为智慧家庭的一部分。四足机器人可以作为陪伴儿童和老人的智能宠物,通过加载自然语言交互系统、表情显示器以及触摸传感器等设备,实现与人类的智能情感交互。基于学习方法的四足机器人具有自主学习运动控制策略的能力和环境感知能力,机器人可以搭载立体相机和激光雷达等传感器实现与家庭环境的交互,学习到多种灵活敏捷的运动技能,实现智能化的环境感知。另外,连接云端以后,四足机器人个体学习到的运动策略可以共享到云端,也可以从云端获取其他机器人的运动技能,大大提高机器人的学习效率。基于深度强化学习方法的四足机器人有望推动智能家居和万物互联的发展。
6 总结和展望
本文介绍了目前国内外具有代表性的四足机器人平台和一些使用深度强化学习方法训练四足机器人控制器的工作。然后分析了更适合进行深度强化学习方法训练四足机器人控制策略的仿真平台及环境,总结目前由仿真环境到四足机器人实体平台存在的难点及减小仿真到现实之间差距的思路。最后,对具有学习能力的四足机器人的应用场景进行展望。
根据深度强化学习四足机器人运动控制的研究现状,本团队未来的研究工作主要在以下三方面:
使用基于学习的方法训练四足机器人学习不同的步态并根据速度进行自适应步态切换,步态生成部分使用模仿学习方法进行训练,加入专家参考轨迹并设定轨迹拟合奖励函数,引导机器人生成多种步态,通过设定速度适应阈值,使机器人生成自适应的步态切换。
训练四足机器人自主学习路径规划问题,使用栅格法建立环境地图,将机器人和地图的位置信息作为状态空间信息,机器人的前进和转向速度作为动作空间信息,奖励函数按照四足机器人距离目标点和障碍物的距离作为标准进行设计,训练四足机器人找到最优路径。
训练四足机器人学习跌倒复位的控制策略,随机化机器人跌倒状态,机器人的质心高度和关节角度作为状态空间信息,关节位置指令作为动作空间,根据恢复过程中与正常站立的质心和关节位置误差作为设计奖励函数的依据,训练并生成四足机器人的跌倒自恢复控制策略。
